 [ Home Page - Surveys - Documents - Presentations - Search ]
[ Home Page - Surveys - Documents - Presentations - Search ]
This page is for printing out all of the case studies. Note that some of the internal links may not work.
The Exploit Interactive e-journal [1] was funded by the EU's Telematics For Libraries programme to disseminate information about projects funded by the programme. The e-journal was produced by UKOLN, University of Bath.
Exploit Interactive made use of Dublin Core metadata in order to provide enhanced local search facilities. This case study describes the approaches taken to the management and use of the metadata, difficulties experienced and lessons which have been learnt.
Metadata needed to be provided in order to provide richer searching than would be possible using standard free-text indexing. In particular it was desirable to allow users to search on a number of fields including Author, Title and Description
In addition it was felt desirable to allow users to restrict searches by issues by article type (e.g. feature article, regular article, news, etc.) and by funding body (e.g. EU, national, etc.) These facilities would be useful not only for end users but also by the editorial team in order to collate statistics needed for reports to the funders.
The metadata was stored in a article_defaults.ssi file which was held in the directory containing an article. The metadata was held as a VBscript assignment. For example, the metadata for the The XHTML Interview article [2] was stored as:
doc_title = "The XHTML Interview"
author="Kelly, B."
title="WebWatching National Node Sites"
description = "In this issue's Web Technologies column we ask Brian Kelly to tell us more about XHTML."
article_type = "regular"
This file was included into the article and converted into HTML <META> tags using a server-side include file.
Storing the metadata in a neutral format and then converting it into HTML <META> tags using a server-side script meant that the metadata could be converted into other formats (such as XHTML) by making a single alteration to the script.
It was possible to index the contents of the <META> tags using Microsoft's SiteServer software in order to provide enhanced search facilities, as illustrated below.
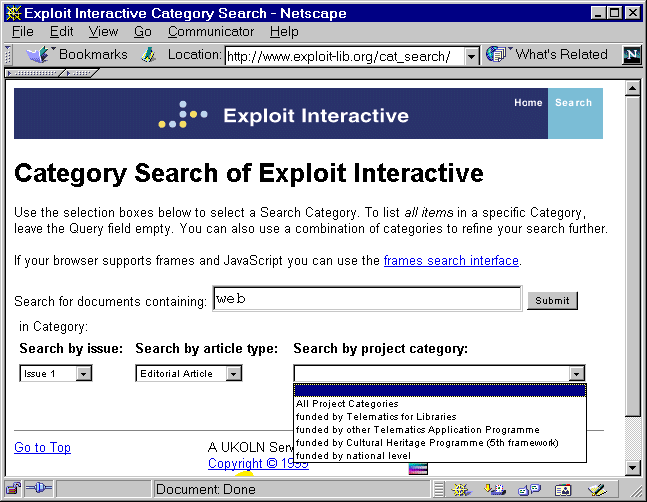
Figure 1: Standard Search Interface (click for enlarged view)
As illustrated in Figure 1 it is possible to search by issue, article type, project category, etc.
Alternative approaches to providing the search interface can be provided. An interface which uses a Windows-explorer style of interface is shown in Figure 2.
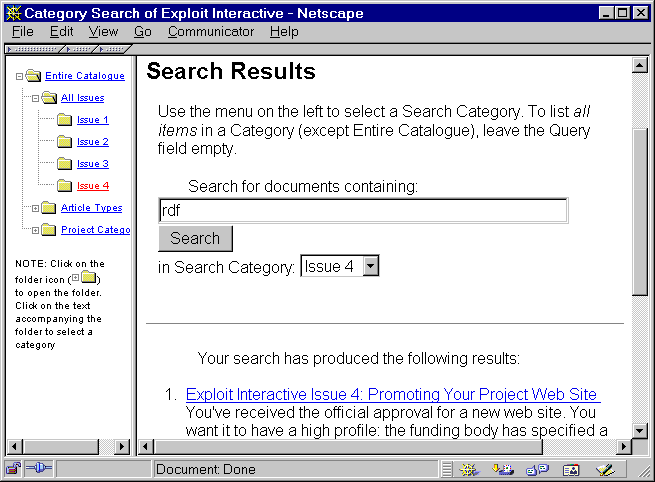
Figure 2: Alternative Search Interface (click for enlarged view)
Initially when we attempted to index the metadata we discovered that it was not possible to index <META> tags with values containing a full stop, such as <meta name="DC.Title" content="The XHTML Interview">.
However we found a procedure which allowed the <META> tags to be indexed correctly. We have documented this solution [3] and have also published an article describing this approach [4].
During the two year lifetime of the Exploit Interactive e-journal three editors were responsible for its publication. The different editors are likely to have taken slightly different approaches to the creation of the metadata. Although the format for the author's name was standardised (surname, initial) the approaches to creation of keywords, description, etc. metadata was not formally documented and so, inevitably, different approaches will have been adopted. In addition there was no systematic checking for the existence of all necessary metadata fields and so some may have been left blank.
The approaches which were taken provided a rich search service for our readers and enabled the editorial team to easily obtain management statistics. However if we were to start over again there are a number of changes we would consider making.
Although the metadata is stored in a neutral format which allows the format in which it is represented to be changed by updating a single server-side script, the metadata is closely linked with each individual article. The metadata cannot easily be processed independently of the article. It is desirable, for example, to be able to process the metadata for every article in a single operation - in order to, for example, make the metadata available in OAI format for processing by an OAI harvester.
In order to do this it is desirable to store the metadata in a database. This would also have the advantage of allowing the metadata to be managed and allow errors (e.g. variations of author's names, etc.) to be cleaned.
Use of a database as part of the workflow process would enable greater control to be applied for the metadata: for example, it would enable metadata such as keywords, article type, etc. to be chosen from a fixed vocabulary, thus removing the danger of the editor misspelling such entries.
Brian Kelly
UKOLN
University of Bath
BATH
Email: b.kelly@ukoln.ac.uk
The FAILTE project [1] was funded by JISC to provide a service which engineering lecturers in higher education could use to identify and locate electronic learning resources for use in their teaching. The project started in August 2000. One of the first tasks was to set up a project Web site describing the aims, progress and findings of the project and the people involved.
Figure 1: The FAILTE home page
As an experienced Web author I decided to use this opportunity to experiment with two specifications which at that time were relatively new, namely cascading style sheets (CSS) and HTML. At the same time I also wanted to create pages which looked reasonably attractive on the Web browsers in common use (including Netscape 4.7 which has poor support for CSS) and which would at least display intelligible text no matter what browser was used.
Here is not the place for a detailed discussion of the merits of separating logical content markup from formatting, but I will say that I think that, since this is how HTML was envisaged by its creators, it works best when used in this way. Some of the reasons at the time of starting the Web site were:
A quick investigation of the Web server log files from a related server which dealt with the same user community as our project targeted lead us to the decision that we should worry about how the Web site looked on Netscape 4.7, but not browsers with poorer support of XHTML and CSS (e.g. Netscape 4.5 and Internet Explorer 3).
The Web site was a small one, and there would be one contributor: me. This meant that I did not have to worry about the lack of authoring tools for XHTML at the time of setting up the Web site. I used HomeSite version 4.5, a text editor for raw HTML code, mainly because I was familiar with it. Divisions (<div> tags) were used in place of tables to create areas on the page (a banner at the top, a side bar for providing a summary of the page content), graphics were used sparingly, and colour was used to create a consistent and recognisable look across the site. It is also worth noting that I approached the design of the Web site with the attitude that it I could not assume that it would be possible to control layout down to the nearest point.
While writing the pages I tested mainly against Netscape 4.7, since this had the poorest support for XHTML and CSS . I also made heavy use of the W3C XHMTL and CSS validation service [2], and against Bobby [3] to check for accessibility issues. Once the code validated and achieved the desired effect in Netscape 4.7 I checked the pages against a variety of browser platforms.
While it was never my aim to comply with a particular level of accessibility, the feedback from Bobby allowed me to enhance accessibility while building the pages.
Most of the problems stemmed from the need to support Netscape 4.7, which only partially implements the CSS specification. This cost time while I tried approaches which didn't work and then looked for work-around solutions to achieve the desired effect. For example, Netscape 4.7 would render pages with text from adjacent columns overlapping unless the divisions which defined the columns had borders. Thus the <div> tags have styles which specify borders with border-style: none; which creates a border but doesn't display it.
The key problem here is the partial support which this version of Netscape has for CSS: older versions have no support, and so the style sheet has no effect on the layout, and it is relatively easy to ensure that the HTML without the style sheet makes sense.
Another problem was limiting the amount of white space around headings. On one page in particular there were lots of headings and only short paragraphs of text. Using the HTML <h1>, <h2>, <h3>, etc. tags left a lot of gaps and led to a page which was difficult to interpret. What I wanted to do was to have a vertical space above the headings but not below. I found no satisfactory way of achieving this using the standard heading tags which worked in Netscape 4.7 and didn't cause problems in other browsers. In the end, I created class styles which could be applied to a <span> to give the effect I wanted e.g.:
<p><span class="h2">Subheading</span><br />
Short paragraph</p>
This was not entirely satisfactory since any indication that the text was a heading is lost if the browser does not support CSS.
The Web site is now two years old and in that time I have started using two new browsers. I now use Mozilla as my main browser and was pleasantly surprised that the site looks better on that than on the browsers which I used while designing it. The second browser is an off-line Web page viewer which can be used to view pages on a PDA, and which makes a reasonable job rendering the FAILTE Web site - a direct result of the accessibility of the pages, notably the decision not to use a table to control the layout of the page. This is the first time that the exhortation to write Web sites which are device-independent has been anything other than a theoretical possibility for me (remember WebTV?)
I think that it is now much easier to use XHTML and CSS since the support offered by authoring tools is now better. I would also reconsider whether Netscape 4.7 was still a major browser: my feeling is that while it still needs supporting in the sense that pages should be readable using it, I do not think that it is necessary to go to the effort of making pages look attractive. In particular I would not create styles which imitated <Hn> in order to modify the appearance of headings. I look forward to the time when it is possible to write a page using standard HTML repertoire of tags without any styling so that it makes sense as formatted text, with clear headings, bullet lists etc., and then to use a style sheet to achieve the graphical effect which was desired.
 Phil Barker
Phil Barker
ICBL
MACS
Heriot-Watt University
Edinburgh
Email: philb@icbl.hw.ac.uk
URL: http://www.icbl.hw.ac.uk/~philb/
Citation Details:
"Standards and Accessibility Compliance for the FAILTE Project Web Site",
by Phil Barker, Heriot-Watt University.
Published by QA Focus, the JISC-funded
advisory service, on 4th November 2002.
Available at http://www.ukoln.ac.uk/qa-focus/documents/case-studies/case-study-02/
The FAILTE project was funded by the JISC's 5/99 programme.
In a number of surveys of JISC 5/99 project Web sites carried out in October / November 2002 the FAILTE Web site was found to (a) comply with XHTML standards, (b) comply with CSS standards and (c) comply with WAI AA accessibility guidelines.
Brian Kelly, QA Focus, 4 November 2002
Standards and Accessibility Compliance for the FAILTE Project Web Site,
Barker, P., QA Focus case study 02, UKOLN,
<http://www.ukoln.ac.uk/qa-focus/documents/case-studies/case-study-02/>
First published November 2002.
![]() The RDN's Subject Portals Project
(SPP) is funded under the
JISC's DNER Development Programme.
There were two proposals, SAD I
(Subject Access to the DNER) and SAD II.
The original SAD I proposal was part of a closed JISC DNER call, 'Enhancing JISC
Services to take part in the DNER'. The SAD II proposal was successful under
the JISC 5/99 call, 'Enhancing the DNER for Teaching and Learning'.
The original project proposals are available [1].
The RDN's Subject Portals Project
(SPP) is funded under the
JISC's DNER Development Programme.
There were two proposals, SAD I
(Subject Access to the DNER) and SAD II.
The original SAD I proposal was part of a closed JISC DNER call, 'Enhancing JISC
Services to take part in the DNER'. The SAD II proposal was successful under
the JISC 5/99 call, 'Enhancing the DNER for Teaching and Learning'.
The original project proposals are available [1].
The aim of the project is to improve the functionality of five of the RDN hub sites to develop them into subject portals. Subject portals are filters of Web content that present end users with a tailored view of the Web within a particular subject area. In order to design software tools that simultaneously satisfy the needs of a variety of different sites and make it easier for institutional portals to embed our services in the future, we are designing a series of Web "portlets". One portlet will be built for each of the key portal functions required, focussing initially on authorisation and authentication (account management); cross-searching; and user profiling; but including eventually a range of "additional services" such as news feeds, jobs information, and details of courses and conferences. The project is committed to using open source software wherever possible.
The hub sites involved in the SPP are EEVL (based at Heriot Watt University, Edinburgh), SOSIG (University of Bristol), HUMBUL (University of Oxford); BIOME (University of Nottingham) and PSIGate (University of Manchester). The project is managed from UKOLN based at the University of Bath, and the technical development is led from ILRT at the University of Bristol.
The fact that the SPP partners are geographically dispersed has posed a number of challenges. Since the objective of the SPP is the enhancement of the existing hub sites, hub representatives have naturally wished to be closely involved, both on the technical and on the content management sides of the project. At the last count, 38 people are involved in the project, devoting to it varying percentages of their time. But this means that physical meetings are difficult to organise and costly: since work began in December 1999 on the SAD II project, only two full project meetings have been held, with another planned for the beginning of 2003. Smaller physical meetings have been held by the technical developers at ILRT and the five hubs, but these again are extremely time-consuming.
We also faced the problem that many of the project partners had never worked together before. Not only was this a challenge on a social level, it was also likely to prove difficult to find where the skills and experience (and software preferences) of the developers overlapped, and at the beginning of 2002, the then project manager Julie Stuckes commissioned a skills audit to discover the range and extent of these skills and where the disparities lay. It was also likely to be hard to keep track at the project centre of the different development activities taking place in order to produce a single product, and to reduce the risk of duplicating effort, or worse, producing incompatible work. We also thought moreover that it was desirable to develop a method of describing the technical work involved in the project in a way easily understood by the content managers and non-technical people outside of the project.
We tackled the problem of communication across the project by the use of a project JISCmail mailing list [2]. The list is archived on the private version of the SPP Web site [3] where other internal documents are also posted.
The developers have their own list (spp-dev@dev.portal.ac.uk) and their own private Web site [4] which is stored in a versioning system (CVS - Concurrent Version System [5]) which gives any authenticated user the ability to update the site remotely.
In addition the developers hold weekly live chat meetings using IRC (Internet Relay Chat [6]) software (as shown in Figure 1), the transcripts of which are logged and archived on the developers' Web site.
Using IRC means the developers are able to keep each other informed of their activities in a relaxed and informal manner; this has aided closer working relationships.
Figure 1: Example IRC Session
As well as holding the developers' Web site, CVS also contains the project's source code and build environment. This takes the form of a central repository into and out of which developers check code remotely, ensuring that their local development environments are kept in step. A Web interface also provides the option of browsing the code, as well as reviewing change histories. Automatic e-mail notification alerts the developers to updates checked into the CVS repository, and all changes are also logged. This has proved an essential tool when co-ordinating distributed code development.
The other part of the software development infrastructure is providing a build environment that takes care of standard tasks, allowing the team members to concentrate on their coding. Using a combination of open-source tools (e.g. ant [7] and junit [8]) a system has been created that allows the developer to build their code automatically, run tests against it, and then configure and deploy it into their test server. As well as this, the build system will also check for new versions of third-party packages used by the project, updating them automatically if necessary. This system is also managed by current project down from the central repository, build, configure and deploy it, having it running in a matter of minutes.
Because of the widely dispersed team, the difference in software preferences and the mixed technical ability across the project, we looked around for a design process that would best record and standardise our requirements. UML (Unified Modelling Language [9]) is now a widely accepted standard for object oriented modeling, and we chose it because we felt it produced a design that is clear and precise, so making it easy to understand for technical and non-technical minds alike. UML gave us a means to visualise and integrate use cases, integration diagrams and class models. Moreover using UML modelling tools, it was possible to generate code from the model or update the model whenever the code was further developed.
Figure 2: Example UML Diagram
Finding UML software that had all the features needed was a problem: there are plenty of products available but none quite met all our requirements, especially when it came to synchronising the work being done by different authors. Eventually we opted to use the ICONIX process [10]. This is a simplified approach to UML modeling, which uses a core subset of diagrams. This enabled us to move from use cases to code quickly and efficiently using a minimum number of steps, thus giving the technical side of the project a manageable coding cycle.
Additional funding was obtained from the JISC in order to bring one of the authors of the ICONIX process (Doug Rosenberg) over from California to run a three day UML training course. Although this course was specially designed for SPP, places were offered to other 5/99 projects in order to promote wider use of this methodology across the JISC community. Unfortunately, despite early interest, no other project was represented at the training, although Andy Powell, the technical co-ordinator for the RDN, attended the course. Additional funding was also received from the JISC to purchase licences for Rational Rose [11], which we had identified as the most effective software available to produce the design diagrams
Finally, to provide greater structure to the project, a timetable of activities produced using MS Project is posted on the private project Web site and is kept continually up to date. A message is posted to the project mailing list to alert partners of any major changes to the timetable.
It would have been sensible for us to have adopted a process for software development at an earlier stage in the project: it was perhaps a need that we could have anticipated during the SAD I project phase. Also, it is worth noting from our experiences that getting the communications and technical support infrastructure in place is a job in itself, and should be built into the initial planning stage of any large and dispersed project.
Electronic communication is still no substitute for face-to-face meetings so the SPP development team continue to try to meet as regularly as possible. Time is inevitably a major problem wherever project partners have other work commitments: all the project partners based at the hub sites have to juggle SPP work which is for the project as a whole, with that which relates particularly to their own hub's adoption of the project's outcomes. Increasingly, as the project develops, less work will be required from the project "centre" and more at the hubs, leading to an eventual handover of the subject portal developments to the hubs for future management.
It is our plan to make use of UML diagrams in the final project documentation to describe the design and development process. They will offer a detailed explanation of our decision making throughout the project and will give future projects an insight into our methodology. Andy Powell was also so impressed with UML that he is planning to use it across development work for the RDN in the future.
The future development of the SPP beyond the end of the project is likely to be led by the technical development partners, for instance in the continued development of the portlets to enable them to be installed into alternative open source software platforms to make the technology as compatible with existing systems as possible. It is therefore greatly to the benefit of the project that they have become such an effective and close working team.
Ruth Martin, SPP Project Manager
UKOLN
University of Bath
Bath
BA2 7AY
Email: r.martin@ukoln.ac.uk
Jasper Tredgold, SPP Technical Co-ordinator
ILRT
University of Bristol
10 Berkeley Square
Bristol
BS8 1HH
Email: jasper.tredgold@bris.ac.uk
The SPP project (initially known as SAD I and then SAD II) was funded by the JISC's 5/99 programme.
Brian Kelly, QA Focus, 4 November 2002
Managing a Distributed Development Project: The Subject Portals Project,
Martin, R. and Tredgold, J., QA Focus case study 03, UKOLN,
<http://www.ukoln.ac.uk/qa-focus/documents/case-studies/case-study-03/>
First published 4th November 2002.
e-MapScholar, a JISC 5/99 funded project, aims to develop tools and learning and teaching materials to enhance and support the use of geo-spatial data currently available within tertiary education in learning and teaching, including digital map data available from the EDINA Digimap service. The project is developing:
The Disability Discrimination Act (1995) (DDA) aimed to end discrimination faced by many disabled people. While the DDA focused mainly on the employment and access to goods and services, the Special Education Needs and Disability Act (2001) (SENDA) amended the DDA to include education. The learning and teaching components of SENDA came into force in September 2002. SENDA has repercussions for all projects producing online learning and teaching materials for use in UK education because creating accessible materials is now a requirement of the JISC rather than a desirable project deliverable.
This case study describes how the e-MapScholar team has addressed accessibility in creating the user interfaces for the learning resource centre, case studies, content management system and virtual placement.
Figure 1: Screenshot of the case study index |
Figure 2: Screenshot of the learning resource centre resource selection page |
Figure 3: Screenshot of the content management system |
Figure 4: Screenshot of the Virtual Placement (temporary - still under development) |
An accessible Web site is a Web site that has been designed so that virtually everyone can navigate and understand the site. A Web site should be informative, easy to navigate, easy to access, quick to download and written in a valid hypertext mark up language. Designing accessible Web sites benefits all users, not just disabled users.
Under SENDA the e-MapScholar team must ensure that the project deliverables are accessible to users with disabilities including mobility, visual or audio impairments or cognitive/learning issues. These users may need to use specialist browsers (such as speech browsers) or configure their browser to enhance the usability of Web sites (e.g. change font sizes). It is also a requirement of the JISC funding that the 5/99 projects should reach at least priority 1 and 2 of the Web Accessibility Initiative (WAI) standards and where appropriate, priority 3.
The project has been split into four major phases:
While the CMS and learning units are inter-connected, the other components can exist separately from one another.
The project has employed a simple and consistent design in order to promote coherence and also to ease navigation of the site. Each part employs similar headings, navigation and design.
The basic Web design was developed within the context of the learning units and was then adapted for the case studies and virtual placement.
Summaries, learning objectives and pre-requisites are provided where necessary.
Links to help page are provided. The help page will eventually provide information on navigation, how to use the interactive tools and FAQ in the case of learning units and details of any plug-ins/software used in the case studies.
Font size will be set to be resizable in all browsers.
Verdana font has been used as this is considered the most legible font face.
CSS (Cascading style sheets) have been used to control the formatting of text; this cuts out the use of non-functional elements, which could interfere with text reader software.
Navigation has been used in a consistent manner.
All navigational links are in standard blue text.
All navigation links are text links apart from the learning unit progress bar, which is made up of clickable images. These images include an ALT tag describing the text alternative.
The progress bar provides a non-linear pathway through the learning units, as well as providing the user with an indication of their progress through the unit.
The link text used can be easily understood when out of context, e.g. "Back to Resource" rather than "click here".
'Prev' and 'Next' text links provide a simple linear pathway through both the learning units and the case studies.
All links are keyboard accessible for non-mouse users and can be reached by using the tab key.
Where possible the user is offered a choice of pathway through the materials e.g. the learning units can be viewed as a long scrolling page or page-by-page chunks.
Web safe colours have been used in the student interface.
The interface uses a white background ensuring maximum contrast between the black text, and blue navigational links.
Very few graphics have been used in the interface design to minimise download time.
Content graphics and the project logo have ALT tags providing a textual description.
Long descriptions will be incorporated where necessary.
Graphics for layout will contain "" (i.e. null) ALT tags so they will be ignored by text reader software.
Tables have been used for layout purposes complying with W3C standards; not using structural mark-up for visual formatting.
HTML 4.0 standards have been complied with.
JavaScript has been used for the pop-up help menu, complying with JavaScript 1.2 standards.
The user is explicitly informed that a new window is to be opened.
The new window is set to be smaller so that it is easily recognised as a new page.
Layout is compatible with early version 4 browsers, both in Netscape, Internet Explorer and Opera.
Specific software or plug-ins are required to view some of the case study materials e.g. GIS or AutoCAD software has been used in some of the case studies. Users will be advised of these and where possible will be guided to free viewers. Where possible the material will be provided in an alternative format such as screen shots, which can be saved as an image file.
Users are warned when non-HTML documents (e.g. PDF or MS Word) are included in the case studies and where possible documents are also provided in HTML format.
Problems experienced have generally been minor.
Throughout the project accessibility has been thought of as an integral part of the project and this approach has generally worked well. Use of templates and CSS have helped in minimising workload when a problem has been noted and the materials updated.
It is important that time and thought goes into the planning stage of the project as it is easier and less time consuming to adopt accessible Web design in an early stage of the project than it is to retrospectively adapt features to make them accessible.
User feedback from evaluations, user workshops and demonstrations has been extremely useful in identifying potential problems.
Deborah Kent
EDINA National Data Centre
St Helens Office
ICT Centre
St Helens College
Water St
ST HELENS
WA10 1PZ
Email: dkent@ed.ac.uk
Lynne Robertson
Geography
School of Earth, Environmental and Geographical Sciences
The University of Edinburgh
Drummond Street
Edinburgh EH8 9XP
Email: lr@geo.ed.ac.uk
For QA Focus use.
Creating Accessible Learning And Teaching Resources: The e-MapScholar Experience,
Kent, D. and Robertson, L., QA Focus case study 04, UKOLN,
<http://www.ukoln.ac.uk/qa-focus/documents/case-studies/case-study-04/>
First published November 2002.
The e-MapScholar project [1] aims to develop tools and learning and teaching materials to enhance and support the use of geo-spatial data currently available within tertiary education in learning and teaching, including digital map data available from the EDINA Digimap service [2]. These tools and learning materials will be delivered over the Web and will be accessed from a repository of materials branded the "Learning Resource Centre".
The project is funded by the JISC [3] to form part of the DNER, now called the Information Environment [4] and works closely with other projects funded under the same programme.
From the outset of the e-MapScholar Project it was apparent that various standards needed to be agreed upon and conformed to. The two core issues were:
In reaching a broad community of users, a compromise needed to be found between delivery of service to 'low spec' PCs and high-end functionality that would support interactive tools. A range of technical discussions at the outset of the project discussed these implications in the context of choice of standards and technical evaluation criteria.
The various technical elements and their respective standards were specified at the start of the project. These included the use of Java 1.1 for the interactive applets (see Figure 1), and Javascript 1.2 and HTML 4.01 for the user interface. All learning material content would be stored in XML files which would be transformed using XSLT and Java. Similarly, authors of learning materials would also be provided with a set of guidelines for producing the content.
Figure 1: Screen shots of interactive tools produced by e-MapScholar
All software components were written in Java 1.1. All code has and remains fully compliant with this version. Though Java 1.1 does not have as much functionality as later versions e.g. 1.2 and 1.3, it makes the service compliant with a broader choice of browsers and operating systems. Java code was also written to control the conversion of XML into HTML.
HTML 4.01 is used for the layout of the learning resource centre pages. Using HTML standards ensure that the site is more accessible to a wider range of browsers, and is transformed more quickly and easily. The use of client-side JavaScript has been kept to a minimum and only used for pop-up window items such as the help menu and map legends. These are all written in JavaScript 1.2. Using this version of JavaScript again reflected a compromise between control of graphics and levels of interaction, and compatibility with browsers and operating systems.
Authors providing content to the learning units have been issued with a document containing guidance notes. This document aims to standardise the content of the learning units, by providing procedures on how various elements of the units should be written. These elements include guidelines on the structuring of a unit, wording of learning objectives and quiz tools, and the acceptable formats for images and photographs. Complying with these guidelines will ensure the pedagogical aspect of the units meet teaching requirements and are suitable for students across a range of abilities.
The imposition of all of the above standards increased the chances of interoperability between the various units and modules comprising the service.
The use of Java 1.1 should ensure that users do not have to download the plug-in as the majority of browsers come packaged with this version of Java Virtual Machine installed (or higher). However, last year Microsoft launched their latest version of Internet Explorer (6.0) without a Java VM. This means that users of IE 6 will have to download a Java plug-in to run any Java applets, regardless of what version of Java the applets have been created with.
Web statistics [5] (illustrated in Figure 2) show that Internet Explorer is the most widely used Web browser, with IE 6 already accounting for a considerable portion of this usage. This means that 48% of Internet users will have to download the Java plug-in order to run any Java applets.
Figure 2: Pie chart of browser statistics generated using data from
[6]
With many users upgrading to the new service in the future, one might question the point in using Java 1.1 when the majority of Internet users will still have to download the plug-in? Ideally, standards should be employed with the majority of users in mind.
At the outset we chose Java 1.1 since it was incorporated in Internet Explorer and the majority of other browsers, and would not involve users having to download the plug-in. It is estimated that 48% of web users are using IE6, all of whom will need to download the Java plug-in. Our ambition of 'use without plug-in' has somewhat evaporated, and an argument could now be made that we could ask users to download other plug-ins, notably 'Flash'. Ironically IE6 users would not need to download Flash player as it comes ready packaged in IE6.
If Flash were used (in conjunction with Java 1.1) it would allow greater levels of interaction with the user, and easier development of visualisation tools. However, this would have required access to Flash developers which the project does not have at this stage. Currently no decision has been made on whether it is worth taking advantage of the additional functionality afforded by Flash player, but it does open a door, which was previously thought to be firmly closed.
