Technical description and implementation of the eBank UK aggregator service and cross-searching web interface |
![]()
This document describes, from a technical perspective, the deployment of an aggregator service and web search interface developed as part of eBank UK project. eBank UK is a JISC-funded project which is part of the Semantic Grid Programme.
The project builds on the technical architecture currently being deployed within the ePrints UK Project and which has been described in an Ariadne article. The architecture supports the harvesting of metadata from eprint archives in UK academic institutions and elsewhere using the OAI Protocol for Metadata Harvesting (OAI-PMH). The eBank UK Project will augment this work by also harvesting metadata about research data from institutional 'e-data repositories'. A specific area of chemistry (crystallography) has been used as an exemplar activity that produces datasets during research activities, and an e-data repository has been developed at the University of Southampton. Metadata records harvested from e-data repositories will be stored in the central database alongside publication metadata records.
A web interface to the central database of e-print and e-data metadata is being hosted by the Resource Discovery Network(RDN), and a CGI-based embedding mechanism has been used to embed the service into the PSIGate web site.
The software requirements for the 'e-data repositories' were developed by Southampton and modifications were made to the eprints.org software to provide storage for and metadata descriptions of the research data output.
The metadata schema requirements for research data were the subject of a joint investigation by Southampton and UKOLN. [Project Metadata Schema Page] The user requirements are being documented in a separate work package. [Project User Requirements Page]. In this document some reference is made to user requirements for the web search interface where they are relevant to explain the requirements for the aggregator and search service.
The system consists of e-data and e-print repositories which expose metadata about e-data and e-prints. The metadata links the e-prints to the e-data records. The metadata is harvested into a central database, where it is indexed and made available for searching via a web interface. Remote interfaces that give access to searching of the central database will also be supported using an embedding mechanism. The eBank UK technical requirements for aggregator service and cross-searching web interface are described in a separate document.
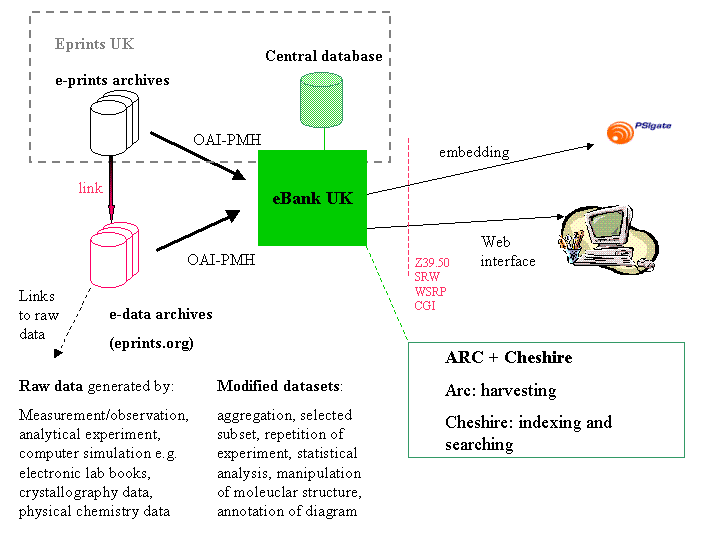
These are repositories which are OAI-PMH compliant. The description of the Open Archives Initiaitive Protocol for Metadata Harvesting is beyond the scope of this report. It is assumed that the reader is familiar with the OAI-PMH. For further information see the Open Archives Initiative Web Site and an overview in the eBank UK paper presented at the PV conference in October 2004.
The requirements for the e-print and e-data repositories, for the purposes of the agreggator and search system, are:
The aggregator and search system is agnostic about whether repositories expose metadata about e-prints or e-data or both and about whether the repositories hold metadata and content (e-data and/or e-prints) or just metadata. The system is also agnostic about whether content-holding repositories store the metadata embedded into the content or separately from it. The only requirement of repositories is that they are able to expose metadata using the appropriate schema and the OAI-PMH.
The detailed implementation of the e-data repository has been undertaken by Southampton. Creation of original data may be followed by one or more additional processes which in turn generate modified datasets. Examples of modfied datasets include:
The derived data is related to the original data in some way. It may also be included in publications, or stored. The example area used in the pilot development is that of Crystallography. Crystallography experiments produce a number of data files during a sequential process of measurement and analysis; the process consists of a number of well-defined stages. The data files produced contain raw data and derived results; some of the files are presented according to internationally agreed formatting standards. The Southampton e-data repository supports the dataset depostion and metadata creation process for the crystallography data.
