 [ Home Page - Surveys - Documents - Presentations - Search ]
[ Home Page - Surveys - Documents - Presentations - Search ]
This page is for printing out the case studies on the subject of Metadata. Note that some of the internal links may not work.
Gathering the Jewels [1] was established by a consortium of the following bodies: National Library of Wales, Society of Chief Librarians (Wales), National Museums and Galleries of Wales, Federation of Welsh Museums, Archives Council Wales, Royal Commission of Ancient and Historic Monuments Wales, Council of Museums in Wales, Wales Higher Education Libraries Forum and the Welsh County Archivists Group. The goal of the project was to digitise 23,000 items from approximately 190 libraries, museums and archives all over Wales and to present them on the Internet by means of a searchable database.
The nature of the project has four important consequences for the way we approach the collection of metadata:
When we first looked at the question of metadata, and came face to face with the reality of the difficulties listed above, the problem seemed massive. To make things worse, the Dublin Core elements apparently needed their own glossary to make them intelligible. These were dark days. However, things very quickly improved.
In the first place, we talked to professionals from the National Library of Wales's metadata unit, who reassured us that the Dublin Core elements could be translated into English. But more importantly than that, they showed us that the elements could be made to work for us: that there is a degree of flexibility about what many of the elements can be taken to mean; that the most important thing is to be consistent, however you interpret a particular element.
For example, there is a Dublin Core element called "Publisher". The National Library would interpret this as the organisation publishing the digital material on the Internet - i.e., us; we, on the other hand, would prefer to use it for the institution providing us with the material. Both interpretations are apparently valid, so long as they are used consistently. We also interpret the "Title" element in a way that will let us use it as a caption to the image when it is displayed on the Internet.
We also made a couple of key decisions. We were not here to catalogue 23,000 items to the Dublin Core standard. Also, the output of the whole project was to be a Web site linked to a searchable database – so the bare minimum metadata we had to collect was defined by the requirements of the Web site and search mechanisms for the database. In other words, an image appearing on a user's computer screen had to have a certain amount of information associated with it (a caption, a date, a credit to the institution that gave it to us, as well as subject and place-name keywords, etc.); any other metadata we could collect would be nice (the 'extent' or size, the 'medium', etc.) but not essential.
This was also our "Get Out Of Jail Free" card with regard to the bilingual aspects of the Web site. Anything which the user will see or search on has to be in English and Welsh. Other Dublin Core elements are recorded in English only (this decision was taken on the advice of the National Library of Wales and is based entirely on the limitations of existing computer systems and the amount of time that fully bilingual metadata would take to translate and enter; it has nothing to do with political preferences for one language or the other.)
As a result we have divided our metadata into four categories. Core elements are those that are mandatory, and which will be viewed or searched by the user, together with copyright information; Important elements are those which we may not get from an institution but which we will supply ourselves, such as a detailed interpretative description of the image. Technical elements are those which record how the material was digitally captured; we do not regard these as a high priority but as they are easy to enter in batches we always make sure we complete them. And finally Useful elements are the other Dublin Core elements that we will collect if the institution can supply them easily, but which we will otherwise leave blank until such time as cataloguing to the Dublin Core standard becomes the norm.
| Title English | a caption for the item, no more than one line |
| Title Welsh | as above, in Welsh |
| Identifier | unique ID of item, e.g. accession or catalogue number |
| Location | place name most significantly associated with the image |
| Period | period of subject depicted |
| Copyright | brief details of copyright ownership and clearance |
| Creator | institution/individual that produced the original |
| Date | date of production, e.g., when a painting was painted |
| Description | max. 200 word description of the resource and its content |
| Description Welsh | as above, in Welsh |
| Capture device | e.g. the scanner or camera used to capture the image |
| Capture history | e.g. the software employed |
| Manipulation history | file format master created in, quality control checks, etc. |
| Resolution of master | number of pixels (e.g., 3,400 x 2,200) |
| Compression | compressed or uncompressed |
| Bit depth of master | e.g. 24 bit |
| Colour profiles | e.g. Apple RGB embedded |
| Greyscale patch | e.g. Kodak Q13 greyscale |
| Type | type of resource, e.g. “image”, “text” |
| Extent | size, quantity, duration e.g. “1 vol., 200 pages” |
| Medium | example, “photograph” |
| Language | example, “EN” , “CY” ,”FR” |
| Relationship | example, “is part of collection ….” |
| Location alt. | bilingual place name variants |
| Publisher | usually repository name |
| GIS Reference | Eastings, Northings of place most significantly associated with the image |
| OS NGR | OS National Grid Reference of place most significantly associated with the image |
| Credit Line | where additional credit line is required for a record. Defaults to repository name |
Allison Coleman
Gathering the Jewels Ltd
National Library of Wales
Aberystwyth, Ceredigion
SY23 3BU.
