|
|
|
nof-digitise Technical Advisory Service |
About this information sheetThis paper explains how the use of XML might contribute to your ability to share information about the valuable resources that your project is developing. Although its coverage is of necessity general, it may help you to evaluate some of the comments made by vendors and developers in this area. The first part of the paper contains a very brief overview of the subject of metadata, with particular emphasis on metadata for resource discovery. The purpose of this section is not to make detailed recommendations about what metadata you may require to describe your resources, but rather to try to highlight some of the ways metadata is used, and how those uses create particular requirements for its exchange. The main part of the paper explains what XML is. It provides some background to the development of the XML specification, a brief overview of some features of XML, and some examples of how XML is used. It includes a simplified summary of XML syntax, but does not provide a detailed treatment of this area, as such information is widely available elsewhere. The main aim is to highlight exactly how XML supports the effective sharing of information in different contexts. Finally, we examine how well XML meets the requirements for the exchange of metadata. This part of the paper seeks to draw out some of the limitations of XML and to explain some related specifications and technologies that seek to address those limitations. By way of conclusion, the paper offers a short set of questions that your project may wish to consider. These questions represent an attempt to move the discussion from the general issues covered in the body of the paper to their relevance in the particular context of NOF-digitise projects, though the breadth of the subject area means that they remain fairly general. This paper does not make specific recommendations for the use of particular XML-based markup languages or metadata schemas within NOF-digitise projects: the potential range of uses are simply too wide to address in a general paper. The paper concentrates on the structural and syntactic aspects of sharing metadata, rather than the specific semantics of that metadata. Note: In the context of this paper the expression "metadata sharing" that is used in the title is employed in a general sense to refer to the "disclosure" or "publishing" of resource descriptions. It is not intended to carry the more specific sense of the re-use of existing metadata records under some form of "collaborative cataloguing" model. ContentsAbstract
1. What is metadata?Metadata is structured information about resources (including both digital and non-digital resources) that can be used to help support a wide range of operations. The activity most often considered in discussions of metadata is that of resource discovery - locating resources of interest by using the descriptions of resources which have been disclosed (published) by their creators, distributors or custodians (or indeed by third parties). The content of resource discovery metadata should allow a user to evaluate the relevance of a resource, and metadata may also provide information on the mechanisms required to access resources once they have been selected and located. Metadata may also help a user interpret the content of a resource. However, metadata may also support many other activities related to the management of resources by their custodians, including the administration of rights associated with the resource and issues related to its preservation [l]. Metadata is created within a specific context and for specific purposes. It is hardly surprising, then, that different purposes and different contexts have different metadata requirements. The following definitions of metadata highlight a number of issues: Metadata is machine understandable information about web resources or other things [2]. Metadata is data associated with objects which relieves their potential users of having to have full advance knowledge of their existence or characteristics. A user might be a program or a person [3]. Both these definitions emphasise that metadata is to be used by programs as well as by human readers. Berners-Lee takes a broad view of the range of "resources" that metadata might describe. He envisages metadata used to describe not only the objects we might think of as "Web resources" (HTML pages, images, databases etc) and physical resources (books, manuscripts, artefacts), but also people and places and even "abstract" resources like concepts and events. Dempsey and Heery's definition suggests that a metadata record is a surrogate for - "stands in" for - the resource itself, albeit in some specific, limited ways. A user can access metadata about a resource quite separately from the resource itself, and some user requirements may be met through reference to the metadata alone with no need to access the resource it describes. 1.1 How metadata is usedIt proves almost impossible to sustain a clear distinction between "data" and "metadata". A pragmatic approach suggests that information is metadata when it is used as metadata! However, by examining some of the functions that metadata is created to support, it is possible to suggest some features of metadata use that condition its content and the form in which it is made available. For example, taking the case of resource disclosure and discovery, we can suggest some actions that various agents may wish to perform. This list is not intended to be exhaustive. Typically the users (or potential users) of resources wish:
Resource providers wish:
In addition, third parties may wish
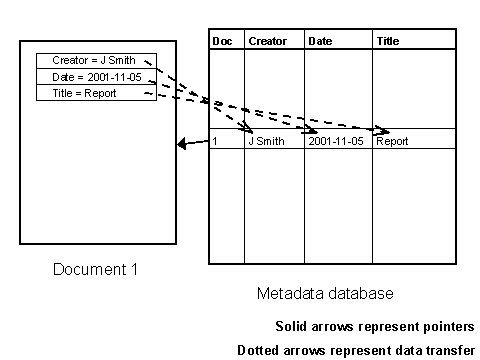
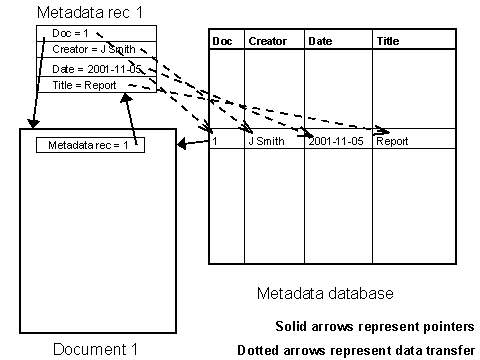
1.2 Metadata and aggregationTo support these functions, the (possibly diverse and distributed) descriptions of individual resources (or at least some data extracted from those descriptions) must be brought together - aggregated - with metadata about other resources by a service which then makes that aggregated data accessible to users through some form of search interface. The scope of such a service may vary: it may be within a single project, across a cluster of projects, across the whole of a funding initiative like the NOF-digitise programme, or within the scope of a subject area or a geographical domain. Indeed a resource provider may make metadata available on the basis that it can be used by any service which locates it. This is typically the approach underlying the creation of simple metadata embedded in the headers of HTML documents on the Web: the resource provider expects that it will be indexed by the "spiders" of search engine services but does not make specific agreements with those services. Of course, those different services process such metadata in different ways and it is sometimes difficult to predict how (if at all) the presence of metadata affects the ranking of a resource in their retrieval services. The mechanism by which that aggregation takes place may vary: a resource provider may actively submit metadata records to the service (information "push"); or the service may "harvest" those metadata records from the resource provider (information "pull"). The Open Archives Initiative (OAI) metadata harvesting protocol represents a standardised approach to harvesting (based on the use of XML) so that metadata is made available to any service which seeks to use it [4]. In a "closed" context, the harvesting may take place according to system-specific procedures: indeed the use of the OAI protocol presumes that some level of aggregation will be performed internally by the resource provider before it is made accessible to external services through OAI. The indexing of metadata records in situ for the purposes of enabling a central service to "cross-search" that distributed resource might be regarded as a distinct option. However, the objective in this case is usually to present to the end user a view of that distributed dataset as a unified whole. The records may not be copied to a single central database, but the results of a query are presented to the user as if that is the case - with many of the same challenges. While the mechanism chosen may impose some constraints on the form and content of the metadata records, the key point is that metadata is created by resource providers with the expectation that it will be aggregated in some way by a service. As a prerequisite, it must be available in a form which that service can locate, access and use. This has implications for the form in which metadata is created. Some file formats and resource creation tools provide some means of embedding metadata within the resource: the use of HTML <meta> elements was noted above; the document summary information available within word processor tools like Microsoft Word is another example. However, that information has little value as metadata unless it can be extracted from the resource and made available to an aggregation service, and for proprietary file formats that may be a complex task. An alternative to embedding metadata within a resource is to create it as a separate but related resource: that may be a separate file or a record in a database. The resource may contain a pointer to the metadata (for example an HTML <link> element) and the metadata will almost certainly contain a pointer to the resource. In short then, metadata for resource discovery may be created in diverse forms and made available to a range of parties using many different mechanisms. However, we can say with some certainty that metadata is created with the intention that it will be
These two factors create requirements for the effective sharing of information which go beyond the requirements for information exchange within a community. 2. What is XML?The Extensible Markup Language (XML) is a recommendation of the World Wide Web Consortium (W3C), a member organisation that develops technical specifications for the infrastructure of the Web [5]. The XML 1.0 specification defines a means of describing structured data in a text-based format. Within a short period of time (the XML specification was published in 1998), XML-based formats have been employed widely for storing data and especially for exchanging data between programs, applications and systems. Within NOF-digitise projects, it may be appropriate to use XML for either or both of these functions. The main emphasis in this paper is on how XML can be used to share information about your resources. And while there may be many reasons for sharing such resource descriptions one will be the fundamental requirement for you to disclose information about the existence of your resources in a form which enables potential users to discover them. It is worth considering briefly some of the reasons for the widespread success of XML. The specification emerged at a time when there was a clear demand to address precisely this problem of how to share effectively data created on one system with a recipient working on a remote system with quite different characteristics. Such data exchange did, of course, take place before the advent of XML, but it often represented a complex and costly part of application development.