On the whole, throughout the project, various software engineering problems have arisen. But broad agreement on the use of standards coupled with clarification of system requirements, and requirement specifications has helped to keep the project manageable from a software engineering prospective.
Lynne Robertson
Geography
School of Earth, Environmental and Geographical Sciences
The University of Edinburgh
Drummond Street
Edinburgh EH8 9XP
Email: lr@geo.ed.ac.uk
For QA Focus use.
Standards for e-learning: The e-MapScholar Experience,
Robertson, L., QA Focus case study 05, UKOLN,
<http://www.ukoln.ac.uk/qa-focus/documents/case-studies/case-study-05/>
The document was published in November 2002.
The NMAP project [1] was funded under the JISC 05/99 call for proposals to create the UK's gateway to high quality Internet resources for nurses, midwives and the allied health professions.
NMAP is part of the BIOME Service, the health and life science component of the national Resource Discovery Network (RDN), and closely integrated with the existing OMNI gateway. Internet resources relevant to the NMAP target audiences are identified and evaluated using the BIOME Evaluation Guidelines. If resources meet the criteria they are described and indexed and included in the database.
NMAP is a partnership led by the University of Nottingham with the University of Sheffield and Royal College of Nursing (RCN). Participation has also been encouraged from several professional bodies representing practitioners in these areas. The NMAP team have also been closely involved with the professional portals of the National electronic Library for Health (NeLH).
The NMAP service went live in April 2001 with 500 records. The service was actively promoted in various journal, newsletters, etc. and presentations or demonstrations were given at various conference and meetings. Extensive use was made of electronic communication, including mailing lists and newsgroups for promotion.
Work in the second year of the project included the creation of two VTS tutorials: the Internet for Nursing, Midwifery and Health Visiting, and the Internet for Allied Health.
As one of the indicators of the success, or otherwise, in reaching the target group we wanted to know how often the NMAP service was being used, and ideally who they are and how they are using it.
The idea was to attempt to ensure we were meeting their needs, and also gain data which would help us to obtain further funding for the continuation of the service after the end of project funding.
There seems to be little standardisation of the ways in which this sort of data is collected or reported, and although we could monitor our own Web server, the use of caching and proxy servers makes it very difficult to analyse how many times the information contained within NMAP is being used or where the users are coming from.
These difficulties in the collection and reporting of usage data have been recognised elsewhere, particularly by publishers of electronic journals who may be charging for access. An international group has now been set up to consider these issues under the title of project COUNTER [2] which has issued a "Code of Practice" on Web usage statistics. In addition QA Focus has published a briefing document on this subject [3].
We took a variety of approaches to try to collect some meaningful data. The first and most obvious of these is log files from the server which were produced monthly and gave a mass of data including:
A small section of one of the log files showing the general summary for November 2002 can be seen below. Note that figures in parentheses refer to the 7-day period ending 30-Nov-2002 23:59.
Successful requests: 162,910 (39,771) Average successful requests per day: 5,430 (5,681) Successful requests for pages: 162,222 (39,619) Average successful requests for pages per day: 5,407 (5,659) Failed requests: 2,042 (402) Redirected requests: 16,514 (3,679) Distinct files requested: 3,395 (3,217) Unwanted logfile entries: 51,131 Data transferred: 6.786 Gbytes (1.727 Gbytes) Average data transferred per day: 231.653 Mbytes (252.701 Mbytes)
A graph of the pages served can be seen in Figure 1.
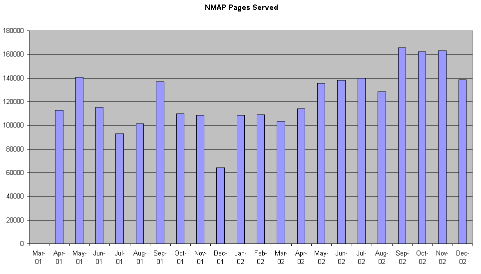
Figure 1: Pages served per month
The log files also provided some interesting data on the geographical locations and services used by those accessing the NMAP service.
Listing domains, sorted by the amount of traffic, example from December 2002, showing those over 1%.
| Requests | % bytes | Domain |
| 48237 | 31.59% | .com (Commercial) |
| 40533 | 28.49% | [unresolved numerical addresses] |
| 32325 | 24.75% | .uk (United Kingdom) |
| 14360 | 8.52% | ac.uk |
| 8670 | 7.29% | nhs.uk |
| 8811 | 7.76% | .net (Network) |
| 1511 | 1.15% | .edu (USA Educational) |
A second approach was to see how many other sites were linking to the NMAP front page URL. AltaVista was used as it probably had the largest collection back in 2000 although this has now been overtaken by Google. A search was conducted each month using the syntax: link:http://nmap.ac.uk and the results can be seen in Figure 2.
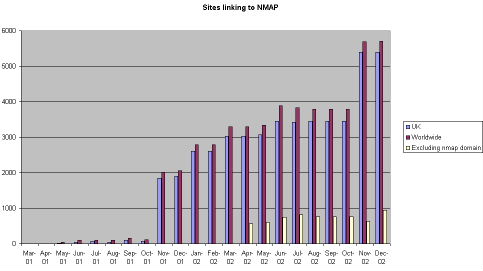
Figure 2 - Number of sites linking to NMAP (according to AltaVista)
The free version of the service provided by InternetSeer [4] was also used. This service checks a URL every hour and will send an email to one or more email addresses saying if the site is unavailable. This service also provides a weekly summary by email which, along with the advertising includes a report in the format:
========================================
Weekly Summary Report
========================================
http://nmap.ac.uk
Total Outages: 0.00
Total time on error: 00:00
Percent Uptime: 100.0
Average Connect time*: 0.13
Outages- the number of times we were unable to access this URL
Time on Error- the total time this URL was not available (hr:min)
% Uptime- the percentage this URL was available for the day
Connect Time- the average time in seconds to connect to this URL
During the second year of the project we also conducted an online questionnaire with 671 users providing data about themselves, why they used NMAP and their thoughts on its usefulness or otherwise, however this is beyond the scope of this case study and is being reported elsewhere.
Although these techniques provided some useful trend data about the usage of the NMAP service there are a series of inaccuracies, partly due to the nature of the Internet, and some of the tools used.
The server log files are produced monthly (a couple of days in areas) and initially included requests from the robots used by search engines, these were later removed from the figures. The resolution of the domains was also a problem with 28% listed as "unresolved numerical addresses" which gives no indication where the users is accessing from. In addition it is not possible to tell whether .net or .com users are in the UK or elsewhere. The number of accesses from .uk domains was encouraging and specifically those from .ac & .nhs domains. It is also likely (from data gathered in our user questionnaire) that many of the .net or .com users are students or staff in higher or further education or NHS staff who accessing the NMAP service via a commercial ISP from home.
In addition during the first part of 2002 we wrote two tutorials for the RDN Virtual Training Suite (VTS) [5], which were hosted on the BIOME server and showed up in the number of accesses. These were moved in the later part of 2002 to the server at ILRT in Bristol and therefore no longer appear in the log files. It has not yet been possible to get access figures for the tutorials.
The "caching" of pages by ISPs and within .ac.uk and .nhs.uk servers does mean faster access for users but probably means that the number of users in undercounted in the log files.
The use of AltaVista "reverse lookup" to find out who was linking to the NMAP domain was also problematic. This database is infrequently updated which accounts from the jumps seen in Figure 2. Initially when we saw a large increase in November 2001 we thought this was due to our publicity activity and later realised that this was because it included internal links within the NMAP domain in this figure, therefore from April 2002 we collected another figure which excluded internal links linking to self.
None of these techniques can measure the number of times the records from within NMAP are being used at the BIOME or RDN levels of JISC services. In addition we have not been able to get regular data on the number of searches from within the NeLH professional portals which include an RDNi search box [6] to NMAP.
In the light of our experience with the NMAP project we recommend that there is a clear strategy to attempt to measure usage and gain some sort of profile of users of any similar service.
I would definitely use Google rather than AltaVista and would try to specify what is needed from log files at the outset. Other services have used user registration and therefore profiles and cookies to track usage patterns and all of these are worthy of consideration.
 Rod Ward
Rod Ward
Lecturer, School of Nursing and Midwifery,
University of Sheffield
Winter St.
Sheffield
S3 7ND
Email: Rod.Ward@sheffield.ac.uk
Also via the BIOME Office:
Greenfield Medical Library
Queen's Medical Centre,
Nottingham NG7 2UH
Email: rw@biome.ac.uk
Gathering Usage Statistics and Performance Indicators: The NMAP Experience,
Ward, R., QA Focus case study 06, UKOLN,
<http://www.ukoln.ac.uk/qa-focus/documents/case-studies/case-study-06/>
This document was published on 8th January 2003.
![]() Artworld [1] is a consortium project funded by JISC
under the 5/99 funding round. The consortium consists of The Sainsbury Centre
for Visual Arts (SCVA) at
The University of East Anglia (UEA)
and the Oriental Museum at the University of Durham.
Artworld [1] is a consortium project funded by JISC
under the 5/99 funding round. The consortium consists of The Sainsbury Centre
for Visual Arts (SCVA) at
The University of East Anglia (UEA)
and the Oriental Museum at the University of Durham.
The main deliverable for the project is its Web site which will include a combined catalogue of parts of the two collections and a set of teaching resources.
Object images are being captured using digital photography at both sites and some scanning at SCVA. Object data is being researched at both sites independently and is input to concurrent Microsoft Access databases. Image data is captured programmatically from within the Access database. Object and image data are exported from the two independent databases and checked and imported into a Postgres database for use within the catalogue on the Web site.
There are four teaching resources either in development or under discussion. These are African Art and Aesthetics, Egyptian Art and Museology, An Introduction to Chinese art and Japanese Art. These resources are being developed by the department of World Art Studies and Museology at UEA, The department of Archaeology, Durham and East Asian Studies, University of Durham respectively. The Japanese module is currently under negotiation. These resources are stored as simple XML files ready for publication to the Web.
The target audience in the first instance are undergraduate art history, anthropology and archaeology students. However, we have tried to ensure that the underlying material is structured in such a way that re-use at a variety of levels, 16 plus to post graduate is a real possibility. We hope to implement this during the final year of the project by ensuring conformance with IMS specifications.
In the early days of the project we were trying very hard to find an IT solution that would not only fulfill the various JISC requirements but would be relatively inexpensive. After a considerable amount time researching various possibilities we selected Apache's Cocoon system as our Web publishing engine. To help us implement this we contracted a local internet applications provider Luminas [2].
The Cocoon publishing framework gives us an inexpensive solution in that the software is free so we can focus our resources on development.
One area that we had inadvertently missed during early planning was how we represent copyright for the images whilst providing some level of protection. We considered using watermarking however this would have entailed re-processing a considerable number of images at a time when we had little resource to spare.
This issue came up in conversation with Andrew Savory of Luminas as early notification that all of the images already transferred to the server and in use through Cocoon would need to be replaced. As we talked about the issues Andrew presented a possible solution, why not insert copyright notices into the images "on the fly". This would be done using a technology called SVG (Scalable Vector Graphics). What SVG could do for us is to respond to a user request for an image by combining the image with the copyright statement referenced from the database and present the user with this new combined image and copyright statement.
We of course asked Luminas to proceed with this solution. The only potential stumbling block was how we represent copyright from the two institutions in a unified system. The database was based on the VADS/VRA data schema so we were already indicating the originating institution in the database. It was then a relatively simple task to include a new field containing the relevant copyright statements.
It should be noted that a composite JPEG (or PNG, GIF or PDF) image is sent to the end user - there is no requirement for the end user's browser to support the PNG format. The model for this is illustrated in Figure 1.
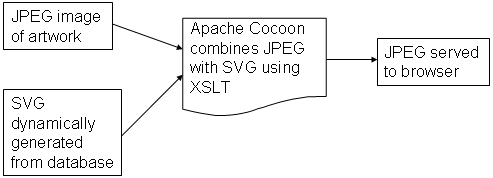
Figure 1: Process For Creating Dynamic Images
Although in this case we ended up with an excellent solution there are a number of lessons that can be derived from the sequence of events. Firstly the benefits of detailed workflow planning in the digitisation process cannot be understated. If a reasonable solution (such as water marking) had been planed into the processes from the start then a number of additional costs would not have been incurred. These costs include project staff time in discussing solutions to the problem, consultancy costs to implement a new solution. However, there are positive aspects of these events that should be noted. Ensuring that the project has a contingency fund ensures that unexpected additional costs can be met. Close relations with contractors with free flow of information can ensure that potential solutions can be found. Following a standard data schema for database construction can help to ensure important data isn't missed. In this case it expedited the solution.
Cocoon [3] is an XML Publishing Framework that allows the possibility of including logic in XML files. It is provided through the Apache software foundation.
SVG (Scalable Vector Graphics) [4] [5] is non proprietary language for describing two dimensional graphics in XML. It allows for three types of objects: vector graphic shapes; images and text. Features and functions include: grouping, styling, combining, transformations, nested transformations, clipping paths, templates, filter effects and alpha masks.
Paul Child
ARTWORLD Project Manager
Sainsbury Centre for Visual Arts
University of East Anglia
Norwich NR4 7TJ
Tel: 01603 456 161
Fax: 01603 259 401
Email: p.child AT uea.ac.uk
Using SVG in the Artworld Project,
Child, P., QA Focus case study 07, UKOLN,
<http://www.ukoln.ac.uk/qa-focus/documents/case-studies/case-study-07/>
The document was published in January 2003.
The Crafts Study Centre (CSC) [1], established in 1970, has an international standing as a unique collection and archive of twentieth century British Crafts. Included in its collection are textiles, ceramics, calligraphy and wood. Makers represented in the collection include the leading figures of the twentieth century crafts such as Bernard Leach, Lucie Rie and Hans Coper in ceramics; Ethel Mairet, Phyllis Barron and Dorothy Larcher, Edward Johnston, Irene Wellington, Ernest Gimson and Sidney Barnsley. The objects in the collection are supported by a large archive that includes makers' diaries, documents, photographs and craftspeoples' working notes.
The Crafts Study Centre Digitisation Project [2] has been funded by the JISC to digitise 4,000 images of the collection and archive and to produce six learning and teaching modules. Although the resource has been funded to deliver to the higher education community, the project will reach a wide audience and will be of value to researchers, enthusiasts, schools and the wider museum-visiting public. The Digitisation Project has coincided with an important moment in the CSC's future. In 2000 it moved from the Holborne Museum Bath, to the Surrey Institute of Art & Design, University College, Farnham, where a purpose-built museum with exhibition areas and full study facilities, is scheduled to open in spring 2004.
The decision to create 'born digital' data was therefore crucial to the success not only of the project, but also in terms of the reusability of the resource. The high-quality resolutions that have resulted from 'born digital' image, will have a multiplicity of use. Not only will users of the resource on the Internet be able obtain a sense of the scope of the CSC collection and get in-depth knowledge from the six learning and teaching modules that are being authored, but the relatively large file sizes have produced TIFF files that can be used and consulted off-line for other purposes.
These TIFF files contain amazing details of some of the objects photographed from the collection and it will be possible for researchers and students to use this resource to obtain new insights into for example, the techniques used by makers. These TIFF files will be available on site, for consultation when the new CSC opens in 2004. In addition to this, the high-quality print out-put of these images means that they can be used in printed and published material to disseminate the project and to contribute to building the CSC's profile via exhibition catalogues, books and related material.
The project team were faced with a range of challenges from the outset. Many of these were based on the issues common to other digital projects, such as the development of a database to hold the associated records that would be interoperable with the server, in our case the Visual Arts Data Service (VADS), and the need to adopt appropriate metadata standards. Visual Resources Association (VRA) version 3.0 descriptions were used for the image fields. Less straightforward was the deployment of metadata for record descriptions. We aimed for best practice by merging Dublin Core metadata standards with those of the Museum Documentation Association (mda). The end produce is a series of data fields that serve firstly, to make the database compatible with the VADS mapping schema, and secondly to realise the full potential of the resource as a source of information. A materials and technique field for example, has been included to allow for the input of data about how a maker produced a piece. Users of the resource, especially students and researchers in the history of art and design will be able to appreciate how an object in the collection was made. In some records for example, whole 'recipes' have been included to demonstrate how a pot or textile was produced.
Other issues covered the building of terminology controls, so essential for searching databases and for achieving consistency. We consulted the Getty Art and Architecture Thesaurus (AAT) and other thesauri such as the MDA's wordhord, which acts as a portal to thesauri developed by other museums or museum working groups. This was sometimes to no avail because often a word simply did not exist and we had to reply on terminology develop in-house by curators cataloguing the CSC collection, and have the confidence to go with decisions made on this basis. Moreover, the attempt to standardise this kind of specialist collection can sometimes compromise the richness of vocabulary used to describe it.
Other lessons learnt have included the need to establish written image file naming conventions. Ideally, all image file names should tie in with the object and the associated record. This system works well until sub-numbering systems are encountered. Problems arise because different curators when cataloguing different areas of the collection, have used different systems, such as letters of the alphabet, decimal and Roman numerals. This means that if the file name is to match the number marked on the object, then it becomes impossible to achieve a standardised approach. Lessons learnt here, were that we did not establish a written convention early enough in the project, with the result that agreement on how certain types of image file names should be written before being copied onto CD, were forgotten and more than one system was used.
The value of documenting all the processes of the project cannot be overemphasised. This is especially true of records kept relating to items selected for digitisation. A running list has been kept detailing the storage location, accession number, description of the item, when it was photographed and when returned to storage. This has provided an audit trail for every item digitised. A similar method has been adopted with the creation of the learning and teaching modules, and this has enhanced the process of working with authors commissioned to write the modules.
Lastly, but just as importantly, has been the creation of QA forms on the database based on suggestions presented by the Technical Advisory Services for Imaging (TASI) at the JISC Evaluation workshop in April 2002. This has established a framework for checking the quality and accuracy of an image and its associated metadata, from the moment that an object is selected for digitisation, through to the finished product. Divided into two sections, dealing respectively with image and record metadata, this has been developed into an editing tool by the project's documentation officer. The QA forms allows for most of the data field to be checked off by two people before the image and record is signed off. There are comment boxes for any other details, such as faults relating to the image. A post-project fault report/action taken box has been included to allow for the reporting of faults once the project has gone live, and to allow for any item to re-enter the system.
The bank of images created by the Digitisation Project will be of enormous importance to the CSC, not only in terms of widening access to the CSC collection, but in helping to forge its identity when it opens its doors as a new museum in 2004 at the Surrey Institute of Art & Design, University College.
Jean Vacher
Digitisation Project Officer
Crafts Study Centre
Surrey Institute of Art & Design, University College
Crafts Study Centre Digitisation Project - and Why 'Born Digital',
Vacher, J., QA Focus case study 08, UKOLN,
<http://www.ukoln.ac.uk/qa-focus/documents/case-studies/case-study-08/>
Information about the Crafts Study Centre (CSC) [1] and the Crafts Study Centre Digitisation Project [2] is given in another case study [3].
At the outset of The Crafts Study Centre (CSC) Digitisation Project extensive research was undertaken by the project photographer to determine the most appropriate method of image capture. Taking into account the requirements of the project as regards to production costs, image quality and image usage the merits of employing either traditional image capture or digital image capture were carefully considered.
The clear conclusion to this research was that digital image capture creating born digital image data via digital camera provided the best solution to meet the project objectives. The main reasons for reaching this conclusion are shown below:
Items from the CSC collection are identified by members of the project team and passed to the photographer for digitisation. Once the item has been placed in position and the appropriate lighting arranged, it is photographed by using a large format monorail camera (cambo) hosting a Betterlight digital scanning back capable of producing image file sizes of up to 137 megabytes without interpolation.
Initially a prescan is made for appropriate evaluation by the photographer. Any necessary adjustments to exposure, tone, colour, etc are then made via the camera software and then a full scan is carried out with the resulting digital image data being automatically transferred to the photographers image editing program, in this case Photoshop 6.
Final adjustments can then be made, if required and the digital image then saved and written onto CDR for onward delivery to the project database.
The main challenges in setting up this system were mostly related to issues regarding colour management, appropriate image file sizes, and standardisation wherever possible.
To this end a period of trialling was conducted by the photographer at the start of the image digitisation process using a cross section of subject matter from the CSC collection.
Identifying appropriate file sizes for use within the project and areas of the digital imaging process to which a level of standardisation could be applied was fairly straightforward, however colour management issues proved slightly more problematic but were duly resolved by careful cross-platform (Macintosh/MS Windows) adjustments and standardisation within the CSC and the use of external colour management devices.
David Westwood
Project Photographer
Digitisation Project Officer
Crafts Study Centre
Surrey Institute of Art & Design, University College
Image Digitisation Strategy and Technique: Crafts Study Centre Digitisation Project,
Westwood, D., QA Focus case study 09, UKOLN,
<http://www.ukoln.ac.uk/qa-focus/documents/case-studies/case-study-09/>
The document was published in January 2003.
Funded by the Higher Education Funding Council for England under strand three of the initiative 'Improving Provision for Students with Disabilities', the aim of the DEMOS Project was to develop an online learning package aimed at academic staff and to examine the issues faced by disabled students in higher education. The project was a collaboration between the four universities in the Manchester area - the University of Salford [2], the University of Manchester [3], the Manchester Metropolitan University [4] and UMIST [5].
At the start of the project the purpose of the Web site was still unclear, which made it difficult to plan the information structure of the site. Of course, it would serve as a medium to disseminate the project findings, research reports, case studies... but for months the design and the information architecture of this site seemed to be in a neverending state of change.
In the early stage of the project virtual learning environments, such as WebCT, were tested and deemed unsuitable for delivering the course material, due to the fact that they did not satisfy the requirements for accessibility.
Figure 1: The Demos Web Site
At this point it was decided that the Web site should carry the course modules. This changed the focus of the site from delivering information about the progress of the project to delivering the online course material.
In the end we envisioned a publicly accessible resource that people can use in their own time and at their own pace. They can work through the modules in the linear fashion they were written in or they can skip through via the table of contents available on every page. There are also FAQ pages, which point to specific chapters.
Many academic institutions have already added links to the DEMOS materials on their own disability or staff development pages.
To ignore accessibility would have been a strange choice for a site that wants to teach people about disability. Accessibility was therefore the main criteria in the selection of a Web developer.
I have been a Web designer since 1998 and specialised in accessibility from the very beginning. For me it is a matter of ethics. Now it is also the law.
The challenge here was to recreate, at least partially, the feeling of a learning environment with its linear structure and incorporating interactivity in form of quizzes and other learning activities without the use of inaccessible techniques for the creation of dynamic content.
Accessibility techniques were applied from the beginning. But the site also represents an evolution in my own development as a Web designer, it always reflected my own state of knowledge. Where in the beginning accessibility meant eradicating the font tag, it now means standard-compliant code and tableless CSS layout.
This site was designed in compliance with the latest standards developed by the World Wide Web Consortium (W3C) [6] and using the latest accessibility techniques [7] as recommended by the Web Accessibility Initiative (WAI) [8] .
In December 2001 the code base of the site was switched over to XHTML 1.0 Transitional. In November 2002 the site was further improved by changing it to a CSS layout, which is used to position elements on the page without the use of tables. The only layout table left is the one holding the header: logo, search box and top navigation icons.
Stylesheets are also used for all presentational markup and a separate print stylesheet has been supplied.
The code was validated using the W3C Validation Services [9].
With the advent of standard-compliant (version 6 and 7) browsers, the Web developer community started pushing for the adoption of the W3C guidelines as standard practise by all Web designer. Now that version 3 and 4 browsers with all their proprietary mark-up were about to be consigned to the scrap heap of tech history, it was finally possible to apply all the techniques the W3C was recommending. Finally the makers of user agents had started listening to the W3C too and were making browsers that rendered pages designed according to standards correctly. (It turns out things weren't all that rosy but that's the topic for another essay.)
Standards are about accessibility, or, as the W3C phrases it, 'universal design'. They ensure that universal access is possible, i.e. that the information contained on a Web page can be accessed using
The most important reason for designing according to standards is that it gives the user control over how a Web page is presented. The user should be able to increase font sizes, apply preferred colours, change the layout, view headers in a logical structure, etc.
This control can be provided by the Web designer by:
On the DEMOS site, all presentational styles are specified in stylesheets. The site 'transforms gracefully' when stylesheets are ignored by the user agent, which means that the contents of a page linearises logically. The user has control over background and link colours via the browser preferences and can increase or decrease font sizes.
The DEMOS Guide to Accessible Web Design contains a chapter on User Control [10], which describes how these changes can be applied in various browsers.
(The links below lead to pages on the DEMOS site, more precisely: the DEMOS Guide to Accessible Web Design [11] )
Some of the techniques used:
More information and details: Accessibility techniques used on the DEMOS site [12] (listed by WAI checkpoints).
Web developers sometimes believe that accessibility means providing a separate text-only or low-graphics version for the blind. First of all: I have always been on that side of the camp that believes that there should be only one version of a site and that it should be accessible.
"Don't design an alternative text-only version of the site: disabled people are not second class citizens..." (Antonio Volpon, evolt.org [13] )Secondly, accessibility benefits not only blind people [14]. To be truly inclusive we have to consider people with a variety of disabilities, people with a range of visual, auditory, physical or cognitive disabilities, people with learning disabilities, not to forget colour blindness, senior citizens, speakers of foreign languages, et cetera, et cetera.
Surely not all of them are part of the target audience, but you never know, and applying all available accessibility techniques consistently does not take that much more effort.
We tried to provide a satisfactory experience for everyone, providing user control, keyboard access, icons and colour to loosen things up, whitespace and headers to break up text in digestable chunks. And we encourage people to provide feedback, especially if they experience any problems.
To ensure accessibility the site was tested across a variety of user agents and on different platforms. A number of screenshots from these tests [15] can be found at the DEMOS site.
The site has also been tested using the Bobby [16] and the Wave [17] Accessibility Checker. It is AAA compliant, which means that it meets all three levels of accessibility.
One of the last things we finally solved to our satisfaction was the problem of creating interactive quizzes and learning activities for the course modules without the use of inaccessible techniques. Many of the techniques for the creation of dynamic and multimedia content (JavaScript, Java, Flash...) are not accessible.
Eventually we discovered that PHP, a scripting language, was perfect for the job. PHP is processed server-side and delivers simple HTML pages to the browser without the need for plug-ins or JavaScript being enabled.
As mentioned before, the Web site started without a clear focus and without a clear structure. Therefore there wasn't much planning and structured development. In the first months content was added as it was created (in the beginning mainly information about the project) and the site structure grew organically. This caused some problems later when main sections had to be renamed and content restructured. From the Web development point of view this site has been a lesson in building expandability into early versions of Web site architecture.
Since there was so much uncertainty about the information architecture in the beginning, the navigation system is not the best it could be. The site grew organically and navigations items were added as needed. The right-hand navigation was added much later when the site had grown and required more detailed navigation - more detailed than the main section navigation at the top of the page underneath the logo and strapline.
But the right-hand navigation is mainly sub-navigation, section navigation, which might be confusing at times. At the same time, however, it always presents a handy table of contents to the section the visitor is in. This was especially useful in the course modules.
The breadcrumb navigation at the top of the main content was also added at a later date to make it easier for the visitor to know where they are in the subsections of the site.
Already mentioned in Phil Barker's report on the FAILTE Project Web Site [18], Netscape 4 was also my biggest problem.
Netscape 4 users still represent a consistent 12% of visitors in the UK academic environment (or at least of the two academic sites I am responsible for). Since this is the target audience for the DEMOS site, Netscape 4 quirks (i.e. its lack of support for standards) had to be taken into account.
Netscape understands just enough CSS to make a real mess of it. Older browsers (e.g. version 3 browsers) simply ignore stylesheets and display pages in a simpler fashion with presentational extras stripped, while standard-compliant browsers (version 6 and 7) display pages coded according to standards correctly. Netscape 4 is stuck right between those two scenarios, which is the reason why the DEMOS site used tables for layout for a long time.