Several forms of publications may refer to datasets, and these include peer-reviewed articles, fast track Letters formats, as well as other sources, e.g. secondary literature:
The publications and the datasets are described by metadata, and the metadata is
made available for harvesting (as e-print and e-data records) via the
Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH).
The e-data and e-print repositories themselves operate
as a black-box as far as the aggregator system is
concerned, so long as the OAI-PMH is supported, and metadata is exchanged
according to an agreed schema.
Metadata about e-data is defined in the CLRC Scientific Metadata Model as
"all the information, additional to the raw data itself, which a potential user of
the data would need to know to be able to make full and accurate use of the data
in a subsequent scientific analysis"
The metadata schema requirements for data sets has been the subject of further study within the project and is reported in a supporting study.
For the purposes of the aggregator and search service, the metadata schema defines the content of the metadata records that are available for harvesting. The schema can also be used to configure the searching engine; the content of the metadata determines the searches that can be offered to the user. Some of the user requirements influenced and shaped the metadata schema used. The description of the schema used to exchange metadata records is available in a separate document. The schema is expressed in XML schema definition language, since exchange of XML metadata is a requirement of the OAI-PMH. The documentation describes how the schema has been applied in the pilot development of the eBank UK project, and provides links to the XML schema definitions.
The metadata from the e-prints archive and the e-data archives is harvested using the Open Archives Initiative Protocol for Metadata Harvesting (version 2). The harvested metadata is stored in a central repository. The frequency of harvesting will initially depend on the frequency of updates of the repositories that are being harvested, but more regular harvesting may be required in the longer term
There is a requirement for the research data to be referenced from the publications or learning materials so that a user can roll-back to the original data from an information source.
Some links are required between publication and dataset metadata and the
publications and datasets. These links are:
Publication metadata --> publication
publication metadata --> dataset
dataset metadata --> publication
dataset metadata --> dataset
These links are required to identify and locate the publications and datasets,
and should be based on existing standards and mechanisms such as URIs
(e.g. URL, PURL or DOI), and/or OpenURLs (e.g. in electronic versions of publications, which might include a DOI where one exists).
Currently
citations (e.g. from a publication to another publication, or citing a dataset)
typically occur in a human-readable form (i.e. plain text),
but increasingly they will take other forms, such as those mentioned above.
The searching capabilities required are dependant on the outcome of user requirements, which are referred to in the detailed design section. The indexing and searching engine searches over the harvested metadata records and retrieves records relevant to the search criteria, for display to the user. The search engine must be able to search within specific metadata fields or indeed combinations of fields. Searches also need to be limited to one set of metadata (e.g e-prints or e-data). There are also dependencies between the choice of metadata schema used and the indexing and searching engine that can be applied. The search interface will be available as Z39.50 (Bath Profile), one of the protocols defined within the JISC Information Environment architecture, and SRW, the Search/Retrieve Web Service protocol (also recommended in the JISC IE). The tools chosen therefore need to support these standards.
The Web Interface allows end-users to carry out searches against the e-print and e-data metadata,
through a web browser.
This is the human-facing part of the system that carries search
requests to the eBank system, interacting with the searching
mechanisms, and displays results to users.
The detailed requirements for the interface were developed from the user requirements.
An iterative style of development was adopted with cycles of user
testing and feedback, building incremental functionality into the interface
as the functionality became available from the underlying systems,
and in response to better elucidation of the requirements.
The Web Interface will conform to Web Accessibility guidelines (the W3C Web Accessibility Initiative Recommendations).
The aim is to be accessible by a variety of browsers, hardware systems, automated programs and end users.
The Web Site must be usable by browsers that support W3C recommendations such as HTML,
Cascading Style Sheet (CSS) and the Document Object Model (DOM). The
appearance of the website will be controlled by the use of style sheets
in line with W3C architecture and accessibility recommendations.
Text-based content will be delivered as XHTML 1.0 or HTML 4.
The Accessibility requirements were adapted from NOF guidelines
The scope of the interface includes presentation of the results
showing e-prints and e-data that match the search criteria,
and their availability. It is not within scope to
display the data sets themselves,
the user may retrieve the data sets from thier location.
The support of interaction with the data sets
using data-specific applications (e.g. by using plug-ins) is considered to be out
of scope for the purposes of this pilot.
The embedding mechanism will enable the eBank UK searches to be embedded within an external website. The user will be able to enter requests from the external web site. The mechanism will relay the request to the eBank service and return results to the user in an adaptable form that allows the results to be presented within the user's site. The mechanism will be based on CGI; WSRP will also be investigated.