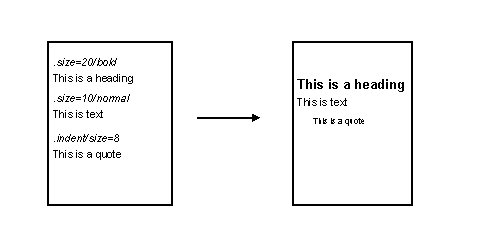
So, the owner or manager of the information can have confidence that the data they create can be read on a remote system (or indeed on their own system after a change of software). And the software developer is freed from at least some of the work in having to read or write many different (and rapidly changing) file formats. Many major commercial vendors have an interest in facilitating such data exchange, and several of the largest contributed to the development of the XML specification and have subsequently invested heavily in software initiatives that build on XML. A note of caution is necessary, however: XML is not a "silver bullet" solution to all the difficulties involved in the effective exchange and reuse of information. Indeed, claims that an application or system "uses XML" provide little basis on which to judge how well it meets those challenges. This paper recognises the valuable role that XML plays, but also emphasises that XML addresses only one facet of the problem. 3. Markup & markup languages : from documents to dataMarkup is text that is added to the data content of a resource in order to convey information about that content [6]. The notion of markup pre-dates the use of automated information systems: the annotations that provided instructions about layout to typesetters were an example of markup. A "marked-up" document contains both data and markup. A markup language is a set of conventions for providing markup so that the reader can interpret accurately the intentions of its creator. At a minimum, the rules of a markup language must specify:
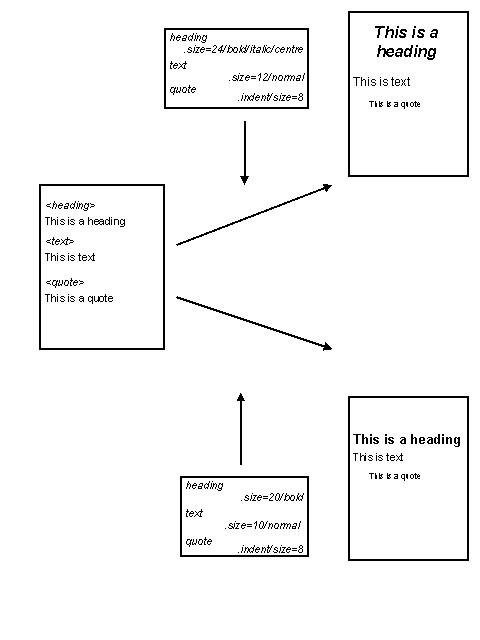
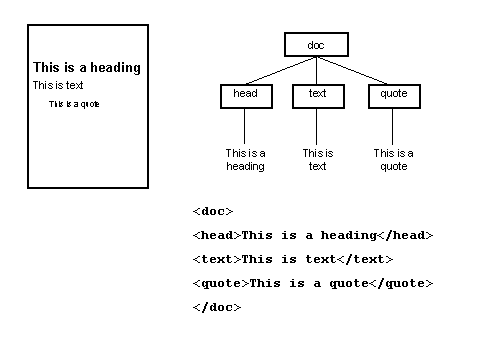
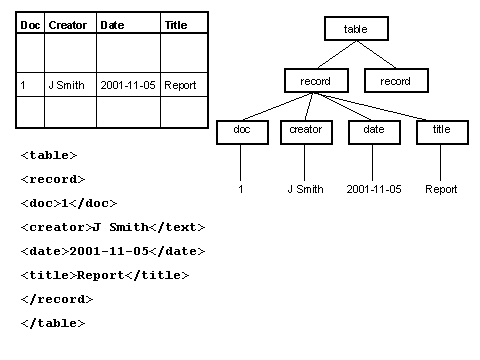
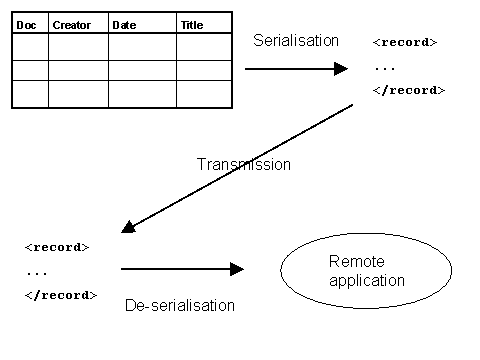
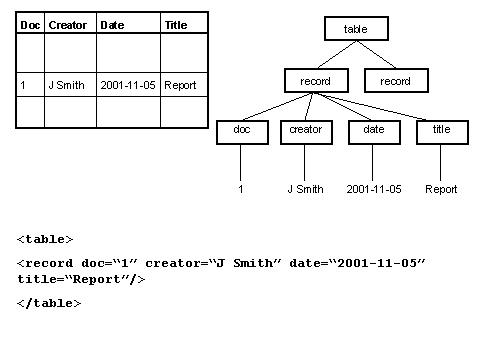
3.1 SGML & XMLThe Standard Generalized Markup Language (SGML) is the precursor of XML. It is an ISO standard (ISO 8879:1986), which, like XML, defines a means of describing structured data in text format, using markup embedded in the data. The description of SGML and XML as "markup languages" is slightly misleading, as neither the SGML standard nor the XML specification meets all the criteria listed above for a markup language. SGML and XML are sometimes described instead as "meta-languages". They both provide a general syntax for markup (i.e. they address the first of the three requirements above, and some parts of the second element), and they also provide a set of rules for defining an unlimited number of specific markup languages. So when someone says they are "using XML", what they usually mean is that they are using one or more of these specific markup languages in accordance with the general XML syntax rules. The difference between SGML and XML is that the former provides a great deal more flexibility. That flexibility makes it a powerful tool, but the cost is one of complexity both in terms of the standard itself and the software required to implement it. XML is a subset of SGML that sacrifices some of that flexibility in return for the benefits that it is easier to use, with all the advantages mentioned in the previous section. 3.2 A document perspectiveSGML evolved from the 1960s to the 1980s. It was designed primarily to meet the requirements of large scale document publishing systems, and some of its features are a reflection of the characteristics and constraints of automated processing systems at that time. Nevertheless, most of SGML's fundamental approach has been inherited by XML. The premise underlying the "document-oriented" approach to markup is that all documents have structure, that is, they are made up of component parts and those parts have relationships with each other. The most visible facet of a document's structure (at least in the domain of printed documents) is that it has a physical structure: a document may consist of a number of pages, for example. Physical structure is contingent: the same document may be rendered with a different physical structure (e.g. printing more words per page will reduce the number of pages, or using a continuous scrollable screen display abandons the concept of the page completely). However, a document has a logical structure that is independent of its physical rendition. Typically that logical structure is communicated to the reader through the use of presentational conventions - a heading is formatted "bigger and bolder" than the text of a section - and indeed when such formatting is removed, the reader is confused precisely because they lose the cues required to interpret logical structure. Within automated systems, presentation is defined by using markup that instructs a program how to render text. The problem faced by the publishing industry was that such formatting instructions are usually specific to individual programs, and furthermore the presentational requirements may be different for different output media. So embedding presentational markup in a document ties the document to a particular rendering program and limits the ability to re-publish in different formats. The solution proposed by SGML is to use markup to identify the logical components of a document and to apply the formatting as a separate process. This use of markup is referred to as "descriptive markup": the author identifies "headings", "quotations" or "captions" without saying anything about font weight or size or indentation. This means that the source document is no longer tied through presentational markup to a particular rendering process, and that it can be re-published in multiple formats and multiple media through the application of different formatting processes. The HyperText Markup Language, HTML, was conceived as a descriptive markup language: it provides (a fixed set of) markup for identifying a very simple set of structural components of a document (headings, divisions, lists, paragraphs etc) [7]. However, HTML also includes markup which is explicitly presentational (describing alignment, font size etc). Furthermore, the use of HTML has become inextricably associated with the formatting behaviour of a very few "user agents" (programs which render HTML documents), namely the small number of Web browsers which dominate the market. As a result, many authors have deployed HTML markup so as to achieve presentational effects using those formatting programs without considering the structures which that markup is describing - so for example, list structures are used simply to achieve indentation, headings for emphasis, and so on. The problems of the approach are highlighted when such HTML documents are "rendered" using other agents such as audio browsers, which depend on a coherent description of document structure. The W3C's promotion of the use of Cascading Style Sheets (CSS), and the associated "deprecation" of the presentational features of HTML, represent an effort to re-emphasise the descriptive aspects of HTML [8]. A further benefit of descriptive markup is that it makes the logical structure of a document available to other software applications that are not concerned with formatting. For example if occurrences of personal names in the text are explicitly identified, then an index of those names could be built. The success of all of these operations (both formatting and more complex manipulation) depends on the document creator and the agent processing that document sharing the same understanding of the markup language - in all three of the aspects identified at the start of section 3. From this point, the discussion will focus on XML. Many of the concepts are inherited from SGML, but because XML has attracted the interest of a different use group, there are often differences of emphasis and of terminology between the XML and SGML communities. And at the level of syntax, XML imposes its own layer of constraints. 