In May 1988, the WebWatch robot 'watched' UK University and College library web sites. This report contains an analysis of the data obtained from this web community.
A list maintained by NISS [1] provided entry-point URLs for 99 library sites. From these we were able to analyse 81 sites, some sites from the list were not analysed for reasons explained later. The analysis included looking at HTML and image resources and the HTTP headers associated with them. Resources will refer to HTML and images unless otherwise specified.
The data collected was processed with various Perl scripts into a form suitable for subsequent analysis with Excel and SPSS.
Figure 1 shows the distribution of number of resources per site.
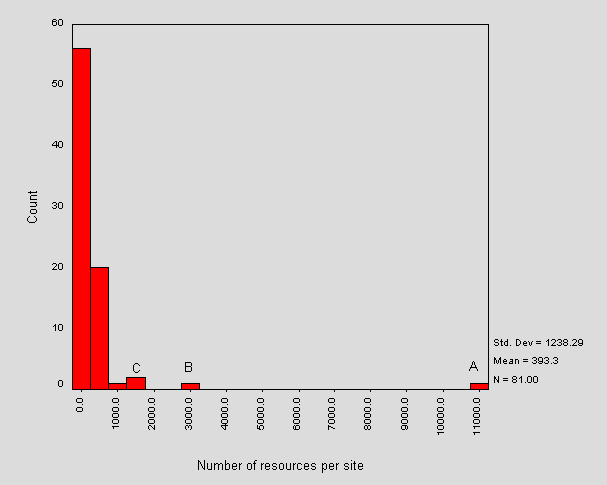
Figure 1 - Distribution of number of resources per site
Note that a majority of sites have less than 2,000 resources under the initial path. The mean number of resources per site is around 393 and the most frequent number of resources is contained within the range 0-500. The outliers in Figure 1 are looked at further on.
The robot only follows resources available via hyperlinks from the entry point and so the summaries represent a users-view of the site. Any resources disallowed under the robots exclusion protoco would not be summarised (although 78% of sites (63) did not have a /robots.txt file). In total, 31,935 URLs were traversed. The domain names of these URLs correspond to the particular academic institution. The URL of most of the sites entered into the robots input file implied that the library shared space on a web server. In such a case, the robot based its traversal on remaining within the directory-path of the entry-point URL. For example, the site http://www.bath.ac.uk/Library/ would be summarised for resources underneath /Library/. This applies to inline resources also, for example, a library site may include an image from a server-wide directory of images that would not be summarised.
Around 10% of the input URLs implied that the library site ran on its own server (though this could physically share a machine). These are shown in Figure 2.
| www.lib.cam.ac.uk |
| www.lib.uea.ac.uk |
| libwww.essex.ac.uk |
| libweb.lancs.ac.uk |
| libweb.lancs.ac.uk |
| rylibweb.man.ac.uk |
| oulib1.open.ac.uk |
| www.lib.ox.ac.uk |
| www.library.sunderland.ac.uk |
| www.lib.ed.ac.uk |
| www-library.st-and.ac.uk |
| www.lib.strath.ac.uk |
| libweb.uwic.ac.uk |
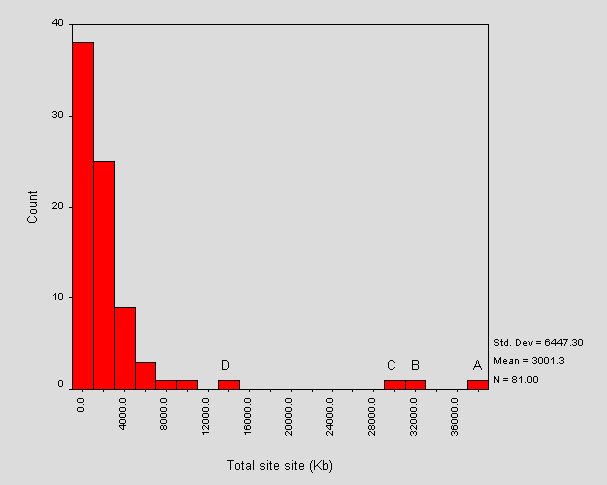
Figure 3 - Distribution of total size of sites
Figure 3 initially shows an unbroken decay, which corresponds to the majority of sites. Further on there are four disconnected bars, the larger three of these contain significantly more content. The largest site analysed (labelled A in Figure 3), is at the University of Salford. It is 39,039Kb (38Mb). This site shares space on the institution's main web server and contains a wide range of information services material (including IT information). Site B is at the University of Aston and has size 31,137Kb (30Mb). This site contains general library and information material. Ths site is on a shared server and is merged with the institution's IT information point. The third outlier, C, is at the University of Manchester and corresponds to a site with its own server. The information contained on it is purely library-related. Outliers A and B of Figure 3 correspond to outliers A and B of Figure 1, i.e. the larger sites contain more resources. Outlier D in Figure 3 is part of the unbroken section of the histogram in Figure 1 (there is another site containing more resources that is within the unbroken section of Figure 3).
