|
|
|
NOF-digitise Technical Advisory Service |
IntroductionThis Information paper outlines the Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH) and outlines the ways in which it might be used to enable users to search to find materials from across the huge range of projects in the NOF-digitise Programme. The Open Archives Initiative was developed in 1999, to enable scholars to create an 'open archive' of their own reports and publications, usually in the stage before they were published formally in print. This archive could then be searched by other scholars, enabling an open archive of publications from a large number of scholars and academic researchers to be generated. The aim was that this should be possible without the use of expensive software, using open standards and metadata. This basic concept has now been implemented by a wide range of projects, and has been used to enable the cross-searching different materials far beyond the initial idea of scholarly and research publications. OAI is most commonly applied to enable users to cross-search databases (or repositories) of metadata, and to find records that match the search request in one or more of those databases. OAI and the NOF-digitise ProgrammeIn the context of the NOF-digitise Programme, OAI-PMH could be used at item-level, to enable users to search across a number of projects in order to find materials that were of interest to them. As an example, a user might be interested in anything that refers to the town of Chipping Norton. It is unlikely that any of the Collections Level records for projects and learning resources would include this term. However, there are likely to be items of interest in NOF-digitise projects such as the British Pathe newsreels, the Taunt Collection digitised by English Heritage and the Great British Historical Atlas. The user would have to find out that these projects existed, and then visit each in turn in order to see if there was information that was relevant. Few users would invest the time needed to navigate through many different websites, and would give up in frustration. Internet search engines, such as Google or Yahoo would be of little added help, as most of the items will be within databases, and therefore be hidden from them in the so-called 'dark web'. OAI works by allowing the automatic 'harvesting' or gathering of metadata into a new central database. This database can then be searched and users presented with a very brief record description and a link to the website from which the record came. By following the link, the user finds the record, displayed on the page that has been developed by the project, complete with any images, links to additional materials, and learning resources that will encourage the user to explore the site, and to find out what else in the site will be of interest. The OAI database is therefore a 'search engine' and presents an interface to user that is very similar to conventional search engines. However, unlike conventional search engines, NOF projects would have some control over the text that would be seen by users, and it may also be possible to display a small project or organisational logo alongside the text record. In order to create this service, a number of components are needed. Projects need to make their metadata available to be 'harvested' into a central database. The harvesting would normally take place through one of two mechanisms:-
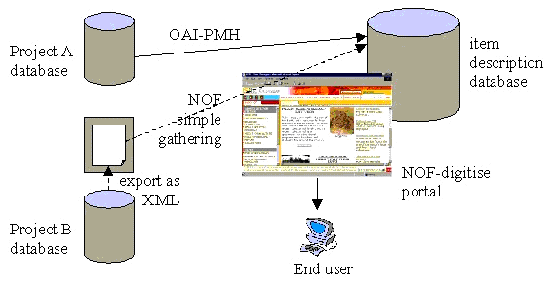
The OAI Protocol for Metadata Harvesting says nothing about the structure of the metadata records that are to be harvested - and most implementations use unqualified Dublin Core. However, in order to meet some of the basic requirements of cross-searching of cultural materials, Qualified Dublin Core may be used. Resource and the 24 Hour Museum (http://www.24hourmuseum.org.uk) are piloting an OAI service, using Qualified Dublin Core, that will search across a number of museum databases. This will allow users to search using the 'Who, What, Where, When' approach implemented by SCRAN (http://www.scran.ac.uk). The use of OAI is becoming more common, and forms an important part of the approach being developed by the JISC for the Information Environment for the Higher and Further education sectors. This means that projects could choose to allow their metadata also to be harvested by JISC services, and therefore encourage the use of their materials by students, researchers and teaching staff in Higher and Further education. A similar approach has also been implemented by Picture Australia (http://www.pictureaustralia.org), which brings together images of Australia from a wide range of sources, including SCRAN. One Australian partner has found. to its great surprise, that, despite having a well-known website and URL, the number of hits on its website has increased by 25% as a direct result of allowing its metadata to be used by Picture Australia. For more information about the Open Archives Initiative see:-
David Dawson
|
AcknowledgementsThis paper was written by David Dawson for the New Opportunities Fund in association with the People's Network and is one of a series of Information Papers that will be produced by the NOF Technical Advisory Service. Queries about the Information Papers should be addressed to:
Richard Waller UKOLN is funded by Resource: The Council for Museums, Archives & Libraries, the Joint Information Systems Committee (JISC) of the Higher and Further Education Funding Councils, as well as by project funding from the JISC and the European Union. UKOLN also receives support from the University of Bath where it is based. |