Tables are not really a huge accessibility problem if used sparingly and wisely. Jeffrey Zeldman wrote in August 2002 in 'Table Layout, Revisited' [19]:
Table layouts are harder to maintain and somewhat less forward compatible than CSS layouts. But the combination of simple tables, sophisticated CSS for modern browsers, and basic CSS for old ones has enabled us to produce marketable work that validates - work that is accessible in every sense of the word.Tables might be accessible these days because screenreader software has become more intelligent but standard-compliance was my aim and layout tables are not part of that.
Luckily techniques have emerged that allow us to deal with the Netscape 4 quirks.
One option is to prevent Netscape 4 from detecting the stylesheet, which means it would deliver the contents in the same way as a text-only browser, linearised: header, navigation, content, footer following each other. No columns, colours, font specifications. But an audience of 12% is too large to show a site to that has lost its 'looks'. The site still had to look good in Netscape 4.
The other option is to use a trick to get Netscape 4 to ignore some of the CSS instructions [20] . Deliver a basic stylesheet to Netscape 4 and an additional stylesheet with extra instructions to modern browsers. This required a lot of tweaking and actually consumed an enormous amount of time but only because I was new to CSS layout. I have converted a number of other sites to CSS layout in the meantime, getting better at it every time.
The DEMOS site now looks good in modern browsers, looks OK but not terrific in Netscape 4, and simply linearises logically in browsers older than that and in text-only browsers.
There are still a few issues that need looking at, e.g. the accessibility of
input forms needs improving (something I'm currently working on) and the structural
mark-up needs improving so that headers are used in logical order starting with
<h1>
There are also a few clashes of forms with the CSS layout. All forms used on the DEMOS site are still in the old table layout. I haven't had the time to figure out what the problem is.
Eventually I also plan to move the code to XHTML Strict and get rid of the remains of deprecated markup [21] , which XHTML Transitional, the doctype [22] used at the moment, still forgives.
Of course it is important to keep the materials produced over the last two and a half years accessible to the public after the funding has run out. This will happen at the end of March 2003. This site will then become part of the Access Summit Web site (at time of writing still under constructions). Access Summit is the Joint Universities Disability Resource Centre that was set up in 1997 to develop provision for and support students with disabilities in higher education in Manchester and Salford.
We currently don't know whether we will be able to keep the domain name, so keep in mind that the URL of the DEMOS site might change. I will do my best to make it possible to find the site easily.
DEMOS Web site
<http://www.demos.ac.uk/>
Jarmin.com Guide to Accessible Web Design:
<http://jarmin.com/accessibility/>
A collation of tips, guidelines and resources by the author of this case study.
Focuses on techniques but includes chapters on barriers to access, evaluation,
legislation, usability, writing for the Web and more. Includes a huge
resources section
<http://jarmin.com/accessibility/resources/>
where you can find links to W3C
guidelines, accessibility and usability articles, disability statistics,
browser resources, validation tools, etc.
This section also contains a list of resources that helped me understand the
power of stylesheets
<http://jarmin.com/accessibility/resources/css_layout.html>.
DEMOS Accessibility Guide:
<http://jarmin.com/demos/access/>
Consists of the Techniques section from the above Guide to Accessible Web Design
<http://jarmin.com/accessibility/>,
plus includes extra information on accessibility techniques used on the
DEMOS site <http://jarmin.com/demos/access/demos.html>
(listed by WAI checkpoints)
and a number of demonstrations
<http://jarmin.com/demos/access/demos06.html>
on how the site looks under a variety of circumstances.
Please contact me if you have feedback, suggestions or questions about the DEMOS site, my design choices, accessible web design, web standards or the new location of the site.

Iris Manhold
14 February 2003
Email: iris@manhold.net
URL: http://jarmin.com/
Citation Details:
"Standards and Accessibility Compliance for the DEMOS Project Web Site", by Iris Manhold.
Published by QA Focus, the JISC-funded advisory service, on 3 March 2002
Available at
http://www.ukoln.ac.uk/qa-focus/documents/case-studies/case-study-10/
This case study describes a project funded by HEFCE (the Higher Education Funding Council for England). Although the project has not been funded by the JISC, the approaches described in the case study may be of interest to JISC projects.
The DEMOS Web site was moved from its original location (<http://www.demos.ac.uk/>) in March 2003. It is now available at <http://jarmin.com/demos/>.
It was noticed that the definition of XHTML and CSS given in the <acronym> element was incorrect. This was fixed on 7 October 2003.
Standards and Accessibility Compliance for the DEMOS Project Web Site,
Manhold, I., QA Focus case study 10, UKOLN,
<http://www.ukoln.ac.uk/qa-focus/documents/case-studies/case-study-10/>
The document was published in February 2003.
The Non-Visual Access to the Digital Library (NoVA) project was concerned with countering exclusion from access to information, which can all too easily occur when individuals do not have so-called 'normal' vision. Usability tests undertaken for the NoVA project provided an insight to the types of problems faced by users and interestingly, although the focus of the project was on the information seeking behaviour of blind and visually impaired people (generally using assistive technologies), the control group of sighted users also highlighted usability problems. This showed that although awareness of Web accessibility is increasing, all types of user could be faced with navigational problems, thus reinforcing the importance of involving a variety of different users in any design and development project.
Some problems experienced were due to accessibility and usability conflicts such as inappropriate or unhelpful use of alternative text, or poor use of language. Other problems were due to a lack of understanding of the different ways users interact and navigate around Web-based resources. Careful consideration must therefore be given not only to assure conflicts between accessibility and usability are addressed, but to the layout and navigation of a site and to the ways different assistive technologies interact with them.
This case study will look specifically at the usability testing phase of the NoVA project. The final report of the NoVA project [1] fully describes the methodology, findings and conclusions, and outlines a number of recommendations for digital library system design.
Despite evidence of much good work to make interfaces accessible and on methods for accessibility checking (see for example: EDNER, 2002 [2] and the World Wide Web Consortium Accessibility Guidelines [3]), there is less work published on usability issues or how people using assistive technologies (such as screen readers) navigate around the Web interface.
Although sites may adhere to accessibility recommendations, users can still experience navigational problems. This is partly due to the fact that Web pages are increasingly designed for parallel or non-serial navigation, offering a variety of options within one page (frames, tables, drop down menus etc). Parallel design can cause problems for users who are navigating the site using assistive technologies which force them down a serial (or linear) route, for example a screen reader reading out every hypertext link on a page one by one.
The overall objective of the NoVA project was to develop understanding of serial searching in non-serial digital library environments, with particular reference to retrieval of information by blind and visually impaired people. Serial searching was defined for the project a linear movement between pages, non-serial (or parallel) searching was defined as movements around a page, between frames or interacting with a number of options such as a table, dialog box or drop-down menu.
Using a combination of desk research, task analysis and user interviews, the objectives of the study were to:
The NoVA usability tests used a combination of observation, transaction logging and verbal protocol, together with pre-and post-task questions.
A sample of 20 sighted and 20 blind and visually impaired people was used to undertake a series of usability experiments. Definitions of terms were set at the beginning of the project. The 'sighted' sample was made up of users who were all able to read a standard (14" - 15") screen. The term 'visually impaired' was defined for the NoVA project as people who needed to use assistive technology, or had to be very close to the screen to be able to 'read' it. The sample size for the NoVA project enabled comparative analysis to take place between two user groups, however it should be noted that Nielsen (2000) [4] suggests excellent results can be obtained from usability tests comprising as little as five users (although he recommends at least 15 users to discover all the usability design problems).
Four information-seeking tasks were set using four Web-based resources:
Although not all of these might be viewed strictly as digital library resources, each resource displayed elements of parallelism in their design and were generally accessible, to greater and lesser degrees, according to the WAI recommendations.
Each of the tasks was consistently set so that comparative analysis could take place between the sighted and visually impaired users. For example, users were asked to search for a national and regional weather forecast using the same search engine.
It was recognised that success in performing searches could be influenced by previous knowledge or experience, either of the technology, the site visited, the subject matter of the task, or by individual interpretation and approach to a task. In an attempt to obtain a balanced picture, the tasks set covered a fairly broad subject base such as weather forecasts, shopping for clothes and travel information.
Every attempt was made to create a relaxed atmosphere and to dispel feelings among the users that they were being tested in any way (although inevitably this still occurred to some extent). This included an initial explanation of the purpose of the study, i.e. to highlight Web usability issues rather than to test information seeking skills. The observer also chatted informally prior to the tasks and offered the users tea/coffee and biscuits to put them at ease. Naturally, the users were ensured that all their responses would be kept strictly anonymous and only used for the stated purpose of the study.
To ensure everyone started from the same place, users were required to commence using the stated electronic resource, but were allowed to choose whether they used the search facility or browsed the site for relevant links. So for example, when asked to look for the national weather forecast for the UK, users were required to start with the search engine, either by typing in search terms or by browsing for a relevant weather link.
Users were not given a time limit to complete each task. At the beginning of the session they were told that they could stop the task at any time and were given examples such as "if you are satisfied that you have found the information", "if you are not satisfied, but think you have found all the information there is", or "if you are fed up with the task". The reason for this was to try and simulate real-life information searching behaviour, where information required by a user may or may not be found from within a specific resource and was not a judgment of the amount of information retrieved.
Data was gathered using a combination of on-screen data capture (Lotus ScreenCam which records on-screen activity and verbal dialog), sound recording and note taking. This method enabled each task to be recorded (either on-screen or by the sound of the assistive technology with verbal dialog) and backed up by note taking.
Users were asked to verbally describe what they were doing during each task. Users were also asked a set of pre- and post-task questions. These comprised general questions, such as how to tell a page is loading, initial comments about the interfaces and the type of information provided; and usability questions, such as their overall experience navigating around the resource. Both the verbal protocol and the pre- and post task questions provided a richer picture of the user's experience by enabling the observer to ascertain not only what they had done, but why they had done it, and how they felt about it.
Interviews were conducted before and after each task to help ensure the electronic resource and the task performed were still fresh in the user's mind before moving on to the next resource.
Data was transcribed in two ways:
Data from the searches and questions were entered and coded into a Computer Assisted Qualitative Data Analysis tool (Atlas-ti) [5].
Data was analysed using Atlas-ti analysis tool, which provided an efficient method of data storage and retrieval. Although entering and coding data was initially time consuming, once completed it provided quick and easy access to the large amounts of data gathered for the project. It was then possible to generate queries and reports for data analysis and report writing.
Each step taken during a search was coded to show the number and type of keystroke used within each search task. This was used to compare the information seeking behaviour of the two samples (sighted and visually impaired) and to look at different trends within each.
Data from the pre- and post-task questions was grouped and coded into categories. This enabled comparisons to be made relating to specific questions. For example, coding quotes from users relating to the question 'How do you know if a page is loading?' revealed that only one of the sighted users mentioned the listening to the hard drive, whereas many of the visually impaired users said they relied on this clue to tell them that the page is loading.
Gathering volunteers for the study was a time-consuming process and could have been a problem if it had not been built in to the NoVA project time frame. It is therefore worth bearing in mind that a substantial amount of time and effort is needed to gather a suitable sample.
In order to obtain specific data on the way people search electronic sources, it was necessary to select a sample of people who were reasonably familiar with using the Internet and, where appropriate, were comfortable using assistive technology. This meant that it was not possible to gather a true random sample. Although this was not particularly problematic for the study, it did mean that the results could not be generalised to the population as a whole.
Data was gathered using a combination of on-screen data capture (Lotus ScreenCam [6]), sound recording and note taking. Initially it was hoped that ScreenCam could be used throughout, however the pilot tests revealed that ScreenCam can interfere with assistive technologies, so it was necessary to use a combination of sound recording and note taking for the visually impaired sample.
It was difficult to create a natural environment for the users to perform the tasks, and although every attempt was made to make the users feel comfortable and to dispel any feelings that their ability was being tested, inevitably at times this did occur. However, this problem was probably unavoidable for the capture of qualitative data.
The observer attempted not to prompt subjects or give any instructions while the subject was performing the task. This proved difficult at times, particularly when it was evident that the user was becoming distressed. In some cases the observer had to provide a "hint" to enable the user to continue (it is suggested that this type of intervention is sometimes necessary in certain circumstances, as is prompting a user to ensure the transcription is accurately logged [7]).
The usability tests undertaken for the NoVA project provided a rich picture of the types of problems faced by users when navigating around Web-based resources, particularly when using assistive technologies. It also provided evidence of the types of features users liked and disliked, how they overcame navigational problems and what types of features enhanced their searching experience, all of which can be fed back into recommendations for the design of digital library systems.
Although the sample chosen was appropriate for the NoVA study, for general usability studies it would be desirable to try to include users with a variety of disabilities such as motor impairments, hearing impairments and visual impairments. Also, users with a mix of abilities to ensure the site is usable as well as interesting and engaging. Usability testing should be used alongside accessibility checking to provide a rich picture of the accessibility and usability of a Web site, which will help designers and developers to ensure their sites embrace universal access and access for all.
The findings of the NoVA usability testing, together with conclusions and recommendations are described in the final report, which is available to download from the NoVA project Web site in Word, PDF and HTML [1]
Jenny Craven
Research Associate
CERLIM, Manchester Metropolitan University
Tel: 0161 247 6142
Email: j.craven@mmu.ac.uk
URL: http://www.mmu.ac.uk/h-ss/dic/people/jcrhome.html
For QA Focus use.
QA Focus is a distributed project, with team members based in UKOLN (University of Bath) and the AHDS (Kings College, London). In addition one of the QA Focus team members is a remote worker. In order to provide effective communications for the team members there is a need for an effective communications infrastructure. This case study describes the communications infrastructure which is employed.
The distributed nature of the QA Focus team means that a good communications infrastructure is an essential part of working practice. The communications tools chosen for use need to be both efficient and easy to maintain, as well as being freely available.
The QA Focus communications infrastructure has been built around a number of separate but complimentary tools.
One of the first communication mechanisms established was a shared file space. MyYahoo [1] is a highly customisable, shared repository. The site provides a number of services including news, bookmarks, maps, calendar and email. The briefcase area allows online storage of files that can then be accessed from anywhere, either by visiting the site or by clicking on links to items. Any type of file can be stored providing they fall within certain content and size guidelines provided by Yahoo. Using MyYahoo the QA Focus team can manage files from work, home or any other location. Yahoo currently provides 30MB worth of free space.
Figure 1: The MyYahoo briefcase
A Yahoogroups mailing list [2] called qa-focus-team was also set up for internal QA Focus use. Yahoo encourage the use of user profiles allowing all their communication methods to be linked together. On setting up your own email account or a MyYahoo Web site you create a profile, this profile can then be assigned an email. Setting up the mailing list involved selecting a Yahoo! Groups Category and deciding on a group email address. Members are then enrolled or invited to join the group. Each individual member can then be configured, allowing them to post, receive and/or receive a copy of all messages to their usual daytime email addresses. The list is maintained and customised by the list owner and lists can be set up for public use or private use only. The main advantage of using the list is the creation of a comprehensive archive. This means that all email information is in an open space and not only held in one person's email box, whom may be on holiday or have changed jobs.
A Blog is a Web log held on the Internet which is updated frequently. Blogging has taken off in recent years and there is now a variety of free software allowing you to set up your own blog without any programming skills. One of the most famous blogs is blogger.com [3]. In order to record activities, ideas etc a blog was set up by the QA Focus team using Movabletype [4], a decentralised, Web based personal publishing system. The blog is currently only accessible internally and is used as a record of activities carried out during the week. These summaries will help with keeping note of work carried out and compiling reports. It is hoped that at a later date the blog will be open for external viewing.
Figure 2: The QA Focus Blog
The QA Focus team have also experimented with forms of instant messaging. These are services that provide users with instantaneous contact with other Internet users. The main advantages of instant messaging are that you can carry out a real-time conversation while involved with other tasks. There is a much higher level of synchronicity than that achieved with an e-mail conversation, so it is useful for high priority work that needs group input.
At one stage the Yahoo IM tool was used. However due to the limitations of this tool members of the QA Focus team agree to move to use of the MSN Messenger tool. This is now used for regular virtual meetings with our remote worker and across the team as a whole. In addition the software is used for short-term tasks for which email is not required, such as arranging meetings.
Setting up the various communication tools is fairly straightforward but can be time-consuming. The real problem is getting users or members of a team to actually use the tools. The core QA Focus team only consists of three people so encouraging use has not been that much of an issue, but occasionally you do find yourself slipping back into old ways of working and using solely email.
Having a good communications infrastructure is key when working in a team, especially when members are distributed remotely. The important factor in establishing use is to document procedures and use the tools diligently at the start so use becomes second nature.
The nature of QA Focus means that all experience and experimentation in a Web related area is always useful and gives us knowledge of both the problems and success areas. However if we had to repeat the process then maybe we would spend more time investigating the different tools available and document their advantages and disadvantages. Unfortunately as most people working on a project will know there is never enough time for research as anyone would like.
Brian Kelly
UKOLN
University of Bath
BATH
Tel: 01225 383943
Minor changes made to details of IM tools by Brian Kelly, 23 February 2003.
Gathering the Jewels [1] was established by a consortium of the following bodies: National Library of Wales, Society of Chief Librarians (Wales), National Museums and Galleries of Wales, Federation of Welsh Museums, Archives Council Wales, Royal Commission of Ancient and Historic Monuments Wales, Council of Museums in Wales, Wales Higher Education Libraries Forum and the Welsh County Archivists Group. The goal of the project was to digitise 23,000 items from approximately 190 libraries, museums and archives all over Wales and to present them on the Internet by means of a searchable database.
The nature of the project has four important consequences for the way we approach the collection of metadata:
When we first looked at the question of metadata, and came face to face with the reality of the difficulties listed above, the problem seemed massive. To make things worse, the Dublin Core elements apparently needed their own glossary to make them intelligible. These were dark days. However, things very quickly improved.
In the first place, we talked to professionals from the National Library of Wales's metadata unit, who reassured us that the Dublin Core elements could be translated into English. But more importantly than that, they showed us that the elements could be made to work for us: that there is a degree of flexibility about what many of the elements can be taken to mean; that the most important thing is to be consistent, however you interpret a particular element.
For example, there is a Dublin Core element called "Publisher". The National Library would interpret this as the organisation publishing the digital material on the Internet - i.e., us; we, on the other hand, would prefer to use it for the institution providing us with the material. Both interpretations are apparently valid, so long as they are used consistently. We also interpret the "Title" element in a way that will let us use it as a caption to the image when it is displayed on the Internet.
We also made a couple of key decisions. We were not here to catalogue 23,000 items to the Dublin Core standard. Also, the output of the whole project was to be a Web site linked to a searchable database – so the bare minimum metadata we had to collect was defined by the requirements of the Web site and search mechanisms for the database. In other words, an image appearing on a user's computer screen had to have a certain amount of information associated with it (a caption, a date, a credit to the institution that gave it to us, as well as subject and place-name keywords, etc.); any other metadata we could collect would be nice (the 'extent' or size, the 'medium', etc.) but not essential.
This was also our "Get Out Of Jail Free" card with regard to the bilingual aspects of the Web site. Anything which the user will see or search on has to be in English and Welsh. Other Dublin Core elements are recorded in English only (this decision was taken on the advice of the National Library of Wales and is based entirely on the limitations of existing computer systems and the amount of time that fully bilingual metadata would take to translate and enter; it has nothing to do with political preferences for one language or the other.)
As a result we have divided our metadata into four categories. Core elements are those that are mandatory, and which will be viewed or searched by the user, together with copyright information; Important elements are those which we may not get from an institution but which we will supply ourselves, such as a detailed interpretative description of the image. Technical elements are those which record how the material was digitally captured; we do not regard these as a high priority but as they are easy to enter in batches we always make sure we complete them. And finally Useful elements are the other Dublin Core elements that we will collect if the institution can supply them easily, but which we will otherwise leave blank until such time as cataloguing to the Dublin Core standard becomes the norm.
| Title English | a caption for the item, no more than one line |
| Title Welsh | as above, in Welsh |
| Identifier | unique ID of item, e.g. accession or catalogue number |
| Location | place name most significantly associated with the image |
| Period | period of subject depicted |
| Copyright | brief details of copyright ownership and clearance |
| Creator | institution/individual that produced the original |
| Date | date of production, e.g., when a painting was painted |
| Description | max. 200 word description of the resource and its content |
| Description Welsh | as above, in Welsh |
| Capture device | e.g. the scanner or camera used to capture the image |
| Capture history | e.g. the software employed |
| Manipulation history | file format master created in, quality control checks, etc. |
| Resolution of master | number of pixels (e.g., 3,400 x 2,200) |
| Compression | compressed or uncompressed |
| Bit depth of master | e.g. 24 bit |
| Colour profiles | e.g. Apple RGB embedded |
| Greyscale patch | e.g. Kodak Q13 greyscale |
| Type | type of resource, e.g. “image”, “text” |
| Extent | size, quantity, duration e.g. “1 vol., 200 pages” |
| Medium | example, “photograph” |
| Language | example, “EN” , “CY” ,”FR” |
| Relationship | example, “is part of collection ….” |
| Location alt. | bilingual place name variants |
| Publisher | usually repository name |
| GIS Reference | Eastings, Northings of place most significantly associated with the image |
| OS NGR | OS National Grid Reference of place most significantly associated with the image |
| Credit Line | where additional credit line is required for a record. Defaults to repository name |
Allison Coleman
Gathering the Jewels Ltd
National Library of Wales
Aberystwyth, Ceredigion
SY23 3BU.
This case study describe a project funding by the NOF-digitise programme. However the content of the case study should be of interest for anyone involved in making use of Dublin Core metadata.
Note that this case study was published in IM@T Online December 2003. (A username is required to access IM@T Online).
The UKOLN Web [1] site runs off a number of different Apache and IIS servers at the University of Bath. There are now thousands of pages on the site, which are maintained by a number of different people.
CGI scripts and forms are used occasionally on the site, for example for booking forms for conferences. Sometimes scripts and the forms connected with them get broken by people moving files, editing scripts and by out of date data. In addition errors may occur when the end user inputs unexpected or illegal data, if another service such as a back end database, fails. In this way, script errors may be indicators of larger problems that need to be quickly addressed.
It was previously impossible to locate specific errors unless a user emailed the site to let tell the Web master that a script error was appearing on a Web page.
It was decided that a new internal server error page would be created which would allow the Web support team to establish what and where problems are happening. The error page would also generate an email to the Web support mailing list saying what had happened and why.
When the support team receives these emails they then decide if this is a problem that requires immediate attention, or, as is sometimes the case if this was a "correct" error. For example, if a robot visits a script and attempts to access the script in an unexpected way, it is entirely appropriate that the robot should see an error. Not all server errors are bad.
The internal-server-error.cgi script created was fairly simple. The process involves:
Reading a template for the page delivered to the end user.
Creating a message to mail to support based on the environment of the Apache server.
Creating a message to merge with the template and send to the user.
Printing a template message to browser.
Sending an email message to support.
A template was used for the HTML so the look and feel could be edited. Once broken CGI scripts were reported the responsibility for changing the page then lies with the owner of that page to remove or repair the particular script.
The report information sent to the Web support team includes the following information:
Internal Server Error - www.ukoln.ac.uk - report
follows:
REMOTE_ADDR -> 138.38.32.85
This is the host of the machine running the script, it may be useful to track users who have seen the 500 error message.
REDIRECT_SCRIPT_FILENAME
->/opt/Web/content/www.ukoln.ac.uk/cgi-bin/booking-form.pl
This is the script that is failing, which is very useful to know.
HTTP_X_FORWARDED_FOR -> 138.38.146.50
If the end user is going via a proxy this may show the actual address of their machine.
REDIRECT_HTTP_USER_AGENT -> Mozilla/4.0 (compatible;
MSIE 6.0; Windows NT5.0)
It is useful to see if a particular browser is causing an error.
REDIRECT_ERROR_NOTES -> Premature
end of scriptheaders:
/opt/Web/content/www.ukoln.ac.uk/cgi-bin/booking-form.pl
This is the error message received, which is also logged to the Apache error log.
SCRIPT_URI ->http://www.ukoln.ac.uk/cgi-bin/booking-form.pl
This is the Web page the user was attempting to view that generated the error.
HTTP_REFERER ->http://www.ukoln.ac.uk/events/bath-profile/form.html
This is the page from which the failing script was linked from.
The main problem was that after the system was set up there were a lot of error messages being sent to the Web support team, though it was anticipated that this would change as the broken scripts are edited and removed. To address this problem the messages are sent to a separate Web-errors email list from which members of support can opt out.
There are various improvements that could be made to the error detection script. Firstly the message could get sent to the server administrator (from the environment variable), which would make it easier to configure the email address of the person to send to, etc.
Another very useful improvement would be for each script on our servers to specify who the error report should go to, however we are unsure if this is configurable. We are currently considering if it would be possible for whoever writes a script to set a particular variable to their username. The error script could then read this and attach this username to the email, such as 'for the attention of xxxusernamexxx'. Or even just send that person the error email.
Once this problem has been tackled it would be helpful to put in place an error logging system that notes who is responsible for fixing the error and marks off when they have done it.
Note: This was initially an RDN [2] development that was reused by UKOLN.
Pete Cliff and Eddie Young
UKOLN
University of Bath
Bath
BA2 7AY
For QA Focus use.
MIMAS [1] is a JISC-funded service [2] which provides the UK higher education, further education and research community with networked access to key data and information resources to support teaching, learning and research across a wide range of disciplines. Services supported by MIMAS include the ISI Web of Science Service for UK Education, CrossFire, UK Census aggregate statistics, COPAC, the Archives Hub, JSTOR, a Spatial Data service which includes satellite data, and a new International Data Service (part of the Economic and Social Data Service) [3].
This document describes the approaches which have been taken by MIMAS to ensure that its services provide levels of accessibility which are compatible with MIMAS's available resources and the services it provides.
The work was carried out in order to ensure that MIMAS services are compliant with the SENDA legislation wherever possible.
A MIMAS Project Management Team called ACE (Accessibility Compliance Exercise) was set up with the remit of making recommendations on accessibility work. We were set the task of making the MIMAS Web site compliant at least with Priority 1 WAI guidelines [4] by 1 September 2002.
The ACE Team consisted of a coordinator and four members of MIMAS staff with a range of skills, and chosen so that each section manager (of which there are three) had at least one person on the team. We knew that it would take a great deal of effort from many members of staff and that it was crucial to have the support of all managers.
The coordinator reported to the MIMAS and Manchester Computing management team and left technical issues to the rest of the team.
The team went about identifying the services, projects, areas of the MIMAS Web sites and other items which are supported and/or hosted by MIMAS.
Usually the creator or maintainer, but in some cases the section manager was identified as the person responsible for each area and a member of the ACE team (the "ACE contact") was assigned to assist and monitor progress.
We drew a distinction between Web pages (information), data and applications. It took some time to get the message through to all staff that ACE (and SENDA) was concerned with all aspects of the services and that we needed to check applications as well as Web pages. We could all have some informed opinion about Web pages, but applications often required an expert in the area to think about the accessibility of a package. Managers were asked to request and gather statements from suppliers on the accessibility of their products.
A Web page was set up on the staff intranet to document the progress each service was making, who the main players were, and to summarise areas of concern that we needed to follow up. This helped the ACE Team to estimate the scope of any work which was needed, and managers to allocate time for staff to train up in HTML and accessibility awareness. We also provide notes on how to get started, templates, training courses etc., and we continue to add information that we think will help staff to make their pages more accessible.
The ACE team met fortnightly to discuss progress. Members of the team recorded progress on the staff intranet, and the coordinator reported to the management team and to others in the Department (Manchester Computing) engaged in similar work.
The ACE team recommended that MIMAS Web resources should aim to comply with at least WAI Priority 1 guidelines. The ACE team had the following aims:
Software (Macromedia's LIFT) was purchased to assist staff evaluate their pages, and extra effort was brought in to assist in reworking some areas accessible.
The ACE team set up an area on the staff intranet. As well as the ongoing progress report, and information about the project and the ACE team this contained hints and tips on how to go about evaluating the accessibility of Web pages, validating the (X)HTML, how to produce an implementation plan, examples of good practice etc.
Other information on the Staff intranet included:
The ACE team had their own pages to make accessible, whilst also being available o help staff who needed guidance with their own Web sites. We all had our usual day jobs to do, and time was short.
