 [ Home Page - Surveys - Documents - Presentations - Search ]
[ Home Page - Surveys - Documents - Presentations - Search ]
This page is for printing outthe briefing papers in the areas of digitisation. Note that some of the internal links may not work.
Producing an archive of high-quality images with a server full of associated delivery images is not an easy task. The workflow consists of many interwoven stages, each building on the foundations laid before. If, at any stage, image quality is compromised within the workflow, it has been totally lost and can never be redeemed.
It is therefore important that image quality is given paramount consideration at all stages of a project from initial project planning through to exit strategy.
Once the workflow is underway, quality can only be lost and the workflow must be designed to capture the required quality right from the start and then safeguard it.
Image QA within a digitisation project's workflow can be considered a 4-stage process.
Strategic QA is undertaken in the initial planning stages of the project when the best methodology to create and support your images, now and into the future will be established. This will include:
Process QA is establishing quality control methods within the image production workflow that support the highest quality of capture and image processing, including:
Sign-off QA is implementing an audited system to assure that all images and their associated metadata are created to the established quality standard. A QA audit history is made to record all actions undertaken on the image files.
On-going QA is implementing a system to safeguard the value and reliability of the images into the future. However good the initial QA, it will be necessary to have a system that can report, check and fix any faults found within the images and associated metadata after the project has finished. This system should include:
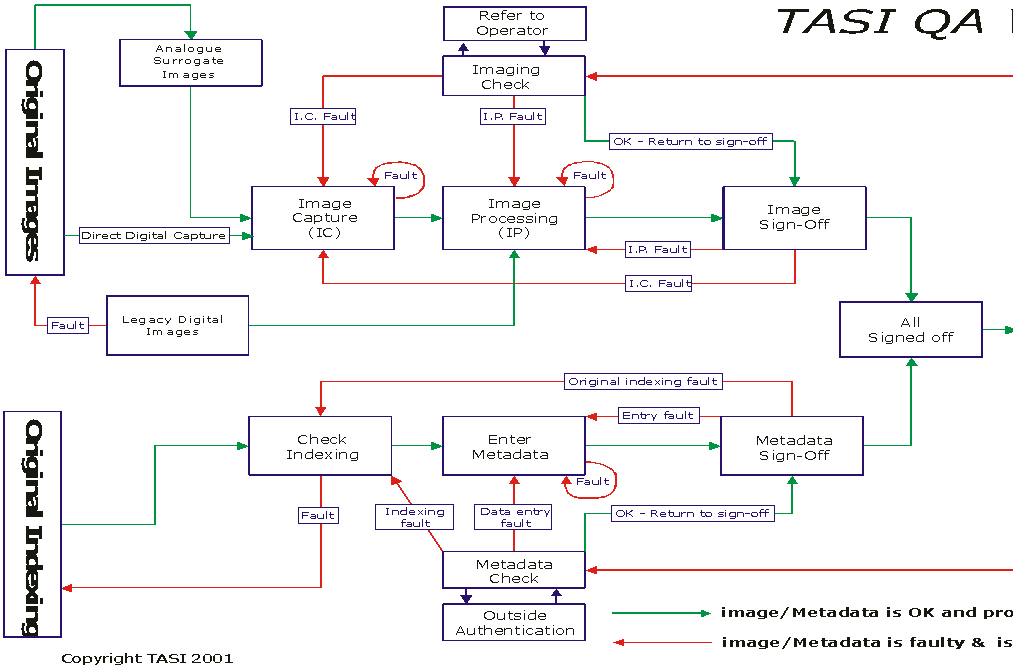
Much of the final quality of a delivered image will be decided, long before, in the initial 'Strategic' and 'Process' QA stages where the digitisation methodology is planned and equipment sourced. However, once the process and infrastructure are in place it will be the operator who needs to manually evaluate each image within the 'Sign-off' QA stage. This evaluation will have a largely subjective nature and can only be as good as the operator doing it. The project team is the first and last line of defence against any drop in quality. All operators must be encouraged to take pride in their work and be aware of their responsibility for its quality.
It is however impossible for any operator to work at 100% accuracy for 100% of the time and faults are always present within a productive workflow. What is more important is that the system is able to accurately find the faults before it moves away from the operator. This will enable the operator to work at full speed without having to worry that they have made a mistake that might not be noticed.
The image digitisation workflow diagram in this document shows one possible answer to this problem.
This document was written by TASI, the Technical Advisory Service For Images.
The creation of CAD (Computer Aided Design) models is an often complex and confusing procedure. To reduce long-term manageability and interoperability problems, the designer should establish procedures that will monitor and guide system checks.
Interoperability problems are often caused by poorly understood or non-existent operating procedures for CAD. It is wise to establish and document your own CAD procedures, or adopt one of the national standards developed by the BSI (British Standards Institution) or NIBS (National Institute of Building Sciences). These may be used to train new members in the house-style of a project, provide essential information when sharing CAD data among different users, or provide background material when depositing the designs with a preservation repository. Particular areas to standardize include:
Procedures on constructing your own CAD standard can be found in the Construct IT guidelines (see references).
When creating CAD data models, a consistent approach to layer creation and naming conventions is useful. This will avoid confusion and increases the likelihood that the designer will be able to manipulate and search the data model at a later date.
The designer has two options to ensure interoperability:
When exporting designs between different CAD applications it is common for model relationships to disintegrate, causing entities to appear disconnected or disappear from the design altogether. A common cause is the use of different tolerance levels - a method of placing limits on gaps between geometric entities. The method of calculating tolerance often varies in different applications: some use absolute tolerance levels (e.g. 0.005mm), others work to a tolerance level relative to the model size (e.g. 10-4 the size), while others have different tolerances according to the units used. When considering moving a design between different applications it is useful to ensure the tolerance level can be set to the same value and identify potential problem areas that may be corrupted when the data model is reopened.
Interoperability problems are also caused by differences in how the system identifies invalid geometry definitions, such as the three-sided degenerate NURBS surfaces. Some systems allow the creation of such entities, others will reject them, whereas some systems know that they are not permissible and in an effort to prevent them from being created, generate twisted four sided surfaces.
Digitisation is a production process. Large numbers of analogue items, such as documents, images, audio and video recordings, are captured and transformed into the digital masters that a project will subsequently work with. Understanding the many variables and tasks in this process - for example the method of capturing digital images in a collection (scanning or digital photography) and the conversion processes performed (resizing, decreasing bit depth, convert file formats, etc.) - is vital if the results are to remain consistent and reliable.
