On 25 November 1998, the WebWatch robot crawled the entry points for UK academic Web sites. This report is an analysis of the findings. This is the third Web crawl of the UK HEI entry points and completes a series of three snapshots of this community. The first crawl is available from the reports area of the WebWatch pages [1] and the second was published in the Journal of Documentation [2].
The input file of URLs obtained from NISS for the previous crawl was used. Of the 170 sites in this list, 150 sites were successfully crawled. Network/connection errors, out of date URLs and so on account for the 20 unexplored sites.
Figure 1 shows a histogram of the total size of entry points. Total size is defined as the HTML page with inline images. A number of linked resources which may be downloaded by modern browsers, including external style sheets, external client-side scripts, resources requiring 'plugins' and background images are not included.
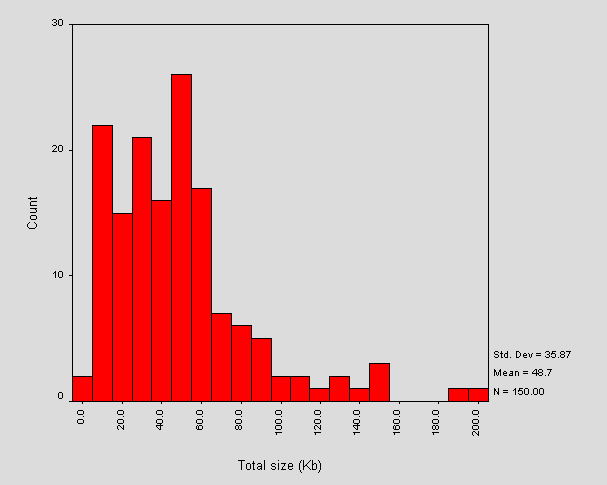
Figure 1 - Total Size of Entry Points
The range of sizes spans from around 5kb (<URL: http://www.rcm.ac.uk/>) to around 200Kb (<URL: http://www.kiad.ac.uk/>). The second large outlier at 192Kb corresponds to <URL: http://www.scot.ac.uk/>.
Figure 2 shows the number of hyperlinks within each site. These are obtained from the A element and from image map AREA elements. This data may include duplicate URLs where more than one hyperlink to the same URL exists.
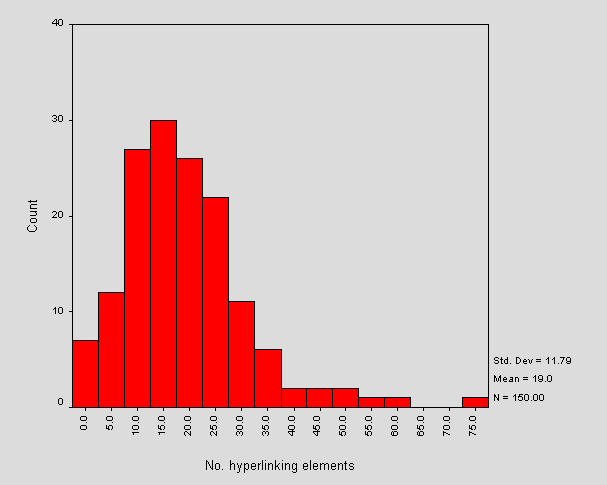
Figure 2 - Total Number of Hyperlink Elements per Site
Note that the outlier corresponds to <URL: http://www.rhbnc.ac.uk/>.
Figure 3 shows a pie chart of the server software encountered during the crawl. This information is based upon the HTTP Server header returned by the web server.
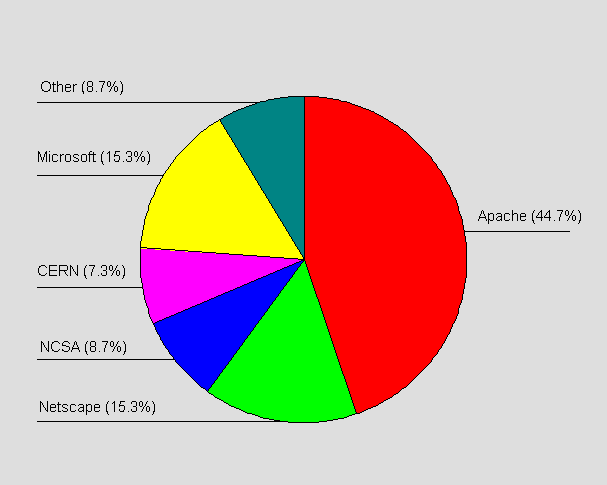
Figure 3 - Server Software Encountered
The Other category consists of the following servers:
| Server | Count |
| Borderware | 1 |
| Lotus Domino | 1 |
| Novell | 2 |
| OSU | 2 |
| SWS-1.0 | 1 |
| WebSTAR | 4 |
| WinHttpd | 1 |
Figure 4 - Components of the 'Other' slice from Figure 3
A more detailed table of the servers found is shown in Figure 5.