Some Web sites needed a lot of work. We brought in external help to rework two large sites and encouraged the systematic use of Dreamweaver in order to maintain the new standards. Using the Dreamweaver templates prepared by the ACE team helped those staff who were not that familiar with HTML coding.
Although Manchester computing and JISC put on Accessibility courses, not all staff were able to attend. Group meetings were used to get the message across, and personal invitations to attend the ACE workshops were successful in engaging HTML experts, managers, programmers and user support staff.
There was still a lot to do after September 2002. Not all sites could reach Priority 1 by September 2002. For these, and all services, we are recommending an accessibility statement which can be reached form the MIMAS home page. We continue to monitor the accessibility of Web pages and are putting effort into making Web sites conform to the local conventions that we have now set out in the MIMAS Accessibility Policy. This Policy is for staff use, rather than a public statement, and is updated from time to time. Accessibility statements [7] are specific to each service.
In January and February 2003, the ACE team ran a couple of workshops to demonstrate key elements of the ACE policy - e.g. how to validate your pages, and to encourage the use of style sheets, Dreamweaver, and to discuss ways of making our Web sites more accessible generally.
We still have to ensure that all new staff are sent on the appropriate Accessibility courses, and that they are aware of the standards we have set and aim to maintain.
Workshops help everyone to be more aware of the issues and benefited the ACE team as well as staff. Because of time constraints we were unable to prepare our won ACE workshops until January 2003, by which time most sites were up to Level 1. Other people's workshops (eg. the JISC workshop) helped those attending to understand the issues relating to their own sites, those maintained by others at MIMAS, and elsewhere.
Talking to staff individually, in small groups, and larger groups, was essential to keep the momentum going.
It would have been helpful to be more specific about the accessibility features we want built in to the Web sites. For example, we encourage "skip to main content" (Priority 3), and the inclusion of Dublin Core metadata.
Anne McCombe
MIMAS
University of Manchester
For QA Focus use.
 The Economic and Social Data Service
(ESDS) [1]
is a national data archiving and dissemination service which came into operation
in January 2003.
The Economic and Social Data Service
(ESDS) [1]
is a national data archiving and dissemination service which came into operation
in January 2003.
The ESDS service is a jointly-funded initiative sponsored by the Economic and Social Research Council (ESRC) [2] and the Joint Information Systems Committee (JISC) [3].
Many Web sites fail to comply with accessibility and usability guidelines or consist of valid code. Prior to setting up the ESDS Web site it was decided that a Web Standards Policy would be agreed upon and adhered to.
The ESDS Web Standards Policy was released in June 2003 and applies to all newly constructed ESDS Web pages.
ESDS is committed to following agreed best standards and good practice in Web design and usability. The underlying code of the ESDS Web site achieves compliance with W3C guidelines for XHTML and Cascading Style Sheets. It strives to meet Web Content Accessibility Guidelines and be Special Educational Needs Disability Act (SENDA) compliant. Where this is not feasible or practical, e.g., proprietary software programs such as Nesstar Light, we will provide an alternative method for users to obtain the assistance they need from our user support staff. JISC and UKOLN recommendations have been reviewed for this policy.
| Standards | Validation and Auditing Tools |
|---|---|
| XHTML 1.0 Transitional http://www.w3.org/TR/xhtml1/ |
W3C XHTML validation service http://validator.w3.org/ |
| CSS Level 2 http://www.w3.org/TR/REC-CSS2/ | W3C's CSS validation service http://jigsaw.w3.org/css-validator/ |
| WCAG 1.0 Conformance Level: all Priority 1 checkpoints, most Priority 2 checkpoints, and some Priority 3 checkpoints. |
A-prompt http://aprompt.snow.utoronto.ca/ Bobby http://bobby.watchfire.com/bobby/ |
For more detailed information about accessibility standards and how best to implement them see:
HTML is the recommended format for small documents and Web pages.
ESDS also provides access to significant amounts of lengthy documentation to users as part of its service. For these lengthier, more complex documents, we generally follow these JISC recommendations.
If a link leads to a non-HTML file, e.g., a zip or Adobe PDF file, this will be clearly indicated.
Portable Document Format (PDF)
For documents provided in PDF, a link to the Adobe free viewer will be made available.
Rich Text Format (RTF)
All leading word processing software packages include a standard facility for
reading RTF and some documents may therefore be made available in this format.
The ESDS is committed to keeping the links on its pages as accurate as possible.
ESDS Web pages are checked using Xenu Link Sleuth [4] or an equivalent checker, on a monthly basis.
ESDS catalogue records are checked using Xenu Link Sleuth or an equivalent checker on a monthly basis.
ESDS Web page links are manually checked every six months to verify that the content of the pages to which they link is still appropriate.
New templates and all pages are checked for use with these standard browsers:
We test our pages on PCs using Microsoft Windows operating systems. We do not have the equipment to test on an Apple Macintosh platform and rely on the standards we use to assure accessibility.
Diane Geraci and Sharon Jack
Economic and Social Data Service
UK Data Archive
University of Essex
Wivenhoe Park
Colchester
Essex
UK
CO4 3SQ
For QA Focus use.
Exploit Interactive [1] was a pan-European Web magazine, which was funded by the European Commission's Telematics for Libraries programme. The magazine was one of the project deliverable of the EXPLOIT project, which aimed to promote the results of EU library projects and to facilitate their take-up by the market of library and information systems. The magazine ran for seven issues between May 1999 and October 2000. During its lifetime the magazine developed and maintained a strong and involved community of Exploit Interactive readers, authors, project partners and information providers and provided a forum for discussion within the EU Telematics for Libraries community.
Prior to the the last issue being published it was recognised that maintaining the site could possibly be a problem. Funding would cease and there would no longer be a member of staff working on the site.
Note that this case study does not address the wider long-term preservation issues. In particular it does not address:
The case study provides a pragmatic approach to access to the Web site after the project funding has finished.
It was decided to agree on a short-medium term access strategy for the Exploit Interactive Web site. This strategy would list policies and procedures for maintenance of the site for the next 10 years. It would also allow us to allocate money to certain activities.
10 years was decided upon primarily because the preservation industry rule of thumb is that data should be migrated every 10 years. It is unlikely that we will have the resources to migrate the Exploit Interactive Web site.
We will use the following procedures:
The area on which Exploit Interactive is held was measured:
Disk Size: 3.92 Gb (3920 Mb)
Exploit Interactive live site: 62.9 Mb
Exploit Interactive development site: 70.3 Mb
Exploit Interactive log files: 292 Mb
Exploit Interactive currently takes up 425.4 Mb of disk space.
The cost of this space is negligible bearing in mind you can purchase 30 Gb disk drives for about £40.
We have established that the domain name has been paid for until 23rd October 2008. We feel this is a sufficiently long period of time.
Two years on from the end of funding there have been very few problems adhering to the access strategy. The domain name has been held and a regular link checking audit has been initiated [2] Time spent on the maintenance of the site, such as link checking, has been minimal (about 30 minutes per year to run a link check and provide links to the results).
There are a number of potential problems which we could face:
However in practice we think such possibilities are unlikely.
We are confident that we will be able to continue to host this resource for at least 3 years and for a period of up to 10 years. However this is, of course, dependent on our organisation continuing to exist during this period.
Brian Kelly
UKOLN
University of Bath
BATH
UK
Tel: +44 1225 385105
For QA Focus use.
The UK Data Archive at the University of Essex is one of the partners within the JISC-funded Collection of Historical and Contemporary Census Data and Related Materials (CHCC) project [1]. The project, led by MIMAS at the University of Manchester, runs from October 2000 to September 2003.
The central aim of the project is to increase use of the CHCC in learning and teaching. It is doing this by: improving accessibility to the primary data resources; developing an integrated set of learning and teaching materials; improving awareness about the contexts in which census data can be used in learning and teaching; integrating contextual materials; providing access to web-based data exploration/visualisation tools; and developing resource discovery tools.
The UK Data Archive's role has been to develop this last output, a Census Resource Discovery System (initially and temporarily entitled a 'Census Portal'), which will allow both the primary census data and the CHCC-created related learning and teaching materials to be searched and browsed.
As a final, additional, introductory comment, it should be noted that although, due to staff changes, Lucy Bell has taken over the project management of the Census Resource Discovery System (CRDS) at the end of its development, the majority of the work described below was carried out between 2001 and 2003 by colleagues within the UK Data Archive and the History Data Service: Cressida Chappell, Steve Warin and Amanda Closier.
As the Census Resource Discovery System (CRDS) was intended to index two very different sorts of resource - primary data and teaching and learning materials - much initial work prior to the start of the project was put into identifying which metadata scheme should be used. It is not possible to index all the materials to a fine enough degree using a single scheme, therefore, the DDI (Data Documentation Initiative) Codebook [2] was used for the data and the IMS Learning Resource Metadata Specification [3] for the learning and teaching materials.
Both schema were taken, analysed and had CHCC Application Profiles crested. An initial problem encountered in the first six months of the project was that the extensions to the DDI had not been finalised by the time they were required for the development work on the CRDS. This delayed the development of the Metadata Entry System (MES); however, the work to set up the MES for the learning and teaching materials went ahead as planned.
The MES is a 'behind-the-scenes' tool, written in Visual FoxPro 7, created so that the metadata which form the CRDS records can be entered remotely into the database. Other CHCC project staff have been sent copies of the MES on CD, which they have installed locally on their PCs and used to enter the metadata. The completed records are automatically sent to the database, where they become live the following day and are then part of the database viewed via the CRDS web site which users can search and browse.
Working with two schema has meant having to design a MES which is suitable for either sort of resource. It has also meant the need to identify and map the related fields within each profile to each other, for the purposes of search, browse and display. Even if the MES can be set up so that the appropriate scheme is used, should the metadata creator select 'data' or 'learning and teaching resource' at the start, the users still need to be able to search across all the resources, no matter which scheme has been used to catalogue them.
This work was undertaken during the end of 2001 and much of 2002. Near the end of the first phase of the project, when these essential preparatory tasks should have been completed, the second of the MES-related obstacles was hit: it was discovered that the IMS specification was likely to be superseded by an eLearning standard, the IEEE Learning Object Metadata (IEEE LOM) [4]. The team working on the CRDS had to move fast to ensure that the system was kept as up-to-date as possible in light of these changes.
Another key task was the identification of the most appropriate thesaurus to use as the controlled vocabulary for the system. It was essential to find an appropriately specific list of keywords for indexing all the metadata records within the database. The list would be employed by several project staff, in diverse locations, all entering their own metadata and so the list needed to be of a manageable size but also to contain all terms which might be required.
Three thesauri were on offer as likely candidates: the Humanities and Social Science Electronic Thesaurus (HASSET) [5], the European Language Social Science Thesaurus (ELSST) [6] and the Social Research Methodology thesaurus (SRM) [7]. The third issue, which caused a delay in relation to metadata, was the need for the project team to reach a consensus on which thesaurus to use.
Despite the fact that some staff members had already left (as the project was reaching a conclusion of its first phase), it was decided to upgrade from IMS to IEEE LOM. The JISC agreed to fund a short-term extension of four months, during which time, as well as incorporating OAI harvesting and setting the system up as a Z39.50 target, the changes between the two schema were to be analysed and technical alterations to both the MES and to the web site's search and browse functionality made. This work is now halfway through. The profile used has been the UK Common Metadata Framework (UKCMF) [8]. The current major task is to update the guidelines used by those people entering metadata to ensure that they correspond with exactly what is seen on the screen.
The biggest headache during the upgrade has been the application of the appropriate XML bindings. At first, it was thought that the system may have to use the IMS bindings as an IEEE LOM set was not yet available. The IMS XML was considered to be similar to that of the IEEE LOM. Following the release of the draft IEEE LOM bindings, however, it was decided that it would be more appropriate to use these. The work to complete the CRDS needs to be done sooner than these will be finalised; nonetheless, it still seems more sensible to apply what will be the eventual schema rather than one which may become obsolete. The XML is being applied using Java Architecture for XML Binding (JAXB) [9]. This is not proving to be as straightforward as was hoped with the IEEE LOM XML, due to issues with the custom bindings file; in contrast, the DDI XML bindings have been relatively simple.
It soon became clear that a single thesaurus would not do the job. Although many included some census-specific terms, none were comprehensive enough. It is expected that some of the CRDS's users will have or will have been given by their tutors sophisticated and precise keywords to use, which are specific to certain census concepts. Additionally, because many of the CHCC-created learning and teaching objects constitute overviews of the subject and introductions to research methodologies, it was vital also to include appropriate methodological keywords to describe these.
In the end, terms from all three of the chosen thesauri were selected (HASSET, ELSST and SRM) and shared with the rest of the CHCC partners. This initial list numbered about 150 terms; however, some essential terms, such as FAMILY STRUCTURE, SOCIO-ECONOMIC GROUP or STANDARD OCCUPATION CLASSIFICATION, were still missing. The CHCC partners suggested additional terms and, after much debate, a final amalgamated list, gleaned from all four of these sources, the three thesauri and the CHCC partners, was settled. The final list contains 260 terms.
The biggest lesson to have been learnt through the development of the CHCC CRDS is the need to build as much slippage time as possible into a timetable. This sounds obvious but is worth repeating. Unfortunately, having said that, several of the obstacles encountered during the last 19 months of this project could not possibly have been predicted.
It was expected that the DDI would have been finalised in early 2002, but this did not happen until late Spring; it was expected that the IMS metadata specification would be the final one to be used (and, in fact, this was the specification advocated by the JISC); it was hoped to resolve the thesaurus question more quickly than proved possible. Most project plans will include slippage time for instances such as the third in this list, but few will be able to include provision for changing or delayed standards.
The second lesson learnt and probably the most important one is the need to be flexible when working with metadata standards and to communicate with those in the know as much as possible.
The CHCC CRDS project has been fortunate in receiving additional funding to incorporate the new changes in elearning metadata standards; without this, a product could have been launched which would have already been out-of-date even before it started.
Lucy Bell
UK Data Archive
University of Essex
Wivenhoe Park
Colchester
CO4 3SQ
Project Web site: http://www.chcc.ac.uk/
For QA Focus use.
Scottish Archive Network (SCAN) is a Heritage Lottery Funded project. The main aim of the project is to open up access to Scottish Archives using new technology. There are three strands to the project:
The digitisation of the Wills and Testaments are the focus of this case study.
The digitisation of the testaments is an ambitious undertaking. The main issues to be considered are:
As digital objects, images of manuscript pages lack the obvious information given by a physical page bound in a volume. It is important for completeness and for sequence that the pages themselves are accurately paginated. This gives a visual indication of the page number on the image as well as being incorporated into the naming convention used to identify the file. As a result quality is improved by reducing the number of pages missed in the digitisation process and by ensuring that entire volumes are captured and in the correct sequence.
The image capture program (dCam) automated the file naming process thereby reducing operator error and automatically capturing metadata for each image. This included date, time, operator id, file name, camera id and so on which helped in identifying whether later problems related to operator training or to a specific workstation. The program also included simple options for retakes.
We have instituted a secondary quality assurance routine. This involves an operator (different to the one who captured the images) examining a selection of the images for any errors missed by the image capture operator. Initially, 100% of the images were checked, but a 30% check was soon found to be satisfactory. The quality control is carried out within 24 hours of a volume being digitised, which means that the volume is still available in the camera room should the any retakes be necessary. The QA operators have a list of key criteria to assess the image - completeness, colour, consistency, clarity and correctness. When operators finds a defective image they reject it and select the reason from a standardised list. Although the images are chosen at random, whenever an error is found the QA program will present the next sequential image, as it is more likely for errors to be clustered together. A report is produced by the QA program which is then used to select any retakes. The reports are also analysed for any recurring problems that may be corrected at the time of capture. Further QA criteria: the quality of the cameras had been specified in terms of capacity (i.e. number of pixels), and we found that it is also possible to specify the quality of the CCD in terms of an acceptable level of defective pixels. This, however, does have a bearing on cost.
This was a time consuming process, which was slower than capture itself. It was important to build up sufficient material in advance of the digitisation getting underway.
We chose to capture colour images. The technique used was to take three separate colour images through red, green and blue filters and then to combine them into a single colour image. This worked well and produced very high quality colour images. However, it was very difficult to spot where there had been slight movement between the three colour shots. At a high level of magnification this produced a mis-registration between the 3 colour planes. The QA process sometimes caught this but it was far more costly for this to be trapped later on. We discovered that where there had been slight movement, the number of distinct colours in an image was almost double the average. We used this information to provide a report to the QA operators highlighting where potential colour shift had taken place. In addition the use of book cradles helped reduce this problem as well as enabling a focused image to be produced consistently.
The project has achieved successful completion within budget. For the digital capture program it proved possible to capture an additional 1 million pages as the capture and quality control workflow worked well. It is clear that the process is well suited to high throughput capture of bound manuscript material. Loose-leaf material took far more conservation effort and a much longer time to capture.
Rob Mildren
Room 2/1
Thomas Thomson House
99 Bankhead Crossway N
Edinburgh
EH11 4DX
for SCAN Business:
Tel: 0131-242-5802
Fax: 0131-242-5801
Email: rob.mildren@scan.org.uk
URL: http://www.scan.org.uk/
for NAS Business:
Tel: 0131-270-3310
Fax: 0131-270-3317
Email: rob.mildren@nas.gov.uk
URL: http://www.nas.gov.uk/
This case study describes a project funded by the Heritage Lottery Fund. Although the project has not been funded by the JISC, the approaches described in the case study may be of interest to JISC projects.
The Exploit Interactive e-journal [1] was funded by the European Commission's Telematics For Libraries Programme. Seven issues were published from May 1999 and October 2000.
The original proposal outlined a technical architecture for the e-journal. In addition the workplan included a mid-term technical review which would provide an opportunity to evaluate the technical architecture and provide an opportunity to implement enhancements which were felty necessary or desirable. This document summaries the developments which were made.
A summary of the mid-project technical developments to Exploit Interactive where published as an article in the e-journal [2]. The main developments included:
During the lifetime of the e-journal a number of the externally-hosted services became unavailable.
The project workplan allowed us to review the technical architecture of the e-journal. This allowed us flexibility to enhance the project deliverable. We will seek to ensure that future project proposals allow such flexibility.
Brian Kelly
UKOLN
University of Bath
BATH
BA2 7AY
Tel: 01225 383943
Email: B.kelly@ukoln.ac.uk
http://www.ukoln.ac.uk/
For QA Focus use.
In 1999 ingenta bought the US-based UnCover Corporation and set about moving the operation to the UK. UnCover had evolved over the space of about 10 years and the service had been fixed and added to in an ad hoc manner in response to customer requirements, with the result that there were now very few people who fully understood it. There were three main issues to be addressed: (1) moving the bibliographic data (i.e. information about journal articles) into a database in the UK and implement a stopgap application to provide access to this data; (2) moving the user level subscription and accounting data into a database and (3) reimplementing the application.
This case study discusses the choices which were available at various stages of the project and why decisions were made. It also discusses whether, with the benefit of hindsight, any of the decisions could have been improved.
UnCover had been set up to provide universities and commercial companies (mostly in the US) with access to journal articles. The system worked by providing a bibliographic database which contains basic information such as the journal title, the authors, journal title, volume, issue, page numbers, etc, which could be searched using the usual methods. If the searcher wanted a copy of the complete article then the system would provide a FAX copy of this at a charge which included the copyright fee for the journal's publisher, a fee for the provider of the copy (which was one of a consortium of academic libraries) and a fee for UnCover.
Additionally, UnCover provided journal alerting services, customised presentation, prepaid deposit accounts, and other facilities.
Ingenta bought the company, partly to give it a presence in the US and partly to get a bibliographic database with good coverage of academic journals going back about 10 years.
Over the space of about a year the entire system was moved to the UK from where it now runs.
The first task was to move the bibliographic backfile and then to start taking and adding the regular weekly updates which UnCover produced. The database consisted of about a million articles per year, though the early years (i.e. from 1988 to about 1992 were somewhat smaller). Ingenta had a good deal of experience in using the BasisPlus database system which originated as a textual indexing system but had acquired various relational features over the years. It has many of the standard facilities of such a system e.g. word and phrase indexing, mark up handling, stopwords, user defined word break characters and so on. Some thought had been given to alternative DBMSs (and this is discussed further below) but given the short timescale it would have been too risky to switch systems at this point. BasisPlus had the additional advantage that ingenta already had an application which could use it and which would require only small modifications to get working.
The application was written to access several databases simultaneously. Each database contained the data for a single year's worth of journal articles and if a particular search was required to cover several contiguous years (as most were then the application automatically applied the search to each year database in turn and then concatenated the results for display in reverse chronological order. There were disadvantages to this method, notably the near impossibility of sorting the results into relevance ranked order, but by and large, it worked well.
Ingenta obtained some samples of the data and set about analysing it and building a test database. This was fairly straightforward and didn't pose any serious problems, so the next step was to start offloading the data from UnCover a year at a time and building the production databases. It soon became obvious that data which purported to be from (say) 1990 contained articles form anywhere between 1988 and about 1995. Persuading the UnCover team to fix this would probably have delayed the build so it was decided to collect all the available data and then write a program to scan it searching for articles from a specified year which could then be loaded into the current target year database. Experience indicated that it's better to fix these sorts of problems yourself rather than try to persuade the other party to undertake what for them is likely to be a significant amount of unwelcome work.
The decision was taken quite early in the project to index the text without specifying any stopwords. Stopwords are commonly used words such as "the", "a", "and", "it", "not", etc. which are often not indexed because they are thought to occur too frequently to have any value as searching criteria and the millions of references will make the indexes excessively large. The result is that trying to search for the phrase "war and peace" will also find articles containing the word "war" followed by ANY word, followed by "peace", e.g. "war excludes peace". At first this seems sensible, but experience had shown that some of the stopwords also occur in other contexts where disabling searching is an acute disadvantage, so for example it becomes impossible to search for "interleukin A" without also finding thousands of references to interleukin B, interleukin C, etc which are not wanted. In fact it turned out that specifying no stopwords had a comparatively small inflationary effect on the indexes (about 20%) and a negligible effect on the performance.
Another important decision was to rethink the way author names were held in the system. UnCover had input names as:
Surname, Forename Initial
e.g. Smith, Robert K
this was very difficult to index in a way which would provide flexible name searching, particularly since bibliographic databases generally use Surname, Initials e.g. Smith, RK though we were generally reluctant to discard any data. It was decided to keep several author name fields, one with the names in their original format, a second to be used for display, a third for searching and a fourth for matching with another database. A more detailed description of the methodology used is given in the QA Focus advisory document on merging databases [1].
This operation of analyzing the data, designing the BasisPlus database structure (which was simply a further modification of several we had done in the past), writing the program to take the UnCover data and convert it for input to Basis and finally building the 12 production databases took about three months elapsed time.
The immediate requirement was for an application which would allow the databases to be searched, the results displayed and emailed, and documents ordered and delivered. There was not an initial requirement to replace the entire UnCover service, since this would continue to run for the time being. An application was available which had originally been written for the BIDS services and was reasonably easily adaptable. Because the BIDS services had used an almost identical database structure, the searching and display mechanisms could be moved with only minor modification. In addition the services had used the results display to drive a search of another database called the PubCat (or Publishers Catalogue) which contained bibliographic information on articles for which ingenta held the full text. If the user's search found one of these, then the system would offer to deliver it, either for free if the user had a subscription to the journal or for a credit card payment.
The major addition at this stage was to provide access to the UnCover document delivery service. The PubCat could only deliver electronic (PDF) versions of documents for issues of those journals held by ingenta (or for which ingenta had access to the document server) and inevitably, these tended to be the more recent issues. UnCover could also deliver older material as FAXes and to enable this it was necessary to construct a call to the UnCover server providing it with ordering details receive an acknowledgement. The HTTP protocol was used for this since it had the right structure and the amount of information passing back and forth was relatively small. In addition, a record of each transaction was kept at the ingenta end for reconciliation purposes.
There were a number of teething problems with the UnCover link, mainly caused by inadequate testing, but by this point there was a reasonably stable database and application.
The first real problem emerged shortly after the system went live, as it became obvious that the feed of bibliographic data from UnCover was going to stop as the UnCover operation in The US was wound down. In retrospect this should have been apparent to the developers involved and should have been allowed for, or at least thought about.
The data feed was to be replaced by the British Library's Inside Serials database (BLIS). In fact there were good reasons for doing this. The journal coverage of Inside Serials is much wider than UnCover and overall, the quality control was probably better. In addition, the coverage is more specifically academic and serious news journals, whereas UnCover had included a significant number of popular journals.
Nonetheless, the problems involved in cutting off one feed and starting another are fairly significant, mainly because an issue of a journal arrives at the various database compilers by a variety of routes and therefore find their way into the data feeds at different times. It was not possible to simply stop the UnCover feed one week and then start updating with BLIS because this would have meant that some articles would previously have been in BLIS, but not yet in UnCover (and therefore would never get into the composite database) while others would have already arrived via UnCover, only to be loaded again via BLIS. The solution adopted was to adapt the system which formatted the BLIS data for loading so that for each incoming article, it would interrogate the database to find out whether it had already been loaded. If it had, then it would merge the new entry with the existing entry (since BLIS had some extra fields which were worth incorporating), otherwise it simply generated a new entry. Also, immediately after stopping the UnCover updates (at the end of January) the previous 10 weeks worth of BLIS updates were applied. It was hoped that this would allow for disparities in the content of the two data feeds. In fact it was impossible to predict the extent of this disparity and the 10 week overlap was simply a best guess. It has since been discovered that arrival rates of some journals can vary even more dramatically than we thought and in retrospect it would have been preferable to have made this overlap somewhat longer (perhaps twice as long, but even then it's unlikely that all the missing articles would have been collected). The other problem was the ability of the updating mechanism to correctly match an incoming article with one which already existed in the database. There are two standard approaches to this difficult problem and these are discussed in some detail in Appendix 1.
In addition to this synchronisation problem, the two databases were rather different in structure and content, in the format of author names and journal titles, and in the minor fields, which all these databases have, but which exhibit a bewildering, and sometimes incomprehensible variety. For those fields which were completely new (e.g. a Dewey Classification) it was simply necessary to fix the databases to add a new field which would get populated as the new fields started to arrive and would have null values otherwise or have some value preloaded. Other fields, and certain other aspects of the content, required the BLIS data to be somehow fixed so that the application (and ultimately of course, the user) would see a consistent set instead of having to deal with a jarring discontinuity. The subject of normalising data from several databases is dealt with in the document on merging databases [1]. The process was less troublesome than it could have been, but this was mostly good luck rather than judgement. The most difficult aspect of BLIS from a presentational point of view is that the journal names are all in upper case. This may sound trivial, but displaying long strings of capitals on the screen now looks overly intrusive, and would in any case have jarred uncomfortably with the UnCover presentation. It was therefore necessary to construct a procedure which would convert the string to mixed case, but deal correctly with words which are concatenated initials (e.g. IEEE, NATO).
In addition to the bibliographic database, UnCover also held a large amount of data on its business transactions and on the relationships with their customers and suppliers and this also needed to be transferred. Because the service was available 24 hours a day and was in constant use, it would have been infeasible (or at least, infeasibly complex) to transfer the actual service to the UK in stages. It was therefore necessary to nominate a period (over a weekend) when the US service would be closed down, the data transferred and loaded into the new database, and the service restarted on the Monday morning.
The first task was to select a database system to hold the data, and ORACLE was chosen from a number of possible candidates. There were good reasons for this:
It had originally been intended to keep all the data (i.e. including the bibliographic data) in a single database, so as well as transferring the subscription and accounting data, it would have been necessary to dump out the bibliographic data and load this as well. It became obvious at an early stage that this was a step too far. There were doubts (later seen to be justified) about the ability of the ORACLE InterMedia system to provide adequate performance when searching large volumes of textual data and the minimal benefits did not justify extra work involved and the inherent risks, so the decision was taken at an early stage to keep the two databases separate, though inevitably this meant that there was a significant amount of data in common.
The database structure was the result of extensive study of the UnCover system and reflected an attempt to produce a design which was as flexible as possible. This is a debatable aim and there was, accordingly, a good deal of debate internally about the wisdom of it. It had the advantage that it would be able to accommodate new developments without needing to be changed, for example, it had been suggested that in the future it might be necessary to deal with objects other than journal articles (e.g. statistical data). By making the structure independent of the type of object it was describing, these could easily have been accommodated. In the short term however it had several disadvantages. Making the structure very flexible led to at least one area of it becoming very inefficient, to the extent that it was slow to update and very slow to interrogate. Moreover, a structure which is flexible admits not only of flexible use, but also flexible interpretation. The structure was difficult for the application designers to understand, and led to interpretations of its meaning which not only differed from that intended, but also from each other.