By documenting the workflow of digitisation, a life history can be built-up for each digitised item. This information is an important way of recording decisions, tracking problems and helping to maintain consistency and give users confidence in the quality of your work.
Workflow documentation should enable us to tell what the current status of an item is, and how it has reached that point. To do this the documentation needs to include important details about each stage in the digitisation process and its outcome.
By recording the answers to these five questions at each stage of the digitisation process, the progress of each item can be tracked, providing a detailed breakdown of its history. This is particularly useful for tracking errors and locating similar problems in other items.
The actual digitisation of an item is clearly the key point in the workflow and therefore formal capture metadata (metadata about the actual digitisation of the item) is particularly important.
Where possible, select an existing schema with a binding to XML:
To check your XML document for errors, QA techniques should be applied:
Quality assurance is essential to ensure GIS (Geographic Information System) data is accurate and can be manipulated easily. To ensure data is interoperable, the designer should audit the GIS records and check them for incompatibilities and errors.
Interoperability between GIS standards is encouraged, enabling complex data types to be compared in unexpected methods. However, the varying standards can limit the potential uses of the data. Designers are often limited by the formats available in different tools. When possible, it is advisable to use OpenGIS - an open, multi-subject standard constructed by an international standard consortium.
To integrate data from multiple databases, the data must be stored in a compatible field structure. Complementary fields in the source and target databases must be of a compatible type (Integer, Floating Point, Date, a Character field of an appropriate length etc.) to avoid the loss of data during the integration process. Checks should also be made that specific fields that are incompatible with similar products (e.g. dBase memo fields) are exported correctly. Specialist advice should be taken to ensure the memo information is not lost.
Databases are often created in an ad hoc manner without consideration of later requirements. To improve interoperability the designer should ensure data complies with relevant standards. Examples include the BS7666 standard for British postal addresses and the RCHME Thesauri of Architectural Types, Monument Types, and Building Materials.
The merging of two different data sources is likely to present specific problems. When combining two GIS tables, the designer should consider the possibility that they have been constructed using different projection measurement systems (a method of representing the Earth's three-dimensional form on a two-dimensional plane and locate landmarks by a set of co-ordinates). The projection co-ordinate systems vary across nations and through time: the US has five primary co-ordinate systems in use that significantly differ with each other. The British National Grid removes this confusion by using a single co-ordinate, but can cause problems when merging contemporary with pre-1940 maps that were based upon Cassini projection. This may produce incompatibilities and unexpected results when plotted, such as moving boundaries and landmarks to different locations that will need to be rectified before any real benefits can be gained. The designer should understand the project system used for each layer to compensate for inaccuracies.
When recreating real-world objects created by two different people, the designer should note the degree of accuracy. One person may measure to the nearest millimetre, while the other measures to the centimetre. To check this, the designer should answer the following questions:
These subtle differences may influence the resulting model, particularly when designing smaller objects.
Digital Rights Management (DRM) refers to any method for a software developer to monitor, control, and protect digital content. It was developed primarily as an advanced anti-piracy method to prevent illegal or unauthorised distribution of content. Common examples of DRM include watermarks, licensing, and user registration. It is in use by Microsoft and other businesses to prevent unauthorised copying and use of their software (obviously, the different protection methods do not always work!).
For institutions, DRM can have limited application. Academia actively encourages free dissemination of work, so stringent restrictive measures are unnecessary. However, it will have use in limiting plagiarism of work. An institution is able to distribute lecture notes or software without allowing the user to reuse text or images within their own work. Usage of software packages or site can also be tracked, enabling specific content to be displayed to different users. To achieve these goals different methodologies are available.
As stated above, Digital Rights Management is not appropriate for all organisations. It can introduce additional complexity into the development process, limit use and cause unforeseen problems at a later date. The following questions will assess your needs:
Do you trust your users to use your work without plagiarising or stealing it?
If the answer to question 1 is yes, do you wish to track unauthorised distribution or impose rules to prevent it?
Will you be financially affected if your work is distributed without permission?
Will digital rights restrictions interfere with the project goals and legitimate usage?
In terms of cost and time management, can you afford to implement DRM restrictions?
If the answer to question 5 is yes, can you afford a strong and costly level of protection (restrictive digital rights) or weak protection (supportive) that costs significantly less?
Digital Rights methodologies can be divided into two types supportive and restrictive. The first relies upon the user's honesty to register or acquire a license for specific functionality. In contrast, the restrictive method assumes the user is untrustworthy, placing barriers (e.g. encryption and other preventive methods) that will thwart casual users who attempt to infringe their work.
The simplest and most cost effective DRM strategy is supportive digital rights. This requires the user to register for data before they are allowed access, blocking all non-authorised users. This assumes that individuals will be less likely to distribute content if they can be identified as the source of the leak. Web sites are the most common use of this protection method. For example, Athens, the NYTimes and other portals provide registration forms or license agreement that the user must complete before access is allowed. The disadvantage of this protection method is the individual can easily copy or distribute data once they have it. Support digital rights is suited to organisations that want to place restrictions upon who can access specific content, but do not wish to restrict content being used by legitimate users.
Restrictive digital rights are more costly, but place more stringent controls over the user. It operates by checking if the user is authorised to perform a specific action and, if not, prevents them from doing it. Unlike supportive rights management, it ensures that content cannot be used at a later date, even if it has been saved to hard disk. This is achieved by incorporating watermarks and other identification methods into the content.
Restrictive digital can be divided into two sub-categories:
The requirements for Digital rights implementations are costly and time-consuming, making them potentially unobtainable by the majority of service providers. For a data archive it is easier to prevent unauthorised access to resources than it is to limit use when they actually possess the information.
Digital rights is reliant upon the need to record information and store it in a standard layout format that others can use to identify copyrighted work. Current digital rights establish a standard metadata schema to identify ownership
Two options are available to achieve this goal: create a bespoke solution or use an established rights schema. An established rights schema provides a detailed list of identification criteria that can be used to catalogue a collection and establish copyright holders at different stages. Two possible choices for multiple media types are:
Digital rights are an important issue that allows an institution to establish intellectual property rights. However, it can be costly for small organizations that simply wish to protect their image collection. Therefore the choice of supportive or restrictive digital rights is likely to be influenced by value of data in relation to the implementation cost.