| Server | Count |
| Apache/1.0.0 | 1 |
| Apache/1.0.3 | 1 |
| Apache/1.1.1 | 1 |
| Apache/1.1.3 | 1 |
| Apache/1.2.0 | 2 |
| Apache/1.2.1 | 2 |
| Apache/1.2.1 PHP/FI-2.0b12 | 1 |
| Apache/1.2.4 | 7 |
| Apache/1.2.4 FrontPage/3.0.2 | 1 |
| Apache/1.2.5 | 12 |
| Apache/1.2.6 | 6 |
| Apache/1.2b10 | 2 |
| Apache/1.2b7 | 1 |
| Apache/1.3.0 (Unix) | 7 |
| Apache/1.3.0 (Unix) Debian/GNU | 1 |
| Apache/1.3.0 (Unix) PHP/3.0 | 1 |
| Apache/1.3.1 (Unix) | 6 |
| Apache/1.3.2 (Unix) | 1 |
| Apache/1.3.3 | 2 |
| Apache/1.3.3 (Unix) | 6 |
| Apache/1.3.3 Ben-SSL/1.28 (Unix) PHP/3.0.5 od_perl/1.16 | 1 |
| Apache/1.3.3 UUOnline/1.4 (Unix) | 1 |
| Apache/1.3a1 | 1 |
| Apache/1.3b3 | 1 |
| Apache/1.3b5 | 1 |
| BorderWare/2. | 1 |
| CERN/3.0 | 8 |
| CERN/3.0A | 3 |
| HTTPS/2.12 | 1 |
| Lotus-Doino/4.5 | 1 |
| Microsoft-IIS/2.0 | 3 |
| Microsoft-IIS/3.0 | 4 |
| Microsoft-IIS/4.0 | 15 |
| Microsoft-Internet-Inforation-Server/1.0 | 1 |
| NCSA/1. | 2 |
| NCSA/1.4. | 1 |
| NCSA/1.5.1 | 3 |
| NCSA/1.5.2 | 7 |
| Netscape-Comunications/1.1 | 1 |
| Netscape-Comunications/1.12 | 1 |
| Netscape-Enterprise/2.01 | 3 |
| Netscape-Enterprise/2.0a | 2 |
| Netscape-Enterprise/3.0 | 4 |
| Netscape-Enterprise/3.0F | 2 |
| Netscape-Enterprise/3.0K | 1 |
| Netscape-Enterprise/3.5-For-NetWare | 1 |
| Netscape-Enterprise/3.5.1 | 4 |
| Netscape-FastTrack/2.0 | 1 |
| Netscape-FastTrack/2.01 | 1 |
| Netscape-FastTrack/2.0a | 1 |
| Netscape-FastTrack/2.0c | 1 |
| Novell-HTTP-Server/2.5R | 1 |
| Novell-HTTP-Server/3.1R | 1 |
| OSU/1.9b | 1 |
| OSU/3.2 | 1 |
| SWS-1.0 | 1 |
| WebSTAR | 2 |
| WebSTAR/1.2.5 ID/13089 | 1 |
| WebSTAR/2.0 ID/44693 | 1 |
| WinHttpd/1.4a (Shareware Non-Comercial License | 1 |
| Total | 150 |
Figure 5 - Table of all Servers Encountered
Of these servers, 40% used HTTP/1.0 and 60% used HTTP/1.1.
The Queso [3] software was used to get an idea of platforms. The high level results are summarised in Figure 6. A more detailed breakdown is presented in Figure 6.
| Estimated | ||
| OS | Min | Max |
| UNIX | 97 | 108 |
| OS2 | 0 | 5 |
| MacOS | 6 | 11 |
| Netware | 3 | 3 |
| Windows NT/95/98 | 20 | 20 |
| Other | 7 | 7 |
| Unknown | 6 | 6 |
Figure 6 - Operating Systems as Reported by Queso
Note that the 'Other' category in Figure 6 corresponds to the Queso output categories Figure 7) 'Cisco...' and the 'Unknown' category corresponds to the Queso output categories 'Unknown OS', 'Firewalled host/port or network congestion' and 'Dead Host, Firewalled port or Unassigned IP'.