Acces Management to data sets may be required for example to provide access to referees during the refereeing process, or to limit access to authorised persons. Since it is only the metadata that is being harvested by the aggregator, and not the datasets themselves, access management and control for data sets is considered out of scope for the pilot development. The metadata is assumed to be freely harvestable if it has been presented for harvesting by the repository OAI-PMH interface. However the user requirements will be documenting authentication and authorisation needs. Hooks will be made available where possible, for example, by noting the levels of access needed, and developing the metadata schemas accordingly.
The implementation follows a pattern that has been deployed successfully in the Resource Discovery Network and the eprints UK project. It uses two readily available open source toolkits (ARC and Cheshire), configured to local requirements, in addition to some locally-developed scripts. These toolkits support the documented standards chosen for the eBank UK project (OAI-PMH, XML Schemas, Z39.50), and offer the additional benefit of familiarity (for the project software developer) as well as software support (e.g. bug fixing) from the ARC and Cheshire development teams. The use of the ARC toolkit and Cheshire system used in tandem to deliver search services is proven and documented on the RDN website. The two tools complement each other, ARC providing the harvesting and central database control mechanisms and Cheshire supplying advanced metadata searching capabilities and Z39.50 interfaces. For instructions on system requirements, downloading, installing and configuring of ARC and Cheshire, please refer to the RDN document and the respective toolkit documentation.
Harvesting is the name given to the process defined in the OAI-PMH by which metadata is transferred from a repository (a data provider) to a service provider. The role of the aggregator (within the service provider) is to issue OAI-PMH requests to the e-data and e-print repositories. The requests result in the harvesting of metadata from the various repositories into a central repository which consists of the aggregation of all the collected metadata. Metadata records consist of XML documents which adhere to a defined schema (as required by OAI-PMH).
An existing OAI-PMH toolkit has been used for the harvesting and to support the central repository. The ARC software is made available by Old Dominion University Digital Library Research Group through a SourceForge site and is an open source implementation of the OAI-PMH, including a harvester. It has been used for a number of months at the RDN to support the cross-searching of subject hubs through the Resource Finder service. ARC supports MySQL connectivity, timed harvesting, resumption token and request control, and is robust in dealing with faulty XML.
The ePrints UK project also hosts an installation of the ARC software on an RDN server, and harvests e-prints metadata using that set-up. ARC is used in conjunction with the MySQL database installation on the RDN machine. The ARC version has been updated regularly and is now version 0.97. For the eBank UK pilot development, the e-Prints UK installation of ARC has been re-used as well as the same RDN MySQL instance. ePrints UK harvests eprints into a central repository, defined as a database in MySQL. eBank UK defined a separate database into which the e-data metadata records could be harvested.
The MySQL databases when used by ARC (and therefore by the
ePrints UK and eBank UK projects) follow a pre-defined structure
which is required and expected by the ARC software. Such databases can be set up using an available
file after suitable configuration with local MySQL and OAI-PMH repository details.
Within ARC, the metadata records are stored within a specific database table
(called main) with the entire XML of the metadata record stored within the
metadata column
of the table. This stored metadata can thereafter be accessed either through
the ARC interface or else directly by means of SQL calls to the MySQL database.
Harvesting is initiated by running the ARC harvesting scripts. The harvesting scripts use values stored in the ARC MySQL database to determine the location of repositories and other harvesting parameters.
For the eBank UK implementation, the address of the eData repository to be harvested is http://eprints.ebank.ecs.soton.ac.uk/perl/oai2. The metadataPrefix argument in OAI-PMH specifies the format of metadata record requested, which supports selective harvesting from repositories which expose metadata in more than one format. The metadata prefix used for the eBank UK pilot is ebank_mets to return records conforming to the agreed metadata schema.
The separation of the eData database and the ePrint database within the MySQL installation allows separate control of harvesting. During the pilot development, harvesting of the eData records was carried out frequently according to changes to the eData repository as notified by the eData repository developer in communication by email. A number of complete reharvests were required whilst the implementation of the eData repository was refined. Feedback was given throughout the iterative process until it was ensured that the metadata exposed by the eData repository complied with the designated metadata schema.
Once the eData repository has become stable, and regular incremental additions of metadata are made to the repository, regular harvesting would be required to keep the central repository updated with the eData records. OAI-PMH provides mechanisms (through datestamps and specific requests) such that only new and updated records are harvested on request, resulting in incremental data harvesting. When using ARC, regular harvesting can be controlled automatically, for example through a shell script which kicks off the ARC harvester at certain specific periods.
As of August 2004, regular harvesting of the edata repository has not been necessary (reflecting the experimental and evolving nature of the work on the metadata schemas and the e-data repository during the pilot development). Regular harvesting can be easily implemented once the eData repository starts to grow steadily, and the metadata schema is deemed stable.