The UK Data Archive at the University of Essex is one of the partners within the JISC-funded Collection of Historical and Contemporary Census Data and Related Materials (CHCC) project [1]. The project, led by MIMAS at the University of Manchester, runs from October 2000 to September 2003.
The central aim of the project is to increase use of the CHCC in learning and teaching. It is doing this by: improving accessibility to the primary data resources; developing an integrated set of learning and teaching materials; improving awareness about the contexts in which census data can be used in learning and teaching; integrating contextual materials; providing access to web-based data exploration/visualisation tools; and developing resource discovery tools.
The UK Data Archive's role has been to develop this last output, a Census Resource Discovery System (initially and temporarily entitled a 'Census Portal'), which will allow both the primary census data and the CHCC-created related learning and teaching materials to be searched and browsed.
As a final, additional, introductory comment, it should be noted that although, due to staff changes, Lucy Bell has taken over the project management of the Census Resource Discovery System (CRDS) at the end of its development, the majority of the work described below was carried out between 2001 and 2003 by colleagues within the UK Data Archive and the History Data Service: Cressida Chappell, Steve Warin and Amanda Closier.
As the Census Resource Discovery System (CRDS) was intended to index two very different sorts of resource - primary data and teaching and learning materials - much initial work prior to the start of the project was put into identifying which metadata scheme should be used. It is not possible to index all the materials to a fine enough degree using a single scheme, therefore, the DDI (Data Documentation Initiative) Codebook [2] was used for the data and the IMS Learning Resource Metadata Specification [3] for the learning and teaching materials.
Both schema were taken, analysed and had CHCC Application Profiles crested. An initial problem encountered in the first six months of the project was that the extensions to the DDI had not been finalised by the time they were required for the development work on the CRDS. This delayed the development of the Metadata Entry System (MES); however, the work to set up the MES for the learning and teaching materials went ahead as planned.
The MES is a 'behind-the-scenes' tool, written in Visual FoxPro 7, created so that the metadata which form the CRDS records can be entered remotely into the database. Other CHCC project staff have been sent copies of the MES on CD, which they have installed locally on their PCs and used to enter the metadata. The completed records are automatically sent to the database, where they become live the following day and are then part of the database viewed via the CRDS web site which users can search and browse.
Working with two schema has meant having to design a MES which is suitable for either sort of resource. It has also meant the need to identify and map the related fields within each profile to each other, for the purposes of search, browse and display. Even if the MES can be set up so that the appropriate scheme is used, should the metadata creator select 'data' or 'learning and teaching resource' at the start, the users still need to be able to search across all the resources, no matter which scheme has been used to catalogue them.
This work was undertaken during the end of 2001 and much of 2002. Near the end of the first phase of the project, when these essential preparatory tasks should have been completed, the second of the MES-related obstacles was hit: it was discovered that the IMS specification was likely to be superseded by an eLearning standard, the IEEE Learning Object Metadata (IEEE LOM) [4]. The team working on the CRDS had to move fast to ensure that the system was kept as up-to-date as possible in light of these changes.
Another key task was the identification of the most appropriate thesaurus to use as the controlled vocabulary for the system. It was essential to find an appropriately specific list of keywords for indexing all the metadata records within the database. The list would be employed by several project staff, in diverse locations, all entering their own metadata and so the list needed to be of a manageable size but also to contain all terms which might be required.
Three thesauri were on offer as likely candidates: the Humanities and Social Science Electronic Thesaurus (HASSET) [5], the European Language Social Science Thesaurus (ELSST) [6] and the Social Research Methodology thesaurus (SRM) [7]. The third issue, which caused a delay in relation to metadata, was the need for the project team to reach a consensus on which thesaurus to use.
Despite the fact that some staff members had already left (as the project was reaching a conclusion of its first phase), it was decided to upgrade from IMS to IEEE LOM. The JISC agreed to fund a short-term extension of four months, during which time, as well as incorporating OAI harvesting and setting the system up as a Z39.50 target, the changes between the two schema were to be analysed and technical alterations to both the MES and to the web site's search and browse functionality made. This work is now halfway through. The profile used has been the UK Common Metadata Framework (UKCMF) [8]. The current major task is to update the guidelines used by those people entering metadata to ensure that they correspond with exactly what is seen on the screen.