The mean size of an academic library web site is around 3Mb. The bars within Figure 2 have width 2000Kb, which indicates that almost half of the site sizes are within the range 0-2000Kb (0-2Mb). The site containing the least content (consisting of one page of HTML) had a total size of just over 4Kb and corresponded to a server at Roehampton Institute London.
The entry points of the smallest five sites are shown in Figure 4.
| URL | Size (Kb) | #HTML | #images |
| http://www.roehampton.ac.uk/support/library/lms.html | 4.3 | 1 | 0 |
| http://www.tasc.ac.uk/lrs/lrs3.htm | 7.9 | 5 | 0 |
| http://www.sihe.ac.uk/Library/Library.html | 9.0 | 1 | 1 |
| http://www.library.sunderland.ac.uk/default.asp | 10.4 | 1 | 0 |
| http://www.mdx.ac.uk/ilrs/lib/libinfo.htm | 20.2 | 14 | 0 |
Figure 5 shows the HTML and image components of Figure 3.
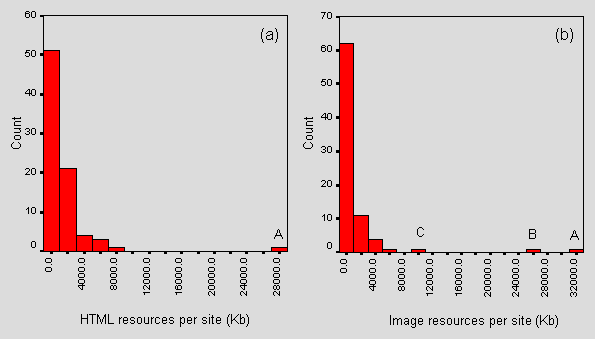
Figure 5 - Distributions of total HTML size and total image size
The mean size of the HTML content of a site is around 3411Kb. We found a range from 1.5Kb to 28Mb. More than half of the sites contain under 2Mb of HTML.
Note that the image distribution is more broken than the HTML distribution suggesting that sites are more characterisable in their image size profiles than HTML size profiles. The mean total amount of image data per site is around 1.5Mb and a majority contain under 2Mb of image data. We encountered a range from 0Kb (i.e. containing no images under the entry-point path), of which there were 8 cases, to 31Mb.
The HTML size outlier (Figure 3a label A) does not correspond to any of the image size outliers (Figure 3b labels A-C). The correlation coefficient for the two sets of sizes is 28% (a fairly mild correlation). The furthest two image outliers (B and C) correspond to the outliers A and B of Figure 2. A preliminary inspection also indicates that bars to the right in Figure 3b tend also to be to the right in Figure 2. The HTML outlier corresponds to outlier B in Figure 2, but to none of the image outliers. We can conclude that the larger sites overall tend to contain a larger image content.
