This page gives a summary of some of the technical papers given at the 7th International World Wide Web Conference, together with some personal observations.
A total of 54 Technical Papers were included in the proceedings for the WWW 7 conference. These were spilt into the categories given below. Note that where I attended the session or have an interest in the area I have indicated that my comments on the paper are available.
The papers were available at <URL: http://www7.conf.au/programme/fullprog.html>
Three papers were given in this session. I attended this session.
Specifying Metadata Standards for Metadata Tool Configuration (Andrew Waugh of CSIRO, Australia) was an excellent paper which argued that a generic metadata editor was needed in order to minimise the costs of creating and maintaining metadata. He proposed use of an editor which could read a metadata schema and so could be used to create a variety of metadata including Dublin Core, ANZLIC and GILS. The PrismEd editor was described as an implementation if this idea. PrismEd is a Java application which was available at <URL: http://mel.dit.csiro.au:8080/~ajw/schema/editor.html>.
The paper was available at <URL: http://www7.conf.au/programme/fullpapers/1913/com1913.htm>
The Limits of Web Metadata and Beyond (Massimo Marchiori, MIT) describes how "fuzzy" techniques can be used to automatically generate metadata for existing resources. The methodology was tested using a PICS-based classification system and the URouLette service for producing random URLs.
The paper was available at <URL: http://www7.conf.au/programme/fullpapers/1896/com1896.htm>
Structure Graph Format: XML Metadata for Describing Web Site Structure (Liechto et al, Hiroshima University) gave a paper which described the use of site maps based on linking and directory structures. The Structured Graph Format (SGF) was proposed as an XML application for defining the structure of a website. The SGMapper application demonstrates use of SGF.
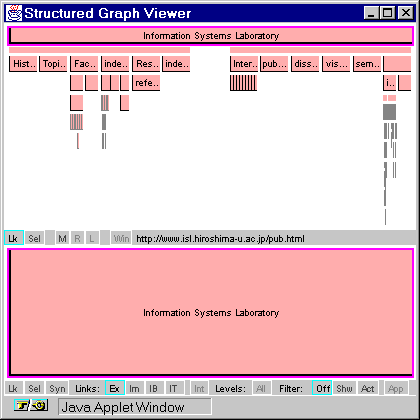
Figure 1 - The SGMapper Application
The paper was available at <URL: http://www7.conf.au/programme/fullpapers/1850/com1850.htm>
Further information on the work, including a demonstration of a Java applet, is available at <URL: http://www.isl.hiroshima-u.ac.jp/projects/SGF/>
Three papers were given in this session.
Automatic Resource Compilation by Analyzing Hyperlink Structure and Associated Text (Chakrabarti et al, IBM and Universities of California and Cornell) described an automated resource compiler (ARC) for cataloguing Internet resources into lists similar to Yahoo. ARC uses the concept of authority pages (which contain a lot of information about the relevant topic) and hub pages (which contain many links related to the topic). These pages are used to refine the results from searches of Alta Vista.
The paper was available at <URL: http://www7.conf.au/programme/fullpapers/1898/com1898.html>
Automated Link Generation: Can We Do Better Than Term Repetition? (Green, Macquarie University, Australia) describes a technique for the automated production of hypertext links based on semantic relatedness rather than structured term repetition.
The paper was available at <URL: http://www7.conf.au/programme/fullpapers/1834/com1834.htm>
WSDM: A User Centred Design Method For Web Sites (De Troyer and Leune, Tilburg University, Netherlands) proposed a design methodology for kiosk-based web services. The methodology is "user-based" rather than "data-driven".
The paper was available at <URL: http://www7.conf.au/programme/fullpapers/1853/com1853.htm>
Inquirus, the NECI Meta Search Engine (Lawrence and Giles, NEC Research Institute) describes an algorithm for a metasearch engine which improves on the results obtained from using Alta Vista directly by post-processing the results set. The parallel architecture of Inquirus means that it is quick at parsing results. The paper concludes that "real time analysis of documents returned from web search engines is feasible."