The digitisation of digital audio can be a complex process. This document contains quality assurance techniques for producing effective audio content, taking into consideration the impact of sample rate, bit-rate and file format.
Sample rate defines the number of samples that are recorded per second. It is measured in Hertz (cycles per second) or Kilohertz (thousand cycles per second). The following table describes four common benchmarks for audio quality. These offer gradually improving quality, at the expense of file size.
| Samples per second | Description |
|---|---|
| 8kHz | Telephone quality |
| 11kHz | At 8 bits, mono produces passable voice at a reasonable size. |
| 22kHz | 22k, half of the CD sampling rate. At 8 bits, mono, good for a mix of speech and music. |
| 44.1kHz | Standard audio CD sampling rate. A standard for 16-bit linear signed mono and stereo file formats. |
The audio quality will improve as the number of samples per second increases. A higher sample rate enables a more accurate reconstruction of a complex sound wave to be created from the digital audio file. To record high quality audio a sample rate of 44.1kHz should be used.
Bit-rate indicates the amount of audio data being transferred at a given time. The bit-rate can be recorded in two ways - variable or constant. A variable bit-rate creates smaller files by removing inaudible sound. It is therefore suited to Internet distribution in which bandwidth is a consideration. A constant bit-rate, in comparison, records audio data at a set rate irrespective of the content. This produces a replica of an analogue recording, even reproducing potentially unnecessary sounds. As a result, file size is significantly larger than those encoded with variable bit-rates.
Table 2 indicates how a constant bit-rate affects the quality and file size of an audio file.
| Bit rate | Quality | MB/min |
|---|---|---|
| 1411 | CD quality | 10.584 |
| 192 | Good CD quality | 1.440 |
| 128 | Near CD quality | 0.960 |
| 112 | Near CD quality | 0.840 |
| 64 | FM quality | 0.480 |
| 32 | AM quality | 0.240 |
| 16 | Short-wave quality | 0.120 |
The majority of audio formats use lossy compression to reduce file size by removing superfluous audio data. Master audio files should ideally be stored in a lossless format to preserve all audio data.
| Format | Compression | Streaming support | Bit-rate | Popularity |
|---|---|---|---|---|
| MPEG Audio Layer III (MP3) | Lossy | Yes | Variable | Common on all platforms |
| Mp3PRO (MP3) | Lossy | Yes | Variable | Limited support |
| Ogg Vorbis (OGG) | Lossy | Yes | Variable | Limited support |
| RealAudio (RA) | Lossy | Yes | Variable | Popular for streaming |
| Microsoft wave (WAV) | Lossless | Yes | Constant | Primarily for Windows |
| Windows Media (WMA) | Lossy | Yes | Variable | Primarily for Windows |
Conversion between digital audio formats can be complex. If you are producing audio content for Internet distribution, a lossless-to-lossy (e.g. WAV to MP3) conversion will significantly reduce bandwidth usage. Only lossless-to-lossy conversion is advised. The conversion process of lossy-to-lossy will further degrade audio quality by removing additional data, producing unexpected results.
Whether digitising analogue recordings or converting digital sound into another format, sample rate, bit rate and format compression will affect the resulting output. Quality assurance processes should compare the technical and subjective quality of the digital audio against the requirements of its intended purpose.
A simple suite of subjective criteria should be developed to check the quality of the digital audio. Specific checks may include the following questions:
Objective technical criteria should also be measured to ensure each digital audio file is of consistent or appropriate quality:
Digital text is one of the oldest description methods, but remains divided by differing file format, encoding methods, schemas, and encoding methods. When choosing a digital text format it is necessary to establish the project needs. Is plain text suitable for the task and are text markup and formatting required? How will the information be displayed and where? This document describes these issues and provides some guidelines for their use.
Digital text has existed in one form or another since the 1960s. Many computer users take for granted that they can quickly write a letter without restriction or technical considerations. A commercial project, however, requires consideration of long-term needs and goals. To avoid complications at a later date, the developer must ensure the tools in use are the most appropriate for the task and, if not, what can be used in their place. To achieve this three questions should be answered:
It is often assumed that everyone can read text. However, this is not always the case. Digital text imposes restrictions upon the content that can have a significant impact upon the project.
In particular, there are two main issues:
The choice of format will be dependent upon the following factors:
For allowing universal information access, plain text remains useful. It has the advantage of being simple to interpret and small in file size. However, there are some differences in the method that is used to encode text characters. The most common variations are ASCII (American Standard Code for Information Interchange) and Unicode.
Several problems may be encountered when storing textual information. For text files it is a simple process to convert the file to Unicode. However, for more complex data, such as databases, the conversion process will become more difficult. Problems may include:
Although ASCII and Unicode are useful for storing information, they are only able describe each character, not the method they should be displayed or organized. Structural mark-up languages enable the designer to dictate how information will appear and establish a structure to its layout. For example, the user can define a tag to store book author information and publication date.
The use of structural mark-up can provide many organizational benefits:
The most common markup languages are SGML and XML. Based upon these languages, several schemas have been developed to organize and define data relationships. This allows certain elements to have specific attributes that define its method of use (see Digital Rights document for more information). To ensure interoperability, XML is advised due to its support for contemporary Internet standards (such as Unicode).
Digital video can have a dramatic impact upon the user. It can reflect information that is difficult to describe in words alone, and can be used within an interactive learning process. This document contains guidelines to best practice when manipulating video. When considering the recording of digital video, the digitiser should be aware of the influence of file format, bit-depth, bit-rate and frame size upon the quality of the resulting video.
Digital video consists of a series of images played in rapid succession to create the illusion of movement. It is commonly accompanied by an audio track. Unlike graphics and sound that are relatively small in size, video data can be hundreds of megabytes, or even gigabytes, in size.
The visual and audio information are individually stored within a digital 'wrapper' an umbrella structure consisting of the video and audio data, as well as information to playback and resynchronise the data.
Digital video remains a complex area that combines the problems of audio and graphic data. When choosing to encode video the designer must consider several issues:
The distribution method will have a significant influence upon the file format, encoding type and compression used in the project.
Removeable media - Video distributed on CD-ROM or DVD are suited to progressive encoding methods that do not conduct extensive error checking. Although file size is not as critical in comparison to Internet streaming, it continues to have some influence.