Figure 6 shows the HTML and image components of Figure 1.
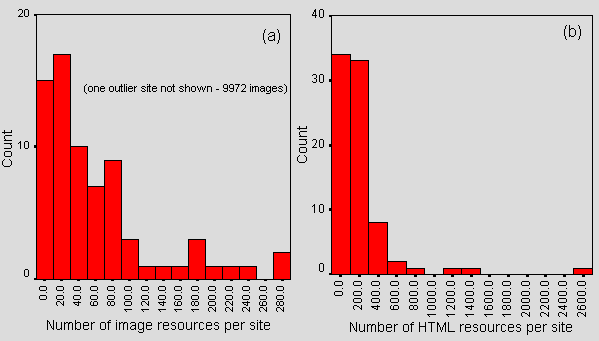
Figure 6 - Number of HTML and image resources per site
There are, on average, 217 pages of HTML and 196 images per site (skewed by a couple of sites with many images - the standard deviation is 1162). Over 90% of sites have less than 400 pages of HTML and all but five sites have less than 200 images.
The mean size of an academic library HTML document is 6.5Kb (with standard deviation 4Kb). The distribution is nearly symmetric between 0Kb and 9Kb (the full range is 0-22Kb) and the modal value with intervals of width 1000 bytes is the range 3,500-4,500 bytes.
The mean size of an image from an academic library web site is 15Kb (with standard deviation 22Kb). The distribution decrements unbroken from 0-60,000 bytes (0-59Kb) and then becomes broken up. The modal value with intervals of size 10,000 bytes is the interval 0-10,000 bytes (0-10Kb).
Figure 7 shows a list of percentage correlation coefficients between counts of resources within a site and site size.
| Correlation sets | % Correlation |
| Number of HTML resources and total size of HTML | 91% |
| Total size of image resources and total size of site | 86% |
| Number of HTML resources and total size of site | 81% |
| Number of image resources and total size of images | 77% |
| Total size of HTML resources and total size of site | 73% |
| Number of image resources and total size of site | 64% |
| Number of image resources and number of HTML resources | 23% |
From Figure 7, we can see that there is a high correlation - 91% - between the number of HTML documents within a site and the total filesize of HTML resources for that site. This seems logical, however it is interesting to compare the analogous case for image resources which is lower at 77%. These percentages imply that HTML resources within a site tend to be more bounded in terms of their size than the image resources. We can also see that the size of all image data correlates quite highly with the total size of a site (86%) and that the analogous metric for HTML is lower at 73%. This would imply that the total size of a site is more dependent on its image content an its HTML content (images are usually bigger). It is interesting to note that there is a relatively weak correlation between the number of image resources and number of HTML resources (averaged over all the sites looked at). This could imply that most pages do not fit into a standard template, however multiply referenced images within a site are indexed only once. See HTML analysis below for a more in-depth look at images.
An academic library web page contains on average 0.5 of an image, with a standard deviation of 1.33. On average, almost all HTML documents include less than 2 images. Since each index was indexed only once as it is found, this figure could be misleading. However, since client-side caching will cache each image this figure could represent the total downloaded resources.
Given the means calculated above, the mean size of an academic library web page complete with inline images is 11Kb.
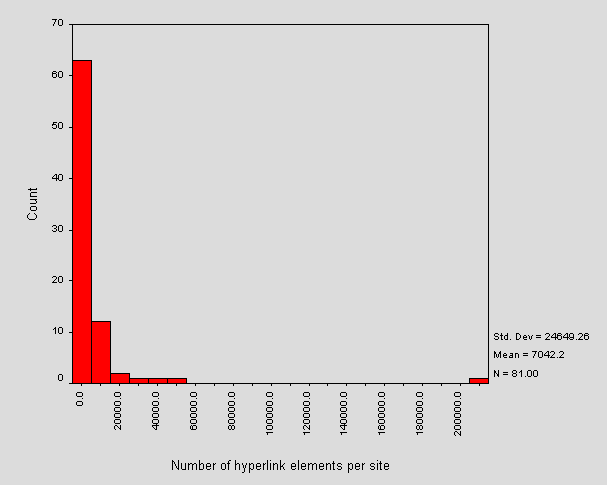
Figure 8 - Number of hyperlinks per site
The outlier is the server at Aston University and so corresponds to outlier B in Figure 3 and this skews the mean. On average, around 99% of HTML documents within an academic library site will contain the HTML elements that provide hyperlinking. Figure 9 shows the distribution of mean number of hyperlinks per document.
