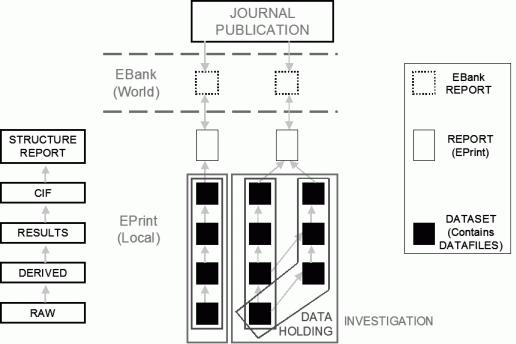
Figure 1. Generalised workflow for crystallography experiments
The eBank UK project has produced a prototype demonstrator of a service based on EPrints.org software providing access to the detailed results of scientific experiments in crystallography. To present this complex data in a retrievable and meaningful way requires that it is described by metadata using appropriate metadata schema that support harvesting and re-use by other services through alternative interfaces. The challenge faced by the project is the complexity and volume of data that are to be made accessible from the principal points in the network dissemination chain - institutional archives, aggregators, service providers, portals, and prospectively other data providers such as publishers and digital libraries. The design of the metadata schema is critical to the success of the demonstrator, and is perhaps the key contribution of the first phase of the project (to September 2004). The report describes the metadata schema adopted during the initial phase of the project, and shows how the metadata records based on these schemas are presented in the demonstrators. The advantages and limitations of the approach are briefly evaluated with a view to appropriateness of the schema for the presentation of experimental data from other science disciplines through other service providers, which will be investigated during phase 2 of the project.A journal publication describing the results of scientific work is typically a distillation of experimental data. The publication is aimed at a wider audience than the immediate peers of the authors, so placing the work in its primary context and reducing the data to the most significant results is critical in making the work more widely known. Those immediate peers, however, may require access to more of the original data produced in the work, to verify reproducibility or to build on those data, for example.
Modern science can produce large volumes of data as computational tools enable experiments to be performed more frequently and more efficiently. In crystallography in the 1960s a PhD student might have investigated three or so structures. Now this number can be analysed in a single morning, yet the publishing protocols for reporting this work are essentially unchanged.
As long as publication has been detached from the means of production and format of this data, managing and providing access to full experimental data has not been simple. Although some journals have attempted to store data relating to published articles, typically this data is only a partial set of the complete dataset, and many journals, especially those based on print formats, do not have the space for any such data. In crystallography just 300,000 crystal structures are documented in database archives, against an estimated 1.5 million known structures: less than 20% of data generated in crystallographic work is reaching the public domain due to publication bottlenecks. Furthermore, there are in excess of 24 million chemical compounds known. As high-throughput technologies, automation and e-science become embedded in chemical and crystallographic working routines, the publication bottleneck issue can only become more severe.
A potential solution is offered by the emergence of electronic networks. Experimental data are produced electronically, so are immediately amenable to network distribution. What needs to be done is to describe the data, preferably by automatically produced metadata, so that the data can be discovered and made available to both machine and human readers. While the Internet and the World Wide Web offer standard protocols for distribution of documents, now being supplemented for the type of scientific data sources described here by e-science and grid technologies, particular domains require specialised metadata and means of discovery. Dublin Core (DC) is a metadata standard that has emerged to provide the 'core', or essential, elements to describe a variety of resources, say of an item that might be found in an academic library. A mechanism designed to improve distribution of such records is the Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH). If the library is considered to be the example data provider, the OAI-PMH allows independent data services to 'harvest' the DC records into a database and enable these records to be searched alongside records from other selected data providers. Cross-searching techniques generally send specific search requests in parallel to different sources (by some specified protocol) and combine the various responses into a result for the cross-search. In contrast, search services built on harvested metadata carry out local searches on the pre-harvested metadata. DC and OAI provide a minimum level of interoperability between data providers and diverse service providers.
Basic DC does not include specialised domain specific terms, but can be extended by means of 'qualified' DC. In this case a schema is devised to describe the extended terms. An XML schema can be drawn up as a template for records using the extended term set, thus facilitating m2m use of records conforming to the extended set. An RDF schema describing the extended term set would enable machine interpretation of property and sub-property relationships, and such a schema also allows tools to relay the semantics of terms to human readers.
Based on an analysis of user requirements the project found that crystallography datasets might be usefully described using a number of properties in addition to 'simple Dublin Core'. Experiments revolve around a single molecule which can be thought of as the topic of the experiments. There are a number of established ways of identifying molecules, which include internationally recognised methods of specifying their formulas or names. In chemistry a very important identifier used for exchange of chemical information is the IUPAC-NIST Chemical Identifier (INChI). An INChI encodes a lot of chemistry that cannot be expressed easily by any other means. These different vocabularies have been incorporated into the schema through the encoding schemes facility of qualified DC.