The compression type is dependent upon the need of the user and the type of removeable media:
| NAME | PURPOSE OF MEDIA | Compression | ||
| Streaming | Progressive | Media | ||
| Advanced Streaming Format (ASF) | Y | Temporal | ||
| Audio Video Interleave (AVI) | Y | Temporal | ||
| MPEG-1 | Y | VideoCD | Temporal | |
| MPEG-2 | Y | DVD | Temporal | |
| QuickTime (QT) | Y | Y | Temporal | |
| QuickTime Pro | Y | Y | Temporal | |
| RealMedia (RM) | Y | Y | Temporal | |
| Windows Media Video (WMV) | Y | Y | Temporal | |
| DivX | Y | Amateur CD distribution | Temporal | |
| MJPEG | Y | Spatial | ||
Table 1: A comparison list of the different file formats, highlighting their intended purpose and compression method.
The provision of video data for an Internet-based audience places specific restrictions upon the content. Quality of the video output is dependent upon three factors:
| Screen Size | Pixels per frame | Bit depth (bits) | Frames per second | Bandwidth required (megabits) |
| 640 x 480 | 307,200 | 24 | 30 | 221.184 |
| 320 x 240 | 76,800 | 16 | 25 | 30.72 |
| 320 x 240 | 76,800 | 8 | 15 | 9.216 |
| 160 x 120 | 19,200 | 8 | 10 | 1.536 |
| 160 x 120 | 19,200 | 8 | 5 | 0.768 |
Table 2: Indication of the influence of screen size, bit-depth and frames per second has upon required bandwidth
When creating video, the designer must balance the video quality with the facilities available to the end user. As an example, an 8-bit screen of 160 x 120 pixels, and 10-15 frames per second is used for the majority of content found on the Internet.
Video presents numerous problems for the designer caused by the complexity of formats and structure. Problems may include:
Temporal Compression - Reduces the amount of data stored over a sequence of frames. Rather than describing every pixel in each frame, temporal compression stores a key frame, followed by descriptive information on changes.
Spatial Compression - Condenses each frame independently by mapping similar pixels within a frame. For example, two shades of red will be merged. This results in a reduction in image quality, but enables the file to be edited in its original form.
Progressive Encoding - Refers to any format where the user is required to download the entire video before they are allowed to watch it.
Internet Streaming - Enables the viewer to watch sections of video without downloading the entire thing, allowing users to evaluate video content after just a few seconds. Quality is significantly lower than progressive formats due to compression being used.
Internet IPR is inherently complex, breaking across geographical boundaries, creating situations that are illegal in one country, yet not in another, or contradict existing laws on Intellectual Property. Copyright is a subset of IPR, which applies to all artistic works. It is automatically assigned to the creator of original material, allowing them to control all public usage (copying, adaptation, performance and broadcasting).
Ensuring that your organization complies with Intellectual Property rights requires a detailed understanding of two processes:
Unless indicated, copyright is assigned to the author of an original work. When producing work it is essential that it be established who will own the resulting product the individual or the institution. Objects produced at work or university may belong to the institution, depending upon the contract signed by the author. For example, the copyright for this document belongs to the AHDS, not the author. When approaching the subject, the author should consider several issues:
When producing work as an individual that is intended for later publication, the author should establish ownership rights to indicate how work can be used after initial publication:
Copyright is an automatically assigned right. It is therefore likely that the majority of works in a digital collection will be covered by copyright, unless explicitly stated. The copyright clearance process requires the digitiser to check the copyright status of:
Copyright clearance should be established at the beginning of a project. If clearance is denied after the work has been included in the collection, it will require additional effort to remove it and may result in legal action from the author.
In the event that an author, or authors, is unobtainable, the project is required to demonstrate they have taken steps to contact them. Digital preservation projects are particularly difficult in this aspect, separating the researcher and the copyright owner by many years. In many cases, more recently the 1986 Domesday project, it has proven difficult to trace authorship of 1000+ pieces of work to individuals. In this project, the designers created a method of establishing permission and registering objections by providing contact details that an author could use to identify their work.
If permission has been granted to reproduce copyright work, the institution is required by law to indicate intellectual property status. Metadata is commonly used for this purpose, storing and distributing IP data for online content. Several metadata bodies provide standardized schemas for copyright information. For example, IP information for a book could be stored in the following format.
|
Access inhibitors can also be set to identify copyright limitations and the methods necessary to overcome them. For example, limiting e-book use to IP addresses within a university environment.
Digitisation often involves working with hundreds or thousands of images, documents, audio clips or other types of source material. Ensuring these objects are consistently digitised and to a standard that ensures they are suitable for their intended purpose can be complex. Rather than being considered as an afterthought, quality assurance should be considered as an integral part of the digitisation process, and used to monitor progress against quality benchmarks.
The majority of formal quality assurance standards, such as ISO9001, are intended for large organisations with complex structures. A smaller project will benefit from establishing its own quality assurance procedures, using these standards as a guide. The key is to understand how work is performed and identify key points at which quality checks should be made. A simple quality assurance system can then be implemented that will enable you to monitor the quality of your work, spot problems and ensure the final digitised object is suitable for its intended use.
The ISO 9001 identifies three steps to the introduction of a quality assurance system:
First and foremost, any system for assuring quality in the digitisation process should be straightforward and not impede the actual digitisation work. Effective quality assurance can be achieved by performing four processes during the digitisation lifecycle:
The ISO 9001 system is particularly useful in identifying clear guidelines for quality management.
Digitisation projects should implement a simple quality assurance system. Implementing internal quality assurance checks within the workflow allows mistakes to be spotted and corrected early-on, and also provides points at which work can be reviewed, and improvements to the digitisation process implemented.
The market for vector graphics has grown considerably, in part, as a result of improved processing and rendering capabilities of modern hardware. Vector-based images consist of multiple objects (lines, ellipses, polygons, and other shapes) constructed through a sequence of commands or mathematical statements to plot lines and shapes in a two-dimensional or three-dimensional space. For Internet usage, this enables graphics to be resized to ever increasing screen resolutions without concern that an image will become 'jaggy' or unrecognisable.