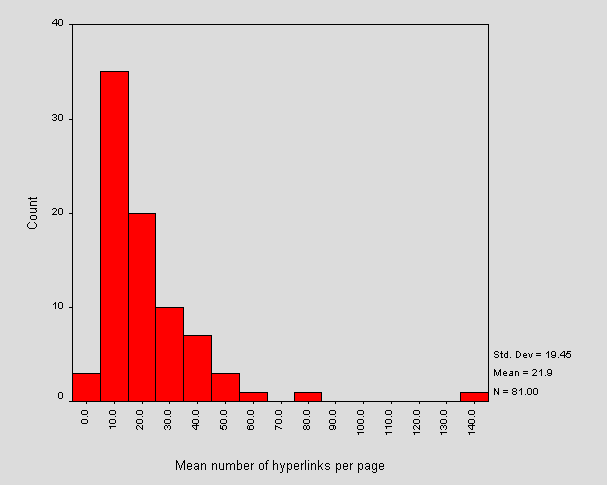
Figure 9 - Mean number of hyperlinks per document
The mean number of hyperlink elements per document is about 22 and the most frequent the interval 5-15 hyperlinks.
The URLs referenced in the hyperlinks were also profiled. For those URLs followed by the robot (i.e. within the site and under the entry-point path) the mean number of characters in a path is 25. More generally, an average 38% (with standard deviation 21%) of hyperlink URLs were qualified with http://. The distribution of this is approximately symmetric about 35% (the modal value); on average 1% of these URLs contained # and 14% contained ?. For those that were not http:// prefixed, around 2% contained # and under 1% contained ?.
The Internet addresses used in the URLs were analysed. We extracted the server name and performed a reverse DNS lookup for IP addresses. The text to the right of the final '.' within the result was used to determine the domain of the server. Figure 10 shows the top five domains.
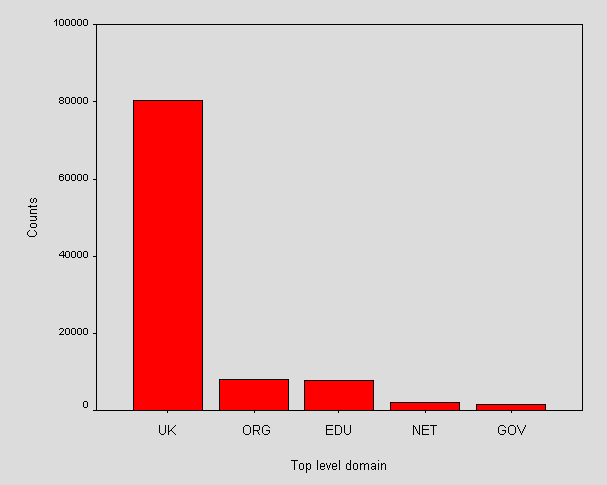
Figure 10 - Top five hyperlinked domains
With the approach that the UK domain is geographically within the UK and that packets are not routed via another country, the chart indicates that this web community will generate traffic mostly within the UK. This may be significant when transatlantic bandwidth is charged for.