3.3 XML syntax : elements and attributesIt is not the main purpose of this paper to provide a detailed study of the syntax of XML, but this section presents a very brief overview with an emphasis on those features most relevant to the discussion of information sharing below. The basic principles of XML syntax are very simple, and will be familiar to anyone who has used HTML - though it should be noted that there are some important differences and the syntactic rules of XML are less permissive than those to which many HTML authors are accustomed. Again, those differences are not discussed in detail here [9]. XML uses tags embedded in the content of a document to delimit and label parts of the document, and those parts are known as elements. Tags themselves begin and end with special characters (<....>) so that they can be distinguished from the data content, and element end tags can be distinguished from start tags by a special character combination (</...). The start and end tags include an element type name and may also contain attributes (see below). Elements may contain character data (only), other elements, a combination of character data and elements - or nothing (i.e. elements can be empty). Attributes are pairs of names and values that occur within the start tag of an element. An individual element can contain only one occurrence of each attribute, and attribute values can contain only character data. 3.4 Document types, DTDs, schemas and validationIn section 3.1, we noted that strictly speaking XML was not a markup language. Rather, the XML specification provides rules to define specific markup languages. It also provides a means of formally describing those specific markup languages in a standard, machine-readable form so that the description of the language can be shared. The purpose of markup is to describe the structure of a document. Further, individual documents can be classified by their type - we recognise classes of documents like memos, minutes, manuals, reports, timetables, and so on, and we do so on the basis that members of a class (or "instances") share a common structural model. Two different reports will contain a different number of sections and paragraphs, but they both conform to the same general model. Markup languages are created on precisely this basis: the designer identifies the common structural characteristics of a class of documents and constructs a markup language that can be applied to all the instances of that class. The XML specification describes how to encode this common structural model in the form of a Document Type Definition (DTD). A DTD lists all the element type names and attribute names that are available to label the component parts of an instance document. It also describes constraints on the use of these elements and attributes that must be followed if an instance document is to conform to the model. So for example, a DTD specifies the names of attributes associated with an element type, or that occurrences of an element type should contain only certain other element types, and that they occur in a certain sequence, and so on. For example, a DTD which described the structural model for a (much simplified!) "report" could specify that the document should contain a main heading, followed by the name of the author, and then one or more sections, each of which should have a heading followed by a number of paragraphs. A more recent specification from the W3C, XML Schema, specifies a second mechanism for capturing this class of information [10]. The XML Schema specification includes more powerful mechanisms for controlling element content than DTDs and also supports a more modular approach. Also, unlike DTDs, XML schemas are themselves encoded using XML syntax. This paper will not describe DTDs or XML Schemas in detail. The key point is that both describe the structural model of a class of XML documents and define and constrain the markup that can be used in instance documents that conform to that model. A model might be described either by a DTD or an XML Schema, though the latter permits more information to be expressed and is generally more flexible. For example, XML Schema allows a schema creator to specify that the content of an element should be a date or a URI. New XML applications, and particularly data-oriented applications (see section 3.5), tend to use XML Schemas in preference to DTDs. Data-oriented applications are more likely to make use of XML Schema's capacity to express tighter constraints and the fact that the model itself is expressed in XML and the schema can itself be processed as an XML document. Sometimes the literature on XML uses the term "schema" more generally to encompass both DTDs and XML Schemas. In terms of the requirements for the rules of a markup language listed at the start of section 3, a DTD or XML Schema provides the remaining parts of the second element - it describes what markup is allowed in an instance document. It defines both the "vocabulary" (the element type names and attribute names which may be used in an instance document) and the "structure" of the language (how elements and attributes may be related in an instance document). A DTD or XML Schema says nothing about what the markup means. It does not explain the semantics of the vocabulary (even if an XML Schema specifies that an element is of type "date", it can not express what sort of date that is) and it does not express the meaning conveyed by the structural relationships between component parts of the document. This point is explored further in section 4. However, since a description of the meaning of markup is an essential part of the description of a markup language, a DTD or XML Schema must be supported by additional documentation that provides this information to its human users. Such documentation consists at the very least of a "tag library" or "data dictionary" which lists the vocabulary of the markup language and describes its semantics; usually it includes more detailed guidelines on the use of that markup language. That documentation must support both the document creator applying markup to a document, and the recipient of a document who must interpret the markup of others. Because DTDs and XML Schemas are machine-readable documents, if an instance document is associated with a specified DTD or XML Schema, a program can validate the document against that DTD or schema i.e. check that the element types and attributes used in the instance are defined in the DTD/Schema and that they are used in the instance in accordance with the constraints expressed in the DTD/Schema. Validation checks that the structure of the instance conforms to the structural model of the document type. Many XML parsers incorporate the capacity to validate against a DTD or XML Schema, though it should be noted that in XML, such validation is optional: there is no requirement that an XML document conforms to a DTD or XML Schema. The only structural constraints which an XML document must follow are the rules of "well-formedness", which, for the purposes of this discussion at least, require that elements have start and end tags, and are correctly nested. This level of structural validation using a DTD or XML Schema performs only minimal checking of the textual content of XML elements or attributes. DTDs provide only very limited functionality in this area, and although XML Schemas extend this functionality, the validation provided at this level is rarely sufficient, particularly for "data-oriented" applications (see section 3.5), and there will usually be a requirement for some additional validation to be performed by application-specific software. The control of content is, then, a major consideration for the creator of an XML document. That control may be as loose as conforming to general rules for the style and coverage of the content an element or it may be as specific as the selection of terms from "controlled vocabularies" (classification schemes, thesauri, taxonomies etc). Such controls remain largely outside the domain of XML itself, and can not be enforced by general purpose XML tools. 