Several vector formats exist for use on the Internet. These construct information in the same way yet provide different functionality. The table below provides a breakdown of the main formats.
| Name | Developer | Availability | Viewers | Uses |
| Scalable Vector Graphics (SVG) | W3C | Open standard | Internet browser | Internet-based graphics |
| Shockwave/Flash | Macromedia | Proprietary | Flash plugin for browser | Video media and multimedia presentation |
| Vector Markup Language (VML) | W3C | Open standard | MS Office, Internet Explorer, etc. | XML-based format. |
For Internet delivery of static images, the W3 recommend SVG as a standard open format for vector diagrams. VML is also common, being the XML language exported by Microsoft products. For text-based vector files, such as SVG and VML, the user is recommended to save content in Unicode.
If the vector graphics are to be integrated into a multimedia presentation or animation, Shockwave and Flash offer significant benefits, enabling vector animation to be combined with audio.
A major feature of vector graphics is its ability to construct detailed objects that can be resized without quality loss. XML (Extensible Markup Language) syntax the basis of the SVG and VML languages is understandable by non-technical users who wish to understand the object being constructed. The example below demonstrates the ability to create shapes using a few commands. The circle, shown on the left, was created by the textual data on the right.
 |
<svg width="8in" height="8in">
|
Figure 1: SVG graphics and associated code
Although XML enables the creation of a diversity of data types it is extremely meticulous regarding syntax usage. To remain consistent throughout multiple documents and avoid future problems, several conventions are recommended:
The use of XML enables a high level of interoperability between formats. When converting for a target audience, the designer has two options:
At the start of development it may help to ask your team the following questions:
Internet IPR is inherently complex, breaking across geographical boundaries, creating situations that are illegal in one country, yet not in another, or contradict existing laws on Intellectual Property. Copyright is a subset of IPR, which applies to all artistic works. It is automatically assigned to the creator of original material, allowing them to control all public usage (copying, adaptation, performance and broadcasting).
Ensuring that your organization complies with Intellectual Property rights requires a detailed understanding of two processes:
Unless indicated, copyright is assigned to the author of an original work. When producing work it is essential that it be established who will own the resulting product the individual or the institution. Objects produced at work or university may belong to the institution, depending upon the contract signed by the author. For example, the copyright for this document belongs to the AHDS, not the author. When approaching the subject, the author should consider several issues:
When producing work as an individual that is intended for later publication, the author should establish ownership rights to indicate how work can be used after initial publication:
Copyright is an automatically assigned right. It is therefore likely that the majority of works in a digital collection will be covered by copyright, unless explicitly stated. The copyright clearance process requires the digitiser to check the copyright status of:
Copyright clearance should be established at the beginning of a project. If clearance is denied after the work has been included in the collection, it will require additional effort to remove it and may result in legal action from the author.
In the event that an author, or authors, is unobtainable, the project is required to demonstrate they have taken steps to contact them. Digital preservation projects are particularly difficult in this aspect, separating the researcher and the copyright owner by many years. In many cases, more recently the 1986 Domesday project, it has proven difficult to trace authorship of 1000+ pieces of work to individuals. In this project, the designers created a method of establishing permission and registering objections by providing contact details that an author could use to identify their work.
If permission has been granted to reproduce copyright work, the institution is required by law to indicate intellectual property status. Metadata is commonly used for this purpose, storing and distributing IP data for online content. Several metadata bodies provide standardized schemas for copyright information. For example, IP information for a book could be stored in the following format.
|
Access inhibitors can also be set to identify copyright limitations and the methods necessary to overcome them. For example, limiting e-book use to IP addresses within a university environment.
You should ensure that you document policies for your project - remember that it can be difficult to implement quality if there isn't a shared understanding across your project of what you are seeking to achieve. For example, see the QA Focus policies on Web standards and link checking [1] [2].
You should ensure that your technical infrastucture which is capable of implementing your policies. For example, if you wish to make use of XHTML on your Web site you are unlikely to be able to achieve this if you are using Microsoft Word as your authoring tool.
You should ensure that you have the resources needed to implement your policies. This can include technical expertise, investment in software and hardware, investment in training and staff development, etc.
Without systematic checking procedures there is a danger that your policies are not implemented in practice. For example, see the QA Focus checking procedures for Web standards and link [3] [4].
You should seek to provide audit trails which provide a record of results of your checking procedures. This can help to spot trends which may indicate failures in your procedures (for example, a sudden growth in the numbers of non-compliant HTML resources may be due to deployment of a new authoring tool, or a lack of adequate training for new members of the project team).
Rather than seeking to develop quality assurance policies and procedures from scratch you should seek to learn from others. You may find that the QA Focus case studies [5] provide useful advice which you can learn from.
If you are in the position of having deployed effective quality assurance procedures it can be helpful for the wider community if you share your approaches. For example, consider writing a QA Focus case study [6].
You should seek to implement 'fitness for purpose' which is based on the levels of funding available and the expertise and resources you have available. Note that perfection is not necessarily a useful goal to aim for - indeed, there is a danger that 'seeking the best may drive out the good'.
Although the QA Focus Web site provides a wide range of resources which can help you to ensure that your project deliverables are interoperable and widely accessible you should remember that you will need to implement quality assurance within your project.
Rather than seeking to implement quality assurance across your project, it can be beneficial if quality assurance is implemented at a higher level, such as within you department or organisation. If you have an interest in more widespread deployment of quality assurance, you should read about the ISO 9000 QA standards [7].
Digitisation is a production process. Large numbers of analogue items, such as documents, images, audio and video recordings, are captured and transformed into the digital masters that a project will subsequently work with. Understanding the many variables and tasks in this process - for example the method of capturing digital images in a collection (scanning or digital photography) and the conversion processes performed (resizing, decreasing bit depth, convert file formats, etc.) - is vital if the results are to remain consistent and reliable. By documenting the workflow of digitisation, a life history can be built-up for each digitised item. This information is an important way of recording decisions, tracking problems and helping to maintain consistency and give users confidence in the quality of your work.
Workflow documentation should enable us to tell what the current status of an item is, and how it has reached that point. To do this the documentation needs to include important details about each stage in the digitisation process, and its outcome.
By recording the answers to these five questions at each stage of the digitisation process, the progress of each item can be tracked, providing a detailed breakdown of its history. This is particularly useful for tracking errors and locating similar problems in other items. The actual digitisation of an item is clearly the key point in the workflow, and therefore formal capture metadata (metadata about the actual digitisation of the item) is particularly important.