This report describes the schema implemented by the eBank UK project to export metadatadescribing crystallographic datasets. The design of the metadata schema is based on the characteristics of the experimental data it describes, and the services that will be supported by using the metadata. In the eBank project the actual and prospective service partners include:
Figure 1. Generalised workflow for crystallography experiments
datasets do not need to be stored at a single location such as the Eprints archive at NCS. By using OAI-based DC, interoperability conditions mean that datasets stored at different locations can be accessed by users as though they were from a single 'virtual' archive depending on the OAI service provider used.
| Name | Description of the stage | Files associated with this stage | Metadata associated with this stage | |||
| File | Type | Description | Name | Data Type | ||
| Initialisation | Mount new sample on diffractometer
Parameterisation to set up data collection |
*.htm
i*.kcd *_sample.jpg |
HTML
BINARY JPG |
Metadata for crystallography
expt
Unit cell determination images Image of sample |
Morphology
Solvent Sample_image |
*STRING (SET)
*STRING .JPG |
| Collection | Collect data | s*.kcd
*_crystal.jpg |
BINARY
JPG |
Diffraction images
Image of crystal |
Temperature
Crystal_image |
*INTEGER
.JPG |
| Processing | Process and correct images | .hkl
.htm *_0KL.jpg *_H0L.jpg *_HK0.jpg |
ASCII
HTML JPG JPG JPG |
Derived dataset
Report file Synthesised image compiled from .kcds Synthesised image compiled from .kcds Synthesised image compiled from .kcds |
Cell_a
Cell_b Cell_c Cell_alpha Cell_beta Cell_gamma Crystal_system Completeness |
*NUMBER
*NUMBER *NUMBER *NUMBER *NUMBER *NUMBER *STRING (SET) *INTEGER (%) |
| Solution | Solve structure | .prp
xs.lst |
ASCII
ASCII |
Log of symmetry determination process
Solution log file |
Space_group
Figure_of_merit |
*STRING (SET)
*NUMBER |
| Refinement | Refine structure | xl.lst
.res |
ASCII
ASCII |
Final refinement listing
Output coordinates |
R1_obs
wR2_obs R1_all wR2_all |
*NUMBER
*NUMBER *NUMBER *NUMBER |
| CIF | Produce CIF | .cif
*_checkcif.htm *.cml |
ASCII
HTML CML |
Final results
Automatic validation results Final results (with chemical content) |
Formula_moiety | *STRING |
| Report | Generate e-Data report | .html | HTML | Publication format (HTML/XHTML) | eDataReport_type
Authors Affiliations Formula_empirical Compound_name CCDC_Code Compound_class Keywords Available_data Related_publications |
*CRYSTAL STRUCTURE
*STRING *STRING *STRING *STRING *STRING *STRING (SET) *STRING (SET) *STRING (SET) STRING |

Figure 2. eCrystallographyDataReport shown to a user (partial view) via the adapted Eprints.org archive interface (Note. The crystal diagram is presented using a Java applet and can be manipulated interactively)
Only the metadata need to be harvested, rather than the full datasets, as the
reports link to the constituent data files in the original archive. For this
purpose the e-data report is represented by a DC schema designed for dissemination
via an OAI interface. Table 2 shows the schema elements presented to
the OAI interface for the exchange of eBank data between data provider and service
provider. Explanations of the elements and how they map to user requirements
are given in the Appendix (part 1).
| Data Name | Data Description | Data Type | XML wrapped content |
|---|---|---|---|
| EPrint_type | 'Crystal Structure' | String | Phrase 'Crystal Structure' |
| Authors | ePrint creator(s) | String | ePrint authors 'Surname, Christian name, initial' |
| Affiliations | Institution(s) of creator(s) | String | Various authors addresses |
| Formula_empirical | Total atom count | String | Atom symbols with their total count (can be real number) subscript |
| Compound_name | IUPAC Chemical name | String | Chemical name with text & integers |
| CCDC_Code | Cambridge Structural Database identifier | String | 6 character code (may become numeric in future) |
| Compound_class | Chemical category | String (set) | 1 word descriptor of chemical category |
| Available_data | Actual data available for various ePrint stages (Y/N) | Y/N Toggle | Y or N presence of data associated with RAW & RESULTS stages |
| Related_publications | Other output containing this compound/structure | String | Literature reference link |
| Publication_date | Date of releasing ePrint to eBank/world | String | Date of public release of ePrint |
| Last_revised_date | Date ePrint last revised | String | Date of latest modification to ePrint |
| Keywords | Categories | String (set?) | Phrase describing chemical relevance |
| Scheme | 2D diagram | String | Two dimensional structural diagram as SMILES string |
| IChI | International Chemical Identifier | String | Unique compound identifier (contains some structural information) |
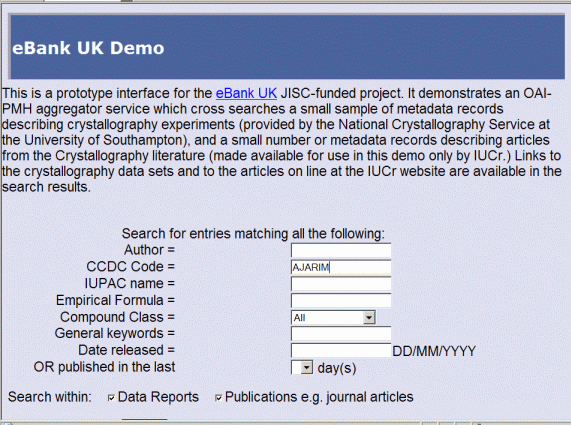
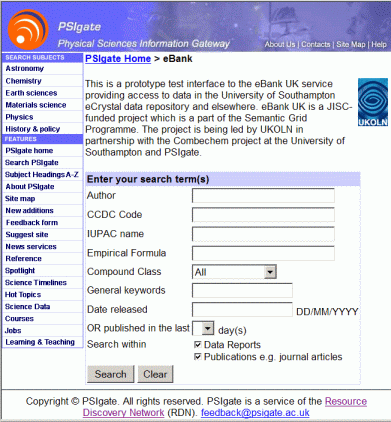
The search interface presented by the eBank UK demo is shown in Figure
3a. A similar search interface offered by PSIgate is shown in Figure
3b. The PSIgate search uses an RDN-include type mechanism: search requests
run scripts on the eBank UK server. Although a stylesheet is used to reformat
the data, the portal has no control over what data are passed across. Service
providers can re-present records, such as the one shown in Figure 2, ideally
supplemented with additional information such as links to other relevant
sources, such as published papers and library holdings, or other information
on which the provider holds data.