The biggest headache during the upgrade has been the application of the appropriate XML bindings. At first, it was thought that the system may have to use the IMS bindings as an IEEE LOM set was not yet available. The IMS XML was considered to be similar to that of the IEEE LOM. Following the release of the draft IEEE LOM bindings, however, it was decided that it would be more appropriate to use these. The work to complete the CRDS needs to be done sooner than these will be finalised; nonetheless, it still seems more sensible to apply what will be the eventual schema rather than one which may become obsolete. The XML is being applied using Java Architecture for XML Binding (JAXB) [9]. This is not proving to be as straightforward as was hoped with the IEEE LOM XML, due to issues with the custom bindings file; in contrast, the DDI XML bindings have been relatively simple.
It soon became clear that a single thesaurus would not do the job. Although many included some census-specific terms, none were comprehensive enough. It is expected that some of the CRDS's users will have or will have been given by their tutors sophisticated and precise keywords to use, which are specific to certain census concepts. Additionally, because many of the CHCC-created learning and teaching objects constitute overviews of the subject and introductions to research methodologies, it was vital also to include appropriate methodological keywords to describe these.
In the end, terms from all three of the chosen thesauri were selected (HASSET, ELSST and SRM) and shared with the rest of the CHCC partners. This initial list numbered about 150 terms; however, some essential terms, such as FAMILY STRUCTURE, SOCIO-ECONOMIC GROUP or STANDARD OCCUPATION CLASSIFICATION, were still missing. The CHCC partners suggested additional terms and, after much debate, a final amalgamated list, gleaned from all four of these sources, the three thesauri and the CHCC partners, was settled. The final list contains 260 terms.
The biggest lesson to have been learnt through the development of the CHCC CRDS is the need to build as much slippage time as possible into a timetable. This sounds obvious but is worth repeating. Unfortunately, having said that, several of the obstacles encountered during the last 19 months of this project could not possibly have been predicted.
It was expected that the DDI would have been finalised in early 2002, but this did not happen until late Spring; it was expected that the IMS metadata specification would be the final one to be used (and, in fact, this was the specification advocated by the JISC); it was hoped to resolve the thesaurus question more quickly than proved possible. Most project plans will include slippage time for instances such as the third in this list, but few will be able to include provision for changing or delayed standards.
The second lesson learnt and probably the most important one is the need to be flexible when working with metadata standards and to communicate with those in the know as much as possible.
The CHCC CRDS project has been fortunate in receiving additional funding to incorporate the new changes in elearning metadata standards; without this, a product could have been launched which would have already been out-of-date even before it started.
Lucy Bell
UK Data Archive
University of Essex
Wivenhoe Park
Colchester
CO4 3SQ
Project Web site: http://www.chcc.ac.uk/
For QA Focus use.
The Exploit Interactive e-journal [1] was funded by the EU's Telematics For Libraries programme to disseminate information about projects funded by the programme. The e-journal was produced by UKOLN, University of Bath.
Exploit Interactive made use of Dublin Core metadata in order to provide enhanced local search facilities. This case study describes the approaches taken to the management and use of the metadata, difficulties experienced and lessons which have been learnt.
Metadata needed to be provided in order to provide richer searching than would be possible using standard free-text indexing. In particular it was desirable to allow users to search on a number of fields including Author, Title and Description
In addition it was felt desirable to allow users to restrict searches by issues by article type (e.g. feature article, regular article, news, etc.) and by funding body (e.g. EU, national, etc.) These facilities would be useful not only for end users but also by the editorial team in order to collate statistics needed for reports to the funders.
The metadata was stored in a article_defaults.ssi file which was held in the directory containing an article. The metadata was held as a VBscript assignment. For example, the metadata for the The XHTML Interview article [2] was stored as:
doc_title = "The XHTML Interview"
author="Kelly, B."
title="WebWatching National Node Sites"
description = "In this issue's Web Technologies column we ask Brian Kelly to tell us more about XHTML."
article_type = "regular"
This file was included into the article and converted into HTML <META> tags using a server-side include file.
Storing the metadata in a neutral format and then converting it into HTML <META> tags using a server-side script meant that the metadata could be converted into other formats (such as XHTML) by making a single alteration to the script.
It was possible to index the contents of the <META> tags using Microsoft's SiteServer software in order to provide enhanced search facilities, as illustrated below.