Samples of the various data files were obtained from UnCover and scripts or programs written to convert this data into a form which could be input to ORACLE. Ultimately the data to be loaded was a snapshot of the UnCover service when it closed down. Once the service had been restarted in the UK, the system would start applying updates to the database, so there would be no possibility of having a second go. This was therefore one of the crucial aspects of the cutover and had it gone wrong, it could easily have caused the whole exercise to be delayed.
In addition to the UnCover data, the source of document delivery was being changed from the UnCover organisation to CISTI (for deliveries in the North America) and the British Library (for deliveries elsewhere) This required that the system know about which journals were covered by the two services in order that it did not take an order for a document which the delivery service had no possibility of fulfilling. IT also needed certain components of the price which has to be calculated on the fly for each article. A similar problem to the article matching arose here. It was necessary to take the relevant details of an article (i.e. journal title, ISSN, publication year, volume and issue) from one source and match them against another source to find out whether the relevant document delivery service could deliver the article. Although this worked reasonably well most of the time, it did initially produce a significant number of errors and, since the documents were paid for, complaints from users which were extremely time consuming to resolve.
This was easily the most complex part of the operation. In addition to the ability to search a database and order documents, UnCover provided a number of additional services (and packages of services) which needed to be replicated. These included:
The work started by identifying "domain experts" who were interviewed by system designers in an attempt to capture all the relevant information about that domain (i.e. that aspect of the service) and which was then written up as a descriptive document and formed the basis of a system design specification. This was probably a useful exercise, though the quality of the documents produced varied considerably. The most common problems were failure to capture sufficient detail and failure to appreciate the subtleties of some of the issues. This led to some of the documents being too bland, even after being reviewed and reissued.
The descriptive documents were converted into an overall system design and then into detailed specifications. The system ran on a series of Sun systems running Unix. The application software was coded was mostly in Java, though a lot of functionality was encapsulated in ORACLE triggers and procedures. Java proved to have been a good decision as there was a sufficiently large pool of expertise in this area. The Web sessions were controlled by WebLogic and this did cause a number of problems, probably no more than would be expected when dealing with a piece of software most people had little experience of.
Inevitably the main problems occurred immediately after the system went live. Given the timescale involved it was impossible to run adequate large scale system tests and the first few weeks were extremely traumatic with the system failing and having to be restarted, alerting services producing inexplicable results and articles which had been ordered failing to arrive.
It had originally been the intention to look for an alternative to BasisPlus as the main bibliographic DBMS. Given that ORACLE was being used for other data, it would have been reasonable to have switched to this. Sometime before, there had been a review of the various possibilities and extensive discussions with the suppliers. Based on this, a provisional decision was taken to switch to using Verity. This was chosen mainly because it was seen as being able to provide the necessary performance for textual searching, whereas there was some doubt about the ability of the ORACLE InterMedia software to provide a sufficiently rapid response.
Faced with the implementation pressures, the switch to an unknown and completely untried DBMS was quickly abandoned. It was still thought that ORACLE might be a viable alternative and the original database design did include tables for storing this information.
Sometime after the system went live, a large scale experiment was conducted to test the speed of ORACLE InterMedia and the resulting response times showed that the conservative approach had in fact been correct.
It is inevitable that transferring a mature and complex service such as UnCover and at the same time making major changes to the way it worked was always going to be risky. Given the scale of the undertaking, it is perhaps surprising that it worked as well as it did, and criticism after the event is always easy. Nonetheless, there have to be things which could have worked better.
There seems to be an unshakeable rule in these cases that the timescale is set before the task is understood and that it is invariably underestimated. In this case, this was exacerbated by the need to bring in a large number of contract staff, who although they were often very competent people, had no experience of this sort of system and who therefore found it difficult to judge what was important and what was not.
Flowing from this, there was a serious communication problem. The knowledge of the working of the UnCover system resided in the U.S. and while there were extensive contacts, this is not a substitute for the close proximity which allows for extended discussions over a long period and for the easy, ad hoc face to face contact which allows complex issues to be discussed and resolved. The telephone and email are poor substitutes for real meetings. The upshot was that some issues took days of emailing back and forth to resolve and even then were sometimes not fully appreciated.
In addition to the difficulties of international communication, the influx of a large number of new staff meant that there was too little time for personal relationships to have built up. There was a tendency for people to work from the specification given, rather than discussing the underlying requirements of the system. The importance of forging close working relationships, particularly on a large and complex project such as this is hard to overemphasise.
The project control methodology used was based on a tightly controlled procedure involving the writing of detailed specifications which are reviewed, amended, and then eventually signed off and implemented. This method is roughly at the other end of the spectrum from what we might call the informal anarchy method. Plainly it has many advantages, and there is no suggestion that an very informal method could have worked here; the problem was simply too complicated. It does however have its drawbacks, and the main one is its rigidity. The specification, whatever its deficiencies, tends to become holy writ and is difficult to adjust in the light of further knowledge. As with many projects, the increasing pressures resulted in the procedures becoming more relaxed, but it is at least debatable whether a more flexible approach should have been used from the start.
Given the bibliographic details of journal articles, there are basically two approaches to the problem of taking any two sets of details and asking whether they refer to the same article.
The details will normally consist of:
In addition, some bibliographic databases include an abstract of the article. BLIS does not, but this is not relevant to this discussion.
The problems arise because different databases catalogue articles using different rules. There will be differences in the use of mark-up, in capitalisation (particularly in journal names), and most notoriously in the rules for author names, where some include hyphens and apostrophes, and some do not, some spell out forenames and other provide only initials, some include suffixes (e.g. Jr., III, IV) and others don't. Also, databases differ in what they include, some for example treat book reviews as a single article within an issue whereas others treat each review separately and others exclude reviews, some include short news articles whereas others don't, and so on. Given these variations, it's plainly impossible to get an exact solution and the real questions are (a) do we prefer the algorithm to err in certain ways rather than others, and (b) how do we measure whether the algorithm is behaving "reasonably"?
One approach is to use information in the article title and author names (probably only the first one or two), along with some other information e.g. journal name and ISSN. This method had been used in the past and while for some purposes it worked reasonably well, the particular implementation depended on a specialised database containing encoded versions of the article title etc, in order to provide acceptable performance. It would either have been necessary to use the same system here or to have written the matching code ourselves (both of which would have meant a great deal of extra work).
There was no possibility of using this solution, so it was decided to try a completely different and computationally much simpler approach which could easily be programmed to run in a reasonable time.
The preference here was to err on the side of not matching, if possible, and an attempt was made to measure the effect of this by looking at articles which had successfully matched and checking that there were no erroneous matches. On this measure, the algorithm worked well. Unfortunately, measuring the opposite effect (i.e. those which should have matched, but did not) is extremely difficult without being able to anticipate the reasons why this might happen. These inevitably come to light later. There were two main ones:
This case study was written by Clive Massey, a former employee of BIDS/ingenta.
This case study describes the deployment of XHTML 1.0 on the QA Focus Web site and the proposed approaches taken to changing the MIME type.
Note that this case studies will be updated once the changes described in the document have been made.
The QA Focus Web site [1] is based primarily on the XHTML 1.0 standard. The decision to use XHTML was taken for several reasons:
The Web site is based on simple use of the PHP scripting language. Key resources are stored in their own directory. A intro.php file is used to include various parameters (title and author details, etc.), navigational elements of the page and the main content of the page, which is managed as a separate XHTML 1.0 fragment.
HTML-kit [2] is used as the main authoring tool.
The ,validate, ,rvalidate and ,cssvalidate tools [3] [4] are used to validate resources when they are created or updated.
Following comments on W3C's QA list [5] it was recognised that use of the text/html MIME type, which was used when both HTML and XHTML resources were served, did not represent best practice. Although the XHTML resources could be displayed by Web browsers the MIME type used meant that XHTML resources would be processed as HTML. Use of the application/xhtml+xml MIME type would mean that browsers which can process XML would process the resource more quickly, as the XML renderer would only have to process a well-structured XML tree, rather than parse HTML and seek to process HTML errors (as HTML browsers are expected to do).
It was also noted that use of the text/html MIME type required compliance with an additional set of guidelines documented in Appendix C of the XHTML 1.0 specification [6] and the XHTML Media Types document [7].
In addition to providing potential benefits to end users, use of the application/xml MIME type will help with the growth of a better-structured Web environment for the benefit of everyone.
Although deployment of the application/xhtml+xml MIME type for use with XHTML resources on the QA Focus Web site would reflect best practices for XML resources, this change does have some potential pitfalls. Before making any changes it is important to be aware of potential problem areas.
The XML standard insists that XML resources must comply with the standard. Conforming XML application should not attempt to process non-compliant resources. This means that if a XHTML resource is defined as XML using the application/xhtml+xml MIME type Web browsers would not be expected to display the page if the resource contained XHTML errors.
Although it is perfectly reasonable that a program will not process a resource if the resource does not comply with the expected standard, this behaviour is not normally expected on the Web. The HTML standard expects Web browsers to attempt to render resources even though they do not comply with the standard. This led to a failure to appreciate the importance of compliance with standards which has resulted in many Web resources being non-compliant. Unfortunately this makes it very difficult for Web resources to be repurposed or to be processed as efficiently as they should be.
The move to a compliant XHTML environment clearly has many advantages. However there are several potential deployment difficulties:
Ideally a workflow system which can guarantee that the resources are compliant would be used. This could be based on use of a Content Management System (CMS) or processing of resources by software such as Tidy [8] prior to publishing on the main Web site. However due to lack of resources, we are not in a position currently to move to this type of publishing environment.
We therefore intend to ensure that documents are XHTML compliant when they are published. The information providers for the Web site will be made aware that ensuing compliance is now mandatory rather than highly desirable.
MIME types are often associated with resources by mapping a file extension with a MIME type in the server configuration file. For example, files with a .html extension are normally given a text/html MIME type. It would be very simple to give files with a .xhtml extension an application/xhtml+xml MIME type. However in our environment most files have the extension .php; these PHP scripts are processed in order to create the XHTML resource. Fortunately it is possible for the PHP script to define the MIME type to be used. This is the approach we intend to deploy.
However in order to allow us to migrate back to use of the text/html MIME type if we experience problems, we will ensure that the MIME type is defined in a single location. This has the advantage that if we wish to deploy an alternative XML MIME type in the future it can be done relatively easily.
Unfortunately some browsers do not understand the application/xhtml+xml MIME type - including Internet Explorer [9]. In order to support such browsers it is necessary to use content negotiation to serve the XHTML 1.0 resource as text/html to Internet Explorer with application/xhtml+xml being sent to other browsers.
As described above we intend to implement XHTML and the application/xhtml+xml MIME type in the following way:
We will probably use the following PHP code:
<?php
if ( stristr($_SERVER["HTTP_ACCEPT"],"application/xhtml+xml") ) {
header("Content-type: application/xhtml+xml");
}
else {
header("Content-type: text/html");
}
?>which was documented in the "The Road to XHTML 2.0: MIME Types" article [10], which also provides very useful background information on this topic.
Prior to making the proposed changes we will seek advice on our approach by inviting comments on this document.
We will then validate the Web site to ensure that all XHTML resources are compliant.
Once the changes are implemented we will check the Web sites using a number of browsers which are available locally. This will include Internet Explorer, Netscape, Mozilla, Opera, Avant and Lynx on a Microsoft platform. We will invite others who have additional browsers of browsers on other platforms to confirm that the Web site is still functional.
If we were to start again, we would ensure that the PHP template contained allowed HTTP headers to be sent. Currently the template does not allow this.
We would also ensure that there was a technical review meeting of members of the QA Focus team which would discuss the advantages and disadvantages of XHTML and procedure a document given our choice of HTML formats and the reasons for the choice.
We would explore the possibilities of running Tidy on the server as part of the publishing process.
Brian Kelly
UKOLN
University of Bath
BATH
UK
BA2 7AY
Email: B.Kelly AT ukoln.ac.uk
For QA Focus use.
It is important that HTML resources comply with the HTML standard. Unfortunately in many instances this is not the case, due to limitations of HTML authoring and conversion tools, a lack of awareness of the importance of HTML compliance and the attempts made by Web browsers to render non-compliant resources. This often results in large numbers of HTML pages on Web sites not complying with HTML standards. An awareness of the situation may be obtained only when HTML validation tools are run across the Web site.
If large numbers of HTML pages are found to be non-compliant, it can be difficult to know what to do to address this problem, given the potentially significant resources implications this may involve.
One possible solution could be to run a tool such as Tidy [1] which will seek to automatically repair non-compliant pages. However, in certain circumstances an automated repair could results in significant changes to the look-and-feel of the resource. Also use of Tidy may not be appropriate if server-side technologies are used, as opposed to simple serving of HTML files.
This case study describes an alternative approach, based on use of W3C's Web Log Validator Tool.
W3C's Log Validator Tool [2] processes a Web site's server log file. The entries are validated and the most popular pages which do not comply with the HTML standard are listed.
The Web Log Validator Tool has been installed on the UKOLN Web site. The tool has been configured to process resources on the QA Focus area (i.e. resources within the http://www.ukoln.ac.uk/qa-focus/ area.
The tool has been configured to run automatically once a month and the findings held on the QA Focus Web site [3]. An example of the output is shown in Figure 1.
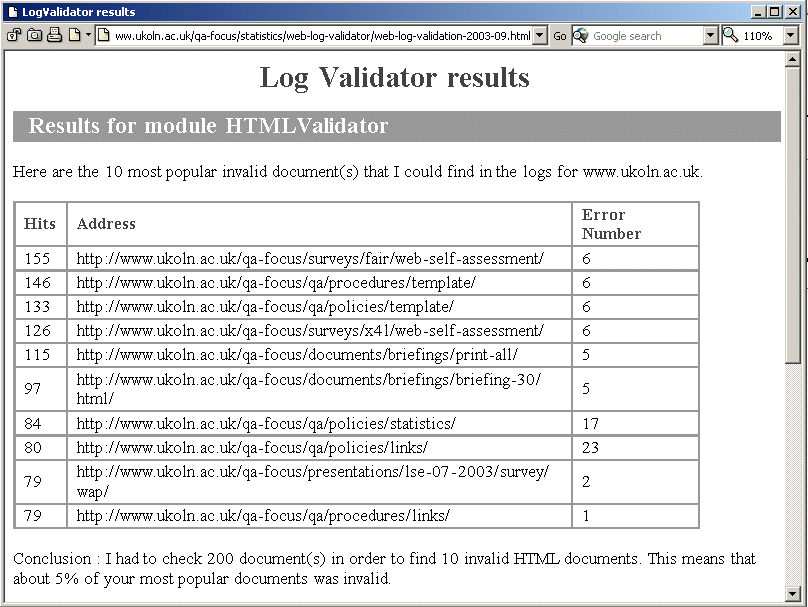
Figure 1: Output From The Web Log Validator Tool
When the tool is run an email is sent to the Web site editor and the findings are examined. We have a policy that we will seek to fix HTML errors which are reported by this tool.
This approach is a pragmatic one. It helps us to prioritise the resources to fix by listed the most popular pages which are non-compliant. Since only 10 non-compliant pages are listed it should be a relatively simple process to fix these resources. In addition if the errors reflect errors in the underlying template, we will be in a position to make changes to the template, in order to ensure that new pages are not created containing the same problems.
We have internal procedures for checking that HTML pages are compliant. However as these procedures are either dependent on manual use (checking pages after creation or updating) or run periodically (periodic checks across the Web site) it is useful to make use of this automated approach as an additional tool.
Ideally this tool would be deployed from the launch of the Web site, in order to ensure best practices were implemented from the start.
Brian Kelly
UKOLN
University of Bath
BATH
UK
BA2 7AY
Email: B.Kelly AT ukoln.ac.uk
For QA Focus use.
The aim of the Healthier Nation [1] project is to identify suitable learning materials from JISC-funded resource databases and/or content repositories and re-purpose a sample of the material as learning chunks to support Health and Social Care curriculum delivery (at FE and HE Levels. The project has specifically focused on "the Big Four" diseases affecting Scotland: Cancer, Coronary Heart Disease, Stroke and Mental Illness.
The first Strand of the project has been concerned with research and evaluation. The objectives of strand 1 have been to identify and evaluate relevant materials on the "big 4" diseases by:
Academic experts from each partner institution prepared a 'mapping grid' to assist the research team to identify relevant resources. The grid included information on key subject areas, specific keywords and exclusions, courses which could use the material (including the level) and any relevant learning outcomes.
As the emphasis for the academic staff was on finding resources that could be used in teaching situations at FE and initial HE levels - possibly with some element of re-purposing - the research team concentrated on the relevant subject gateways, rather than bibliographic sources and indexes.
To provide a structured framework for the evaluation of the learning material, resource sheets were used to record relevant details. The sheets ensured that the evaluation criteria used by all partner institutions were consistent.
The researcher team evaluated all the learning material on their content (clarity, authority, bias, level) and their style and functionality. Copyright details were also recorded for future re-purposing. Restricted vocabularies were used whenever possible to assist metadata tagging of learning objects. Resource sheets were then passed to academic staff to evaluate their appropriateness for teaching and to indicate how they could be used (delivery type, mapped to level/course, any re-purposing that would be required).
The intention was to carry out accessibility evaluations on a selection of the resources during this part of the project. A key issue that has affected this work has been the lack of agreed criteria for accessibility evaluations. One of the project partners, RNC, has been working with TechDis to develop a model for evaluating resources and the accessibility evaluation of the resources will now be carried out at a later stage of the project.
Following evaluation, the materials were:
The research team had difficulty in retrieving relevant material for the project using the search options in RDN subject gateways. Whenever two subject terms were combined the number of hits was drastically reduced. The search term "Heart" for example, retrieved 312 sites in BIOME; by adding a second term "Heart physiology" this was reduced to 8 sites. Search terminology was often restricted to key areas only, e.g. neoplasm, then the researchers trawled through the numerous hits to find materials – a lengthy process, but the only way to ensure that useful material had not been missed.
Searching under the sub-headings that had been provided by the academic staff produced few or in some cases no hits. A BIOME search for "ACE inhibitors" only retrieved 1 site. To provide enough material for the future strands of the project, Google was also used to locate materials for both mental illness and coronary heart disease/stroke.
On average only one in 10 of the resources located were passed to the academic staff for evaluation. The majority were too advanced, predominantly text based and therefore had no advantages over a textbook, or did not cover the project's subject areas (particularly the sub-headings/keywords).
Over 500 resources were evaluated by academic staff, but only 46% made it to the final repository of resources, or as a supplementary teaching resource. The main reasons for the rejection of the remainder were that the material was:
Academic staff felt that, while some of the resources were excellent (particularly for cancer), in general the resources have not been as good as expected and there were not enough graphic or interactive materials for re-purposing. Mental health resources were geared towards the layperson and had a heavy emphasis on organisations.
Most of the resources went through a secondary evaluation stage to ensure that comments made by FE academic staff were applicable for HE and vice versa. In the secondary evaluation, there was general agreement between the academics in FE and HE about the usefulness of the resources. Although some materials were either too high or too low a level, others were rejected because of their similarity or due to problems of access.
All of the academics involved in the project, felt that they would use alternative sources to locate material. Google was their preferred option as it gave access to relevant material more easily than the subject gateways and has the advantage of advanced search strategies, including searches for images, applying multiple search terms, restricting searches by country of origin.
Addressing points 3 and 4 above should significantly reduce the time tutors would have to spend on searching for resources.
Heather Sanderson
Project Manager
Email: heather@kerson1.freeserve.co.uk
This document is based on one of the Research reports available from the Healthy Nation Web site. For further information please see these reports.
The JISC and ESRC-funded SOSIG service [1] is one of the longest running RDN subject gateways. SOSIG provides access to high quality, peer-reviewed records on Internet resources in the area of Social Science, Business and Law.
Many projects will be providing metadata which describes projects' deliverables, which may include resource discovery or educational metadata.
In order for projects to gain an understanding of the importance which JISC services place on the quality of metadata, this case study has been written which describes the approach to 'spring-cleaning' which SOSIG has carried out as one of its quality assurance procedures in order to ensure that its records continued to provide high quality information.
The core of the SOSIG service, the Internet Catalogue, holds over 26,000 structured metadata records describing Internet resources relevant to social science teaching, learning and research. Established in 1994, SOSIG is one of the longest-running subject gateways in Europe. The subject section editors have been seeking out, evaluating and describing social science Internet resources, developing the collection so that it now covers 17 top-level subject headings with over 1,000 sub-sections. Given the dynamic nature of the Internet, and the Web in particular, collection development is a major task. Collection management (i.e. weeding out broken links, checking and updating records) at this scale can also be something of a challenge.
The SOSIG core team, based at ILRT in Bristol, devotes considerable resource to removing or revising records with broken links (human checks based on reports from an automated weekly link-checking programme). Subject section editors, based in universities and research organisations around the UK, also consider durability and reliability of resources as part of the extensive quality criteria for inclusion in the Catalogue. They regularly check records and update them: however, the human input required to do this on a systematic and comprehensive scale would be beyond current resources. SOSIG has therefore recently embarked on a major 'spring cleaning' exercise that it is hoped will address this issue and keep the records current. We describe below the method, and outcomes to date.
There are several reasons why such collection management activity is important. User feedback indicates that currency of the resource descriptions is one of the most appreciated features of the SOSIG service. SOSIG and other RDN hubs are promoted on the basis of the quality of their records: offering out-of-date descriptions and other details is likely to frustrate users and, in the long term, be detrimental to their perceptions and therefore use of the service. Recent changes in data protection legislation also emphasise the obligation to check that authors/owners are aware of and happy with the inclusion of their resources in SOSIG. Checking with resource owners also appears to have incidental public relations benefits and is helping to develop the collection by identifying new resources from information publishers and providers.
How did we go about our spring-clean? Each of the metadata records for the 26,000 resources catalogued in SOSIG contains a field for 'administrative email' - the contact email address of the person or organisation responsible for the site. We adapted an existing Perl script (developed in ILRT for another project), which allowed a tailored email to be sent to each of these addresses. The message includes the URL of the SOSIG record(s) associated with the admin email. Recipients are informed that their resources are included in SOSIG and are asked to check the SOSIG record for their resource (via an embedded link in the message) and supply corrections if necessary. They are also invited to propose new resources for addition to the Catalogue.
We first considered a mass, simultaneous mailout covering all 26,000 records. The script sends one message per minute to avoid swamping the servers. However we had no idea of the level of response likely to be generated and wanted to avoid swamping ourselves! We therefore decided to phase the process, running the script against batches of 2,000 records on a roughly monthly basis, in numerical order of unique record identifiers, these were grouped notifications so that an administrator would get one email referring to a number of different sites/pages they were responsible for. The process was run for the first time at the end of July 2002 and, on the basis of low-numbered identifiers, included records of resources first catalogued in SOSIG's early days. The SOSIG technical officer oversaw the technical monitoring of the process, whilst other staff handled the personal responses, either dealing with change requests or passing on suggestions for additional resources to Section Editors responsible for specific subject areas on SOSIG.
In total we received 950 personal responses (approximately 4%) from email recipients. A further 3,000 or so automated 'bounced' responses were received. Those of us who are regular and long-term users of the Web are well aware of the fairly constant evolution of Web resource content and features. The SOSIG spring clean exercise also highlights the extent of change in personnel associated with Web resources. As mentioned above, of the emails sent relating to the first 4,000 records, over a quarter 'bounced' back. Although a very small proportion of these were automated 'out of office' replies, most were returned because the address was no longer in use.
The majority of the personal responses requested a change in the URL or to the administrative email address recorded for their resource. Many had stopped using personal email addresses and had turned to generic site or service addresses. Others reported that they were no longer responsible for the resource. As the first batches included older records, it will be interesting to see whether the proportion of bounced and changed emails reduces over time, or whether people are really more volatile than the resources.
We have to assume that the remaining email recipients have no cause for complaint or change requests. In fact, we were very pleased at the overwhelmingly positive response the exercise has generated so far. Many simply confirmed that their records were correct and they were pleased to be included. Others noted minor corrections to descriptions, URLs and, as mentioned, admin email addresses. Many also took the time to recommend new resources for addition to the Catalogue. Only one or two concerns were raised about the inclusion of certain data in the recorded, although there were several queries which highlighted changes needed to the email message for the second and subsequent batches.
One of these arose as a result of the de-duplication process, which only operates within each batch of 2,000 records. Where the same admin email address is included in records excluded from that batch, the de-duplication process ignores it. Some recipients therefore asked why we had apparently included only some of their resources, when they are actually on SOSIG, just not in that particular set of records.
Only one major issue was raised, that of deep-linking. It seems that this is a problem for one organisation, and raises questions about the changing nature of the Web - or perhaps some companies' difficulty in engaging with its original principles. Time will tell whether this is an issue for other organisations: to date it has been raised only once.
Spring-cleaning in domestic settings always involves considerable effort, and the SOSIG spring clean is no exception. SOSIG staff spent about a week, full-time, dealing with the personal responses received after each batch of 2,000 records were processed. The first batch of messages all had the same subject line, so it was impossible to distinguish between responses appearing in the shared mailbox used for replies. In the second 2,000, the subject line includes the domain of the admin email address, which makes handling the responses much easier.
Bounced messages create the most work, because detective skills are then necessary to check resources 'by hand' and search for a replacement admin email address to which the message can then be forwarded. Minor corrections take little time, but the recommendation of new resources leads to initiation of our usual evaluation and cataloguing processes which can be lengthy, depending on the nature and scale of the resource.
We realised that timing of the process could have been better: initiating it in the middle of Summer holiday season is likely to have resulted in more out-of-office replies than might be expected at other times. Emails are now sent as routine to owners of all new additions to the catalogue: this complies with the legal requirements but is also an additional quality check and public relations exercise. Once informed of their inclusion in the gateway, resource owners may also remember to notify us of changes in future as has already been the case!.
Although time-consuming, the spring clean is still a more efficient way of cleaning the data than each Section Editor having to trawl through every single record and its associated resource. Here we are relying on resource owners to notify us of incorrect data as well as new resources: they are the ones who know their resources best, and are best-placed to identify problems and changes.
If you are providing metadata which will be passed on to a JISC service for use in a service environment the JISC service may require that the metadata provided is still up-to-date and relevant. Alternatively the service may need to implement validation procedures similar to those described in this document.
In order to minimise the difficulties in deploying metadata created by project into a service environment, projects should ensure that they have appropriate mechanisms for checking their metadata. Ideally projects will provide documentation of their checking processes and audit trails which they can make available to the service which may host the project deliverables.
This document is based on an Ariadne article entitled "Planet SOSIG - A spring-clean for SOSIG: a systematic approach to collection management" originally written by Lesley Huxley, Emma Place, David Boyd and Phil Cross (ILRT). The article was edited for inclusion as a QA Focus case study by Brian Kelly (UKOLN) and Debra Hiom (ILRT).
Contact details for the corresponding authors is given below.
| Debra Hiom ILRT University of Bristol Bristol Email: d.hiom@bristol.ac.uk |
Brian Kelly UKOLN University of Bath BATH Email: b.kelly@ukoln.ac.uk |
Citation Details:
"Approaches To 'Spring Cleaning' At SOSIG",
by Debra Hiom, Lesly Huxley, Emma Place, David Boyd and Phil Cross (ILRT)
and Brian Kelly (UKOLN).
Published by QA Focus, the JISC-funded advisory service, on 17th October 2003.
Available at
<http://www.ukoln.ac.uk/qa-focus/documents/case-studies/case-study-25/>
This document was originally published as a "Planet SOSIG" column in the Ariadne ejournal.
Figure 1: The Library Online Entry Point
Library Online [1] (shown in Figure 1) is the main library Web site/portal for the University of Edinburgh [2]. Although clearly not a project site in itself, one of its functions is to provide a gateway to project sites with which the Library is associated [3].