The intention of the eBank UK pilot search was to allow cross-searching and linking between data sets and publications by examining metadata describing both sets of resources. Originally, it was envisaged that the publication metadata would become available through the ePrints UK repository. However, at the time of development of the pilot eBank UK search service (July 2004), the corpus of metadata records harvested by ePrints UK, despite numbering well over 50,000 records, did not include sufficient publication metadata relevant to the datasets described in the eBank UK project. In other words, the coverage of the harvested e-prints did not extend to the specific sub-discipline of crystallography with which the eBank UK project has engaged.
An intervening measure was required to enable the demonstration of linking to go ahead as planned. Through contacts made by the crystallographers participating in the project, arrangements were put in place with a crystallograpy journal publisher to supply a sample of publication metadata from their series of publications relating directly to crystallography. The publisher supplied XML files with the metadata conforming to a standard structure used in exchanging the metadata between on line publishing services. Using XSLT, this metadata was easily transformed into a metadata format that was compatible for inclusion in the cross-search.
The role of indexing and searching within the pilot is to support the discovery and selection of metadata records describing resources which correspond to the information needs of the user of the searching service. The user typically expresses an information need through a web form which specifies parameters for which the user can select or enter values. This search request needs to be re-expressed in some format that can be used internally by the search engine. The human facing portions of the system need to be presented to mediate human-computer interaction. The visual interfaces take into account the information-processing needs of the human, with language and layout chosen to support the user's task of describing the search requirements. However at a lower layer the information processing takes place as a machine to machine interaction and presents different design and technical requirements.
To meet the machine information processing needs, a standard protocol was chosen at the machine layer to express a search and match it against the metadata records. Z39.50 is an information retrieval standard created for the purpose of standardising requests for information retrieval It is recommended by the JISC and as an established and open standard it presents an interface which is open to re-use at a machine level. Third party applications should be able to interrogate the Z39.50 database without necessarily requiring any knowledge of how the service is delivered, i.e. the internal workings, implementation and design are transparent to the automated user.
Cheshire is an indexing and searching engine, that also provides support for Z39.50. Cheshire is, at its heart, an SGML search engine, that uses SGML formatted (and more recently, XML-formatted) documents. It supports full text documents, and many different types of query including relevance ranked, boolean and mixtures of the two. It can run in a server mode, and doing so uses the Z39.50 protocol, or via a CGI front end to be accessed from a web browser. It is open source, and freely available for use by academic or non commercial organisations. It is written and maintained primarily by Ray Larson at UC Berkeley.
Since Cheshire searches and indexes XML files, it is ideal for working with metadata harvested using the OAI-PMH (which by the requirements of that protocol must be formatted to a documented XML standard). Cheshire can be configured to work with relational databases. However a simpler approach is adopted in dealing with repositories in the RDN and ePrints UK, and this has been maintained for the eBank UK project. Some simple Perl scripts are used to access the harvested metadata in the mySQL database, using the SQL interface to generate XML files containing the marked-up metadata. The XML is transformed slightly, removing extraneous mark-up (such as that required by the OAI-PMH protocol, headers, administrative fields etc.). Following transformation, the metadata conforms to a documented schema that conforms to the guidelines for encoding Dublin Core in XML.
The XML schema definition is also used in the process of configuring Cheshire to define which metadata fields are indexed and searched. The metadata elements are compared against the search requirements of users and a set of suitable indexes are defined, against which searches can be made. This process provides a way of validating the metadata schema aginst the access and discovery requirements of users. The metadata fields and their attributes must be sufficiently expressive to support searching at the granularity required by the users. An example can be provided by examining the crystal structure search requirements (which are described further in a section below).
Briefly, there are a number of ways of describing crystal structure, including empirical formulae, standardised compound name, and crystallography database identifier. When expressed within the metadata schema, these various vocabularies for describing crystal structure are used as attributes of a subject metadata field (The subject element is used since the crystal structure is the 'topic' or subject of the data that is being described). The following is an example extract of the metadata showing various types of vocabulary used to describe a molecule:
<dc:subject xsi:type="ebankterms:EmpiricalFormula">C27H48</dc:subject> <dc:subject xsi:type="ebankterms:IUPAC">5alpha-cholestane</dc:subject> <dc:subject xsi:type="ebankterms:CCDC">ZZZKGI01</dc:subject> <dc:subject xsi:type="ebankterms:CompoundClass">Organic</dc:subject>
Fine-grained searches can be limited to one of the specific ways (or vocabularies) used to describe the structure. Cheshire can be configured to create indexes based on the attributes of the XML element. Therefore specifying the particular vocabulary applied within the metadata makes it possible to achieve this fine-grained searching limited by the type of terms (or vocabularies), by defining and searching against those specific named indexes which Cheshire creates. (Note there may well be other reasons for making the vocabulary distinctions in the metadata, besides fine-grained searching). Thus based on the example above, and as demonstrated in the web interface description later, a search against empirical formula can be matched against the index built by selecting the metadata fields based on the xsi:type attribute with value "ebankterms:EmpiricalFormula".