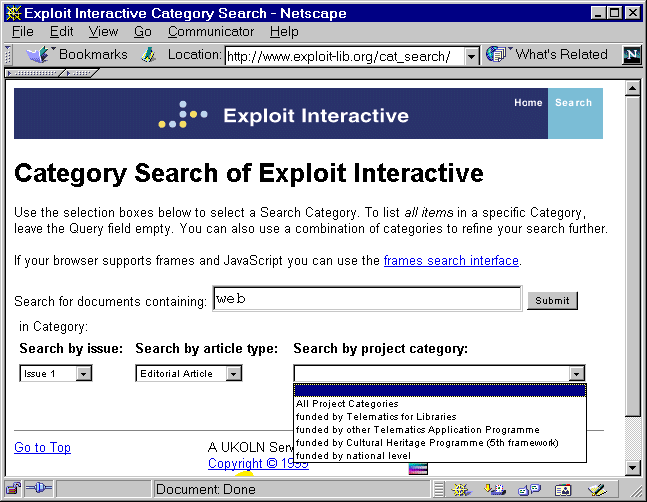
Figure 1: Standard Search Interface (click for enlarged view)
As illustrated in Figure 1 it is possible to search by issue, article type, project category, etc.
Alternative approaches to providing the search interface can be provided. An interface which uses a Windows-explorer style of interface is shown in Figure 2.
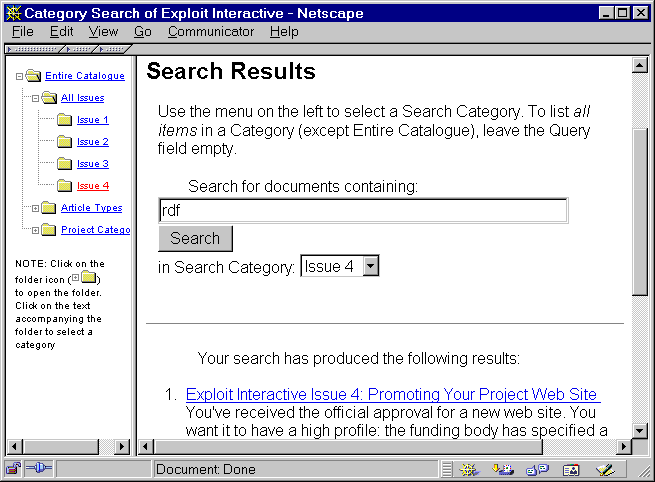
Figure 2: Alternative Search Interface (click for enlarged view)
Initially when we attempted to index the metadata we discovered that it was not possible to index <META> tags with values containing a full stop, such as <meta name="DC.Title" content="The XHTML Interview">.
However we found a procedure which allowed the <META> tags to be indexed correctly. We have documented this solution [3] and have also published an article describing this approach [4].
During the two year lifetime of the Exploit Interactive e-journal three editors were responsible for its publication. The different editors are likely to have taken slightly different approaches to the creation of the metadata. Although the format for the author's name was standardised (surname, initial) the approaches to creation of keywords, description, etc. metadata was not formally documented and so, inevitably, different approaches will have been adopted. In addition there was no systematic checking for the existence of all necessary metadata fields and so some may have been left blank.
The approaches which were taken provided a rich search service for our readers and enabled the editorial team to easily obtain management statistics. However if we were to start over again there are a number of changes we would consider making.
Although the metadata is stored in a neutral format which allows the format in which it is represented to be changed by updating a single server-side script, the metadata is closely linked with each individual article. The metadata cannot easily be processed independently of the article. It is desirable, for example, to be able to process the metadata for every article in a single operation - in order to, for example, make the metadata available in OAI format for processing by an OAI harvester.
In order to do this it is desirable to store the metadata in a database. This would also have the advantage of allowing the metadata to be managed and allow errors (e.g. variations of author's names, etc.) to be cleaned.
Use of a database as part of the workflow process would enable greater control to be applied for the metadata: for example, it would enable metadata such as keywords, article type, etc. to be chosen from a fixed vocabulary, thus removing the danger of the editor misspelling such entries.
Brian Kelly
UKOLN
University of Bath
BATH
Email: b.kelly@ukoln.ac.uk
Although the work described in this case study was funded by the European Commission, the approaches to management and use of metadata may be useful to projects which are addressing similar issues.