In the last seven years or so it has grown to around 2,000 static pages plus an increasing amount of dynamic content, the main database-driven service being the related web-based Library Catalogue [4]. At the time of writing (October 2003), a proprietary Digital Object Management System has been purchased and is being actively developed. This will no doubt impinge on some areas of the main site and, in time, probably the Catalogue: notably access to e-journals and other digital resources/collections. However, for the time being, Library Online and the Catalogue between them provide the basic information infrastructure.
The challenges include enhancing accessibility and usability; also maintaining standards as these develop. Problems exist with legacy (HTML) code, with increasingly deprecated layout designs and separating content from presentation. Addressing these issues globally presents real problems whilst maintaining currency and a continuous, uninterrupted service. It is, of course, a live site - and an increasingly busy one. There are currently over twenty members of staff editing and publishing with varying levels of expertise and no overall Content Management System, as such.
Policy has also been to maintain support for a whole range of older browsers, further complicating matters.
Fortunately, the site design was based on Server-Side Includes (SSIs) and a great deal of effort was put into conforming to best practice guidelines as they were articulated over five years ago. The architecture appears to remain reasonably sound. So an incremental approach has been adopted generally, though some enhancements have been achieved quite rapidly across the board by editing sitewide SSIs. A recent example of the latter has been the introduction of the "Skip Navigation" accessibility feature across the whole site.
A fairly radical redesign of the front page was carried out within the last two years. This will need to be revisited before too long but the main focus is presently on the body of the site, initially higher level directories, concentrating on the most heavily-used key areas.
Enhancements to accessibility and usability are documented in our fairly regularly updated accessibility statement [5]. These include:
None of these features should be contentious, though precise interpretations may vary. Many have been built in to the design since day one (e.g. "alt" tags); others have been applied retrospectively and incrementally. All are, we hope, worthwhile!
Additional functionality with which we are currently experimenting includes media styles, initially for print. The original site navigation design was quite graphically rich and not very "printer-friendly". Progress is being made in this area - but who knows what devices we may need to support in the future? Perhaps we shall eventually have to move to XML/XSLT as used within our Collections Gateway due for launch soon. Meanwhile, for Library Online, even XHTML remains no more than a possibility at present.
Our approach to site development is essentially based on template and stylesheet design, supported by Server-Side Include technology for ease of management and implementation. This largely takes care of quality assurance and our proposed approach to content management should underpin this. We are moving towards fuller adoption of Dreamweaver (MX) for development and Macromedia Contribute for general publishing. Accessibility and usability quality assurance tools are already in regular use including LIFT Online and other resources identified on the site. It seems very likely that this will continue.
All this remains very much work in progress ... Upgrading legacy code, layout design, integration and interoperability with other information systems etc. Categorically, no claims are made for best practice; more a case of constantly striving towards this.
The main problems experienced - apart from time and resources naturally - have been:
With the benefit of hindsight, perhaps stylesheets could have been implemented more structurally. Validity has always been regarded as paramount, while separation of true content from pure presentation might have been given equal weight(?) This is now being reassessed.
We might have derived some benefit from more extensive database deployment - and may well in the future - but we must constantly review, reappraise possibilities offered by new technologies etc. and, above all, listen to our users.
I have referred to some significant developments in prospect which present more opportunities to do things differently - but whether we get these right or wrong, there will always be scope for improvement on the Web, just as in the "real" world. Like politics, it seems to be the art of the possible - or should that be a science?
Steve Scott, Library Online Editor (steve.scott@ed.ac.uk)
For QA Focus use.
This case study focuses on two of the database services that were created and operated as part of the BIDS [1] service: the ISI service and the IBSS service. It describes the experience of launching and supporting these services and discusses lessons learned that might be of value to the creators of other services. The experience demonstrates how a professional approach to service design, support and delivery reflects well on service creators, service operators and the sponsoring bodies. It also demonstrates how community involvement at all stages has a range of important benefits.
The ISI service was the first, and is probably still the best known of the services sponsored by the JISC. Launched in 1991, the BIDS service provided access to the bibliographic databases (or citation indexes) supplied by the Institute for Scientific Information. It was the first large scale, national, end-user service of its kind anywhere in the world. Originally launched as a telnet service, a Web interface was introduced in 1997. This service was replaced in 2000 by the Web of Science operated by MIMAS in which both the data and the service interface are supplied by ISI.
The BIDS IBSS service was launched in 1995. Introduced with a similar interface to the BIDS ISI service, it provided access to bibliographic data indexed and supplied by the International Bibliography of the Social Sciences [2] team based in the library at the London School of Economics (the BLPES). This service was also originally launched as a telnet service, with a Web interface being introduced in 1997. It continues to be operated by BIDS under Ingenta management.
Although these events took place several years ago, much of the experience gained continues to be of relevance and importance to new services being launched today.
When the first ISI service was launched, there were no similar services available, and this presented a major challenge when it came to developing a strategy to bring this new end-user service to the attention of those who could benefit from it. By the time the IBSS service was launched in 1995, it was a more mature market place and the process had become somewhat easier, though a number of the original challenges still remained.
The basic problem was that of creating effective communication channels where none existed before.
The solutions adopted to these issues of communications were manifold and arguably each had a role. New services should consider which of the methods described could be effective for their particular needs.
For both the services mentioned, consultation took place at a number of different levels. As soon as BIDS had been established, a Steering Group was formed. Chaired by a senior librarian, it had representatives from major research libraries, politicians and the BIDS service itself. It provided a valuable sounding board for strategic development of the service, but more importantly from a promotional point of view, it provided an information channel back to the home institutions of the members on current and future service developments. As IBSS is itself a JISC-funded service, it has its own steering group which provides a valuable sounding board for service performance and developments and a forum for announcements.
When the original BIDS ISI service was launched, it wasn't clear how to set about designing an end user service for such a disparate audience. An important contribution to the success of the service was the establishment of a working group to help with the service design, including functionality and screen design. Drawn from a large number of different institutions, most of the members were librarians with experience in the use of online and CD-ROM based search services. As well as supplying important knowledge and experience of good design, like the Steering Group members, they became natural ambassadors for the new service.
Shortly after the first BIDS service was launched, a BIDS User Group was formed. Subsequently, when MIMAS and EDINA were established the group widened its remit and became known as the JIBS user group [3]. Again this group became a two-way communication channel, lobbying for change and improvement, but also becoming a natural route for disseminating information about the services and their development to intermediaries and thence to end-users.
In summary, one of the important factors in the success of these services was community involvement in all stages of service development, as well as the actual service launch.
The BIDS ISI service first became publicly available on 18th February 1991. In the run-up to the launch, regular news bulletins were sent to a new mailing list set up in Newcastle on the service which became known as Mailbase (now replaced by JISCmail [4]). This helped keep all the supporters of the new service in touch with progress on how the service was being developed prior to launch. This enabled us to advertise a series of launch events and demonstrations which were held at various locations around the UK near the time of the start of service.
When the IBSS service agreement was signed in 1994, a more sophisticated approach was taken with a formal press release being issued by the library at LSE (BLPES). When the service itself was launched in January 1995, a series of joint IBSS/BIDS launch events were held around the UK including live demonstrations and 'hands-on' sessions.
It is very common for project timescales to become invalidated by a range of different factors, many outside the service-provider's control. It is important to keep key stakeholders informed as soon as practical of any likely changes to published timescales, even if new dates are difficult to confirm. Regular postings to mailing lists provided a very useful vehicle for keeping people up to date on progress with service launches or the introduction of new features. This was especially important when published dates were close to the start of the academic year.
A key feature of the early BIDS services was community involvement in the design and writing of a wide range of support material. Although these experiences may not be directly applicable to the present day environment, the general principle of involvement is still valid as an important factor in successful launch and support of new services.
With funding from a central training materials initiative, a suite of ISI service support material (flyers, posters, user guides, training materials) was developed with the aid of around 24 volunteers from 20 different institutions. The design of these materials formed the basis of similar materials developed later for additional services such as IBSS.
Both of these services (ISI and IBSS) went through a series of developments during their lifetime. Managing service development is an important issue. In general at any given time there will be pressure from a number of parties for changes to be made to a service. Each potential development will have costs as well as benefits. The benefits have to be assessed and prioritised in the context of their value to the service and its users as well as the cost in terms of time and effort. Developments can be typically either low or high value and low or high cost. Relatively low value improvements may still be worth making if their cost is also low. On the other hand, high value developments may still not be justified if their cost is judged to be excessive (or there may be a case for additional funding to carry out the development).
For the ISI service, an example of an early and important, though costly development, was citation searching (searching for all the papers in the database that have identified or cited a particular work in their list of references). Because this was a unique feature of the database (the indexing of all the citations for each paper), all concerned felt it was vital that the facility should be created. It is interesting to note that monitoring of user activity after citation searching was made available showed disappointingly low levels of use of the facility, despite extensive publicity and the creation of documentation and training support materials, etc. In practice the vast majority of searches are simple words or phrases from titles or abstracts, or author names.
Services such as BIDS-ISI and BIDS-IBSS need to be monitored. Funding bodies are keen to establish whether their investment has been wisely spent, and service providers need to judge performance against an agreed set of criteria. The JISC's Monitoring and Advisory Unit (now the Monitoring Unit [5]) drafted Service Level Agreements for each database service. Quarterly reports demonstrate how the services have delivered against the benchmarks agreed. These include usage levels, help desk activity, registrations, documentation and support material, promotion and marketing activity and hardware availability.
This monitoring has been very useful in establishing the high levels of popularity of these services and demonstrating the quality of service delivery. The figures can also be used to extrapolate likely future usage growth and permit planned increases in resources before the service starts to deteriorate.
In this short document it is only possible to draw a limited number of conclusions from more than a decade of experience of running these services.
The chances of success of any new service will be greatly enhanced by making constructive use of widespread consultation. This can cover a wide range of activities including such things as service functionality, interface design, and desirable facilities.
Consideration should be given to marking the launch of a new service in some suitable manner. Depending on the type of service, its intended clientele, and the predicted take-up rate, it may be appropriate to hold a formal launch event at a strategic location; this often means London. Alternatively, the announcement could be made at a suitable conference or exhibition. It is unwise to rely on only one or two methods of announcing a new service. Try to think of as many different appropriate routes to both decision makers and potential end-users. The timing of a launch is also important. Be aware of the academic year cycle, and try to avoid the period immediately before the start of the academic year. Probably the optimum time is mid-late summer term, before staff go on holiday but after most of the student pressure is off.
It is a good strategy to keep people informed as to the progress of a new service as launch day approaches. As soon as delays appear inevitable, let people know, even if a revised date hasn't been fixed.
This is one area where the world has changed significantly from the days of the first BIDS services. Most students and many (though not all) staff are much more computer literate and are frequent network users. The general expectation is that a network service should be intuitive to use and not require extensive training or help. Nevertheless it is important that potential subscribers (if it is a paid for service) and users are aware of the scope and limitations of a new service. So some form of descriptive publicity or promotional material is still relevant, and serious consideration should be given to at least some paper-based material as well as online information. Using professional designers for paper-based material is well worth considering.
Launching a new service is only the beginning, not the end. Mechanisms for feedback from users and purchasers should be established. The service should contain contact details for help and advice. Presentations and demonstrations provide forums for discussion and constructive criticism. Find out if there is an existing user group who will extend their remit to cover the service.
When changes are identified and implemented, ensure that the change is publicised well in advance. Unless the change is an important bug fix, try to make the changes infrequently, preferably to coincide with term-breaks.
Discuss with the JISC Monitoring Unit a suitable set of parameters for measuring performance. Benchmarks will normally be established in a Service Level Agreement. Set up procedures for recording the information and then delivering it to the MU at quarterly intervals.
Terry Morrow
Tel: +44 1373 830686
Mobile: +44 7733 101837
Email: tm_morrow@yahoo.co.uk
Terry was Director of the well-known BIDS service from 2000 until September 2003. Previously he had been the Marketing and Training Manager for BIDS from the beginning of the service in 1990. He is now an independent consultant and a member of the UK Serials Group Executive Committee.
In 1996, the BIDS [1] team launched a new service called JournalsOnline. The service was one of the first to provide a single point of entry to electronic versions of articles published in academic journals by more than one publisher. The service was a development of two initiatives, both of which emerged out of the 1993 Higher Education Libraries Review [2] more commonly referred to as the "Follett Report".
The first of these was eLib [3] whose aim was to fund a variety of experiments which would collectively make progress in the sphere of electronic access to library materials.
The second was an experiment known as the Pilot Site Licence Initiative [4] which was designed to try and find a way of stabilising the problem of rising journal subscription costs and to sponsor experiments in providing network access to the full text of these journals.
The BIDS JournalsOnline service brought together these two initiatives into one service. In 1998 management responsibility for BIDS passed to the newly created company known as Ingenta, and JournalsOnline was renamed IngentaJournals.
By the mid 1990s it was common for students and researchers carrying out literature searches to have searched one or more of the growing number of networked bibliographic databases to identify an article of interest. Having discovered an article they wished to read, they had to note down the reference and either try to find a physical copy of the journal containing the article in their local library, or ask the library to order a copy under arrangements commonly known as 'inter-library loan'. In practice this often meant ordering (and paying for) a copy from the British Library's Document Supply Centre. The costs were either covered by the library's budget, or recovered from the enquirer's department.
Around that time, some of the larger publishers were beginning to establish their own Web sites which provided network access to electronic versions of their journals.
The challenge was to find a way of enabling end-users to find articles in these journals, given that they were unlikely to know which publisher would be likely to own journals covering their particular area of interest.
JournalsOnline was a synthesis of two separate activities involving the BIDS team: the eLib-funded Infobike project and the Pilot Site Licence Initiative.
BIDS was a successful applicant for an eLib grant to develop a system for online access to a range of electronic journals from a variety of different publishers. The project, with the rather unlikely title of Infobike [5], had a remit to develop and test in general service a system architecture that would allow end-users (as opposed to intermediaries such as librarians) to identify articles of interest by searching or browsing bibliographic databases or publishers catalogues, to check on the status of the enquirer in relation to institutional subscription rights, and to deliver the full text article, either free of charge or for an on-screen payment.
The original partners in the project included Academic Press, Blackwell Science, CALIM (the Consortium of Academic Libraries in Manchester), ICL and the Universities of Keele, Staffordshire and Kent.
This initiative was the outcome of discussions which took place in 1994 between a small number of publishers and the Higher Education Funding Council for England (HEFCE). The result was a three year experiment (later extended) involving four publishers - Academic Press, Blackwell Science, Blackwell Publishing and the Institute of Physics Publishing. These publishers offered access to their entire journal collection for between 60% and 70% of the normal price. BIDS submitted a proposal to provide a single point of access to the material from the PSLI publishers and three of the four (IOPP declined) agreed to participate.
By taking the technology that was developed under the Infobike project, and combining it with the material that was covered by the PSLI proposal, BIDS was able to create an entirely new service which was christened JournalsOnline. This was launched in November 1996.
The service consisted of a merged publishers' catalogue of bibliographic details of published articles, including titles, authors, affiliations and the full text of any available abstract. Access to the catalogue was set up so that it could be searched either as a registered user or as a guest user. Alternatively the 'contents pages' of journal issues could be browsed to identify articles of interest.
When the user requested the full text, the administration software checked their status. If s/he was registered as belonging to a site that had a subscription to the electronic form of the selected journal, the article was delivered immediately to the screen — typically as a PDF. If the user was from a site that did not subscribe to the selected title, they were given the option of paying for the article, either by account (if one has been set up) or by credit/debit card. Similarly, guest searchers were given the option of article delivery with payment by credit card.
A further development was to take existing bibliographic database services, such as the original BIDS ISI service or IBSS service, and use these for the resource discovery phase. The search systems carried out a check to see which, if any, of the bibliographic search results matched articles in the full text catalogue. Where there was a match, the user was shown a hypertext link to follow to the full text. Special 'fuzzy matching' software was used to cater for minor discrepancies between the titles provided by indexing services such as ISI, and the titles supplied by the publishers.
Resource limitations meant that it was impractical to carry out a subscription status check for every search hit, so the 'full text' link only meant that the article existed in full text form in the collection. Accessibility could only be tested by the user following the link — the system would then carry out the subscription check and either offer to deliver the full text (usually PDF) or sell a copy of the article.
There were numerous issues uncovered by these experiments. There isn't space in this short document to describe all of these in detail, though a number of articles have been published covering many of them. The following summarises some of the major ones.
One of the original goals of the JournalsOnline service was to provide a one-stop-shop, a single web entry point which was the network equivalent of a well-stocked library. From here it should be possible to find 90% of the material needed to support teaching and research.
The reality has turned out to be a bit different. There are tensions between the requirements of the players, including libraries, funding agencies, commercial publishers, and academic researchers. Each has a different ideal solution and optimum economic model. JournalsOnline explored one model, namely a service largely paid for by commercial publishers to provide a shop window for their material. They are also charged for hosting the full text where this is part of the contract.
In 1998 the JISC awarded the National Electronic Site Licence Initiative (NESLI) managing agent contract to a consortium of MIMAS and Swets Blackwell. Part of their remit was to provide another resource discovery service for searching and retrieving electronic articles. Many of the journals covered by NESLI continued to be available in parallel via JournalsOnline.
In the meantime libraries continue to complain about the high costs of journals (paper and electronic), while commercial publishers say that their costs have risen because of the growing amount of material submitted for publication and the additional costs of parallel publishing. At the same time researchers want peer-group recognition for their work in the recognised leading journals in their sphere (usually commercially published), but also want free and instant access to everyone else's publications. They would also prefer to be able to find them with only one search operation (the Google effect).
A number of major publishers have developed their own end-user services, and there has been a growing tendency for smaller publishers to be taken over by, or merge with, their larger peers. While this is going on, parts of the research community are testing out new models of publishing, including self-publishing, institutional publishing and pre-print publishing.
So the original goal of JournalsOnline of providing the user community with a genuine one-stop-shop was unsuccessful. It did however (and still does in the form of the IngentaJournals service) provide an extremely useful service for identifying and delivering a large body of full text material.
As noted earlier, commercial publishing is only one possible model for exposing the results of research. There are numerous experiments for alternative models being carried out, including self-publishing on the Web, publishing of their research output by individual institutions, and pre-print archives. Some references for more information about this work are listed at the end of this article [6], [7], [8].
An apparently growing problem for teachers in higher and further education is the ease with which network publishing has made it possible for students, especially undergraduates, to copy sections of material from already published articles and to portray the work as original. The JISC has set up a unit to provide advice and guidance on this difficult issue [9].
Not all JISC-sponsored initiatives have the potential for developing into a fully fledged commercial service. JournalsOnline and, more recently, HERON [10], have provided examples of a successful transition from funded experiment to profitable commercial product.
One lesson to learn from this is that the possibility of eventual commercialisation should be thought about whenever a new JISC project is commenced. If it is thought likely that the resulting service could have a commercial application, then even greater care needs to be taken with issues such as choice of development platform and the integration of community-developed material which may have been made available in the spirit of mutual sharing.
Another issue to consider is who owns the intellectual property rights of any software, data or other products that may emerge from a project. Even if the JISC has provided funds for the project, the IPR typically belong to the major grant receiving organisation. But you should check carefully to see what the situation is with your project.
Terry Morrow
Phone: +44 1373 830686
Email: tm_morrow AT yahoo.co.uk
Terry was Director of the well-known BIDS service from 2000 until September 2003. Previously he had been the Marketing and Training Manager for BIDS from the beginning of the service in 1990. He is now an independent consultant and a member of the UK Serials Group Executive Committee.
The UK Centre for Materials Education [1] supports academic practice and innovative learning and teaching approaches in Materials Science and Engineering, with the aim of enhancing the learning experience of students. The Centre is based at the University of Liverpool, and is one of 24 Subject Centres of the national Learning and Teaching Support Network [2].
Within any field, the use of discipline-specific language is widespread, and UK Higher Education is no exception. In particular, abbreviations are often used to name projects, programmes or funding streams. Whilst use of these initialisms can be an essential tool of discussion amongst peers, they can also reduce accessibility and act as a barrier to participation by others.
In this context, many individuals and organisations maintain glossaries of abbreviations. However, glossaries of this nature usually require manual editing which can be incredibly resource intensive.
This case study describes a tool developed at the UK Centre for Materials Education to help demystify abbreviations used in the worlds of Higher Education, Materials Science, and Computing, through the use of an automated 'Web crawler'.
The HTML 4 specification [3] provides two elements that Web authors can use to define abbreviations mentioned on their Web sites; <abbr> to markup abbreviations and <acronym> to markup pronounceable abbreviations, known as acronyms.
The acronyms and abbreviations are normally identified by underlining of the text. Moving the mouse over the underlined words in a modern browser which provides the necessary support (e.g. Opera and Mozilla) results in the expansion of the acronyms and abbreviations being displayed in a pop-up window. An example is illustrated in Figure 1.
Figure 1: Rendering Of The <ACRONYM> Element
Using this semantic markup as a rudimentary data source, the crawler retrieves Web pages and evaluates their HTML source code for instances of these tags. When either of the tags is found on a page, the initials and the definition provided are recorded in a database, along with the date/time and the URL of the page where they were seen.
The pairs of abbreviations and definitions identified by the crawler are then made freely available online at [4] as illustrated in Figure 2 to allow others to benefit from the work of the crawler.
The limiting factor first encountered in developing the crawler has been the lack of Web sites making use of the <abbr> and <acronym> tags. Consequently, the number of entries defined in the index is relatively small, and the subject coverage limited. Sites implementing the tags are predominantly those that address Web standards and accessibility, leading to a strong bias in the index towards abbreviations used in these areas.
A number of factors likely contribute to a lack of use of the tags. Firstly, many Web authors might not be aware of the existence of the tags. Even in the current generation of Web browsers, there is little or no support for rendering text differently where it has been marked up as an abbreviation or acronym within a Web page. Therefore there is little opportunity to discover the tags and their usage by chance.
The second major factor affecting the quality of the index produced by the crawler has been the inconsistent and occasionally incorrect definition of terms in pages that do use the tags. Some confusion also exists about the semantically correct way of using the tags, especially the distinction between abbreviations and acronyms, and whether incorrect semantics should be used in order to make use of the browser support that does exist.
Figure 2: The Glossary Produced By Harvesting <ABBR> and <ACRONYM> Elements
To provide a truly useful resource, the crawler needs to be developed to provide a larger index, with some degree of subject classification. How this classification might be automated raises interesting additional questions.
Crucially, the index size can only be increased by wider use of the tags. Across the HE sector as a whole, one approach might be to encourage all projects or agencies to 'take ownership' of their abbreviations or acronyms by defining them on their own sites. At present this is rarely the case.
In order to provide a useful service the crawler is reliant on more widespread deployment of <acronym> and <abbr> elements and that these elements are used correctly and consistently. It is pleasing that QA Focus is encouraging greater usage of these elements and is also addressing the quality issues [4].
Lastly, if sites were to produce their pages in XHTML [5] automated harvesting of information in this way should be substantially easier. XML parsing tools could be used to process the information, rather than relying on processing of text strings using regular expressions, as is currently the case.
Tom Heath
Web Developer
UK Centre for Materials Education
Materials Science and Engineering
Ashton Building, University of Liverpool
Liverpool, L69 3GH
Email t.heath@liv.ac.uk
URL: <http://www.materials.ac.uk/about/tom.asp>
After hearing about the automated tool which harvested <abbr> and <acronym> elements [1] it was decided to begin the deployment of these elements on the QA Focus Web site. This case study reviews the issues which needed to be addressed.
The <abbr> and <acronym> elements were developed primarily to enhance the accessibility of Web pages, by allowing the definitions of abbreviations and acronyms to be displayed. The acronyms and abbreviations are normally identified by underlining of the text. Moving the mouse over the underlined words in a modern browser which provides the necessary support (e.g. Opera and Mozilla) results in the expansion of the acronyms and abbreviations being displayed in a pop-up window. An example is illustrated in Figure 1.
Figure 1: Rendering Of The <ACRONYM> Element
As Tom Heath's case study describes, these elements can be repurposed in order to produce an automated glossary.
Since the QA Focus Web site contains many abbreviations and acronyms (e.g. Web terms such as HTML and SMIL, programme, project and service terms such as JISC, FAIR and X4L and expressions from the educational sector such as HE and HEFCE it was recognised that there is a need for such terms to be explained. This is normally done within the text itself e.g. "The JISC (Joint Information Systems Committee) ...". However the QA Focus team quickly recognised the potential of the <abbr> and <acronym> harvesting tool to produce an automated glossary of tools.
This case study describes the issues which QA Focus needs to address in order to exploit the harvesting tool effectively.
The QA Focus Web site makes use of PHP which assemble XHTML fragments. The HTML-Kit authoring tool is used to manage the XHTML fragments. This approach was used to create <abbr> and <acronym> elements as needed e.g.:
<abbr title="Hypertext Markup Language">HTML</abbr>
In order to ensure that the elements had been used correctly we ensure that pages are validated after they have been updated.
The harvesting tool processed pages on the UKOLN Web site, which included the QA Focus area. When we examined the automated glossary which had been produced [2] we noticed there were a number of errors in the definitions of abbreviations and acronyms, which were due to errors in the definition of terms on the QA Focus Web site.
Although these errors were quickly fixed, we recognised that such errors were likely to reoccur. We recognised the need to implement systematic quality assurance procedures, especially since such errors would not only give incorrect information to end users viewing the definitions, but also any automated glossary created for the Web site would be incorrect.
In addition, when we read the definitions of the <abbr> and <acronym> elements we realised that there were differences between W3C's definitions of these terms and Oxford English Dictionaries of these terms in English usage.
We also recognised that, even allowing for cultural variations, some terms could be classed either as acronyms or abbreviations. For example the term "FAQ" can either be classed as an acronym and pronounced "fack" or an abbreviation with the individual letters pronounced - "eff-ay-queue".
A summary of these ambiguities is available [3].
We recognised that the <abbr> and <acronym> elements could be used in a number of ways. A formally dictionary definition could be used or an informal explanation could be provided, possible giving some cultural context. For example the name of the FAILTE project could be formally defined as standing for " Facilitating Access to Information on Learning Technology for Engineers". Alternatively we could say that "Facilitating Access to Information on Learning Technology for Engineers. FAILTE is the gaelic word for 'Welcome', and is pronounced something like 'fawl-sha'.".
We realised that there may be common variations for certain abbreviations (e.g. US and USA). Indeed with such terms (and others such as UK) there is an argument that the meaning of such terms is widely known and so there is no need to explicitly define them. However this then raises the issue of agreeing on terms which do not need to be defined.
We also realised that there will be cases in which words which would appear to be acronyms or abbreviations may not in fact be. For example UKOLN, which at one stage stood for 'UK Office For Library And Information Networking' is now no longer an acronym. An increasing number of organisations appear to be no longer expanding their acronym or abbreviation, often as a result of it no longer giving a true reflection of their activities.
Finally we realised that we need to define how the <abbr> and <acronym> elements should be used if the terms are used in a plural form or contain punctuation e.g.: in the sentence:
JISC's view of ...
do we use:
<acronym title="Joint Information Systems Committee">JISC's<acronym> or
<acronym title="Joint Information Systems Committee">JISC<acronym>'s ...
We recognised that we need to develop a policy on our definition or acronyms or abbreviations and QA procedures for ensuring the quality.
The policies we have developed are:
We will seek to make use of the <acronym> and <abbr> elements on the QA Focus Web site in order to provide an explanation of acronyms and abbreviations used on the Web site and to have the potential for this structured information to be re-purposed for the creation of an automated glossary for the Web site.
We will use the Oxford English Dictionary's definition of the terms acronyms and abbreviations. We treat acronyms as abbreviations which are normally pronounced in standard UK English usage as words (e.g. radar, JISC, etc.); with abbreviations the individual letters are normally pronounced (e.g. HTML, HE, etc.). In cases of uncertainty the project manager will adjudicate.
The elements will be used with the formal name of the acronyms and abbreviations and will not include any punctuation.
We will give a formal definition. Any additional information should be defined in the normal text.
We will not define acronyms or abbreviations if they are no longer to be treated as acronyms or abbreviations.
Implementing QA procedures is more difficult. Ideally acronyms and abbreviations would be defined once within a Content Management System and implemented from that single source. However as we do not have a CMS, this is not possible.