Where possible, select an existing schema with a binding to XML:
To check your XML document for errors, QA techniques should be applied:
Audio quality is surprisingly difficult to predict in a digital environment. Quality and file size can depend upon a range of factors, including vocal type, encoding method and file format. This document provides guidelines on the most effective method of handling audio.
When creating content for the Internet it is important to consider the hardware the target audience will be using. Although the number of users with a broadband connection is growing, the majority of Internet users utilise a dial-up connection to access the Internet, limiting them to a theoretical 56kbps (kilobytes per second). To cater for these users, it is useful to offer smaller files that can be downloaded faster.
The file size and quality of digital audio is dependent upon two factors:
By understanding how these three factors contribute to the actual file size, it is possible to create digital audio that requires less bandwidth, but provides sufficient quality to be understood.
File format denotes the structure and capabilities of digital audio. When choosing an audio format for Internet distribution, a lossy format that encodes using a variable bit-rate is recommended. Streaming support is also useful for delivering audio data over a sustained period without the need for an initial download. These formats use mathematical calculations to remove superfluous data and compress it into a smaller file size. Several popular formats exist, many of which are household names. MP3 (MPEG Audio Layer III) is popular for Internet radio and non-commercial use. Larger organisations, such as the BBC, use Real Audio (RA) or Windows Media Audio (WMA), based upon its digital rights support. Table 1 shows a few of the options that are available.
| Format | Compression | Streaming | Bit-rate |
| MP3 | Lossy | Yes | Variable |
| Mp3PRO | Lossy | Yes | Variable |
| Ogg Vorbis | Lossy | Yes | Variable |
| RealAudio | Lossy | Yes | Variable |
| Windows Media Audio | Lossy | Yes | Variable |
Figure 1: File Formats Suitable For Low-Bandwidth Delivery
Once recorded audio is saved in a lossy format, it is wise to listen to the audio data to ensure it is audible and that essential information has been retained.
Finally, it is recommended that a variable bit-rate is used. For speech, this will usually vary between 8 and 32kbp as needed, adjusting the variable rate accordingly if incidental music occurs during a presentation.
The audio quality required, in terms of bit-rate, to record audio data is influenced significantly by the type of audio that you wish to record: music or voice.
The creation of audio data for low-bandwidth environments does not necessitate a significant loss in quality. The audio should remain audible in its compressed state. Specific checks may include the following questions:
To produce high-quality digital images you should follow certain rules to ensure that the image quality is sufficient for the purpose. This document presents guidance on digitising and improving image quality when producing a project Web site.
Quality scans start with quality originals - high-contrast photos and crisp B&W line art will produce the best-printed results. Muddy photos and light-coloured line art can be compensated for, but the results will never be as good as with high-quality originals. The use of bad photos, damaged drawings, or tear sheets - pages that have been torn from books, brochures, and magazines - will have a detrimental effect upon the resultant digital copy. If multiple copies of a single image exist, it is advisable to choose the one that has the highest quality.
It is often difficult to improve scan quality at a later stage. It is therefore wise to scan the source according to consistent, pre-defined specifications. Criteria should be based upon the type of material being scanned and the intended use. Table 1 indicates the minimum quality that projects should choose:
| Use | Type | Dots Per Inch (dpi) |
| Professional | Text | 200 |
| Graphics | 600 | |
| Non-professional | Text | 150 |
| Graphics | 300 |
Table 1: Guidelines To Scanning Source Documents
Since most scans require subsequent processing, (e.g. rotate an image to align it correctly) that will degrade image quality, it is advisable to work at a higher resolution and resize the scans later.
Once the image has been scanned and saved to in an appropriate file format, measures should be taken to improve the image quality.
For best results, an image should lay with its sides parallel to the edge of the scanner glass. Although it is possible to straighten images that have been incorrectly digitised, it may introduce unnecessary distortion of the digital image.
To reduce the amount of subtle blur (or 'fuzziness') and improve visual quality, processing tools may be used to sharpen, smooth, improve the contrast level or perform gamma correction. Most professional image editing software contains filters that perform this function automatically.
Scanned images are often affected by many problems. Software tools can be used to remove the most common faults:
Be careful you do not apply the same effect twice. This can create unusual effects that distract the observer when viewer the picture.
Digital text has existed in one form or another since the 1960s. Many computer users take for granted that they can quickly write a letter without restriction or technical considerations. This document provides advice for improving the quality of structural mark-up, emphasising the importance of good documentation, use of recognised standards and providing mappings to these standards.
Although ASCII and Unicode are useful for storing information, they are only able describe each character, not the method they should be displayed or organized. Structural mark-up languages enable the designer to dictate how information will appear and establish a structure to its layout. For example, the user can define a tag to store book author information and publication date.
The use of structural mark-up can provide many organizational benefits:
The most common markup languages are SGML and XML. Based upon these languages, several schemas have been developed to organize and define data relationships. This allows certain elements to have specific attributes that define its method of use (see Digital Rights document for more information). To ensure interoperability, XML is advised due to its support for contemporary Internet standards (such as Unicode).
For organisations that already utilise structural mark-up the benefits are already apparent. However, some consideration should be made on improving the quality of descriptive data. The key to improving data quality is twofold: utilise recognised standards whenever possible; and establish detailed documentation on all aspects of the schema.
Documentation Documentation is an important, if often ignored, aspect of software development. Good documentation should establish the purpose of structural data, examples, and the source of the data. Good documentation will allow others to understand the XML without ambiguity.
Use recognised standards Although there are many circumstances where recognised schemas are insufficient for the required task, the designer should investigate relevant standards and attempt to merge their own bespoke solution with the various standard. In the long-term this will have several benefits:
TEI, Dublin Core and others provide cross-subject metadata elements that can be combined with subject specific languages.
Provide mappings to recognised standards Through the creation of different mappings the developer will standardise and enhance their approach to schema creation, removing potential ambiguities and other problems that may arise. In an organisational standpoint, the mappings will also allow improved relations between cooperating organisations and diversify the options available to use information in new ways.
Follow implementation conventions In addition to implementing recognised standards, it is important that the developer follow existing rules to construct existing elements. In varying circumstances this will involve the use of an existing data dictionary, an examination of XML naming rules. Controlled languages (for example, RDF, SMIL, MathML and SVG) use these conventions to implement specific localised knowledge.
