 [ Home Page - Surveys - Documents - Presentations - Search ]
[ Home Page - Surveys - Documents - Presentations - Search ]
The UK Centre for Materials Education [1] supports academic practice and innovative learning and teaching approaches in Materials Science and Engineering, with the aim of enhancing the learning experience of students. The Centre is based at the University of Liverpool, and is one of 24 Subject Centres of the national Learning and Teaching Support Network [2].
Within any field, the use of discipline-specific language is widespread, and UK Higher Education is no exception. In particular, abbreviations are often used to name projects, programmes or funding streams. Whilst use of these initialisms can be an essential tool of discussion amongst peers, they can also reduce accessibility and act as a barrier to participation by others.
In this context, many individuals and organisations maintain glossaries of abbreviations. However, glossaries of this nature usually require manual editing which can be incredibly resource intensive.
This case study describes a tool developed at the UK Centre for Materials Education to help demystify abbreviations used in the worlds of Higher Education, Materials Science, and Computing, through the use of an automated 'Web crawler'.
The HTML 4 specification [3] provides two elements that Web authors can use to define abbreviations mentioned on their Web sites; <abbr> to markup abbreviations and <acronym> to markup pronounceable abbreviations, known as acronyms.
The acronyms and abbreviations are normally identified by underlining of the text. Moving the mouse over the underlined words in a modern browser which provides the necessary support (e.g. Opera and Mozilla) results in the expansion of the acronyms and abbreviations being displayed in a pop-up window. An example is illustrated in Figure 1.
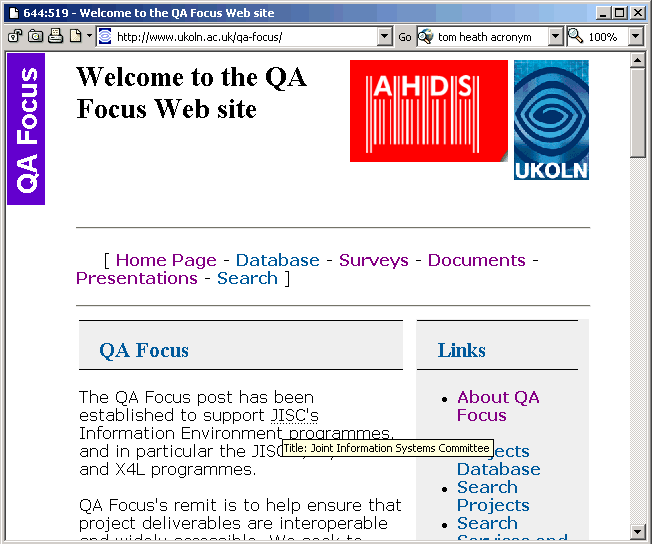
Figure 1: Rendering Of The <ACRONYM> Element
Using this semantic markup as a rudimentary data source, the crawler retrieves Web pages and evaluates their HTML source code for instances of these tags. When either of the tags is found on a page, the initials and the definition provided are recorded in a database, along with the date/time and the URL of the page where they were seen.
The pairs of abbreviations and definitions identified by the crawler are then made freely available online at [4] as illustrated in Figure 2 to allow others to benefit from the work of the crawler.
The limiting factor first encountered in developing the crawler has been the lack of Web sites making use of the <abbr> and <acronym> tags. Consequently, the number of entries defined in the index is relatively small, and the subject coverage limited. Sites implementing the tags are predominantly those that address Web standards and accessibility, leading to a strong bias in the index towards abbreviations used in these areas.
A number of factors likely contribute to a lack of use of the tags. Firstly, many Web authors might not be aware of the existence of the tags. Even in the current generation of Web browsers, there is little or no support for rendering text differently where it has been marked up as an abbreviation or acronym within a Web page. Therefore there is little opportunity to discover the tags and their usage by chance.
The second major factor affecting the quality of the index produced by the crawler has been the inconsistent and occasionally incorrect definition of terms in pages that do use the tags. Some confusion also exists about the semantically correct way of using the tags, especially the distinction between abbreviations and acronyms, and whether incorrect semantics should be used in order to make use of the browser support that does exist.
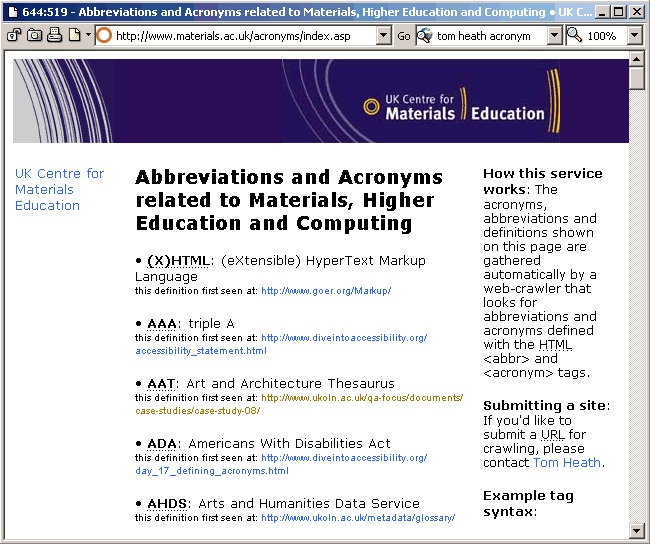
Figure 2: The Glossary Produced By Harvesting <ABBR> and <ACRONYM> Elements
To provide a truly useful resource, the crawler needs to be developed to provide a larger index, with some degree of subject classification. How this classification might be automated raises interesting additional questions.
Crucially, the index size can only be increased by wider use of the tags. Across the HE sector as a whole, one approach might be to encourage all projects or agencies to 'take ownership' of their abbreviations or acronyms by defining them on their own sites. At present this is rarely the case.
In order to provide a useful service the crawler is reliant on more widespread deployment of <acronym> and <abbr> elements and that these elements are used correctly and consistently. It is pleasing that QA Focus is encouraging greater usage of these elements and is also addressing the quality issues [4].
Lastly, if sites were to produce their pages in XHTML [5] automated harvesting of information in this way should be substantially easier. XML parsing tools could be used to process the information, rather than relying on processing of text strings using regular expressions, as is currently the case.
Tom Heath
Web Developer
UK Centre for Materials Education
Materials Science and Engineering
Ashton Building, University of Liverpool
Liverpool, L69 3GH
Email t.heath@liv.ac.uk
URL: <http://www.materials.ac.uk/about/tom.asp>
[ Home Page - Surveys - Documents - Presentations - Search ]

Web page by Brian Kelly of UKOLN.
Last Modified 27-July-2006
Email comments to webmaster@ukoln.ac.uk