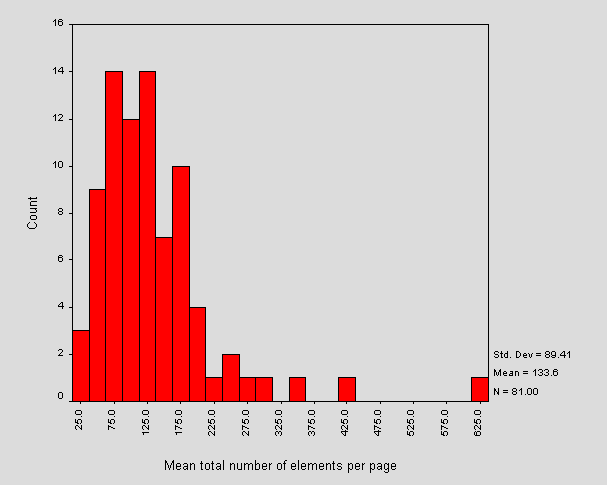
Figure 11 - Mean total number of elements per HTML page
The mean number of elements per page is around 134.
Interestingly the furthest outlier in Figure 11 does not correspond to any of the site size outliers in Figure 3, endorsing the earlier idea that the outliers of Figure 3 tend to be as a result of images. It does in fact correspond to the 8000 bar in Figure 5a. This site contains the greatest number of elements per page (on average) but this does not make it the site with the most HTML. However, the correlation coefficient between the mean total number of elements per page of HTML and the total site HTML content is 98%.
Figure 12 shows the mean number of unique elements per page of HTML.
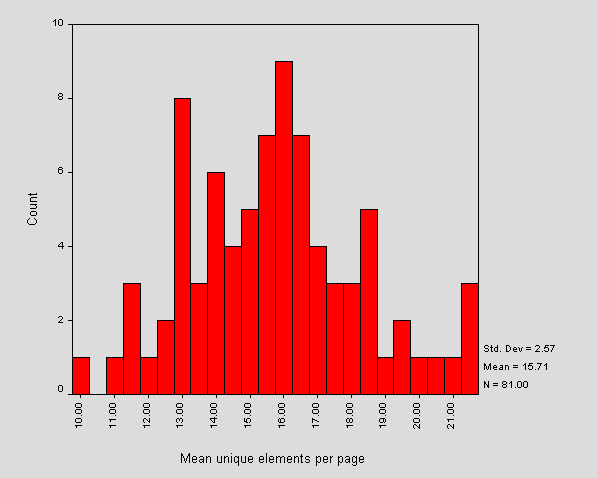
Figure 12 - Mean unique number of elements per HTML page
Comparing to Figure 11, we see that the mean of the average number of elements per page is around 16 which is also the modal value. Note that the outlier in Figure 11 has no representation in Figure 12. The distribution in Figure 12 is more symmetric and approximately normal than that of Figure 11. This indicates that the number of unique elements per page is likely to be bounded. In the future it will be interesting to compare a case of XML.
In contrast to the previous calculation on the mean number of images per page we also counted the number of image tags per page. Figure 13 shows the distribution of the mean number of images per page per site.
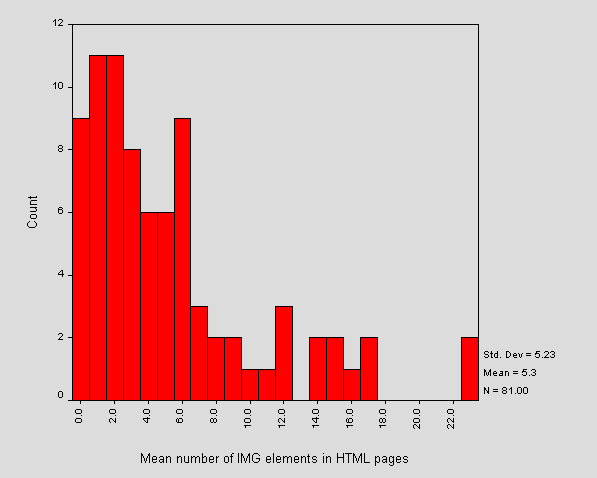
Figure 13 - Distribution of mean number of images per page per site
Figure 13 characterises individual sites in their overall use of the IMG element. We can see that the average number of images over all sites is around 5. There is variation, but sites seem to stick within bounds (as seen by the small number of bars of height 1 count). The most frequent number of IMG elements per page is between 0.5 and 2.5.