One aspect of QA is staff development. We will ensure that authors of resources on the QA Web site are aware of how these elements may be repurposed, and thus the importance of using correct definitions.
We will liaise with Tom Heath, developer of the acronym and abbreviation harvester to explore the possibilities of this tool being used to display usage of <abbr> and <acronym> elements on the QA Focus Web site.
Although the issues explored in this case study are not necessarily significant ones the general issue being addressed is quality of metadata. This is an important issue, as in many cases, metadata will provide the 'glue' for interoperable services. We hope that the approaches described in this case study will inform the work in developing QA procedures for other types of metadata.
This case study describes the experiences of the INHALE project [1] (which ran from September 2000- March 2003) and the subsequent INFORMS project [2] (which ran from October 2002-August 2003).
The INHALE Project (one of the JISC 5/99 Programme projects) had a number of aims:
The outcomes from the project were:
At the outset of the project the vision of what was required was set out clearly in the project plan and this was closely adhered to throughout.
During the first year the project team successfully created a standalone set of information skills units for students on Nursing and Health courses. The JISC's technical guidelines on interoperability and accessibility guided the Web developer in the creation of the online resources. The new information skills materials using the JISC's DNER resources as well as freely available Web resources were tested within pilot modules in the School of Health Sciences at Huddersfield. Evaluation reports from these were written. These evaluations fed into the continuous "product" development.
During the second year (September 2001- September 2002) additional information skills units were created and some of the initial units were customised. Some of the new resources were based around subscription information databases and were cascaded out for use within the partner institutions, Leeds Metropolitan University and the University of Central Lancashire.
Meanwhile at Huddersfield the resources were being embedded at different levels within Blackboard in new pilot modules.
Running parallel to the delivery of the resources within modules was the continuing development of the INHALE "database". The "database" was seen as the key to enable customisation of the initial set of INHALE materials and the generation of new units by all the partner institutions. This required the disaggregation of all the original materials into objects. Fortunately, from the outset, the vision was that the end result would be a database of learning "objects" and all the materials were created with this concept to the fore. Thus the disassembly was not as onerous a task as it may seem.
Dissemination of the project's learning and outcomes began early in the project and had two key strands. The first was to involve stakeholders in the delivery of information skills within the institutions. Workshops and meetings were held internally and attended by academic teaching staff, librarians, learning technologists, computing service staff and learning and teaching advisors. The second strand was to disseminate to the wider UK HE and FE community and various events were held beginning with an event that was to be repeated "E-Resources for E-Courses".
By July 2002 interest in the use of the INHALE resources had grown. In September 2002, the submission of a proposal for a project within the DiVLE Programme to continue the work of the INHALE project was successful. The new project was named INFORMS and from October 2002 to March 2003, the INHALE project and INFORMS projects ran concurrently. During this time the University of Loughborough and the University of Oxford, (the new INFORMS project partners), were able to test the transferability and viability of all the INHALE project materials and models as well as inputting new ideas for developing the resources.
By the end of the INHALE project in March 2002 there were over 200 units within the new database and a number of new institutions were also testing and using the database.
At this point an exit strategy was written for the INHALE project. The project team felt that there was a possible "market" for the INHALE/INFORMS information skills database within the HE/FE community. However the JISC Programme Managers considered that the database of units required more "market testing" within the HE/FE community. To some extent the INFORMS project has allowed the team to begin the process of market testing.
The INFORMS project officially completed in August 2003 and there are now over 400 units in the INFORMS database and 17 institutions have portfolios of units across the range of subjects studies across the HE/FE community. Usage of the resources can be tracked via a Web log analysis tool developed in house that is linked to the database.
Librarians (and some academic teaching staff) institutions are creating their own online, interactive innovative information skills teaching and learning resources without any knowledge of Web authoring. The database allows instant editing and updating, it automatically produces accessible and printable versions of the units. The 400 plus units in the database are shared across all the participating institutions. Units copied across institutions are tracked via an audit trail. A User Guide, Editorial Policy and Conditions of Use Agreement are all essential documents that have been produced to support users of the database.
There was some initial hold-up in getting the project started and by the time the Project Co-ordinator joined the team in January 2001, the project was approximately 2-3 months behind in writing the initial units, rolling out the baseline evaluation and writing the evaluation instruments. Delivery to the students in the first pilot module was set for mid-February 2001 and this deadline was met.
Manchester Metropolitan University pulled out of the project in June 2001 when they were successful with obtaining funding from the JISC for the BIG BLUE Project.
The Project Director left to take up another post at the University of Central Lancashire in September 2001. The loss of the Director's role as the stakeholder for the project within the Library Management Team and amongst the Academic Librarians had a detrimental effect on the uptake of the resources across the institution that is still being addressed.
The loss of someone else with information skills expertise to bounce off ideas and to provide another point of view on the project's development, as well as mutual support, has been a problem for the subsequent Project Director.
However the move by the Project Director to the University of Central Lancashire was beneficial as UCLan was invited to take the place of Manchester Metropolitan Library on the project and the input from that institution was invaluable.
In November 2001, two months after the demise of the Project Director the project's Web developer was recruited to an internal position in the library. This could have proved disastrous but in fact a new Web developer was recruited from the interviewees for the internal post and began work on the project only 10 days after the original developer had moved.
The new Project Director encountered internal political problems that have constantly hampered the uptake of the resources.
In September 2001 the University of Huddersfield experienced a severe problem with the load on its network. The project was unable to continue development on integrating video and audio into the resources.
The problem with the LAN traffic had a knock-on effect. The central service managing the Blackboard resources plus the learning and teaching support for this was re-organised. Key stakeholders in this support area within the University left so the necessary key personnel to champion the uptake of the INHALE resources in Blackboard were lost. Eventually some new posts have been created.
The Project Director mis-judged the demands that running the two projects (INHALE & INFORMS) during the period October 2002 to March 2003 would make.
The JISC only require projects to make their Web sites available to the rest of HE/FE for 3 years after the end of the project. Thus if a resource has a potential for further uptake and development then the project will need to produce a strategy to enable this.
The University of Huddersfield is not in a position to fund user support for the database. The institution is still in the early days of recovery after its re-organisation of the technical and teaching and learning support infrastructure for Blackboard.
The INFORMS (INHALE) project team have been pursuing a number of possible strategies:
The INFORMS Project team think that there is a commercial potential for the INFORMS software beyond the HE/FE sector and have been successful in a bid for funding to investigate and pursue this further over the next 12 months via a University of Huddersfield Commercial Fellowship.
It is planned that any profit will eventually be used to provide support for the INFORMS database. (Staffed support for HE/FE users of the INFORMS database, support of the Web server hosting the database, support to implement new developments).
The location of the INFORMS resources within an Information Skills Portal alongside the VTS, Big Blue and the Resource Guides, etc. would be an ideal scenario and one that has been suggested already by the Big Blue project.
Both the Open University and Sheffield Hallam have products that may benefit from the technical developments of the INHALE/INFORMS projects.
If demand for portfolios in the database grows then the capacity of the Web server at Huddersfield will be over-reached. So one possible strategy could be to move the database to either EDINA or MIMAS.
Mirroring the database at Edina has been explored and this may be possible in 12 months if the return from the commercialisation of the software is sufficient.
It may be possible to give away the software to HE/FE institutions to run on their own servers and develop should they wish to do so. The main disadvantage of this is the loss of the shared resources.
A case has been put to the JISC, the reply has been that additional evidence of a need must be gathered through "market testing".
For the time being the new INFORMS (Commercial) Project is the route being taken by the ex Project Director of INHALE/INFORMS to create supportive funding in the long term for the INFORMS database of information skills teaching and learning resources. The new INFORMS (Commercial) project began officially on 1st October 2003 and will run for 12 months. One of its first successes has been to secure a place at a reception in the House of Commons being held by the Set for Britain group who are promoting start-up, spin-out, spin-off commercialisation of UK University research. At the reception we will be delivering a poster presentation for the MPs, Peers and various other attendees of the proposed commercialisation of the INHALE/INFORMS software.
The TimeWeb (Time Series Data on the Web) project was a joint project between Biz/ed [1] at the Institute for Learning and Research Technology [2] at the University of Bristol and the JISC/ESRC supported MIMAS service [3] at Manchester Computing at the University of Manchester. The central aim of the project was to develop the key national and international macro-economic time series data banks, such as the OECD Main Economic Indicators, held at MIMAS into a major learning and teaching resource.
The key deliverables of the TimeWeb project were:
The TimeWeb learning and teaching materials and the TimeWeb Explorer were successfully launched into service on Thursday, 14th February 2002 [5]. Through the use of shared style sheets and a common design, movement between the learning and teaching materials developed by Biz/ed and the TimeWeb Explorer Web site developed at MIMAS appeared seamless to the user. Thus Timeweb provided an integrated package of both data and learning and teaching materials.
This case study describes the approaches adopted by Biz/ed and MIMAS to deliver the TimeWeb project deliverables to users and also to embed those deliverables into a service environment to facilitate long term maintenance and support.
In order for the JISC to be successful in its stated aim of enhancing JISC services for learning and teaching, it was imperative that the deliverables from the TimeWeb project were released to users and embedded in a service environment. Both MIMAS and Biz/ed fully understood the importance of releasing the deliverables and promoting their long term use in order to maximise JISC's investment.
In the original project plan, it was intended that the release of prototype interfaces and learning and teaching materials for user testing and evaluation would take place at various stages during the development phase. The objective was that final release of the TimeWeb Explorer and the associated learning and teaching materials would coincide with the end of the project. Once the project ended it was anticipated that the ongoing support and maintenance of the TimeWeb Explorer and learning and teaching materials would be absorbed by the existing MIMAS and Biz/ed service infrastructures.
At the time, these aims were felt to be realistic as both MIMAS and ILRT had considerable experience in transferring project deliverables into services. Whilst MIMAS and Biz/ed successfully achieved the objective of releasing the deliverables into service at the end of the project, the long term support and maintenance has proved more problematic than originally anticipated.
The TimeWeb team encountered a range of problems which had to be overcome in order to achieve the twin objectives of releasing the project deliverables to users and also to embed these deliverables in a service environment to facilitate long term maintenance and support. The following is a summary of the problems encountered and how the Biz/ed and MIMAS teams overcame them:
MIMAS encountered a range of technical problems that needed to be overcome before the TimeWeb Explorer could be officially released to users. To avoid the normal problems associated with the long term support and maintenance of software developed 'in house' MIMAS decided to use a proprietary solution for the development of the Web based interfaces to the time series databanks. The selected solution was SAS AppDev Studio [6] which had been developed by the SAS Institute [7]. The intention was to use the visual programming environment provided by SAS to build a lightweight Java based interface to the time series databanks.
Whilst Java facilitated the development a sophisticated and interactive interface it also resulted in a series of major development problems which had to be resolved. For example, the Java sandbox security model typically does not allow data files to be written to the server or client, an essential step for data downloads. Such development problems were compounded as the TimeWeb Explorer was one of the most advanced projects ever written with SAS AppDev studio, and SAS themselves were limited in the technical help they could provide. The additional staff effort required to resolve the unanticipated technical problems significantly held up development work and prevented MIMAS from releasing the interface for user testing until towards the end of the project. It also resulted in MIMAS shelving plans for the more advanced user interface.
When the TimeWeb Explorer was released for initial user testing a number of unanticipated deployment problems were encountered which caused significant delays. Firstly, the use of the applet required users to install a particular version of the Sun Java Plug-in (Sun's newer releases of the plug-in are unfortunately not backward compatible with earlier versions). AppDev Studio tends to lag behind the latest version of the plug-in produced by Sun and, moreover, different versions of the plug-in could not co-exist on the same PC. This created problems for users unable to install software on their PC due to network restrictions, or for cluster users where the latest version of the plug-in had already been installed. Much work went into finding the best compromise, resulting in a parallel version of Timeweb that ran on later versions of the plug-in also being created. A second deployment problem resulted from the many variations amongst user systems (such as operating system, browser version, download permissions, cache settings or network connection), all of which had some influence on the operation of the TimeWeb Explorer. All these deployment problems had to be fully investigated and documented to allow a wide range of users as possible to use the Timeweb Explorer reliably. Resolution of these technical problems required significant additional development effort towards the end of the project which further delayed the release of the TimeWeb Explorer into service.
Before the TimeWeb Explorer was released to users as a new service, it was necessary to embed it within the existing MIMAS Macro-Economic Time Series Databank Service. As the OECD MEI was updated monthly it was necessary to establish data loading procedures which existing support staff could use. As part of the service integration, it was also necessary to implement and test the access management system required to restrict access to authorised users as required under the terms and conditions of the OECD data redistribution agreement.
It was also necessary to develop a range of support and promotional materials to coincide with the release of the TimeWeb Explorer. MIMAS launched the Explorer alongside an accompanying Web site containing help pages, detailed information on running requirements and links to the metadata for the OECD MEI databank. In addition to email announcements sent out to various lists, a TimeWeb Explorer factcard [8] and an A3 TimeWeb publicity poster were produced and widely distributed. The creation of these publicity materials required assistance from other support staff within MIMAS. In addition, it was also necessary to provide training to MIMAS Helpdesk staff to enable them to deal with initial queries relating to the use of the TimeWeb Explorer.
Having transitioned the TimeWeb Explorer into a supported MIMAS service it soon became apparent that additional effort was required for both on-going maintenance and development of the interface. For example, additional software engineering effort would be required to respond to user feedback/bug reporting and - more importantly - to extend the TimeWeb Explorer interface to provide access to other time series databanks. The loss of dedicated software engineering effort at the end of the project - due to the absence of continuation funding - made the on-going maintenance and development of the interface very problematic.
When the TimeWeb project started in 2000, there were no proprietary systems available that could have been used to provide the required flexible Web-based access to aggregate time series. By the time the project had ended, the Beyond 20/20 Web Data Server (WDS) [9] had emerged as a standard tool for the publication and dissemination of international time series databanks over the Web and was starting to be used by many of the world's largest international and national governmental organisations, such as OECD and the Office for National Statistics (ONS). Not only did the Beyond 20/20 WDS offer the required functionality, it could also be used to import data in a range of different formats. More significantly, the WDS runs in a standard Web browser (IE 4.01/Netscape 4.5 and above) with Javascript enabled thus avoiding the problems associated with Java plug-ins which had been encountered with the TimeWeb Explorer.
In 2002/2003, the MIMAS Macro-economic Time Series Data Service underwent a major transformation as part of the establishment of the new ESRC/JISC funded Economic and Social Data Service (ESDS) [10]. In January 2003, the new ESDS International Data Service [11] based at MIMAS was launched. In order to provide flexible Web-based access to a much larger portfolio of international time series databanks statistics produced by organisations, such as the International Monetary Fund, and to minimise in-house interface development overheads, a strategic decision was taken to standardise on the Beyond 20/02 WDS interface. As a result, an internal project team was set up to plan and oversee the transition from the TimeWeb Explorer to Beyond 20/20 WDS. The project team benefited considerably from the lessons learnt when introducing the TimeWeb Explorer interface into service and the transition to Beyond 20/20 was completed in April 2003.
One of the most significant problems faced in the creation of the learning materials was the sheer breadth of potential data handling skills that exist. There is a wide variety of contexts and qualifications that involve data skills. The Biz/ed team was aware that whilst the Higher Education market was the chief target, the materials would have maximum effectiveness if they addressed other audiences. It follows that supporting the needs of different users is difficult when the user base can be drawn from such a variety of backgrounds.
The main problem faced by the Biz/ed team was in relation to the need for sample data to support the learning and teaching materials under development. This need having been identified, it was necessary to source the datasets and agree terms for their release by the data provider. In this case it was felt appropriate that UK data would be sampled. UK National Statistics were approached in order to gain their approval for a small number of datasets to be held within the TimeWeb suite of learning and teaching materials.
During the period of negotiations with National Statistics there was a change in policy at Governmental level which had the effect of removing all barriers to the use of official data, on the proviso that commercial benefit was not to be obtained. As Biz/ed is a free educational service, this did not pose a problem. However, getting hold of the data codes for the sample datasets added extra delays in being able to finally release the TimeWeb learning and teaching materials.
In preparation for TimeWeb moving into service, it was recognised that the maintenance of up-to-date data was crucial. This involved technical work in creating scripts to run out the data from National Statistics. This occurs on an annual basis. However problems continue to emerge as the codes applied to the data by National Statistics appear to be changed on every update. Thus, on-going maintenance continues to be an issue.
As a non-JISC service at the time of the project, the materials were placed within Biz/ed as a stand-alone resource. Given that Biz/ed became a JISC service in late 2002, there are now issues around the integration of the TimeWeb resource into the service and how they are maintained
One of the key things to come out of the project was how difficult it was to respond to emerging standards and changing requirements both during the development phase and once deliverables have been transferred into a service environment. For example, since the completion of the TimeWeb project, learning objects have emerged as a major theme in e-learning. Migrating the TimeWeb materials to a learning object model and ensuring compliance with new metadata standards (e.g. IEEE LOM) so that that they are reusable and form part of a true resource discovery environment would be a major undertaking which would require additional funding. However, it is very difficult to respond to new funding opportunities, such as X4L [12], when teams and associated expertise have dispersed.
We believe that TimeWeb would have benefited from closer examination of possible project exit strategies at various points during the project. When the project finished in February 2002 there was very little guidance from JISC about future directions. An optimal solution would have been for the project partners - in their roles as service providers - to seek continuation funding for the materials to be updated and the data interface to be maintained. For instance, the sample datasets used within the learning materials could have been adapted to reflect changing interests and events. Whilst we demonstrated successfully that project deliverables could be delivered into service through existing service providers it was clear that additional resources were going to be required for long term support and maintenance. As a project, we should have been more proactive at an earlier stage in terms of making a case to JISC for additional funding.
The detailed planning of the transfer of project deliverables into service was left until towards the end of the project. It would have been better to start the planning at a much earlier stage. It would have also have been advisable to have defined the transfer of deliverables to service as a separate work package in the original project plan. This work package would have needed to be kept under review during the course of the project to reflect changes and developments. However, it was clear from our experience that we had underestimated the amount of software engineering effort required to transfer 'project quality' software to 'service quality'. We also underestimated the amount of additional work that would have to be provided by other support staff to assist with the transfer to service.
Whilst Java held out the promise of developing a sophisticated and interactive interface to time series that would meet the needs of researchers and students alike, we had not fully anticipated the technical problems that would arise. Had we been aware of the pitfalls of the Java route, we would have probably adopted a simpler and more robust database driven approach to delivering time series data across the Web. Rather than trying to fully exploit leading edge technology we should have focused on a less challenging software solution that would have been easier to transfer into service and subsequently maintain.
Whilst the TimeWeb Explorer had a limited service life and was eventually replaced by a commercial system, this does not mean that it was a failure. During the year in service it resulted in a significant increase in the use of the OCED MEI - much of it for teaching and learning. Developing the TimeWeb Explorer gave MIMAS invaluable insights into what was required to deliver international macro-economic time series via an interface that was suitable for both researchers and students. Therefore, TimeWeb has played an important role in the establishment of ESDS International as a major new UK academic data service.
Keith Cole
Deputy Director/Services Manager
MIMAS
Manchester Computing
University of Manchester
Tel: 0161 275 6066
Email: Keith.Cole@man.ac.uk
Andy Hargrave
Biz/ed Research Officer
Institute for Learning and Research Technology
University of Bristol
Tel: 0117 9287124
Email: Andy.Hargrave@bristol.ac.uk
This case study discusses the processes which have been used at BIDS to produce databases suitable for a service environment. The organisation gained extensive experience in this area, both with bibliographic data and with statistical and taxonomic data.
It frequently happens that a database needs to be constructed by taking data from other sources, converting and merging it to form a single database. There are numerous pitfalls in this process caused by errors and inconsistencies in the data. This document discusses where these can occur and suggests ways to handle them. It emphasises the importance of tackling some of the issues before they arise and discusses possible options. The overall approach is a pragmatic one - little is to be gained by trying to insist on perfection and while there is sometimes room for negotiation it is futile to expect too much The fact that the database isn't perfect does not mean that it isn't useful, sometimes extremely useful.
If the initial merger is successful then there will often be a requirement to add further unanticipated data. It discusses what can be done to mitigate the problems that can arise when this occurs.
This paper attempts to provide some guidance on the problems likely to be encountered when trying to merge two or more databases. In order to avoid hedging every statement and opinion with caveats, I have frequently given the text a didactic tone which should not be taken too literally. There are no hard and fast rules, except perhaps to expect the worst and hopefully be pleasantly surprised when the worst doesn't happen.
If you are proposing to merge databases, this will almost inevitably involve moving one or more of them from a different system and this process brings its own set of tribulations which are discussed in the next section.
Just because it is difficult doesn't mean it isn't worth trying, simply that it is important to be realistic about the limitations of the process. The cumulative errors and inconsistencies between the databases will inevitably mean that the whole is less than the sum of its parts and differences in the world views of the compilers of the various databases will mean that there has to be some loss of resolution. The more databases you are trying to merge, the worse these effects become and the more difficult it is to anticipate the problems, so perhaps the first question you should be asking is whether you want to merge them at all or whether it is better to leave them as separate and identifiable databases, merging the data on the fly when the application requires it. Given that the application can usually be changed rather more easily than the database, this is an option which is always worth a look. It has its drawbacks however. Merging on the fly generally means that the application has to be able to deal with all the errors and inconsistencies as they appear. Moreover, it has to deal with them without necessarily having any prior knowledge of what they might be, so there is an ever present risk that the application can be thrown by some unforeseen eventuality or that the resulting virtual database may present serious errors or misconceptions to the end user as a result of the application mishandling them. At least if you have tried to put them together, you will have had the opportunity to study the data content and hopefully have a clearer view of what you are dealing with.
Even if these exist they will almost certainly contain errors and omissions which will cause problems. Of course, there is no suggestion that the supplier of the data has deliberately set out to confuse or mislead, quite the reverse, but with the best will in the world, the useful information never makes it from the head onto the page, so while it is useful as a guide, any specification or other documentation should always be treated as potentially incomplete.
Because the documentation should never be relied upon, the start of any serious study is the data itself. Always start by getting large samples of the data and then spend a couple of days (or more) studying them. Time spent doing this is very rarely wasted and you are likely to discover all sorts of interesting things. Each field should be checked through to make sure that it bears at least some relation to what you are expecting. The things to look out for are:
These issues are discussed in more detail below.
If a database covers a substantial time period and has been compiled incrementally, then it is possible that the quality control has improved over time, so it is worth trying to obtain samples from different parts of the time period covered and in any case, just looking at recent data is to be avoided. The meaning of some of the fields have drifted over time, or the very early data may have a lot of errors. In extreme cases, the very early data may be so poor that you could consider discarding it, though there will often be political considerations which preclude this.
Some errors are almost impossible to spot by looking, so it is worth considering writing some scripts or short programs to check fields which you think may have errors. Check digits obviously fall into this category, as do dates. Fields which purport to contain a small range of possible values (e.g. language codes, currency codes) can easily be checked in this way and will often be found to have other, undocumented, values.
In other cases, you might be able to use a script, or a utility like the Unix grep command, to strip out the instances of a particular field from the sample records so that they can be viewed separately on the screen and making unexpected variants easier to identify.
Databases are almost invariably created for some specific purpose (i.e. the data generally hasn't just been collected for the sake of collecting it) and this means that the data is skewed towards this purpose. It will also be skewed towards the creator's view of the world. Data is not a value-free commodity, but a description, often a highly personalised one of some aspect of the world. This description may be at odds with your requirements and the first important task in any data migration is to try to identify the assumptions which have been unconsciously built into the database and to assess the impact which these might have. (There are exceptions. Taxonomic databases, e.g. those covering the classification of plants or animals, have been created with no specific use in view, simply in order to record a section of the taxonomy in a modern, convenient form, but this is unusual.)
A database and its associated applications which have been in existence for some time will have evolved so that the applications make allowances for the vagaries of the data and it is important to bear this in mind.
What might look like egregious errors or inconsistencies to you might be unimportant for the original purpose. An example of this was an economic database containing sets of time-series data and supplied by a major UK institution. Close inspection showed that many of the time series were repeated and that some that were present were incomplete. In fact the data was supplied mostly to other financial institutions who took out the series they needed and discarded the rest. Since these institutions usually wanted the same subset (which was actually correct), errors in the rest were not noticed (and would probably have been considered unimportant). Trying to provide an academic database service was a different matter, since there was no way of knowing which series were going to be important for a particular line of research, so the whole database had to treated equally. This led to some interesting discussions with the supplier which were eventually resolved.
You can start by thinking about the way in which the data is currently being used. It is possible that its current use is to facilitate rapid short term decisions (commercial databases often have this purpose). In this case, timeliness is of the essence and there will often be an acceptance that a loss of accuracy is a price worth paying. Indeed, it may be compulsory since the data may be useless unless it is available in time. For research purposes however, timeliness is generally less important than accuracy, so what is required is a database of record, one which is a source of authoritative and reproducible results.
Another possibility is that the data is not of the correct scale. The author spent many months painfully acquiring a large quantity of meteorological data covering South West England and South Wales in the belief that this would be a broadly useful research resource for the academic community in the South West, only to discover that many people either wanted data about micro-climates (for which it was insufficiently detailed) or about the UK, the North Atlantic, Western Europe, etc (for which it was hopelessly localised) or about some specific location (which wasn't covered). An assumption that the research would follow the availability of resources was shown to be quite unfounded (at least in this case) and usage of the database was very low in spite of efforts to promote it.
Failing to recognise the implications of such strategic mismatches may result in a database which is not fit for the purpose and which, as a result, is little used.
The people who supplied the data (assuming they are still around) will usually want to be notified of errors that you find, so it is a good idea to negotiate some mechanism for notifying them and for receiving corrections before you start finding them. Keep it simple. People who maintain databases usually don't believe that there are very many errors in them and will happily agree to supply corrections. The arrangements will invariably need to be modified in the light of experience. Using the data for other purposes generally reveals a large number of problems and the suppliers will have underestimated the amount of work involved, so it is also safe to assume that any arrangement, however well-intended, may collapse when put to the test. For this reason it is important to have an alternative strategy for dealing with errors which does not depend on the supplier.
People who construct databases often incorporate very little error checking into the data definition itself even when this could be done automatically by the software. The result is fields in the data which are simply character strings and which can therefore contain pretty much anything.
The classic example is dates. If dates have hitherto been stored simply as character strings, then it is almost certain that impossible values (e.g. 29/2/1957) will have crept in. If you are planning to move the data to a DBMS field which is defined as a date it will certainly refuse to have anything to do with values like this. To make matters worse, the original supplier will probably have no way of recovering the correct value, so the situation is literally irretrievable. Similar problems arise with fields which are supposedly numeric, but which contain invalid characters.
It is generally not a good idea to take an overly rigorous approach to fixing errors and in any case people who use databases are surprisingly tolerant of them. Except in very unusual circumstances, you won't be able to work out the correction for yourself, so the options are basically:
Discard the data. This is always tempting, but is usually a bad idea because it will often have knock-on effects and because the error may be only in a single field in a record.
Leave it as it is, but mark it in some way (perhaps by having a field in your database which indicates that the record is erroneous). This is OK, but gets very complicated if you want to indicate anything more precise than that the record contains one or more errors somewhere.
Change it to some valid value which can be interpreted as meaning that there is an error. Risky, but useful if you have a value which simply cannot be stored in the database as it stands (e.g. dates which are invalid or non-numeric characters in a field defined as numeric). For this reason it is often not a good idea to impose constraints on the data which haven't been imposed before, as this may just cause insoluble problems.
Ignore it. This sounds like the worst of all worlds, but you need to be practical about these things and provided the value is obviously invalid, it may have surprisingly little impact. Most statistical packages, for example, incorporate techniques for dealing with missing values, so the item can simply be discarded during the analysis. This is not to say that errors are unimportant, or that you shouldn't make efforts to find and correct them, but these efforts can soon produce sharply diminishing returns. Errors which are obvious and detectable are actually much less problematic than those which are not algorithmically detectable, such as digit transpositions in numbers.