Use of a consistent naming scheme and directory structure, as well as controlled vocabulary or thesaurus improve the likelihood that digitised content captured by many people over an extended period will be organized in a consistent manner that avoid ambiguity and can be quickly located.
This QA paper describes techniques to aid the storage and successful location of digital images.
Effective categorization of images stored on a local drive can be equally as important as storing them in an image management system. Digitisation projects that involve the scanning and manipulating of a large number of images will benefit from a consistent approach to file naming and directory structure.
An effective naming convention should identify the categories that will aid the user when finding a specific file. To achieve this, the digitisers should ask themselves:
This can be better described with an example. A digitisation project is capturing photographs taken during wartime Britain. They have identified location, year and photographer as search criteria for locating images. To organize this information in a consistent manner the project team should establish a directory structure, common vocabulary and shorthand terms for describing specific locations. Figure 1 outlines a common description framework:
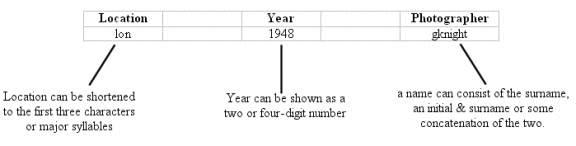
To avoid problems that may occur when the image collection expands or is transferred to a different system, the naming convention should also take account the possibility that:
Naming conventions will allow the project to avoid the majority of these problems. For example, a placeholder may be chosen if one of the identifiers is unknown (e.g. 'ukn' for unknown location, 9999 for year). Special care should be taken to ensure this placeholder is not easily mistaken for a known location or date. Additional criteria, such as other photo attributes or a numbering system, may also be used to distinguish images taken by the same person, in the same year, at the same location.
Digital derivatives (i.e. images that have been altered in some way and saved under a different name) introduce further complications in how you distinguish the original from the altered version. This will vary according to the type of changes made. On a simple level, you may simply choose a different file extension or store files in two different directories (Original and modified). Alternatively you may append additional criteria onto the filename (e.g. _sm for smaller images or thumbnails, _orig and _modif for original and modified).
The archival of digital images requires the consideration of the most effective method of storing technical and life cycle information. Metadata is a common method used to describe digital resources, however the different approaches may confuse many users.
This paper describes QA techniques for choosing a suitable method of metadata storage that takes into account the need for interoperability and retrieval.
Metadata may be associated with an image in three ways:
When considering the storage of image metadata, the designer should consider three questions:
The answer to these questions should guide the choice of the metadata storage model. Some file formats are not designed to store metadata and will require supplementation through the external model; other formats may not store data in sufficient detail for your requirements (e.g. lifecycle data). Alternatively, you may require IP (Intellectual Property) data to be stored internally, which will require a file format that supports these elements.
Metadata is intended for the storage and retrieval of essential information regarding the image. In many circumstances, it is not possible to store internal metadata in a format that may be read by different applications. This may be for a number of reasons:
Before choosing a specific image format, you should ensure the repository software is able to extract metadata and that editing software does not corrupt the data if changes are made at a later date. To increase the likelihood of this, you should take one of the following approaches:
Although this will not guarantee interoperability, these measures will increase the likelihood that it may be achieved.
To organise your image collection into a defined structure, it is advisable to develop a controlled vocabulary. If providing an online resource, it is useful to identify your potential users, the academic discipline from which they originate, and the language they will use to locate images. Many repositories have a well-defined user community (archaeology, physics, sociology) that share a common language and similar goals. In a multi-discipline collection it is much more difficult to predict the terms a user will use to locate images. The US Library of Congress [3], the New Zealand Time Frames [4] and International Press Telecommunications Council (IPTC) [5] provide online examples of how a controlled vocabulary hierarchy may be used to catalogue images.
A digitised image requires careful preparation before it is suitable for distribution. This document describes a workflow for improving the quality of scanned images by correcting faults and avoiding common errors.
The sequence in which modifications are made will have a significant contribution to the quality of the final image. Although conformance to a strict sequence is not always necessary, inconsistencies may be introduced if the order varies dramatically between images. The Technical Advisory Service for Images (TASI) recommends the following order:
Once you are satisfied with the results, the master image should be saved in a lossless image format - RGB Baseline TIFF Rev 6 or PNG are acceptable for this purpose.
Subsequent improvements by resizing or sharpening the image should be performed on a derivative.
The key to the development of a successful digitisation project is to separate it into a series of stages. All projects planning to digitise documents should establish a set of guidelines to help ensure that the scanned images are complete, consistent and correct. This process should consider the proposed input and output of the project, and then find a method of moving from the first to the second.
This document provides preparatory guidance to consider when approaching the digitisation of many still images using a flatbed scanner.
Before the digitisation process may begin, the digitiser requires suitable tools to scan & manipulate the image. It is possible to scan a graphic using any image processing software that supports TWAIN (an interface to connect to a scanner, digital camera, or other imaging device from within a software application), however the software package should be chosen carefully to ensure it is appropriate for the task. Possible criteria for measuring the suitability of image processing software include:
A timesaving may be found by utilizing a common application, such as Adobe Photoshop, Paintshop Pro, or GIMP. For most purposes, these offer functionality that is rarely provided by editing software included with the scanner.
Image distortion and dark shading at page edges are common problems encountered during the digitisation process, particularly when handling spine-bound books. To avoid these and similar issues, the digitiser should ensure that:
Scanning large objects that prevent the scanner lid being closed (e.g. a thick book) often causes discolouration or blurred graphics. Removing the spine will allow each page to be scanned individually, however this is not always an option (i.e. when handling valuable books). In these circumstances you should consider a planetary camera as an alternative scanning method.
It is often costly and time-consuming to rescan the image or improve the level of detail in an image at a later stage. Therefore, the digitiser should ensure that a consistent approach to digitisation is taken in the initial stages. This will include the choice of a suitable resolution, file format and filename scheme.
It is difficult to improve low quality scans at a later date. It is therefore important to digitise images at a at a slightly higher resolution (measured in pixels per inch) and scan type (24-bit or higher for colour, or 8-bit or higher for grey scale) than required and rescale the image at a later date.