These figures contrast with the previous calculation that there is, on average, 0.5 of an image corresponding to each page. Since the first analysis was based on number of image resources, rather than number of tags, we could deduce that image replication accounts for an average of almost 5 images per page. Client-side caching of images could therefore result in saving 75Kb of download data.
From our previous conclusions of image sizes and total size of site we might guess that the right outlier in Figure 13 is one of the larger sites, since the larger sites are dominated by large image resources. This is not, in fact, the case and we conclude that this outlier includes the same images a number of times. This could suggest that the pages are written within a standard template.
Note that these figures are averages across each site - there is variation within each site. The page with the most IMG tags across all site contained 499 and this site corresponds to the largest outlier of Figure 3. The mean maximum across all sites is 23.
Each page of HTML retrieved was validated against an HTML 3.2 DTD using nsgmls [2] and the output stored. Only 12% of HTML pages validated with no errors. Although some sites contained compliant HTML documents, no site contained only compliant documents.
Within each HTML element, the following event handlers were looked for, onBlur, onChange, onClick, onFocus, onLoad, onMouseOver, onSelect, onSubmit and onUnload. 22% of sites used event handlers to some extent. The findings are shown in Figure 14.
| Handler | #Occurrences | %Sites using [count] |
| OnBlur | 0 | 0.0% [0] |
| OnChange | 1 | 1.1% [1] |
| OnClick | 66 | 7.4% [6] |
| OnFocus | 0 | 0.0% [0] |
| OnLoad | 10 | 6.2% [5] |
| OnMouseOver | 1013 | 13.6% [11] |
| OnSelect | 19 | 3.8% [3] |
| OnSubmit | 17 | 3.8% [3] |
| OnUnload | 0 | 0.0% [0] |
Further analysis shows that 22% of sites use event handlers.
Figure 14 shows that no use was made of the onBlur, onFocus or onUnload handlers. The most popular event-handler was onMouseover with 1013 occurrences over 11 sites. Figure 10 shows that this event-handler is used multiply on pages.
21% of sites (17 sites) made some use of the SCRIPT element. Where this tag contained attributes it was invariably language=JavaScript or language=JavaScript1.1.
Only one of the analysed referenced a Java applet with the APPLET element. There were no cases of technologies being included with the EMBED element or the OBJECT element.
Use of the META element was analysed. We specifically looked for the attributes shown in Figure 12 (case insensitively and accounting for the use of single and/or double quotes).
| HTTP-EQUIV = CONTENT-TYPE | Used to specify the MIME type and character set of the document |
| HTTP-EQUIV = DC.* | Used to include Dublin Core metadata |
| HTTP-EQUIV = REFRESH | Used to tell the server to update the page |
| HTTP-EQUIV = PICS | Used to include PICS content-ratings |
| HTTP-EQUIV = REPLY-TO | Used to include an author email address |
| NAME = GENERATOR | Used to indicate software used in creating the page |
| NAME = DC.* | Used to include Dublin Core metadata |
| NAME = AUTHOR|DESCRIPTION|KEYWORDS | Used to include search-engine type metadata |
The META element applications are not mutually exclusive (this is illustrated in Figure 17). We found that 40% of sites used no search-engine type metadata within their whole site, 27% included no Generator and 35% included no Content-type. A small number of sites used Refresh (7%), DC (6%), Reply-To (1%) and PICS (1%).
Figure 16 shows the percentage of all pages using various META attributes.