In the process of developmening the pilot, a bug was revealed in the Cheshire code which was reported to the Cheshire team. XML Schema support is a relatively recent feature of the Cheshire software. The metadata schema to which records conform is derived from and references the extended Dublin Core XML schema maintained by the DCMI. This schema uses the substitution groups feature of the XML Schemas standard. During development of the search service it was revealed that Cheshire had poor support for this feature of schemas, creating a potential barrier for the use of Cheshire in applications that, like eBank UK, employ extended Dublin Core XML schemas. The problem was rapidly fixed by the Cheshire developers and the fix was made available in the next minor release of the Cheshire software (version Version 2.39g). Thus the development of the eBank UK pilot has contributed to the validation of one of the primary tools for Z39.50, which was developed in the JISC/NSF DLI initiative. This collaboration between the eBank UK development team and the Cheshire developers has strengthened the Cheshire software by helping to address its support for the extended Dublin Core encoding in XML. Dublin Core is one of the recommended standards in the JISC IE.
The Z39.50 eBank UK server runs on port 2112 and can be accessed on z3950.rdn.ac.uk:2112
The Web Interface is the user-facing part of the system that enables users to interact with the metadata. The search service at the aggregator (or service provider) facilitates discovery of data across the repositories from which the aggregator has harvested metadata, providing a common point of entry into the datasets through their metadata descriptions. The search interface helps both in discovering the presence of data sets held or described by the remote e-Data repositories, and also in locating and accessing those data sets. In other words, the eBank UK search service mediates the discovery of and access to the data sets. Furthermore, since there may be links between the data sets and the publications, the aggregator may help to enable linking to be made between related resources. These links are established through the metadata descriptions and can be revealed to the user through the search interface.
The web site for the eBank UK search service is hosted by the Resource discovery Network and was created at http://eprints-uk.rdn.ac.uk/ebank-demo/. The web site is delivered using Perl CGI scripts which use forms to collect the input from the user, modify the query to a format suitable for use with Cheshire, then interact with the search engine through Cheshire's tcl interface. CSS has been used to define the display characteristics of the interface when presented through a web browser.
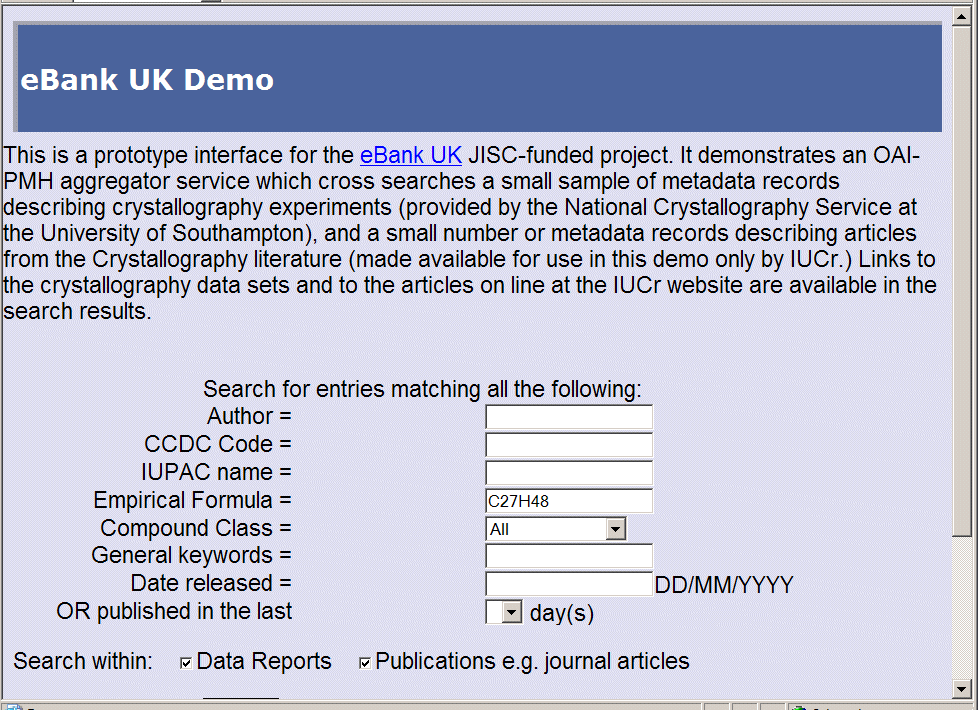
Please refer to the User Requirements Page for full explanation of user requirements. The discovery of data sets is to be made by the searching of metadata descriptions. The human user can express information needs through the web interface by defining search parameters against which the metadata records will be matched. A number of search criteria emerge from the user requirements discussion, and these are summarised below.