Before scanning the image, the digitiser should consider the file format in which it will be saved. RGB Baseline TIFF Rev 6 is the accepted format of master copies for archival and preservation (although PNG is a possible alternative file format). To preserve the quality, it is advisable to avoid compression where possible. If compression must be used (e.g. for storing data on CD-ROM), the compression format should be noted (Packbits, LZW, Huffman encoding, FAX-CCITT 3 or 4). This will avoid incompatibilities in certain image processing applications.
Data intended for dissemination should be stored in one of the more common image formats to ensure compatibility with older or limited browsers. JPEG (Joint Photographic Experts Group) is suitable for photographs, realistic scenes, or other images with subtle changes in tone, however its use of 'lossy' compression causes sharp lines or letterings are likely to become blurred. When modifying an image, the digitiser should return to the master TIFF image, make the appropriate changes and resave it as a JPEG.
Digitisation projects will benefit from a consistent approach to file naming and directory structure that allows images to be organized in a manner that avoids confusion and can be quickly located. An effective naming convention should identify the categories that will aid the user when finding a specific file. For example, the author, year it was created, thematic similarities, or other notable factors. The digitiser should also consider the possibility that multiple documents will have the same filename or may lack specific information and consider methods of resolving these problems. Guidance on this issue can be found in related QA Focus documents.
Watermarking is an effective technology that solves many problems within a digitisation project. By embedding Intellectual Property data (e.g. the creator, licence model, creation date or other copyright information) within the digital object, the digitiser can demonstrate they are the creator and disseminate this information with every copy, even when the digital object has been uploaded to a third party site. It can also be used to determine if a work has been tampered with or copied.
This paper describes methods for establishing if a project requires watermarking techniques and criteria for choosing the most suitable type.
Before implementing watermarking within your workflow, you should consider its proposed purpose. Are you creating watermarks to indicate your copyright, using it as a method of authentication to establish if the content has been modified, or doing so because everyone else has a watermarking policy? The creation of a watermark requires significant thought and modification to the project workflow that may be unnecessary if you do not have a specific reason for implementing it.
For most projects, digital watermarks are an effective method of identifying the copyright holder. Identification of copyright is encouraged, particularly when the work makes a significant contribution to the field. However, the capabilities of watermarks should not be overstated. It is useful in identifying copyright, but is incapable of preventing use of copyrighted works. The watermark may be ignored or, given sufficient time and effort, removed entirely from the image. If the intent is to restrict content reuse, a watermark may not be the most effective strategy.
To assist the choice of a watermark, the project team should identify the required attributes of a watermark by answering two questions:
The answer to the first question is influenced by the skills and requirements of your target audience. If the copyright information is intended for non-technical and technical users, a visible watermark is the most appropriate. However, if the copyright information is intended for technical users only or the target audience is critical of visible watermarks (e.g. artist may criticise the watermark for impairing the original image), an invisible watermark may be the best option.
To answer the second question, the project team should consider the purpose of the watermark. If the intent is to use it as an authentication method (i.e. establish if any attempt to modify the content has been made), a fragile watermark will be a valued attribute. A fragile watermark is less robust towards modifications where even small change of the content will destroy embedded information. In contrast, if the aim is to reflect the owner's copyright, a more robust watermark may be preferential. This will ensure that copyright information is not lost if an image is altered (through cropping, skewing, warp rotation, or smoothing of an image).
If resilience is a required attribute of a digital watermark, the project team has two options: invisible or visible watermark. Each option has different considerations that make it suitable for specific purposes.
Invisible Watermarks
Invisible watermarks operate by embedding copyright information within the image
itself. As a rule, watermarks that are less visible are weaker and easier to
remove. When choosing a variant it is important to consider the interaction between
watermark invisibility and resilience. Some examples are shown in Table 1:
| Name | Description | Resilience |
| Bit-wise | Makes minor alterations to the spatial relation of an image | Weak |
| Noise Insertion | Embed watermark within image noise | Weak |
| Masking and filtering | Similar to paper watermarks on a bank note, it provides a subtle, though recognisable evidence of a watermark. | Strong |
| Transform domain | Uses dithering, luminance, or lossy techniques (similar to JPEG compression) on the entire or section of an image. | Strong |
Table 1: Indication of resilience for invisible watermarks
'Bit-wise' & 'noise insertion' may be desirable if the purpose is to determine whether the medium has been altered. In contrast, 'transform domain' and 'masking' techniques are highly integrated into the image and therefore more robust to deliberate or accidental removal (caused by compression, cropping, and image processing techniques) in which significant bits are changed. However, these are often noticeable to the naked eye.
Visible Watermarks
 A visible watermark is more resilient and may be used to immediately identify
copyright without significant effort by the user. However, these are, by design,
more intrusive to the media. When creating a visible watermark, the project team
should consider its placement. Projects funded with public money should be
particularly conscious that the copyright notice does not interfere with the
purpose of the project. A balance should be reached between the need to make the
watermark difficult to remove and its use to the user.
A visible watermark is more resilient and may be used to immediately identify
copyright without significant effort by the user. However, these are, by design,
more intrusive to the media. When creating a visible watermark, the project team
should consider its placement. Projects funded with public money should be
particularly conscious that the copyright notice does not interfere with the
purpose of the project. A balance should be reached between the need to make the
watermark difficult to remove and its use to the user.
Both watermarks make them suitable for specific situations. If handling a small image collection, it may be feasible (in terms of time and effort) to use both watermarks as a redundant protection measure - in the event that one is removed, the second is likely to remain.
If the project is using a watermark to establish their copyright, some thought should be made on the static information you wish to provide. For example:
Some content management systems are also able to generate dynamic watermarks and embed them within the image. This may record the file information (file format, image dimensions, etc.) and details about the download transaction (transaction identifier, download date, etc.). This may be useful for tracking usage, but may annoy the user if the data is visible.
To avoid unnecessary corruption of a watermark by the digitiser/creator themselves, the watermark creation process should be delayed until the final steps of the digitisation workflow. Watermarks can be easily removed when the digitiser is modifying the image in any way (e.g. through cropping, skewing, adjustment of the RGB settings, or through use of lossy compression). If an image is processed to the degree that the watermark cannot be recognized, then reconstruction of the image properties may be possible through the use of an original image.
[ Home Page - Surveys - Documents - Presentations - Search ]

Web page by Brian Kelly of UKOLN.
Last Modified 11-August-2004
Email comments to webmaster@ukoln.ac.uk