3.5 A data perspectiveThe generic structural "paradigm" used within XML is that of a tree structure. Simplifying slightly, a single "document element" (or "root element") contains a number of "children", which may in turn have "children" of their own, and so on to an unlimited number of levels, with the lowest levels, or the "leaves" on the tree, being text data. In XML syntax, the tree structure is represented (in its simplest form) as a set of nested elements. Note that this is simply one way of representing the tree structure using the XML syntax: it represents the decision of one designer, and it is not the only way i.e. the same tree structure could have many different expressions using XML. This is a very important point and we return to it at the end of this section. (See figure 10.) The tree-structure model is a simple but powerful one, and a wide range of structured data can be represented in this way - including the classes of data that are typically stored in a relational or object-oriented database. Indeed the most widespread use of XML is in this area, rather than in the "traditional" area of "document markup" (though XML continues to be used in the latter area too). This capability was already present in SGML, but the complexity of SGML and its software tools made it much too costly and difficult to deploy in this context. In contrast, the simplicity of XML and the lightweight nature of its tools make it much better suited for this purpose. This assertion should be qualified by a note of caution that, even within the reduced complexity of XML, this sort of exchange depends on the careful management of several variables. It should also be emphasised that such data exchange did take place before the advent of XML, using technologies designed specifically for that purpose (e.g. the Common Object Request Broker Architecture (CORBA)), and indeed that continues to be the case. From a strictly technical viewpoint, an XML-based approach may not be appropriate in all contexts, but there has been a massive deployment of XML in this area. Indeed that deployment has led to moves to improve the integration between the XML-based and non-XML-based technologies [11]. The term serialisation is used to describe the process of creating an XML-based representation of structured data that either is stored persistently in another form or has been created by an application within memory, in order to transmit that data to another application or system. At the other end of the transmission channel, it is read, parsed and de-serialised and, depending on the nature of the application, the data may be added to a persistent store (e.g. a database) at the "target" side of the exchange. In some cases the XML document might exist only for the brief duration of its transmission over a network; in other cases it may be stored in a semi-permanent form which is accessed by the target application some time later. The capability of XML to support this sort of exchange between different operating systems is one of the main reasons for its widespread use, and some major database vendors have begun to integrate such XML serialisation / de-serialisation functionality into their systems. An analogy is sometimes drawn between XML elements and attributes and nouns and adjectives, with the suggestion that the designers of XML markup languages should represent "primary" content as character data and reserve attributes for "information about content". Such assertions perhaps reflect a rather narrow "document-oriented" perspective or experiences of the behaviour of a small subset of software tools. In fact, no such universal rules can be applied and different designers make different decisions about the use of elements and attributes. Figure 8 described one way of serialising a record from a database table using XML syntax, and in that form the data content of the fields in the table was represented as element content in the XML document. A second designer may take the decision to serialise the data using attribute values instead: It is perhaps worth repeating at this point that while XML documents are human-readable, it is rarely the case that human readability is the primary design consideration - and this is especially true of data-oriented applications where the primary generators and consumers of the XML documents are software tools. 3.6 XML in practiceIn fact, although the XML specifications use the SGML-based terminology of the "document", such a document may be any collection of information processed as a unit, and not necessarily one which we would label as a "document" in the more general sense of the word. Such a "unit" might be a report or a technical manual, but it might also be an employee record, a purchase transaction, or a metadata record describing an information resource - or indeed an aggregation of several of these units to be processed as a whole. Many "data-oriented" XML-based applications have little relationship with the "document-oriented" domain of publishing and formatting - though it should be noted that there are also a large number of XML applications that do retain precisely these concerns. The document-data distinction should perhaps be thought of not as a simple opposition but as a continuum, with individual applications lying somewhere between the two poles. There is some correspondence between the position of an application on this document-oriented/data-oriented continuum and the way the XML document is created. Although there are exceptions to this generalisation, XML documents in a "document-oriented" application are typically created by the direct action of a human author using a text-based software tool (an "XML editor") to apply markup to the data content of a document. Such tools make use of the rules recorded in a DTD or XML Schema to ensure that the author can use only the markup that is permitted by the structural model. This process of "marking up" a document is sometimes described as "encoding", and perhaps the most widely known "document-oriented" applications are those which make use of the of the Text Encoding Initiative (TEI) DTD to encode literary and linguistic texts for academic research, or the DocBook DTD for structuring technical documentation [12]. In contrast, in a data-oriented application the XML document is usually created by the action of an export or serialisation program that applies markup to data stored elsewhere, probably in a database. If a human creator created the content initially, they probably did so by entering it using a form without even being aware that it would be "marked-up" as an XML document! In such applications, the use of XML is completely invisible to the human users of the application, both the information manager and the end user - though of course not to the application designer or software developer. The case of the Encoded Archival Description (EAD) DTD illustrates perhaps that the document-data distinction is not always clear-cut. EAD is a DTD for the encoding of archival finding aids [13]. Archival finding aids are highly structured documents that describe archival materials, and such finding aids are created in accordance with a number of structural and content standards. Usually, such finding aids have a hierarchical structure that incorporates description at various levels, from that of a high-level aggregate of material, through sub-groups of that whole, possibly down to the description of individual items. The standard documentation that supports the use of EAD tends to emphasise a "document-oriented" approach to the encoding of this information. It is certainly true that the higher levels of description within an archival finding aid usually consist of extended pieces of textual description. At lower levels, however, the descriptive information within the finding aids often has a regular tabular structure that has many of the characteristics we might associate with the data-oriented perspective. The tools and processes used to create EAD-encoded documents are a matter for the individual implementer to decide, but a "hybrid" approach is quite possible, with some information encoded using an XML editor and other parts created by exporting the content of database tables. 