One of the requirements for crystallographers is to search by crystal structure. Crystal structure can be described in a number of ways, such as 'the formula of the chemical compound' or 'the compound name'. The scenario in which the crystal structure search is likely to be used starts as: "A scientist would like to know whether a certain compound has been studied" Alternative search criteria are:
Combination searches must also be supported e.g.
The following screen shot shows how these search parameters are presented to the user as a web form:
There are two main types of resources that the pilot search service deals with: data sets (specifically ones generated from crystal structure experiments), and publications (journal articles from a crystallography publisher). When displaying results, a two-column layout is used to present the two types of resources, in batches of ten. A selection of the fields from the metadata records present a concise description of the dataset. Within the e-data repository, (where the data sets are actually held), and from which the metadata is harvested, the data is presented to the users as an archive of reports, one of which is shown below:
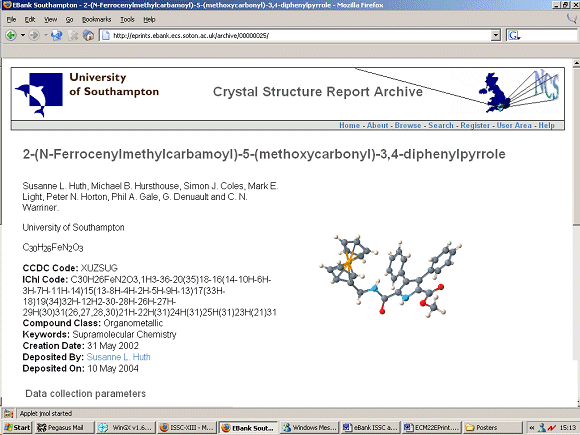
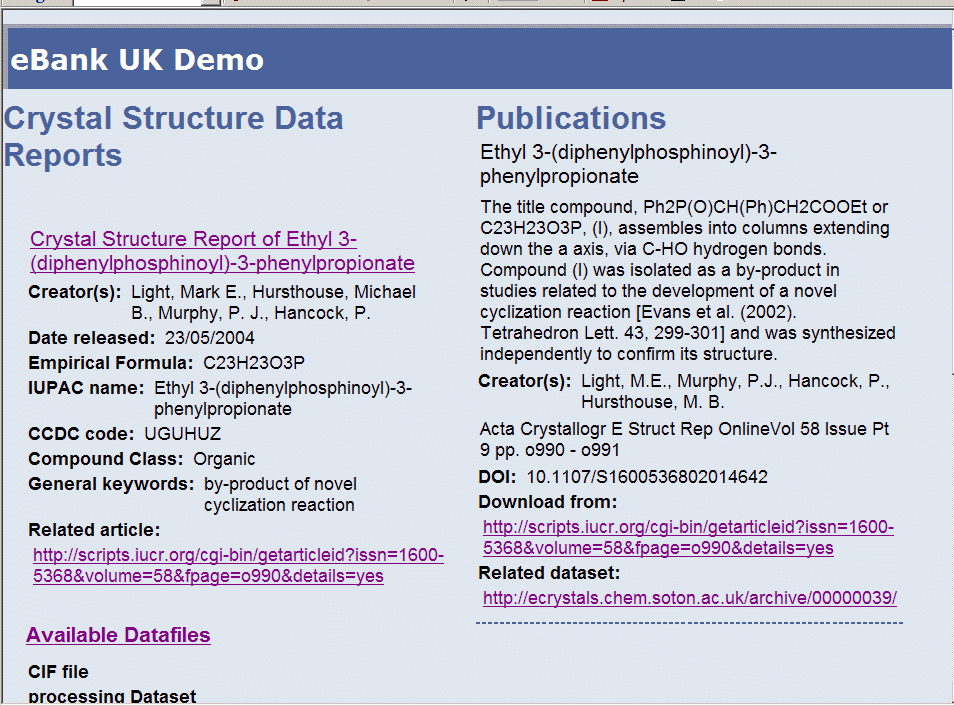
In discussion with the users, it was decided that a concise description the data would suffice to inform the user whether the data set uncovered is likely to meet the user's information need; for the full details of the experimental parameters and to access all the individual data files related to a crystal structure experiment, the user would be referred to the edata archive. This is achieved by encoding a link to the edata archive web page for the data set report. The dataset metadata contains the locations of the report encoded as URLs which are used to create the links back to the archive. Therefore the aggregator search results only show a subset of the metadata held by the edata repository. The concise description of the datasets displayed in the search results consists of:
The results screen can be seen in the following picture:
The CSS standard operates on the principle of separating the specifics of display from the internal structure of the document. The stylesheet defines visual characteristics such as fonts and when applied to the content determines how the content is presented. This separation of concerns in the design offers the flexibility of applying different displays to the same content, thus the look and feel of the content can be modified simply by re-defining the display characteristics. Cross-browser compatibility is also supported since browser-responsive options can be defined in CSS. CSS can also be accessibility-friendly, for example if fixed-width fonts are avoided, the zooming controls on web browsers can be used to alter the magnification of the display, making it bigger, say, for someone with a visual impairment. Alternatively the user could chose to apply a preferred colour scheme, (expressed in a user-defined stylesheet), and overide the scheme of the default display which may not fit with the user's preferred options. Separating the content from the formatting definitions has advantages not only in the preparation and tailoring of visual displays in web browsers, but indeed extends to other uses such as displaying content in different devices, like PDAs.