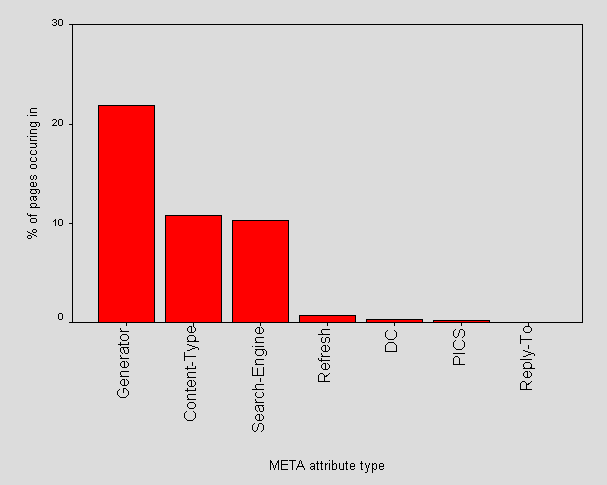
Figure 16 - Percentage of all pages using various META attributes.
72% of sites (59) made some use of the Generator attribute, and across these sites Generator appears in 38% of pages. 61% (49) used Search-engine type metadata which occured across these sites in 28% of pages. 57% (46) used Content-Type across 24% of their pages. Refresh was used in 4% of sites (6) and across these sites was used in 4% of pages. Dublin Core was used by 6% of sites (5) and was used within 5% of the pages of these sites. PICS was used by 1% of sites (1 - EHCHE).
Figure 17 shows how pages simultaneously use the META element.
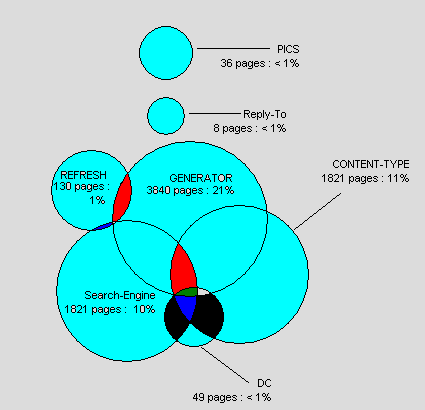
Figure 17 - Simultaneous uses of the META element
Figure 18 shows a chart of the servers encountered.
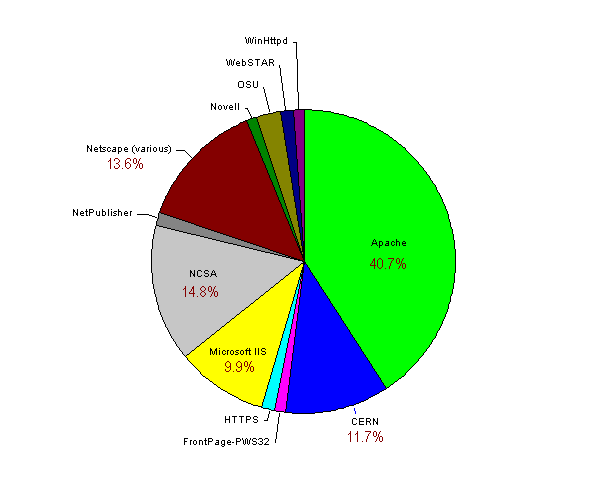
Figure 18 - Breakdown of HTTP servers
Apache is most popular by a large margin, which probably suggests that UNIX is the most popular operating system (we found nothing within the headers to suggest that it was apache on another OS). The categories shown in Figure 19 represent supersets of the servers (the server name). The server field also contains a version number and any extensions, such as FrontPage extensions. Figure 16 shows the fully qualified server field for that occured more than once.