A database will sometime contain fields whose meaning has changed over time, or which has been used for more than one purpose and this is one situation where the data can be fixed without incurring penalties. This can occur in financial data which the meaning of certain terms in company accounts can be redefined. The result is that the data is not comparable from year to year, and since this is usually what academics who are using the data want to do, it can cause serious problems if it isn't highlighted in some way. The simplest solutions are either to split it into several fields (one for each meaning) all but one having a null value at any given occurrence, or to invent an extra field which indicates the changing meaning. For data which is to be processed solely by your applications either will do, but for data which is to be exposed to end users, the former is preferable as it makes the change of meaning explicit and difficult to ignore.
The most obvious thing to remember about merging databases is that there needs to be some basis for merging, i.e. that the databases need to have some common values which provide a link between them. Often this will be some universal unique identifier which has been assigned, e.g. an ISSN for journals or a Stock Exchange Daily Official List (SEDOL) number for quoted companies and their shares. Unfortunately universal unique identifiers are as susceptible to Murphy's Law as everything else. They may not be particularly universal, they may not even be unique and what they identify can be disconcertingly variable. As with all data it is important to make allowances for the unexpected and not to hard wire rigid constraints which will subsequently prove to be unsustainable.
Most of the problems encountered in merging databases arise as a result of trying to make fields which are on the face of it the same (e.g. a personal name) actually compatible. Before embarking on this, it is useful to think about what you are going to do with the data and to remember that filestore isn't usually a constraint, so rather than converting all the various forms of the data into a single reduced form, you could consider holding various copies of the same field. One of these could be (say) the name in its original form, another the name reduced to a common format suitable for searching and another a form suitable for displaying in the results of a search. An advantage of doing this is that you have the original in the database, so you could subsequently change to using that for displaying at some later date, and also because having the original format to hand in the database can be very useful for sorting out queries later. The disadvantage of it is of course that the conversion from the various formats becomes more complex. How you choose to play this trade-off depends on your circumstances.
Databases containing text will often contain textual mark up to represent characters which are not normally encountered e.g. letters with accents & other diacritics, Greek or Cyrillic letters, and other signs like up-arrow which don't occur in the usual ASCII Latin alphabets. There will generally be (a) a unique system for representing these in each database and (b) they will all contain a different set of characters. This is one situation where standardising is almost certainly a good idea.
The characters fall into three categories:
Those which are a Latin letter with an added diacritic mark or a symbol representing a ligature. In these cases there is an obvious substitution, so although you might want to display the word "correctly" with the accented character or ligature in the search results, it will probably not be a good idea to insist on the inclusion of the accent for searching purposes, so people can search for "Cote", but see "CÔté" displayed. There are cultural arguments here of course. We live in a largely unaccented world and the accented world could argue that searching for "the" when you are looking for "thé" is not an acceptable way to treat their language. Whatever the rights and wrongs, this argument has pretty much been lost.
Those characters which cannot be converted to a basic Latin equivalent, e.g. Greek or Hebrew letters but for which there is still a need to provide a searchable version. In this case the simplest solution is to replace the Greek letter with the spelled out version e.g. chi-squared, gamma-rays, aleph-zero.
Those characters which have no sensible equivalent for searching purposes, e.g. up-arrow. These are easy to handle from a displaying point of view, but are very difficult to search for without using some decidedly non-obvious replacement text. Fortunately these characters are usually found in situations where searching is not commonly required so this tends not to be a problem.
In some database systems the indexing can be instructed to ignore character strings enclosed by certain delimiters and if this is available it provides a good solution. Alternatively, it may be possible to pre-process the field value before presenting it for indexing (which amounts to the same thing). It is necessary to define delimiters which will enclose the "hidden" text and which are either defined to the DBMS or used in the field pre-processor and also to indicate how many characters the enclosed text need to replace. Supposing that the delimiters are { and } the text can therefore look something like:
... a {pointer to chi.gif 3}chi-squared test on Du C{Ô 1}ot{é 1}e de Chez Swan."for searching purposes the text reduces to:
".... a chi-squared test on Du Cote de Chez Swan."Although as a general rule it is not a good idea to adjust the data content, case conversion is sometimes an exception to this. Old databases will often have text fields which are in upper case and displaying this on the screen has come to look overly aggressive (though it used to be quite normal, of course). Depending on the content of the text, it may be possible to convert it to a more conventional mixed case. Care needs to be taken before embarking on this. The original ISI bibliographic databases provided to BIDS in 1991 were entirely in upper case and some consideration was given to attempting to convert it. The idea was discarded, mainly because of the near impossibility of distinguishing the word "in" from the chemical symbol for Indium ("In"), the symbol for Cobalt ("Co") from the formula for carbon monoxide ("CO"), and similar examples. It was decided that the benefits did not outweigh the potential for confusion which might occur, and that that BIDS could have been accused of corrupting or mishandling the data.
There are other situations however, when this has been done to good effect, usually when there is a restricted vocabulary. Journal names are an example where there is very limited punctuation and no awkward constructs like chemical and mathematical formulae. In this case, it is very easy to parse the string into words and adjust the casing of each word (perhaps putting a limited list of common words like "the" and ऺnd" into all lower case). It is not perfect of course. The simple algorithm converts acronyms like "NATO" into "Nato", so a list of common acronyms needs to be incorporated to stop this, but even allowing for deficiencies, the overall effect is distinctly preferable.
It is not necessary to merge fields just because they contain notionally the same thing. In some circumstances there will be fine distinctions in the semantics of the fields which would make combining them seriously misleading.
A plant species, for example, may have several names associated with it, either because it has been reclassified (possibly several times) or because it has been named by different authorities on separate occasions. Complex rules have evolved for prioritising these and any manipulation of a taxonomic database will almost certainly need to take this into account.
All the above problems are compounded when the database needs to be updated. There are generally two possibilities here:
The database is being rebuilt from scratch using updated source data. If it is technically feasible this will usually be the preferable option. Not only does it allow you to correct errors which found their way into the original database (in spite of your efforts) but it also means that you can now make use of those insights which you had just too late the first time around. Unless the database is extremely large or there are other overriding reasons why it is infeasible (for example because a large number of manual fixes have been applied which would need to be reapplied), you should at least consider this option.
The database needs to be updated in situ. This can pose acute technical problems. Remember that in order to put the databases together, you needed some way to tie together related records. Even in the unlikely event that you've managed to reconcile all the relationships and have no records from one database that don't have partners in the other(s), there is no guarantee that this situation will continue and it is very unlikely that it will. Individual databases get updated at different rates, so any update process needs to assume that there will be unresolved relationships at any stage and that these may always be resolved by some subsequent update (or they may not, or the update may produce an additional erroneous resolution). How difficult it is to solve these problems depends on the regularity of the updates and how time critical they are. Basically you are trading effort against accuracy. If the updates arrive daily or weekly then it is unlikely that you'll be able to afford the luxury of manual intervention in the updating process and you will have to live with the results.
Any merging operation which is even moderately successful runs the risk of being required to incorporate another unknown and unanticipated data source. It is usually futile to point out that one of the reasons the initial merger was a success is because all the databases were known about beforehand, and in any case, you are being paid the biggest compliment possible, so you might as well make the most of it.
Now however, is not the time to start thinking about it. It is always a good idea to behave from the start as though this were bound to happen and there are a number of fairly elementary things to bear in mind.
Fields which contain classification values, e.g. a language name or code should always allow for additional values.
Fields in the database should be disaggregated where possible, so if a supplied text field actually contains 2 or more (probably closely related) items of data and it is possible to disassemble these into separate fields, then do this. An example is journal names. There are numerous examples of journals (usually at the more popular end rather than hard-bitten academics) which have the same name and in this case it is normal to distinguish them by appending the place of publication (separated by some suitable delimiter). In this case it is usually a simple matter to split this into two fields.
This case study was written by Clive Massey who worked on the original BIDS system and was subsequently involved in many aspects of the services, including database and User Interface design. He was later employed by Ingenta, initially as Help Desk Manager and then on database design and administration.
In 1999 Ingenta bought the US-based UnCover Corporation and set about moving its bibliographic database and document delivery operation to the UK. UnCover had evolved over the space of about 10 years and the service had been fixed and added to in an ad hoc manner in response to customer requirements, with the result that there were now very few people who fully understood it. There were three main issues to be addressed: (1) moving the bibliographic data (i.e. information about journal articles) into a database in the UK and implement a stopgap application to provide access to this data; (2) moving the user level subscription and accounting data into a database and (3) reimplementing the application.
This case study discusses the choices which were available at various stages of the project and why decisions were made. It also discusses whether, with the benefit of hindsight, any of the decisions could have been improved.
UnCover had been set up to provide universities and commercial companies (mostly in the US) with access to journal articles. The system worked by providing a bibliographic database which contains basic information such as the journal title, the authors, journal title, volume, issue, page numbers, etc, which could be searched using the usual methods. If the searcher wanted a copy of the complete article then the system would provide a FAX copy of this at a charge which included the copyright fee for the journal's publisher, a fee for the provider of the copy (which was one of a consortium of academic libraries) and a fee for UnCover.
Additionally, UnCover provided journal alerting services, customised presentation, prepaid deposit accounts, and other facilities.
Ingenta bought the company, primarily to establish direct relationships with the North American academic library community with its large user base and also to get a bibliographic database with good coverage of academic journals going back about 10 years.
Over the space of about a year the entire system was moved to the UK from where it now runs.
The first task was to move the bibliographic backfile and then to start taking and adding the regular weekly updates which UnCover produced. The database consisted of about a million articles per year, though the early years (i.e. from 1988 to about 1992 were somewhat smaller). Ingenta had a good deal of experience in using the BasisPlus database system which originated as a textual indexing system but had acquired various relational features over the years. It has many of the standard facilities of such a system e.g. word and phrase indexing, mark up handling, stopwords, user defined word break characters and so on. Some thought had been given to alternative DBMSs (and this is discussed further below) but given the short timescale it would have been too risky to switch systems at this point. BasisPlus had the additional advantage that Ingenta already had an application which could use it and which would require only small modifications to get working.
The application was written to access several databases simultaneously. Each database contained the data for a single year's worth of journal articles and if a particular search was required to cover several contiguous years (as most were) then the application automatically applied the search to each year database in turn and then concatenated the results for display in reverse chronological order. There were disadvantages to this method, notably the near impossibility of sorting the results into relevance ranked order, but by and large, it worked well.
Ingenta obtained some samples of the data and set about analysing it and building a test database. This was fairly straightforward and didn't pose any serious problems, so the next step was to start offloading the data from UnCover a year at a time and building the production databases. It soon became obvious that data which purported to be from (say) 1990 contained articles from anywhere between 1988 and about 1995. Persuading the UnCover team to fix this would probably have delayed the build so it was decided to collect all the available data and then write a program to scan it searching for articles from a specified year which could then be loaded into the current target year database. Experience indicated that it's better to fix these sorts of problems yourself rather than try to persuade the other party to undertake what for them is likely to be a significant amount of unwelcome work.
The decision was taken quite early in the project to index the text without specifying any stopwords. Stopwords are commonly used words such as "the", ऺ", ऺnd", "it", "not", which are often not indexed because they are thought to occur too frequently to have any value as searching criteria and the millions of references will make the indexes excessively large. The result is that trying to search for the phrase "war and peace" will also find articles containing the word "war" followed by ANY word, followed by "peace", e.g. "war excludes peace". At first this seems sensible, but experience had shown that some of the stopwords also occur in other contexts where disabling searching is an acute disadvantage, so for example it becomes impossible to search for "interleukin A" without also finding thousands of references to interleukin B, interleukin C, etc which are not wanted. In fact it turned out that specifying no stopwords had a comparatively small inflationary effect on the indexes (about 20%) and a negligible effect on the performance.
Another important decision was to rethink the way author names were held in the system. UnCover had input names as:
Surname, Forename Initial
e.g. Smith, Robert K
This was very difficult to index in a way which would provide flexible name searching, particularly since bibliographic databases generally use Surname, Initials e.g. Smith, RK though we were generally reluctant to discard any data. It was decided to keep several author name fields, one with the names in their original format, a second to be used for display, a third for searching and a fourth for matching with another database.
This operation of analyzing the data, designing the BasisPlus database structure (which was simply a further modification of several we had done in the past), writing the program to take the UnCover data and convert it for input to Basis and finally building the 12 production databases took about three months elapsed time.
The immediate requirement was for an application which would allow the databases to be searched, the results displayed and emailed, and documents ordered and delivered. There was not an initial requirement to replace the entire UnCover service, since this would continue to run for the time being. An application was available which had originally been written for the BIDS services and was reasonably easily adaptable. Because the BIDS services had used an almost identical database structure, the searching and display mechanisms could be moved with only minor modification. In addition the services had used the results display to drive a search of another database called the PubCat (or Publishers Catalogue) which contained bibliographic information on articles for which Ingenta held the full text. If the user's search found one of these, then the system would offer to deliver it, either for free if the user had a subscription to the journal or for a credit card payment.
The major addition at this stage was to provide access to the UnCover document delivery service. The PubCat could only deliver electronic (PDF) versions of documents for issues of those journals held by Ingenta (or for which Ingenta had access to a Publisher's document server) and inevitably, these tended to be the more recent issues. UnCover could deliver older material as FAXes and to enable in the new application this it was necessary to construct a call to the UnCover server providing it with ordering details receive an acknowledgement. The HTTP protocol was used for this since it had the right structure and the amount of information passing back and forth was relatively small. In addition, a record of each transaction was kept at the Ingenta end for reconciliation purposes.
There were a number of teething problems with the UnCover link, mainly caused by inadequate testing, but by this point there was a reasonably stable database and application.
The first real problem emerged shortly after the system went live, as it became obvious that the feed of bibliographic data from UnCover was going to stop as the UnCover operation in The US was wound down. In retrospect this should have been apparent to the developers involved and should have been allowed for, or at least thought about.
The data feed was to be replaced by the British Library's Inside Serials database (BLIS). In fact there were good reasons for doing this. The journal coverage of Inside Serials is much wider than UnCover and overall, the quality control was probably better. In addition, the coverage is more specifically academic and serious news journals, whereas UnCover had included a significant number of popular journals.
Nonetheless, the problems involved in cutting off one feed and starting another are fairly significant, mainly because an issue of a journal arrives at the various database compilers by a variety of routes and therefore find their way into the data feeds at different times. It was not possible to simply stop the UnCover feed one week and then start updating with BLIS because this would have meant that some articles would previously have been in BLIS, but not yet in UnCover (and therefore would never get into the composite database) while others would have already arrived via UnCover, only to be loaded again via BLIS. The solution adopted was to adapt the system which formatted the BLIS data for loading so that for each incoming article, it would interrogate the database to find out whether it had already been loaded. If it had, then it would merge the new entry with the existing entry (since BLIS had some extra fields which were worth incorporating), otherwise it simply generated a new entry. Also, immediately after stopping the UnCover updates (at the end of January) the previous 10 weeks worth of BLIS updates were applied. It was hoped that this would allow for disparities in the content of the two data feeds. In fact it was impossible to predict the extent of this disparity and the 10 week overlap was simply a best guess. It has since been discovered that arrival rates of some journals can vary even more dramatically than we thought and in retrospect it would have been preferable to have made this overlap somewhat longer (perhaps twice as long, but even then it's unlikely that all the missing articles would have been collected). The other problem was the ability of the updating mechanism to correctly match an incoming article with one which already existed in the database. There are two standard approaches to this difficult problem and these are discussed in some detail in Appendix 1
In addition to this synchronisation problem, the two databases were rather different in structure and content, in the format of author names and journal titles, and in the minor fields, which all these databases have, but which exhibit a bewildering, and sometimes incomprehensible variety. For those fields which were completely new (e.g. a Dewey Classification) it was simply necessary to fix the databases to add a new field which would get populated as the new fields started to arrive and would have null values otherwise or have some value preloaded. Other fields, and certain other aspects of the content, required the BLIS data to be somehow fixed so that the application (and ultimately of course, the user) would see a consistent set instead of having to deal with a jarring discontinuity. The subject of normalising data from several databases is dealt with in the advisory document on merging databases [1]. The process was less troublesome than it could have been, but this was mostly good luck rather than judgement. The most difficult aspect of BLIS from a presentational point of view is that the journal names are all in upper case. This may sound trivial, but displaying long strings of capitals on the screen now looks overly intrusive, and would in any case have differed too obviously from the UnCover presentation. It was therefore necessary to construct a procedure which would convert the string to mixed case, but deal correctly with words which are concatenated initials (e.g. IEEE, NATO).
In addition to the bibliographic database, UnCover also held a large amount of data on its business transactions and on the relationships with their customers and suppliers and this also needed to be transferred. Because the service was available 24 hours a day and was in constant use, it would have been infeasible (or at least, infeasibly complex) to transfer the actual service to the UK in stages. It was therefore necessary to nominate a period (over a weekend) when the US service would be closed down, the data transferred and loaded into the new database, and the service restarted on the Monday morning.
The first task was to select a database system to hold the data, and ORACLE was chosen from a number of possible candidates. There were good reasons for this:
It was seen as a safe option. Having to transfer the service over a weekend meant that there if an unforeseen problem had arisen, this would have been disastrous. Nothing can guarantee absolute safety, but an industry standard system with extensive backup and recovery facilities seemed to offer the least risk.
Because it was so widely used, there is a large pool of available expertise (including some already available in-house). This would probably not apply (or would not have applied then) to a system like MySQL.
There was little doubt that ORACLE could handle the volumes and transaction rates, and that it also had the capacity for the predicted expansion.
It had originally been intended to keep all the data (i.e. including the bibliographic data) in a single database, so as well as transferring the subscription and accounting data, it would have been necessary to dump out the bibliographic data and load this as well. It became obvious at an early stage that this was a step too far. There were doubts (later seen to be justified) about the ability of the ORACLE InterMedia system to provide adequate performance when searching large volumes of textual data and the minimal benefits did not justify extra work involved and the inherent risks, so the decision was taken at an early stage to keep the two databases separate, though inevitably this meant that there was a significant amount of data in common.
The database structure was the result of extensive study of the UnCover system and reflected an attempt to produce a design which was as flexible as possible. This is a debatable aim and there was, accordingly, a good deal of debate internally about the wisdom of it. It had the advantage that it would be able to accommodate new developments without needing to be changed, for example, it had been suggested that in the future it might be necessary to deal with objects other than journal articles (e.g. statistical data). By making the structure independent of the type of object it was describing, these could easily have been accommodated. In the short term however it had several disadvantages. Making the structure very flexible led to at least one area of it becoming very inefficient, to the extent that it was slow to update and very slow to interrogate. Moreover, a structure which is flexible admits not only of flexible use, but also flexible interpretation. The structure was difficult for the application designers to understand, and led to interpretations of its meaning which not only differed from that intended, but also from each other.
Samples of the various data files were obtained from UnCover and scripts or programs written to convert this data into a form which could be input to ORACLE. Ultimately the data to be loaded was a snapshot of the UnCover service when it closed down. Once the service had been restarted in the UK, the system would start applying updates to the database, so there would be no possibility of having a second go. This was therefore one of the crucial aspects of the cutover and had it gone wrong, it could easily have caused the whole exercise to be delayed.
In addition to the UnCover data, the source of document delivery was being changed from the UnCover organisation to CISTI (for deliveries in the North America) and the British Library (for deliveries elsewhere) This required that the system know about which journals were covered by the two services in order that it did not take an order for a document which the delivery service had no possibility of fulfilling. It also needed certain components of the price which has to be calculated on the fly for each article. A similar problem to the article matching arose here. It was necessary to take the relevant details of an article (i.e. journal title, ISSN, publication year, volume and issue) from one source and match them against another source to find out whether the relevant document delivery service could deliver the article. Although this worked reasonably well most of the time, it did initially produce a significant number of errors and, since the documents were paid for, complaints from users which were extremely time consuming to resolve.
This was easily the most complex part of the operation. In addition to the ability to search a database and order documents, UnCover provided a number of additional services (and packages of services) which needed to be replicated. These included:
The REVEAL alerting services. Users could nominate a number of journals or specify a number of standard searches. After each update had been applied, contents pages of new issues of the specified journals were emailed to the users and the searches were run against the new issues and articles which satisfied the search were also emailed.
Deposit accounts. Organisations could set up a prepaid account against which their users could purchase documents rather than having to pay for them by credit card.
Organisations could purchase a "portal" which provided them with a customised login. Users connecting from that institution were automatically authenticated, either by IP address recognition or by recognising the source page of the HTTP link, and the presentation of the Ingenta pages was also customised to include the organisation's logo and other specific information. A portal might also include REVEAL and deposit account facilities.
The work started by identifying "domain experts" who were interviewed by system designers in an attempt to capture all the relevant information about that domain (i.e. that aspect of the service) and which was then written up as a descriptive document and formed the basis of a system design specification. This was probably a useful exercise, though the quality of the documents produced varied considerably. The most common problems were failure to capture sufficient detail and failure to appreciate the subtleties of some of the issues. This led to some of the documents being too bland, even after being reviewed and reissued.
The descriptive documents were converted into an overall system design and then into detailed specifications. The system runs on a series of Sun systems under Unix. The application software was coded was mostly in Java, though a lot of functionality was encapsulated in ORACLE triggers and procedures. Java proved to have been a good decision as there was a sufficiently large pool of expertise in this area. The application process communication layer was controlled by WebLogic and this did cause a number of problems, probably no more than would be expected when dealing with a piece of software most people had little experience of.
Inevitably the main problems occurred immediately after the system went live. Given the timescale involved it was impossible to run adequate large scale system tests and the first few weeks were extremely traumatic with the system failing and having to be restarted frequently, alerting services producing inexplicable results and articles which had been ordered failing to arrive.
It had originally been the intention to look for an alternative to BasisPlus as the main bibliographic DBMS. Given that ORACLE was being used for other data, it would have been reasonable to have switched to this. Sometime before, there had been a review of the various possibilities and extensive discussions with the suppliers. Based on this, a provisional decision was taken to switch to using Verity. This was chosen mainly because it was seen as being able to provide the necessary performance for textual searching, whereas there was some doubt about the ability of the ORACLE InterMedia software to provide a sufficiently rapid response.
Faced with the implementation pressures, the switch to an unknown and completely untried bibliographic DBMS was quickly abandoned. It was still thought that ORACLE might be a viable alternative and the original database design did include tables for storing this information.
Sometime after the system went live, a large scale experiment was conducted to test the speed of ORACLE InterMedia and the resulting response times showed that the conservative approach had in fact been correct.
It is inevitable that transferring a mature and complex service such as UnCover and at the same time making major changes to the way it worked was always going to be risky. Given the scale of the undertaking, it is perhaps surprising that it worked as well as it did, and criticism after the event is always easy. Nonetheless, there have to be things which could have worked better.
There seems to be an unshakeable rule in these cases that the timescale is set before the task is understood and that it is invariably underestimated. In this case, this was exacerbated by the need to bring in a large number of contract staff, who although they were often very competent people, had no experience of this sort of system and who therefore found it difficult to judge what was important and what was not.
Flowing from this, there was a serious communication problem. The knowledge of the working of the UnCover system resided in the U.S. and while there were extensive contacts, this is not a substitute for the close proximity which allows for extended discussions over a long period and for the easy, ad hoc face to face contact which allows complex issues to be discussed and resolved. Telephone and email are poor substitutes for real meetings. The upshot was that some issues took days of emailing back and forth to resolve and even then were sometimes not fully appreciated.
In addition to the difficulties of international communication, the influx of a large number of new staff meant that there was too little time for personal relationships to have built up. There was a tendency for people to work from the specification given, rather than discussing the underlying requirements of the system. The importance of forging close working relationships, particularly on a large and complex project such as this is hard to overemphasise.
The project control methodology used was based on a tightly controlled procedure involving the writing of detailed specifications which are reviewed, amended, and then eventually signed off and implemented. This method is roughly at the other end of the spectrum from what we might call the informal anarchy method. Plainly it has many advantages, and there is no suggestion that an very informal method could have worked here; the problem was simply too complicated. It does however have its drawbacks, and the main one is its rigidity. The specification, whatever its deficiencies, tends to become holy writ and is difficult to adjust in the light of further knowledge. As with many projects, the increasing pressures resulted in the procedures becoming more relaxed, but it is at least debatable whether a more flexible approach should have been used from the start.
Given the bibliographic details of journal articles, there are basically two approaches to the problem of taking any two sets of details and asking whether they refer to the same article.
The details will normally consist of:
Article Title: Possibly with a translation, if the original title is not in English.
Author Names: In a wide variety of formats and in some cases with only the first 3 or 4 authors included.
Journal Title: Sometimes with an initial "The" missing.
ISSN: The International Standard Serial Number, if the journal has one.
Publication Year: Year of publication.
Volume Number: Some journals, particularly weekly journals, like New Scientist, no longer include a volume number.
Issue Number: Journals which only publish once a year sometimes don't use a issue number.
Page Number: Usually start and end page numbers, but sometimes just the start page is given.
In addition, some bibliographic databases include an abstract of the article. BLIS does not, but this is not relevant to this discussion.
The problems arise because different databases catalogue articles using different rules. There will be differences in the use of mark-up, in capitalisation (particularly in journal names), and most notoriously in the rules for author names, where some include hyphens and apostrophes, and some do not, some spell out forenames and other provide only initials, some include suffixes (e.g. Jr., III, IV) and others don't. Also, databases differ in what they include, some for example treat book reviews as a single article within an issue whereas others treat each review separately and others exclude reviews, some include short news articles whereas others don't, and so on. Given these variations, it's plainly impossible to get an exact solution and the real questions are (a) do we prefer the algorithm to err in certain ways rather than others, and (b) how do we measure whether the algorithm is behaving "reasonably"?
One approach is to use information in the article title and author names (probably only the first one or two), along with some other information e.g. journal name and ISSN. This method had been used in the past and while for some purposes it worked reasonably well, the particular implementation depended on a specialised database containing encoded versions of the article title etc, in order to provide acceptable performance. It would either have been necessary to use the same system here or to have written the matching code ourselves (both of which would have meant a great deal of extra work).
There was no possibility of using this solution, so it was decided to try a completely different and computationally much simpler approach which could easily be programmed to run in a reasonable time:
reduce the journal titles to a canonical form by converting everything to lower case, removing any punctuation and removing common words like "the", "of", ऺn", etc.
if both articles have an ISSN then match on this. if they match then compare the reduced journal names. if either of these fail then the articles are different, otherwise
match on volume numbers (null volume numbers match as equal) if they differ then the articles are different, otherwise
match on issue numbers (null issue numbers match as equal) if they differ then the articles are different, otherwise
match on start page.
The preference here was to err on the side of not matching, if possible, and an attempt was made to measure the effect of this by looking at articles which had successfully matched and checking that there were no erroneous matches. On this measure, the algorithm worked well. Unfortunately, measuring the opposite effect (i.e. those which should have matched, but did not) is extremely difficult without being able to anticipate the reasons why this might happen. These inevitably come to light later. There were two main ones:
Although the ISSN is allocated rigorously, the allocation of ISSN to journal within the databases is sometimes incorrect. This will often have occurred when a journal has split into two or more separate journals and the new ISSN's are not correctly transcribed. Because ISSN is a property of the journal, the error propagates to every article in that journal. This was probably the main source of serious errors.
UnCover catalogued some journals with a volume and issue number (presumably by allocating a volume number based on the publication year) whereas these were (correctly) catalogued in BLIS with only an issue number.
In retrospect, too much faith was probably placed in the ISSN and this led to problems which are extremely difficult to fix later. The ideal solution is for the publisher to assign an article identifier (the DOI would serve this purpose) which means that it stands a better chance of being correct but of course, this solution cannot be applied at a later stage, since the DOI or whatever would simply incorporate any errors.
This case study was written by Clive Massey who worked on the original BIDS system and was subsequently involved in many aspects of the services, including database and User Interface design. He was later employed by Ingenta, initially as Help Desk Manager and then on database design and administration.
[ Home Page - Surveys - Documents - Presentations - Search ]

Web page by Brian Kelly of UKOLN.
Last Modified 17-November-2003
Email comments to webmaster@ukoln.ac.uk
QA Focus Comments
Although the work described in this case study was funded by the European Commission, the approaches to management and use of metadata may be useful to projects which are addressing similar issues.
Citation Details
Managing And Using Metadata In An E-Journal, Kelly, B., QA Focus case study 01, UKOLN,
<http://www.ukoln.ac.uk/qa-focus/documents/case-studies/case-study-01/>
First published 25 October 2002.
Changes