Note that the estimated minimum and maximum values in Figure 6 may be skewed because of the Queso unknowns referred to above.
| Operating system | Count |
| BSDi or IRIX | 1 |
| Berkeley: Digital, HPUX, SunOs4, AIX3, OS/2 WARP-4, others... | 5 |
| Berkeley: HP-UX B.10.20 | 1 |
| Berkeley: IRIX 5.x | 3 |
| Berkeley: usually Digital Unix, OSF/1 V3.0, HP-UX 10.x | 14 |
| Berkeley: usually HP/UX 9.x | 1 |
| Berkeley: usually SunOS 4.x, NexT | 5 |
| Cisco 11.2(10a), HP/3000 DTC, BayStack Switch | 7 |
| Dead Host, Firewalled Port or Unassigned IP | 2 |
| FreeBSD, NetBSD, OpenBSD | 1 |
| IBM AIX 4 | 2 |
| IRIX 6.x | 2 |
| Linux 1.3.xx, 2.0.0 to 2.0.34 | 5 |
| Linux 2.0.35 to 2.0.9 | 1 |
| MacOS-8 | 6 |
| Novell Netware TCP/IP | 3 |
| Reliant Unix from Siemens-Nixdorf | 1 |
| Solaris 2.x | 60 |
| Standard: Solaris 2.x, Linux 2.1.???, MacOS | 5 |
| Windows 95/98/NT | 20 |
| Firewalled Solaris 2.x | 1 |
| Firewalled host/port or network congestion | 3 |
| Unknown OS | 1 |
| Total | 150 |
Figure 7 - Queso Output
The attributes of the HTML META element were examined for known metadata conventions. Figure 8 shows the results.
| Metadata | No. META elements | No. sites |
| PICS | 1 | 1 |
| HTTP-EQUIV="Refresh" | 9 | 9 |
| Reply-To | 3 | 3 |
| Search Engine | 190 | 95 |
| Dublin Core | 102 | 11 |
| HTTP-EQUIV="(Dublin Core)" | 8 | 1 |
Figure 8 - Types of Metadata Encountered
29 pages used the SCRIPT element to include a client-side script block. Of these, 23 pages included the attribute-value LANGUAGE="JavaScript".
All HTML elements were searched for the set of defined JavaScript event handlers. The results are shown in Figure 9.
| Handlers | Count | Sites |
| onChange | 1 | 1 |
| onClick | 13 | 4 |
| onLoad | 10 | 8 |
| onMouseOver | 320 | 36 |
Figure 9 - Event Handlers Encountered
Two Java applets were referenced by the site <URL: http://www.uwic.ac.uk/>.
The site <URL: http://www.luton.ac.uk/> referenced a plugin using the OBJECT element.
21 sites used framesets. 10 sites use HTTP-EQUIV="refresh" to update the entry point page.
Figure 10 shows a summary of the cachability of crawled resources.
| Cachable resources | 72.5% of HTML pages, 80.9% of images |
| Non-cachable resources | 4.4% of HTML pages, 0.2% of images |
Figure 10 - Cachability of Resources Encountered
Additionally, 40% of HTML pages and 45% of images contained the HTTP/1.1 Etag header.
A resource is defined as cachable if:
A resource is defined as not cachable if:
The cachability of resources is not determined if the resource used the Etag HTTP/1.1 header, since this would require additional testing at the time of the trawl which was not carried out.
As shown in Figure 11, the Apache and Microsoft servers have shown increasing adoption. The Netscape server has fluctuated (perhaps due to a period of experimentation). The NCSA and CERN servers have shown a decrease in usage.
The growth of Apache and Microsoft servers has also resulted in a decrease of the 'Other' category, i.e. sites are subscribing to the more popular servers.
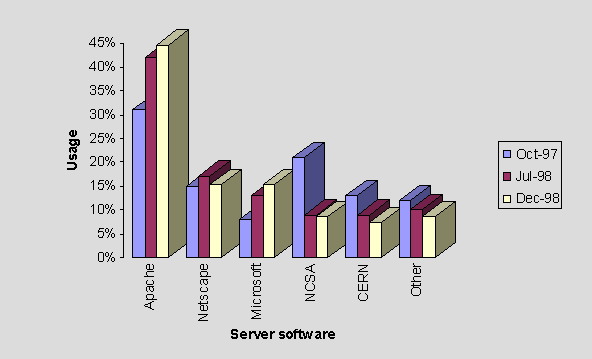
Figure 11 - Use of Server Software Over Three Crawls
A chart showing the growth of various servers is shown in Figure 12. This chart shows the contribution of growth for the period Oct 1997 - Jul 1998 and Jul 1998 - Nov 1998. Note that negative growth is interpreted as decline.