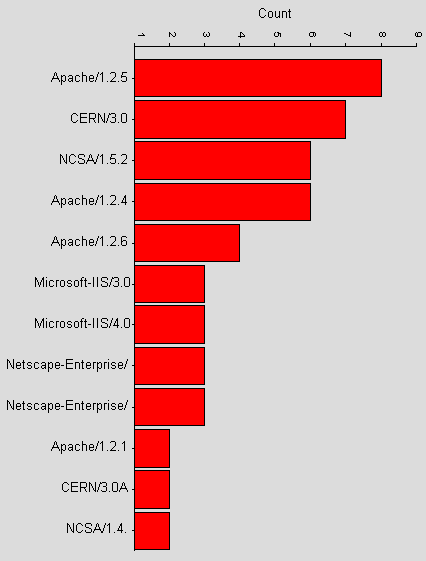
Figure 19 - Recurring HTTP server versions
The multiple Netscape-Enterprise bars refer to Netscape-Enterprise 2.01 and Netscape-Enterprise 3.0 (we also noticed individual cases of 3.0J and 3.0F which are not included).
Only apache had extra information other than version and included UUOnline-2.0, mod_perl, PHP-FI-2.0 and FrontPage/v3.0.x.
There was no indication in any of the server headers as to the platform/operating system that the server runs on other than the fact that some servers only run on certain platforms (e.g. Microsoft IIS). We can infer the potential use of HTTP/1.0 or HTTP/1.1 from the servers used.
The HTTP caching headers Etag, Last-modified and any header of the form Expir* were looked for. Figure 20 shows the percentage of resources (images and HTML documents) per site that contained one or more of these headers.
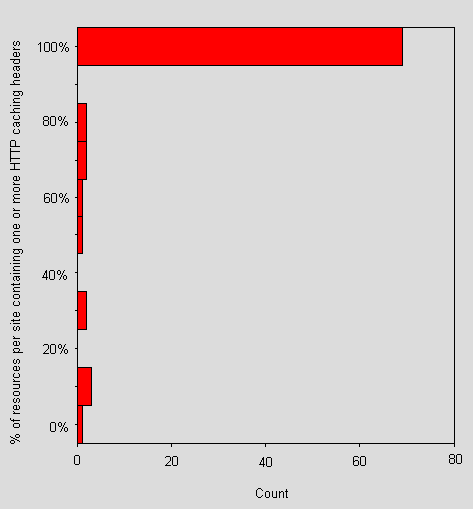
Figure 20 - % of resources per site containing one or more HTTP caching headers
Figure 20 shows that a majority of sites include one or more of the above headers. A closer examination reveals that 36% of sites have more than one such header in their HTML and a fraction more have more than one in their image headers. There doesn't appear to be any great bias in attaching caching headers to HTML or image resources. Although 37% of sites has slightly differing ratios of Cachable HTML/Total HTML to Cachable images/Total image, the mean difference across sites is only 0.1%. This is probably related to the high use of apache, which automatically includes some caching headers.
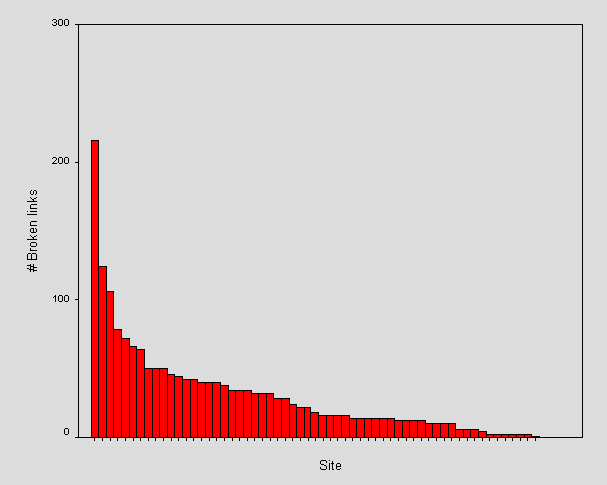
Figure 21 - Broken links across sites
The first few sites with the largest number of broken links do not correspond to the largest sites.
The sites that appeared within the input file but not in the final analysis were either dropped, due to dynamic content which confused the robot, or else at the time of crawling the entry-point could not be contacted.