Managing And Using Metadata In An E-Journal,
Kelly, B., QA Focus case study 01, UKOLN,
<http://www.ukoln.ac.uk/qa-focus/documents/case-studies/case-study-01/>
First published 25 October 2002.
The JISC and ESRC-funded SOSIG service [1] is one of the longest running RDN subject gateways. SOSIG provides access to high quality, peer-reviewed records on Internet resources in the area of Social Science, Business and Law.
Many projects will be providing metadata which describes projects' deliverables, which may include resource discovery or educational metadata.
In order for projects to gain an understanding of the importance which JISC services place on the quality of metadata, this case study has been written which describes the approach to 'spring-cleaning' which SOSIG has carried out as one of its quality assurance procedures in order to ensure that its records continued to provide high quality information.
The core of the SOSIG service, the Internet Catalogue, holds over 26,000 structured metadata records describing Internet resources relevant to social science teaching, learning and research. Established in 1994, SOSIG is one of the longest-running subject gateways in Europe. The subject section editors have been seeking out, evaluating and describing social science Internet resources, developing the collection so that it now covers 17 top-level subject headings with over 1,000 sub-sections. Given the dynamic nature of the Internet, and the Web in particular, collection development is a major task. Collection management (i.e. weeding out broken links, checking and updating records) at this scale can also be something of a challenge.
The SOSIG core team, based at ILRT in Bristol, devotes considerable resource to removing or revising records with broken links (human checks based on reports from an automated weekly link-checking programme). Subject section editors, based in universities and research organisations around the UK, also consider durability and reliability of resources as part of the extensive quality criteria for inclusion in the Catalogue. They regularly check records and update them: however, the human input required to do this on a systematic and comprehensive scale would be beyond current resources. SOSIG has therefore recently embarked on a major 'spring cleaning' exercise that it is hoped will address this issue and keep the records current. We describe below the method, and outcomes to date.
There are several reasons why such collection management activity is important. User feedback indicates that currency of the resource descriptions is one of the most appreciated features of the SOSIG service. SOSIG and other RDN hubs are promoted on the basis of the quality of their records: offering out-of-date descriptions and other details is likely to frustrate users and, in the long term, be detrimental to their perceptions and therefore use of the service. Recent changes in data protection legislation also emphasise the obligation to check that authors/owners are aware of and happy with the inclusion of their resources in SOSIG. Checking with resource owners also appears to have incidental public relations benefits and is helping to develop the collection by identifying new resources from information publishers and providers.
How did we go about our spring-clean? Each of the metadata records for the 26,000 resources catalogued in SOSIG contains a field for 'administrative email' - the contact email address of the person or organisation responsible for the site. We adapted an existing Perl script (developed in ILRT for another project), which allowed a tailored email to be sent to each of these addresses. The message includes the URL of the SOSIG record(s) associated with the admin email. Recipients are informed that their resources are included in SOSIG and are asked to check the SOSIG record for their resource (via an embedded link in the message) and supply corrections if necessary. They are also invited to propose new resources for addition to the Catalogue.
We first considered a mass, simultaneous mailout covering all 26,000 records. The script sends one message per minute to avoid swamping the servers. However we had no idea of the level of response likely to be generated and wanted to avoid swamping ourselves! We therefore decided to phase the process, running the script against batches of 2,000 records on a roughly monthly basis, in numerical order of unique record identifiers, these were grouped notifications so that an administrator would get one email referring to a number of different sites/pages they were responsible for. The process was run for the first time at the end of July 2002 and, on the basis of low-numbered identifiers, included records of resources first catalogued in SOSIG's early days. The SOSIG technical officer oversaw the technical monitoring of the process, whilst other staff handled the personal responses, either dealing with change requests or passing on suggestions for additional resources to Section Editors responsible for specific subject areas on SOSIG.
In total we received 950 personal responses (approximately 4%) from email recipients. A further 3,000 or so automated 'bounced' responses were received. Those of us who are regular and long-term users of the Web are well aware of the fairly constant evolution of Web resource content and features. The SOSIG spring clean exercise also highlights the extent of change in personnel associated with Web resources. As mentioned above, of the emails sent relating to the first 4,000 records, over a quarter 'bounced' back. Although a very small proportion of these were automated 'out of office' replies, most were returned because the address was no longer in use.
The majority of the personal responses requested a change in the URL or to the administrative email address recorded for their resource. Many had stopped using personal email addresses and had turned to generic site or service addresses. Others reported that they were no longer responsible for the resource. As the first batches included older records, it will be interesting to see whether the proportion of bounced and changed emails reduces over time, or whether people are really more volatile than the resources.