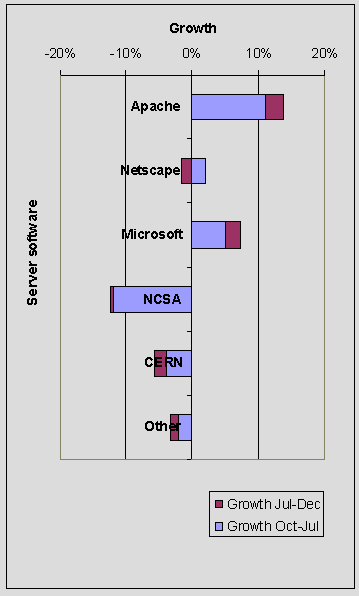
Figure 12 - Growth of Servers over Three Crawls
A set of sites was isolated, for which reliable measurements of size exist for two previous web crawls. The results are shown in Figure 13.
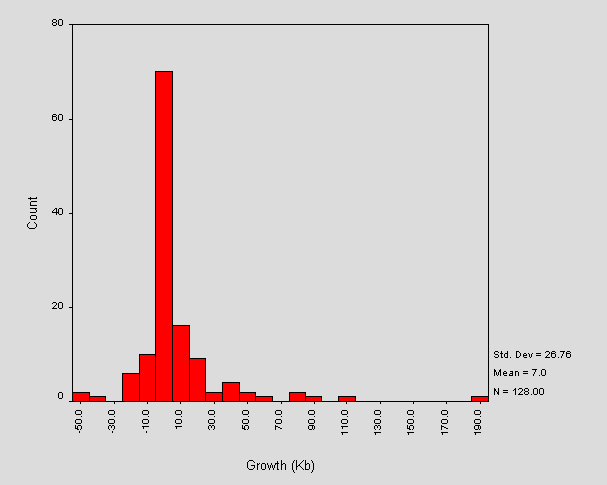
Figure 13 - Changes in Size of Entry Points
Note that a majority of sites have not undergone great fluctuations in size. The outlier corresponds to <URL: http://www.scot.ac.uk>. The pages for this site are different since this site has become part of a larger institution.
The number of institutional entry points which make use of "splash screens" or redirect has shown a steady increase from five sites (Oct 97) to seven sites (July 1998) to ten sites in the current trawl.
The domains referenced by hyperlinks in the three crawls have been dominated by ac.uk and this domain has shown an overall increase. Figure 14 shows the contribution of different types of domain name as a percentage of all hyperlinks in the site.
| Domain | October 1997 | July 1998 | November 1998 |
| Total .uk | 97.31% | 97.13% | 98.00% |
| ac.uk | 96.63% | 95.94% | 97.68% |
| net | 0.30% | 0.16% | 0.11% |
| com | 0.82% | 0.61% | 0.63% |
| org | 0.34% | 0.08% | 0.18% |
| Other | 0.15% | 0.08% | 0.10% |
| IP address | 0.00% | 0.12% | 0.04% |
| Badly formed URL | 1.10% | 1.72% | 0.91% |
Figure 14 - Domains Referenced in Hyperlinks
Note in Figure 14, that the ac.uk data is a subset of the uk data.
In each crawl, we have looked for search-engine (SE) type metadata and Dublin-Core (DC) metadata. The findings over the 3 crawls are shown in Figure 15.
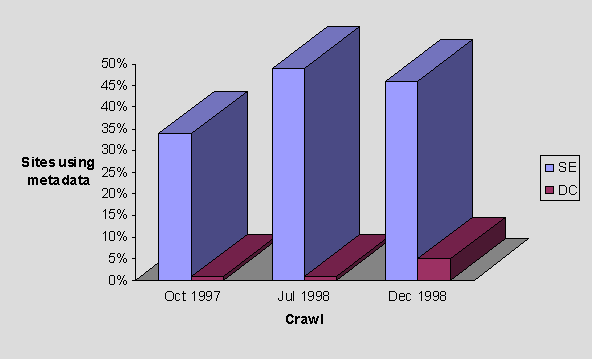
Figure 15 - Trends in Metadata Usage
Figure 15 shows that the use of Dublin Core metadata has increased considerably over the three crawls, from one site in October 1997 to 11 sites in November 1998.