The full flexibility of CSS has not been exploited in this phase of eBank search service development, however the use of stylesheets makes the above options available in future develpoment.
One of the aims of the eBank UK project was to demonstrate how the search interface could be embedded into external frameworks. This would allow the service to be presented to established user bases of existing services, since the users would not have to be attracted to try out a new service, but would find the service readily integrated into a web site that was already being used.
The technical options available for embedding range from the tried and tested CGI mechanisms to newer more standardised protocols such as SRW and WSRP. The CGI-Include route is the longest-established method employed within the Resource Discovery Network. It offers the advantages of requiring least development effort on behalf of the consumer, no new technologies to be employed over and above the CGI mechanisms which are already likely to be in use to deliver web pages and searches.
The CGI method was used to demonstrate the embedding of eBank UK search into the PSIgate subject gateway. Due to time constraints, the SRW and WSRP interfaces have not been demonstrated in this phase of the eBank UK poilot service.
SRW is the Search and Retrieve Web Service, the successor of Z39.50 which takes the information retrieval standard into the web services model of interaction. For services developed using Cheshire, it would be simple to extend the interface to include SRW support, using a package made available by the Cheshire developers. The Resource Discovery Network has deployed an SRW interface to its catalogue; by using SRW, the eBank UK searches would be consumed by an SRW-aware application, that can send requests according to the SRW protocol. Results would be returned to the application as XML Records; the XML could then be reformatted (for example into HTML) at the consumer end to fit into the requirements of the consumer application and interface. This option is likely to be attractive to applications that are familiar with the Z39.50 protocol and the web services model, (or those with existing implementations of SRW) since the learning curve would be minimal. Additionally the results can be formatted flexibly to requirements by transforming the XML.
WSRP is the Web Service for Remote Portlets in version 1.0 specification (an OASIS approved standard). It is intended to make content from conent services available to aggregating intermediaries such as portals. The approach is that of 'write once, deploy many times' such that without further development effort the content can be re-displayed into end-user pages. WSRP is presentation-oriented and suitable for interactive web applications. Within a portal framework that is capable of consuming WSRP applications, re-implementation of the presentation layer is avoided.
To deploy eBank UK as a WSRP application it would be necessary to (1) develop an eBank UK interface that re-casts the code into a web-services model and (2) test its deployment within a portal infrastructure. Both vendor and open source implementations of WSRP are available as development platforms. Consuming the eBank UK search service as a WSRP application is likely to be most viable for any institutions or services that are already deploying portal frameworks and running portal application servers (such as uPortal).
PSIgate is the RDN subject gateway for the physical sciences and draws academic users from astronomy, chemistry, earth sciences, materials sciences, physics, and science history and policy communities. It is a free service that offers access to high quality Web resources in the physical sciences, and has an established community of web users in those areas.
The intention is to present the eBank UK search facilities through the PSIgate web interface in an integrated way, so that the eBank UK search fits in with the look and feel that PSIgate users recognise. The PSIgate eBank UK search interface was produced by slightly modifying the CGI scripts used for the eBank UK main service. Since the display look and feel of the interface is controlled by CSS, an alternative stylesheet was designed by the PSIgate developer. The modifed CGI script linked to the PSIgate-adapted stylesheet, and by making http requests to the CGI, calls from PSIgate to the script returned HTML with an instruction to present the results according to the PSIgate stylesheet. The stylesheet adaptations delivered the PSIgate look and feel, and the following screen shot shows the search interface at PSIgate with the PSIgate-defined styles applied.