4. Information sharing using XMLSome of the popular literature on XML suggests that "XML lets you make up your own tags". It is quite true that XML permits the document creator to choose whatever element type names and attribute names they wish (subject to XML's limitations on the use of special characters). Further, because validation against a DTD or XML Schema is optional, the XML specification itself imposes no requirement that the markup used in an instance is checked against a pre-existing model: the only requirement is that the document should be "well-formed". You could use element type names and attribute names that are not pre-defined elsewhere. However, it is vital to remember that the primary purpose of using XML is to share structured data (or documents) with another party. As was emphasised in section 3.4, XML says nothing about the meaning of the element type names and attribute names that you assign. Even if you choose names that you consider meaningful, precise and unambiguous, you can have no certainty that a human recipient of your XML document will interpret your names as you intended or that a software agent will process your data elements as you expected. To avoid misinterpretation, you must establish prior agreement with the recipient in advance on exactly what your markup means: you must use a common markup language. In theory your project could design your own markup language, create and publish a DTD or XML Schema and the supporting documentation to describe the language, and then ensure that all of your communication partners understand its meaning. This may be sustainable for XML-based information exchange within a "closed" community with a small number of partners, but even in this case it should be emphasised that the design of a markup language is not a simple task. In short, then, you should only consider "making up your own tags" for XML documents which you are certain will be circulated only within the boundaries of your own system - and even then it is vital that you document the meaning of your markup for the benefit of other developers who will have to maintain that system in the future. For sharing of information beyond the boundaries of a system, it is almost always preferable to adopt an existing DTD or XML Schema that reflects the consensus of a community. As the use of XML increases, there are XML markup languages for a wide range of applications in a number of domains, and many of these are recognised as standards for information exchange within particular communities. The use of XML Schemas is a key component of the UK government's e-government Interoperability Framework (e-GIF) [14]. The e-GIF initiative is defining XML Schemas to describe and (through validation) control the structure (and to some extent, through data-typing constraints, the content) of information which is exchanged internally between government systems and in at least some transactions between government and external communication partners. Such schemas are central to the management of transactions to be conducted via the "Citizen's Portal" [15]. At this point, it is useful to consider a little more closely the requirements for the effective transmission of information using language. Consider the example of making a simple statement using the English language. For my statement to be interpreted correctly by a reader, we need to have agreement about (at least!) three things:
If my reader's interpretation of any of these factors differs from mine, then there is risk that my statement will not be interpreted as I intended. 4.1 The power of XMLA language community is defined by consensus on such conventions, and the same is true for the exchange of information using XML i.e. we can think of "markup language communities" where
This is best illustrated through some simple examples. Suppose that I prepare a music catalogue using the (imaginary!) MusicCat XML Schema and publish my catalogue on the Web, and a remote collector prepares and publishes a catalogue using the same XML Schema (see Figure 11).
<catalogue>
<album identifier="http://pj.org/album/245">
<title>The Spotlight Kid</title>
<artist>Captain Beefheart</artist>
<track identifier="http://pj.org/track/723">
<artist>Captain Beefheart</artist>
<song identifier="http://pj.org/song/999">
<title>Grow fins</title>
<author>Van Vliet, Don</author>
</song>
</track>
<track identifier="http://pj.org/track/724">
<!-- and so on... -->
</track>
</album>
</catalogue>
<catalogue>
<album identifier="http://johnsmith.org/album/777">
<title>Clear Spot</title>
<artist>Captain Beefheart</artist>
<track identifier="http://johnsmith.org/track/888">
<artist>Captain Beefheart</artist>
<song identifier="http://johnsmith.org/song/999">
<title>Big eyed beans from Venus</title>
<author>Van Vliet, Don</author>
</song>
</track>
</album>
</catalogue>
Figure 11. Two MusicCat XML catalogues Then I can read their XML document and locate tracks by a specified artist, but more importantly my software can search their document because I have already programmed it with the following mapping:
4.2 The limits of XMLAs with natural language, the difficulties arise when information must be shared beyond the boundaries of the community - and this is a primary requirement in the use of metadata. Continuing the example above, suppose that a museum has published a description of its holdings using the (imaginary...) ArtCat XML Schema.
<catalogue>
<collection>
<identifier>
http://museumofmodernart.org/collection/12
</identifier>
<title>The Magic Band Sketches Collection</title>
<creator>Van Vliet, Don</creator>
<items>
<picture>
<identifier>
http://museumofmodernart.org/picture/63
</identifier>
<details>
<title>Zoot Horn Rollo</title>
<artist>Van Vliet, Don</artist>
</details>
</picture>
<picture>
<!-- and so on... -->
</picture>
</items>
</collection>
</catalogue>
Figure 12. An ArtCat XML catalogue Then I can read their XML document and I can probably locate pictures painted by a specific artist in their catalogue. However, it requires either some guesswork on my part based on the element type names and attribute names or a reference to the documentation that describes the semantics and structure of the ArtCat schema. To search across both catalogues, my software - the search component of my cross-domain metadata service - now has to be programmed with two mappings:
In fact there are at least three separate problems to be addressed here, and these are considered in turn in the following sections. 4.2.1 The uniqueness of names : Namespaces in XMLThe first problem is that two different XML Schemas can use the same term to express different concepts. In our examples above, both MusicCat and ArtCat use the element type name "artist". In this particular example, the difference in meaning is perhaps not so great and both might be seen as types of resource creator. However, it is easy to think of examples where the same term is used with quite different meanings in different domains: the term "conductor" signifies three quite different concepts in the separate areas of public transport, classical music and electrical engineering - and yet it would be quite possible for three domain-specific XML Schemas to use the term as an element type name! As long as document instances are exchanged only within the domain - within the boundaries of that markup language community - then the name is interpreted unambiguously according to the conventions of that community. However, when this data is passed from one community to another or data from the three communities is combined (as in the case of a metadata aggregation service), we face the problem of the "collision" of names - the same term used with quite different meanings. The W3C "Namespaces in XML" specification addresses this problem [16]. It allows names to be qualified by associating them with a "namespace". A namespace is a collection of names, and it has a unique name: the uniqueness of namespace names is guaranteed by making them URIs. Element type names and attribute names can then be qualified by a namespace name - which removes the ambiguity where two names from different schemas "collide". At the syntactic level, the association between the "local part" of the name and the namespace name is made through the use of a namespace prefix. The prefix is associated with the namespace name (by a namespace declaration), and the prefix is then used to qualify names. The resulting qualified name has a local part and a namespace name. The following example associates the element type name "title" with the namespace "<http://pj.org>".