The paper was available at <URL: http://www7.conf.au/programme/fullpapers/1906/com1906.htm>
The Anatomy of a Large-Scale Hypertextual Search Engine (Bran and Page, Stanford University) describes Google, a prototype large-scale search engine containing 24 million pages. Google has been developed as an architecture which can support novel research techniques on large-scale Web data. Since the large-scale search engines are commercial services, details are not readily available. The work at Stanford University is intended to provide an understanding of issues within the public domain.
Google makes use of linking information on web resources to calculate a quality rating which is used to improve search results. For example a web resources has a high Page Rank if many pages point to it or if pages that point to it have a high Page Rank.
Note that this technique can be used to search for resources which have not been trawled (e.g. Postscript files and images).
Use of the Google service and feedback is encouraged.
The paper is available at <URL: http://www7.conf.au/programme/fullpapers/1921/com1921.htm>
Google was available at <URL: http://google.stanford.edu/>
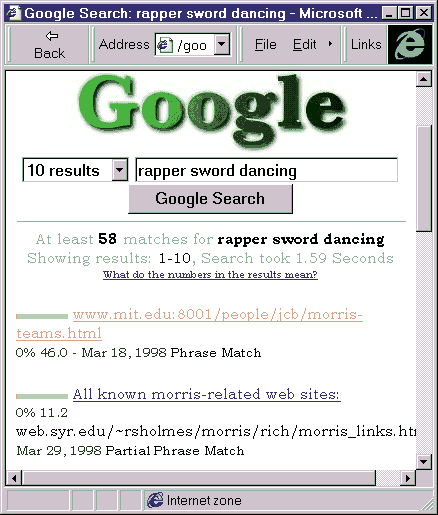
Figure 2 - Google
Full-text Indexing of Non-textual Resources (Bryers, Linkopings University, Sweden) described a technique for provided a text version of resources for indexing by robots. An unformatted text version of a PostScript file can, for example, be served to a robot. The end user, when following a result from a search will be presented with a menu page which contains a pointer to the Postscript version.
The paper was available at <URL:http://www7.conf.au/programme/fullpapers/1870/com1870.htm>
Efficient Crawling Through URL Ordering (Cho et al, Stanford University) described a technique which web indexing robots could use when deciding which resources to index. As with a number of other papers it proposed making use of link information.
The paper was available at <URL:http://www7.conf.au/programme/fullpapers/1919/com1919.htm>
A Regional Distributed WWW Search and Indexing Service - the DESIRE way (Ardo and Lundberg, Library of Denmark and Lund University, Sweden) described the DESIRE project. The Nordic Web Index provides a regional index of web resources in the Nordic countries.
The paper was available at <URL:http://www7.conf.au/programme/fullpapers/1900/com1900.htm>
The Nordic Web Index is available at four locations including an English version at <URL: http://nwi.dtv.dk/uinwi/index_e.html>
There were three papers in this session. One is described below.
An Extensible Rendering Engine for XML and HTML (Ciancarini et al, Bologna University) describes how Java can be used to provide browser support for new HTML / XML tags using Java applets known as displets. An example is shown below:
<APPLET archive="displets.zip"> <PARAM NAME="def" VALUE = " <TAG name='reverse' src='reverse.class'> </TAG> "> .. <P>This text is displayed as <REVERSE>white text on black>/REVERSE>
Information, including access to the Displet Java code is available at <URL: http://www.cs.unibo.it/~fabio/displet/>
I did not attend Session 1. I chaired Session II in which the following papers were presented.
The Shark-Search Algorithm. An Application: Tailored Web Site Mapping (Hersovici et al, IBM) described work which built on work described at the WWW 5 conference two years ago.
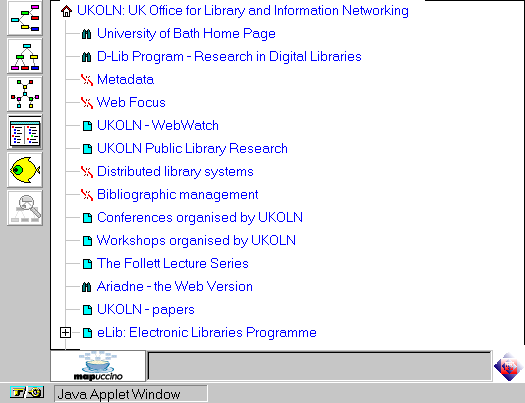
Figure 3 - The Mapuccino Interface
The paper described the refinement of the "fish-search" technique for client-side searching of web resources. This technique was developed by P De Bra to provide searching of a server cache. The technique has been refined to support "fuzzy" searching. The Mapuccino service has been developed based on this technique. Using Mapuccino it is possible to search a Web service such as Yahoo. Links will be followed if the fuzzy-matching criteria is satisfied (e.g. the link anchor satisfies the search criteria.).
