 [ Home Page - Surveys - Documents - Presentations - Search ]
[ Home Page - Surveys - Documents - Presentations - Search ]
The Exploit Interactive e-journal [1] was funded by the EU's Telematics For Libraries programme to disseminate information about projects funded by the programme. The e-journal was produced by UKOLN, University of Bath.
Exploit Interactive made use of Dublin Core metadata in order to provide enhanced local search facilities. This case study describes the approaches taken to the management and use of the metadata, difficulties experienced and lessons which have been learnt.
Metadata needed to be provided in order to provide richer searching than would be possible using standard free-text indexing. In particular it was desirable to allow users to search on a number of fields including Author, Title and Description
In addition it was felt desirable to allow users to restrict searches by issues by article type (e.g. feature article, regular article, news, etc.) and by funding body (e.g. EU, national, etc.) These facilities would be useful not only for end users but also by the editorial team in order to collate statistics needed for reports to the funders.
The metadata was stored in a article_defaults.ssi file which was held in the directory containing an article. The metadata was held as a VBscript assignment. For example, the metadata for the The XHTML Interview article [2] was stored as:
doc_title = "The XHTML Interview"
author="Kelly, B."
title="WebWatching National Node Sites"
description = "In this issue's Web Technologies column we ask Brian Kelly to tell us more about XHTML."
article_type = "regular"
This file was included into the article and converted into HTML <META> tags using a server-side include file.
Storing the metadata in a neutral format and then converting it into HTML <META> tags using a server-side script meant that the metadata could be converted into other formats (such as XHTML) by making a single alteration to the script.
It was possible to index the contents of the <META> tags using Microsoft's SiteServer software in order to provide enhanced search facilities, as illustrated below.
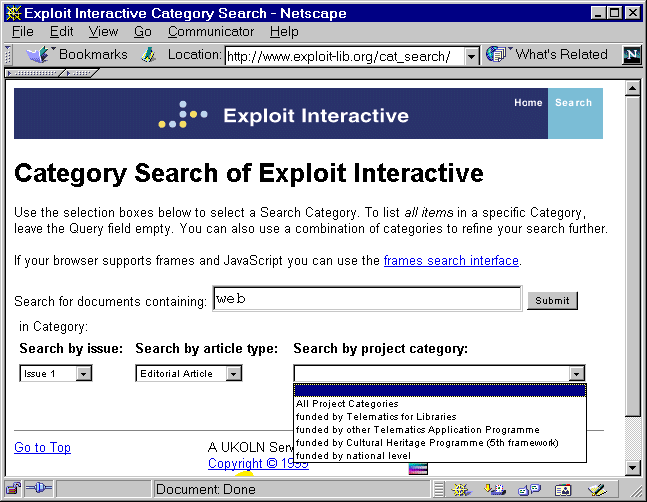
Figure 1: Standard Search Interface (click for enlarged view)
As illustrated in Figure 1 it is possible to search by issue, article type, project category, etc.
Alternative approaches to providing the search interface can be provided. An interface which uses a Windows-explorer style of interface is shown in Figure 2.
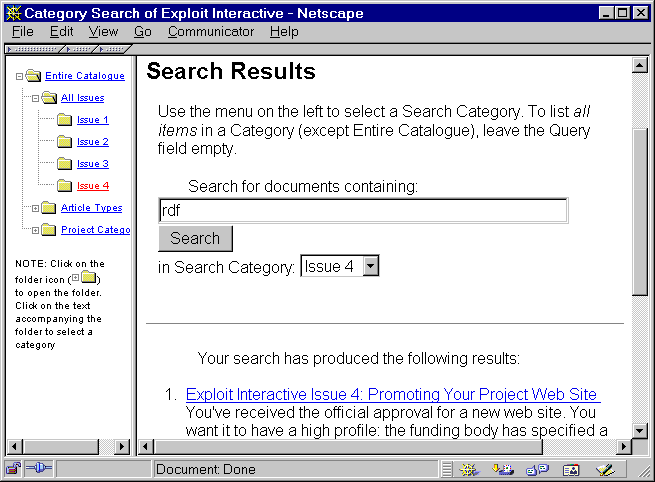
Figure 2: Alternative Search Interface (click for enlarged view)
Initially when we attempted to index the metadata we discovered that it was not possible to index <META> tags with values containing a full stop, such as <meta name="DC.Title" content="The XHTML Interview">.
However we found a procedure which allowed the <META> tags to be indexed correctly. We have documented this solution [3] and have also published an article describing this approach [4].
During the two year lifetime of the Exploit Interactive e-journal three editors were responsible for its publication. The different editors are likely to have taken slightly different approaches to the creation of the metadata. Although the format for the author's name was standardised (surname, initial) the approaches to creation of keywords, description, etc. metadata was not formally documented and so, inevitably, different approaches will have been adopted. In addition there was no systematic checking for the existence of all necessary metadata fields and so some may have been left blank.
The approaches which were taken provided a rich search service for our readers and enabled the editorial team to easily obtain management statistics. However if we were to start over again there are a number of changes we would consider making.
Although the metadata is stored in a neutral format which allows the format in which it is represented to be changed by updating a single server-side script, the metadata is closely linked with each individual article. The metadata cannot easily be processed independently of the article. It is desirable, for example, to be able to process the metadata for every article in a single operation - in order to, for example, make the metadata available in OAI format for processing by an OAI harvester.
In order to do this it is desirable to store the metadata in a database. This would also have the advantage of allowing the metadata to be managed and allow errors (e.g. variations of author's names, etc.) to be cleaned.
Use of a database as part of the workflow process would enable greater control to be applied for the metadata: for example, it would enable metadata such as keywords, article type, etc. to be chosen from a fixed vocabulary, thus removing the danger of the editor misspelling such entries.
Brian Kelly
UKOLN
University of Bath
BATH
Email: b.kelly@ukoln.ac.uk
[ Home Page - Surveys - Documents - Presentations - Search ]

Web page by Marieke Guy of UKOLN.
Last Modified 29-May-2005
Email comments to webmaster@ukoln.ac.uk
QA Focus Comments
Although the work described in this case study was funded by the European Commission, the approaches to management and use of metadata may be useful to projects which are addressing similar issues.
Citation Details
Managing And Using Metadata In An E-Journal, Kelly, B., QA Focus case study 01, UKOLN,
<http://www.ukoln.ac.uk/qa-focus/documents/case-studies/case-study-01/>
First published 25 October 2002.
Changes