<doc xmlns:my="http://pj.org/">
<my:title>XML and metadata sharing</my:title>
</doc>
Figure 13. XML namespaces A second example illustrates the use of two different namespaces to avoid a "collision" of names:
<doc xmlns:our="http://pj.org/"
xmlns:their="http://nof.org/">
<our:title>Metadata sharing and XML</our:title>
<their:title>
NOF Information Paper 5:
Metadata sharing and XML
</their:title>
</doc>
Figure 14. XML namespaces Finally it should be noted that the title element in figure 13 (my:title) has the same qualified name as the first title element in figure 14 (our:title): it is not the namespace prefix which is significant, but the namespace name with which that prefix is associated. The use of XML namespaces has probably caused more debate than any other XML-related subject. We certainly do not propose to revisit that debate here. The main point is that all XML namespaces do is provide a mechanism for qualifying names to make them unique (the use of URIs) and a shorthand syntax for applying this in XML documents (the use of namespace prefixes). 4.2.2 The need for a pidgin : the Dublin CoreThe second problem in the example above is that the two XML Schemas (MusicCat and ArtCat) use different element type names ("author" and "artist") to express the concept of the "creator" of two different types of resource. In fact the two names probably convey to their human reader rather more than the concept of "creator", since they express more information about two different processes of creation. These differences are important to the manager of those resources and to the user of this information within the respective domains. From the point of view of a fairly simple process of resource discovery, however, the concept of "the creator of the resource" is often satisfactory. This is not the same as saying that the distinction between an "author" and an "artist" is irrelevant: rather, that there are some contexts where that distinction is not of primary importance. The Dublin Core Metadata Element Set is usually presented as a small set of terms (only 15 elements in its basic subset) which describe properties common to most types of resource, and which can be used for composing simple descriptions of resources [17]. However, since we have approached the subject of metadata sharing as one of communication and the use of language, it is appropriate to apply this same perspective here. In an important article [18], Tom Baker presents the view that the Dublin Core element set is a small vocabulary that can be used to make simple statements: Dublin Core performs the role of a "pidgin" language. The markup languages of the many different resource description communities are certainly more powerful and expressive than the Dublin Core pidgin, and that power is appropriate for communication within those communities where it can be interpreted as its "speakers" intend. As with natural language, however, when information is shared beyond the community - as is the case with metadata - , some simplification of that expression is often the most effective means of communication. At this point in the paper, we concentrate on the first aspect of the Dublin Core pidgin: its simple vocabulary. Baker's article emphasises the simple structure of its statements, and we return to this aspect in section 4.2.3. The proponents of Dublin Core do not suggest that this simple vocabulary serve as the "native" lexicon of each community (though in some cases it may prove adequate). Rather those communities should seek to "map" the terms of their local languages - or at least a subset of those terms - to the terms of the Dublin Core vocabulary and make descriptions of their resources available in this simplified form - which (it is hoped!) a larger proportion of readers outside of the community will be able to interpret and understand. The Open Archives Initiative (OAI) metadata harvesting protocol recognises the value of this approach in its requirement that metadata records be made available using the simple Dublin Core vocabulary (and OAI provides a corresponding XML Schema for this purpose). OAI allows a resource provider to make available records conforming to other schemas, but the availability of simple DC records is mandatory. The Technical Standards & Guidelines for NOF-digitise also mandate that Dublin Core descriptions are produced: In order to facilitate potential exchange and interoperability between services, item level descriptions must be capable of being expressed in Dublin Core and should be in line with developing e-government and UfI metadata standards. [19] If the MusicCat and ArtCat XML Schemas had made use of XML namespaces to disambiguate the names of all element types and attributes, and had made use of the more generic Dublin Core elements in place of the domain-specific names like "author" and "artist", the above examples might appear as:
<music:catalogue xmlns:music="http://music.org/"
xmlns:dc="http://purl.org/dc/elements/1.1">
<music:album dc:identifier="http://pj.org/album/245">
<dc:title>The Spotlight Kid</dc:title>
<dc:creator>Captain Beefheart</dc:creator>
<music:track dc:identifier="http://pj.org/track/723">
<dc:creator>Captain Beefheart</dc:creator>
<music:song dc:identifier="http://johnsmith.org/song/999">
<dc:title>Grow fins</dc:title>
<dc:creator>Van Vliet, Don</dc:creator>
</music:song>
</music:track>
</music:album>
</music:catalogue>
<art:catalogue xmlns:art="http://art.org/"
xmlns:dc="http://purl.org/dc/elements/1.1">
<art:collection>
<dc:identifier>
http://museumofmodernart.org/collection/12
</dc:identifier>
<dc:title>The Magic Band Sketches Collection</dc:title>
<dc:creator>Van Vliet, Don</dc:creator>
<art:items>
<art:picture>
<dc:identifier>
http://museumofmodernart.org/picture/63
</dc:identifier>
<art:details>
<dc:title>Zoot Horn Rollo</dc:title>
<dc:creator>Van Vliet, Don</dc:creator>
</art:details>
</art:picture>
</art:items>
</art:collection>
</art:catalogue>
Figure 15. MusicCat and ArtCat using XML Namespaces and Dublin Core 4.2.3 The meaning of structure : XML and RDFHowever, even with the use of namespaces to qualify names and the pidginisation of some of the terms drawn from domain-specific vocabularies, the cross-domain search service must still be programmed with two sets of mappings:
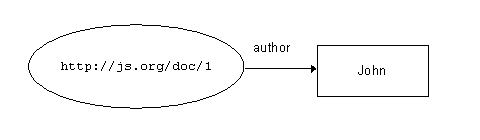
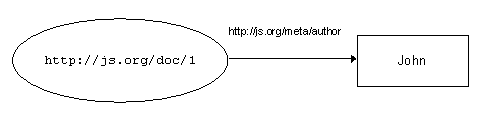
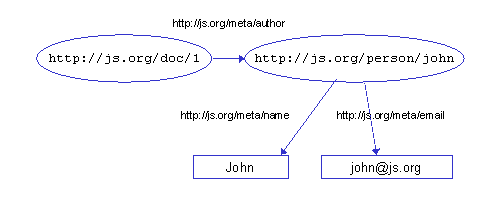