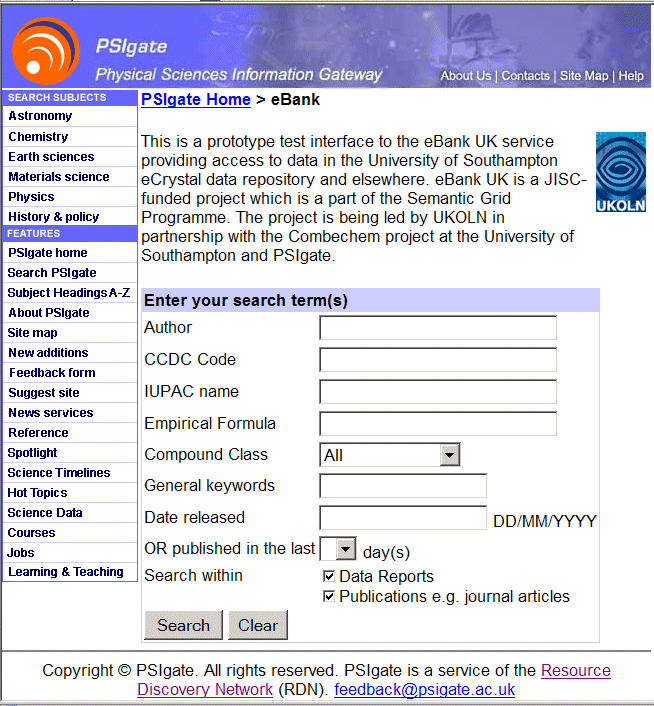
As can be seen from the screen shot, the embedded service presents the same search fields and supports the same functionality as the eBank UK web interface. However it uses modified stylesheets to tailor the look and feel of the interface to the PSIgate style.
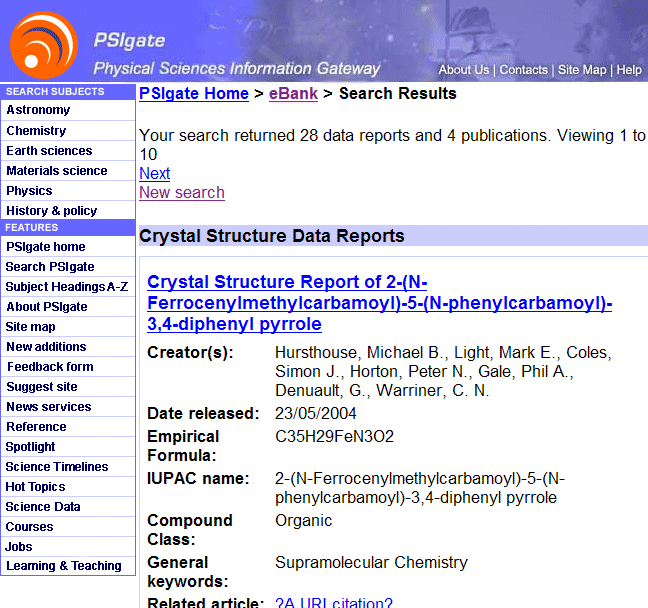
Search results can also be presented with the PSIgate styles, using the same stylesheet technique (above).
The eBank UK Project Website
Liz Lyon, Rachel Heery, Monica Duke, Simon Coles, Jeremey Frey, Michael Hursthouse, Leslie Carr and Christopher Gutteridge
eBank UK: linking research data, scholarly communication and learning
AHM 2004, eScience All Hands Meeting, Nottingham UK, 31 August-3 September 2004.
Paper and powerpoint presentation available from the University of Southampton e-Prints Service: [entry in
repository]
Rachel Heery, Monica Duke, Michael Day, Liz Lyon, Simon Coles, Jeremy Frey, Michael Hursthouse, Leslie Carr and Christopher Gutteridge.
Integrating research data into the publication workflow: eBank experience
PV-2004, Ensuring the Long-Term Preser
vation and Adding Value to the Scientific and Technical Data, European Space Agency, Frascati, Italy, 5-7 October 2004.
Paper: [PDF]
The SRW home page
Ariadne article
The WSRP Specification
Introductory article on WSRP
|
UKOLN, University of Bath http://www.ukoln.ac.uk / Intelligence, Agents, Multimedia Group, School of Electronics and Computer
Science, University of Southampton School of Chemistry, University of Southampton PSIGate, University of Manchester |

|
![]()
Web page content by Monica Duke of UKOLN
Page last revised on:
24-Aug-2004
Email comments to m.duke@ukoln.ac.uk