a |
b |
E-data reports are represented as records in an XML format, defined and constrained by the adopted schema. An eCrystallographyDataReport might not be commonly encountered by a digital library OAI harvester, which would need to refer to the eBank schema to understand its contents. An eBank record conforms to the schema described above, although additional 'layers' might be added to provide richer metadata for other service providers. For example, while the current eBank data might be harvested by specialist crystallography services, more general providers of digital library services might require additional information to be able to handle such data.
With increasingly complex digital objects becoming available for harvesting, such as objects with multiple components and multiple metadata components, 'containers' are needed to transport not just the core data but the additional components too. The Metadata Encoding and Transmission Standard (METS) is such a container and provides an XML document format for encoding metadata necessary for both management of digital library objects within a repository and exchange of such objects between repositories. METS recognises that describing digital objects requires an increasingly complex series of metadata descriptions - administrative, structural and technical metadata, for example. Other proposed 'containers' for describing complex objects include MPEG21 Digital Item Declaration Language (DIDL) and content packaging standards from elearning organisations such as the IMS Global Learning Consortium.
A schematic view of metadata exchanged in eBank UK project using OAI-PMH with METS wrapper elements is shown in Figure 4. An example eBank record that includes a METS layer is shown in the Appendix (part 3).

Figure 4. Schematic view of metadata exchanged in eBank project using OAI-PMH
This record contains declarations linking to the eBank XML schema definitions (.xsd). Two .xsd documents have been created for the eBank demo, defining
The eBank project was originally funded by JISC for one year from September 2003. In that time eBank has demonstrated how new infrastructure can be built on existing and emerging services to integrate and disseminate new sources of data, in this case research data generated by solving crystallography structures. Although within the design process some consideration has been given to wider applicability, the project acknowledges that the the current schema have been developed within a particular area of chemistry. The next phase of the project intends to explore whether the existing schema can be applied to other areas of chemistry and beyond. Creating a more generic scientific schema will depend on gaining consensus on a generic scientific data model. To reach such a consensus will require, as was the case with crystallography, an intimate understanding of the underlying experimental processes that are to be represented, and active involvement in the relevant science communities.
Within the limited confines of the eBank infrastructure, it has been shown that data from experiments can be produced and structured for effective dissemination from the data producer to a local archive for storage and then on to aggregator and discovery services. The project has provided a demonstratior of a search interface based on harvested metadata which can in future be used for evaluating against user requirements.
The principal strengths of the current eBank approach, as revealed by its application of a dataset description and schema, and future requirements, are listed below.
Strengths
Future work is required in a number of areas.
Future workFuture plans include working closely with IUCr and CCDC to integrate the eBank approach into chemistry-related publications so this is the globally accepted route for publishing crystal structures. Initial discussions with chemistry publishers such as the American Chemical Society (ACS) and Taylor and Francis, a learned society and commercial publisher respectively, indicate that the eBank open access OAI-based approach to accessing crystal structures is one solution to the current publication bottleneck problem.
eBank is not just about chemistry, or even crystallography, although these disciplines provide a very good exemplar. It is about how to structure e-data reports and how to use this structure to make these data accessible from the principal points in the network dissemination chain - institutional archives, aggregators, service providers, portals and, prospectively, other data providers such as CCDC, publishers and digital libraries.
This document defines the schema for the exchange of eBank data between data provider and service provider in the eBank UK project, with explanations for the elements and mapping to user requirements.
At the time of writing this report had reached Version 3 (modified 21st
September 2004)
Download the (Word) document from: http://www.ukoln.ac.uk/projects/ebank-uk/schemas/ebank-schema.doc