These multiple mappings are necessary because the two different XML Schemas employ different structural conventions to express relationships between units of information. For example, the statement that a resource (album, track, song, collection, picture etc) has a "creator" is expressed using different XML constructs in the two schemas - and within the ArtCat schema different conventions are used for the "collection" and the "picture". These are simply the choices of the schema designers and all are equally good and valid. A human reader of the document may be able guess the conventions, but a software tool must be programmed with prior "knowledge" of the different structural conventions in use. While this may be sustainable for a service operating over instance documents conforming to a small number of different XML Schemas, it is not scalable to a context in which the number of schemas and the number of structural conventions is ever increasing - which is quite likely to be the case for a service operating on metadata from several domains. Tim Berners-Lee summarises the problem: XML allows users to add arbitrary structure to their documents but says nothing about what the structures mean The solution proposed by Berners-Lee and the W3C is the adoption of a common simple model for the expression of statements about resources, and a set of standard syntactic conventions for representing those statements in XML. In adopting this standard model and the syntax to represent it, communication partners accept a common convention for the meaning of structures in their XML documents. This is what the Resource Description Framework (RDF) seeks to provide. 5. The Resource Description Framework (RDF)5.1 RDF Model & SyntaxThe Resource Description Framework (RDF) Model and Syntax is another recommendation of the W3C [21]. (There are a number of other specifications that build on RDF, RDF Schema being of particular importance, but they will not be discussed here.) The designers of RDF sought to address the requirements for exchanging metadata and for combining metadata from diverse sources, while leaving the description of the semantics of that metadata to the appropriate resource description communities. The premise underlying RDF is that metadata consists of simple statements about resources. This is similar to Tom Baker's approach to the pidgin "grammar" of Dublin Core: as well as adopting a small vocabulary, pidgin speakers employ that vocabulary using simple sentence patterns that can be used in many different contexts. In RDF, those statements take the form: a resource has a property which has a value, and the value may be a string (a literal) or a second resource. In RDF, a property is an "attribute" (in the general sense of the word!) used to describe that resource. For example, figure 16a represents the statement that:
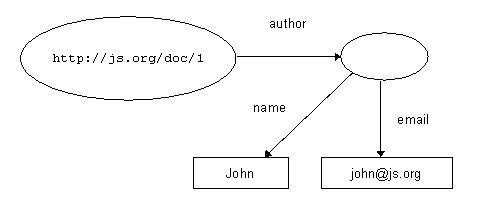
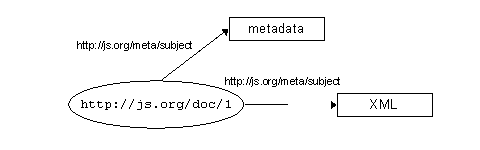
Figure 16b extends that first statement by adding that:
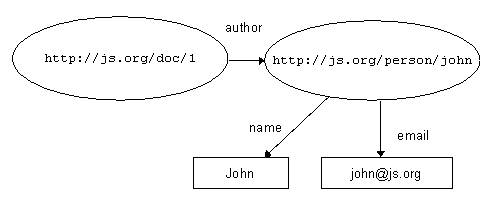
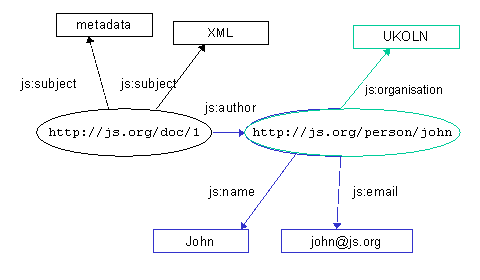
Figure 16c illustrates that the second resource can also be uniquely identified: A resource is anything which can be identified by a Uniform Resource Identifier (URI) - which turns out to mean "anything that has identity" [22]. That "thing" need not exist as a physical or digital object, but if we assign a URI to it, that assignment enables us to make statements about it! Sometimes, when a URI has been assigned to a resource, then the resource is described as being "on the Web". Further, it is common practice for people making statements about resources to ensure the uniqueness of their URIs by using URIs constructed on the basis of the domain name of a Web server, and carrying the http: scheme prefix. This convention is a means of ensuring uniqueness, but that is all it is: the use of http:-based URIs does not mean that anything exists at the location identified if that string is interpreted as a URL. So, anything can be identified by a URI. The properties used in an RDF statement can be uniquely identified by URIs, which is useful when we wish to combine statements which use the vocabularies of different resource description communities: This simple model proves to be extremely powerful. It is extensible: RDF provides a pidgin grammar, but it has little to say about the vocabulary to be used. In fact, RDF allows properties to be drawn from any vocabularies, and multiple vocabularies can be used in the same document. Further, these simple statements can be combined to build up more complex ones. Because URIs provide unique identifiers for both resources and properties, statements created independently by different authors can be "merged" Figure 17a. Merging RDF descriptions Figure 17b. Merging RDF descriptions Figure 17c. Merging RDF descriptions Figure 17d. Merging RDF descriptions This model is independent of XML - RDF-based statements could be (and indeed are) recorded in many different forms - but the RDF Model & Syntax recognises the value of XML as a syntax for exchange and defines conventions for expressing RDF statements in XML. The document fragments in figures 18a to 18d correspond to the descriptions portrayed diagrammatically in figures 17a to 17d. Figure 18d represents the merged description:
<rdf:RDF xmlns:js="http://js.org/meta/">
<rdf:Description about="http://js.org/doc/1">
<js:author>
<rdf:Description about="http://js.org/person/john">
<js:name>John</js:name>
<js:email>john@js.org</js:email>
</rdf:Description>
</js:author>
</rdf:Description>
</rdf:RDF>
Figure 18a. Merging RDF/XML descriptions
<rdf:RDF xmlns:js="http://js.org/meta/">
<rdf:Description about="http://js.org/doc/1">
<js:subject>metadata</js:subject>
<js:subject>XML</js:subject>
</rdf:Description>
</rdf:RDF>
Figure 18b. Merging RDF/XML descriptions
<rdf:RDF xmlns:js="http://js.org/meta/">
<rdf:Description about="http://js.org/person/john">
<js:organisation>UKOLN</js:organisation>
</rdf:Description>
</rdf:RDF>
Figure 18c. Merging RDF/XML descriptions
<rdf:RDF xmlns:js="http://js.org/meta/">
<rdf:Description about="http://js.org/doc/1">
<js:author>
<rdf:Description about="http://js.org/person/john">
<js:name>John</uc:name>
<js:email>john@js.org</js:email>
<js:organisation>UKOLN</js:organisation>
</rdf:Description>
</js:author>
<js:subject>metadata</js:subject>
<js:subject>XML</js:subject>
</rdf:Description>
</rdf:RDF>
Figure 18d. Merging RDF/XML descriptions Furthermore, the RDF model corresponds well to the data used within relational and object-oriented databases: it is relatively easy to express the information held in a database using the RDF model and to publish that information using the RDF/XML syntax. And once it is published in that form it is available for querying and processing in association with similar data from other sources. Returning to the example above, where three sets of RDF statements were "merged", imagine that the sources of those three sets of statements were records stored in three quite separate databases. The databases can be queried separately, certainly, and a human user could perform three separate queries and merge the results together. Once the data is published using RDF, programs can join the previously separate statements together - and other parties can begin to add new statements about those resources. We noted above that in many cases XML documents are created by programs rather than by human authors, and this holds even more so for RDF/XML documents. In short, then using RDF in association with XML means adopting specified conventions for the meaning of structures in an XML document. By constraining the options available, RDF enhances interoperability by reducing the risk that a document is misinterpreted. A reader of the document who is aware of those conventions and who recognises that the document is applying them can interpret the meaning of the structures without ambiguity. Furthermore, the reader can do so on the basis that they may not be familiar with all the vocabularies used in the document, but they are able to recognise the statements made about resources and extract those statements which use the vocabularies they do recognise. For example, consider the instance document in figure 19:
<rdf:RDF xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:js="http://js.org/meta/">
<rdf:Description about="http://js.org/doc/1">
<dc:title>Metadata sharing and XML</dc:title>
<dc:creator>John Smith</dc:creator>
<js:rating>3</js:rating>