We have to assume that the remaining email recipients have no cause for complaint or change requests. In fact, we were very pleased at the overwhelmingly positive response the exercise has generated so far. Many simply confirmed that their records were correct and they were pleased to be included. Others noted minor corrections to descriptions, URLs and, as mentioned, admin email addresses. Many also took the time to recommend new resources for addition to the Catalogue. Only one or two concerns were raised about the inclusion of certain data in the recorded, although there were several queries which highlighted changes needed to the email message for the second and subsequent batches.
One of these arose as a result of the de-duplication process, which only operates within each batch of 2,000 records. Where the same admin email address is included in records excluded from that batch, the de-duplication process ignores it. Some recipients therefore asked why we had apparently included only some of their resources, when they are actually on SOSIG, just not in that particular set of records.
Only one major issue was raised, that of deep-linking. It seems that this is a problem for one organisation, and raises questions about the changing nature of the Web - or perhaps some companies' difficulty in engaging with its original principles. Time will tell whether this is an issue for other organisations: to date it has been raised only once.
Spring-cleaning in domestic settings always involves considerable effort, and the SOSIG spring clean is no exception. SOSIG staff spent about a week, full-time, dealing with the personal responses received after each batch of 2,000 records were processed. The first batch of messages all had the same subject line, so it was impossible to distinguish between responses appearing in the shared mailbox used for replies. In the second 2,000, the subject line includes the domain of the admin email address, which makes handling the responses much easier.
Bounced messages create the most work, because detective skills are then necessary to check resources 'by hand' and search for a replacement admin email address to which the message can then be forwarded. Minor corrections take little time, but the recommendation of new resources leads to initiation of our usual evaluation and cataloguing processes which can be lengthy, depending on the nature and scale of the resource.
We realised that timing of the process could have been better: initiating it in the middle of Summer holiday season is likely to have resulted in more out-of-office replies than might be expected at other times. Emails are now sent as routine to owners of all new additions to the catalogue: this complies with the legal requirements but is also an additional quality check and public relations exercise. Once informed of their inclusion in the gateway, resource owners may also remember to notify us of changes in future as has already been the case!.
Although time-consuming, the spring clean is still a more efficient way of cleaning the data than each Section Editor having to trawl through every single record and its associated resource. Here we are relying on resource owners to notify us of incorrect data as well as new resources: they are the ones who know their resources best, and are best-placed to identify problems and changes.
If you are providing metadata which will be passed on to a JISC service for use in a service environment the JISC service may require that the metadata provided is still up-to-date and relevant. Alternatively the service may need to implement validation procedures similar to those described in this document.
In order to minimise the difficulties in deploying metadata created by project into a service environment, projects should ensure that they have appropriate mechanisms for checking their metadata. Ideally projects will provide documentation of their checking processes and audit trails which they can make available to the service which may host the project deliverables.
This document is based on an Ariadne article entitled "Planet SOSIG - A spring-clean for SOSIG: a systematic approach to collection management" originally written by Lesley Huxley, Emma Place, David Boyd and Phil Cross (ILRT). The article was edited for inclusion as a QA Focus case study by Brian Kelly (UKOLN) and Debra Hiom (ILRT).
Contact details for the corresponding authors is given below.
| Debra Hiom ILRT University of Bristol Bristol Email: d.hiom@bristol.ac.uk |
Brian Kelly UKOLN University of Bath BATH Email: b.kelly@ukoln.ac.uk |
Citation Details:
"Approaches To 'Spring Cleaning' At SOSIG",
by Debra Hiom, Lesly Huxley, Emma Place, David Boyd and Phil Cross (ILRT)
and Brian Kelly (UKOLN).
Published by QA Focus, the JISC-funded advisory service, on 17th October 2003.
Available at
<http://www.ukoln.ac.uk/qa-focus/documents/case-studies/case-study-25/>
This document was originally published as a "Planet SOSIG" column in the Ariadne ejournal.
[ Home Page - Surveys - Documents - Presentations - Search ]

Web page by Brian Kelly of UKOLN.
Last Modified 17-November-2003
Email comments to webmaster@ukoln.ac.uk
QA Focus Comments
This case study describe a project funding by the NOF-digitise programme. However the content of the case study should be of interest for anyone involved in making use of Dublin Core metadata.
Note that this case study was published in IM@T Online December 2003. (A username is required to access IM@T Online).