The paper was available at <URL:http://www7.conf.au/programme/fullpapers/1849/com1849.htm>
Mapuccino is available at <URL: http://www.ibm.com/java/mapuccino/>
Figure 4 illustrates a view of the UKOLN web site following a search for "British Library".

Figure 4 - The Mapuccino Interface
WCP - A Tool For Consistent On-line Updates of Documents in a WWW Server (Rangarajan et al, Lucent Technologies and Infosys Technologies) described a tool for managing the updates of multiple related HTML documents. The tool updated the server configuration file to redirect requests to a consistent set of files until the updates had been completed.
The paper was available at <URL: http://www7.conf.au/programme/fullpapers/1858/com1858.htm>
Comments on 2 of the 4 papers in this session are given.
In the paper What is A Tall Poppy Among Web Pages? (Pringle et al, Monash University) the author described how the main web search engines were "reverse engineered" in order to derive a model of how they rank resources they index. They analysed the results of a variety of searches, based on popular search terms, as identified by the Magellan "voyeur" page (see <URL: http://voyeur.mckinley.com/cgi-bin/voyeur.cgi>)
From the results of their work they developed a set of decision trees for the search engines. They concluded that Excite had the most complex decision tree.
The paper was available at <URL:http://www7.conf.au/programme/fullpapers/1872/com1872.htm>
In the paper A Technique For Measuring The Relative Size and Overlap of Public Web Search Engines (Bharat and Broder, Digital) the main search engines were again analysed, this time to estimate their coverage of web resources and the extent of overlap of the search engines. This was the first attempt to measure the coverage and overlap of search engines.
The paper concluded that in November 1997 the total size of the static web was 200 million pages, with Alta Vista indexing 100 million pages, Hot Bot 77 million, Excite 32 million and Infoseek 27 million. Search engines index only 160 million pages.
The paper was available at <URL:http://www7.conf.au/programme/fullpapers/1937/com1937.htm>
Comments on 1 of the 2 papers in this session are given.
In the paper Intermediaries: New Places for Producing and Manipulating Web Content (Barrett and Maglio, IBM) the authors introduced the term intermediaries which enable new functionality to be introduced to the web without extended the client or the server. Intermediaries can be implemented by using proxies which can be used for a variety of applications such as web personalisation, document caching, content distillation and protocol extension.
An example of an intermediate can be seen from the WBI (Web Browser Intelligence) proxy service which is available at <URL: http://wwwcssrv.almaden.ibm.com/wbi>.
The paper was available at <URL: http://www7.conf.au/programme/fullpapers/1895/com1895.htm>
Comments on 1 of the 2 papers in this session are given.
Summary of WWW Characterisations (Pitkow, Xerox) gave a review of many summaries of web characterisation studies. The paper described the various techniques which can be used for web characterisation studies, including analysing client behaviours (which typically requires specialist client software), analysing proxies and gateways, analysing server logs and analysing web services (such as analysis of resources collected by the main Web search engines).
The author came up with several interesting observations which had been observed from more than a single survey:
| File sizes | Average HTML size of 4-6Kb and a median of 2 Kb. Images have an average size of 14Kb. |
| Site popularity | Roughly 25% of web servers account for over 85% of the traffic. |
| Life span of documents | Around 50 days. |
| Occurrence of broken links when "surfing" | Between 5-7% of requested files. |
| Occurrence rate of redirects | Between 13-19% of requested files. |
| Number of page requests per site. | Heavily tailed distribution with a typical mean of 3 and a mode of one page request per site. |
| Reading time per page. | Heavily tailed distribution with an average of 30 seconds, median of 7 seconds and standard deviation of 100 seconds. |
The paper was available at <URL:http://www7.conf.au/programme/fullpapers/1877/com1877.htm>