</rdf:Description>
</rdf:RDF>
Figure 19. A multi-vocabulary RDF/XML description Any RDF-aware application reading that document will interpret it as containing three statements about the resource http://js.org/doc/1. Suppose the application has been programmed to seek statements made using the properties of the Dublin Core element set - perhaps it is part of an aggregation service reading descriptions harvested from the Web in order to compile a database of Dublin Core-based resource descriptions. The properties of the Dublin Core element set are of course all identifiable by URIs. The application "recognises" that two of the statements in this description use Dublin Core properties and it can create the appropriate database entries. The third statement uses a property http://js.org/meta/rating which the application does not recognise - it is presumably of interest to another use community - and the application can simply ignore that statement. (If the application had access to additional information about the relationships between terms from different vocabularies, then it might be able to establish that it was in fact the equivalent of a Dublin Core property, but that is beyond the scope of this discussion.) For a cross-domain metadata service, then, the use of RDF/XML addresses the scalability issue of having to manage the structural conventions of an ever-expanding number of domain-specific XML Schemas. It also permits the use of multiple vocabularies in a manner which allows partners to communicate, at least on a basis of "partial understanding". 5.1 RDF: a note of cautionAt the time of writing (late 2001), there is a good deal of enthusiasm about the potential of RDF. It forms the cornerstone of Tim Berners-Lee's vision of a "Semantic Web", and there is considerable activity in this area at the W3C and within academic research communities. There are some RDF applications in use outside this context - the most widely deployed is perhaps RDF Site Summary (RSS), used primarily to deliver metadata about news stories between content providers and portals on the Web [23]. However, RDF has not yet been adopted as widely as its developers and supporters might have hoped. In part, this is perhaps a problem of perception: because the interest in RDF is coming in the first instance from research communities, it is perceived as theoretical. And indeed, some of the discussions about RDF tend to be cast within a language which is not immediately familiar to the XML community. Further, at the time of writing (November 2001), a W3C working group is in the process of making some (minor) revisions to the RDF Model & Syntax specification and completing work on the RDF Schema specification [24]. As a consequence, there are fewer RDF-based software tools available, and considerably less expertise amongst application designers and software developers than is the case for XML - though this situation is changing. However, there is a real danger of ignoring the existence of the problems that RDF is designed to address, and which this paper has sought to explain. 6. SummaryXML is designed specifically to support the sharing of structured data across applications and systems, and it has a vital role to play in the sharing of metadata to facilitate resource discovery. The essential contribution that XML makes is to provide a syntax for data exchange, but this is only one of the requirements for effective sharing of information using XML. The adoption of a standard schema for resource description and the use of that schema in accordance with its supporting documentation provides a vocabulary and the semantics associated with that vocabulary. Conformance to a community standard XML DTD or XML Schema represents adherence to a common structural model and consensus on what that structural model conveys - an agreement on grammar. XML document instances can be shared within that community and their syntax, semantics and structure will be unambiguous to their recipients. However, one of the defining characteristics of metadata is that it is shared beyond the boundaries of a single community. In this open environment, the use of XML namespaces and of small "pidgin" vocabularies like the Dublin Core metadata element set provide support for syntactic and semantic interoperability, but the multiple XML DTDs and XML Schemas of the different communities lack a common convention for the meaning conveyed by structure - they do not share a common grammar. The RDF Model and Syntax specification seeks to provide this common grammar by specifying the meanings of structures: by constraining the options available to express meaning through structure, the risk of ambiguity and misinterpretation is reduced and the potential for interoperability between systems is increased. 7. Some questions to consider
Glossary
Notes and references[1] For more information, see UKOLN, nof-digitise Technical Standards and Guidelines Version 3, (July 2001). Available at [2] Berners-Lee, Tim, "Metadata architecture", "Design issues" working paper (January 1997). Available at [3] Dempsey, Lorcan and Rachel Heery, "Metadata: a current view of practice and issues", Journal of Documentation 54 (2), (March 1998). Preprint version available at [4] The Open Archives Initiative Protocol for Metadata Harvesting Version 1.1 (July 2001). Available at [5] Extensible Markup Language 1.0 (Second Edition) (October 2000). Available at [6] This section draws heavily on the introductory sections of: [7] HyperText Markup Language (HTML 4.01) (December 1999). Available at [8] Cascading Style Sheets, Level 1 (December 1996). Available at [9] Introductions to XML syntax include: [10] XML Schema is published in three parts: [11] For information on CORBA, and on the relationship of CORBA and XML, see the Object Management Group site at [12] The Text Encoding Initiative website is at [13] The Encoded Archival Description website is at [14] Cabinet Office, e-government: a strategic framework for public services in the Information Age, (April 2000). Available at
[15] The UKonline.gov.uk website is at [16] Namespaces in XML (January 1999). Available at [17] The Dublin Core Metadata Initiative website is at [18] Baker, Thomas. "A Grammar of Dublin Core", D-Lib 6 (10), (October 2000). Available at [19] UKOLN, nof-digitise Technical Standards and Guidelines Version 3, (July 2001). Available at [20] Berners-Lee, Tim, James Hendler and Ora Lassila, "The Semantic Web", Scientific American, (May 2001). Available at [21] Resource Description Framework Model and Syntax Specification, (February 1999). Available at
[22] RFC 2396: Uniform Resource Identifiers (URI): Generic Syntax
, (August 1998). Available at
[23] RDF Site Summary (RSS) 1.0, (December 2000). Available at
[24] The RDF Core Working Group website is at
|
AcknowledgementsThis paper was commissioned from Pete Johnston by UKOLN on behalf of the New Opportunities Fund in association with the People"s Network and is one of a series of Information Papers that will be produced by the NOF Technical Advisory Service. Queries about the Information Papers should be addressed to:
Marieke Napier UKOLN is funded by Resource: The Council for Museums, Archives & Libraries, the Joint Information Systems Committee (JISC) of the Higher and Further Education Funding Councils, as well as by project funding from the JISC and the European Union. UKOLN also receives support from the University of Bath where it is based. |