William Yeo Arms
Corporation for National Research Initiatives, USA.
Introduced by Charles Oppenheim
Monday 11th September 1995
It is a great pleasure for somebody of Welsh background, who was brought up in England, but now lives in the United States, to give the first Follett Lecture in Scotland. This evening, I want to talk about the research in digital libraries that is happening in the United States, not so much for the research itself but to describe the process and the impact that it is having on the future of libraries around the world.
Let me give a bit of background. Almost all my working life has been in universities. Since I began as an undergraduate in 1963, I always worked for organisations that had good traditional libraries, until January this year. In January, I started a new job in an organisation that has no library. Yet I am now more active in research than at any time since my days as a graduate student and a junior faculty member. I am reading more of the current literature, I am more up to date on what is going on, and writing more papers for other people to read. Yet my only library is the Internet. The Internet is the only library needed by somebody doing research in my fields of computer networks and digital libraries. Given a choice between the traditional library and the on-line library, there is only one choice; I would choose the Internet.
I now want to show you some on-line examples of services on the Internet that I use. They have been chosen to give a framework for the rest of the discussion. I shall start by showing you a few examples of my library on the Internet. I shall then talk about the technology behind them and the organisations behind that technology.
Before I begin my demonstrations, let me tell you about computer equipment I have here. I shall be running two applications on this computer. I have a slide presentation and an Internet connection. When I demonstrate the use of the Internet, there is a little bit of deception. I ran through the talk about an hour ago and looked at all the on-line examples that I will show you. In most cases, when I show them to you there will be copies of them already stored on this machine and I will not be fetching them from the United States of America again. I apologise for my deception, but actually the main Internet connection to the United States went down about an hour ago, so it is probably safer.
To begin with some examples from the World Wide Web, here is the CNRI Home Page. This is where our organization first publishes the work that we do, nowadays. If, for example, you want to find the development that we are doing at CNRI, on the Handle System, here is where you would look for it.
Th is particular paper is an overview of the system published by David Ely and myself a few months ago. We simultaneously posted it on the CNRI Web pages and submitted it to the Internet Engineering Task Force as an Internet Draft. By these two methods of publication, all our colleagues had instantaneous access to our work. A characteristic of both the World Wide Web and Internet drafts is that, with both methods of publication, neither version ever touches paper. The whole system of Internet Engineering publications is purely an on-line system. (Incidentally, you may notice that the secretariat for the Internet Engineering Task Force is based at CNRI.)
A year ago there were two general complaints about the information on the Internet, that that you c an never find things and there was never anything interesting. During the past year there has been tremendous development in both areas.
Our ability to find things on the Internet has been transformed by the introduction of Web searching programs. The program that I normally use is the Lycos program, which is an index to millions of pages of the World Wide Web.
Lycos was developed by a former colleague of mine at Carnegie Mellon University. It is one of at least five good systems that are now available. For example, I can search Lycos for references to "Follett". I will type the words "Follett Report" and hit 'enter'. Lycos returns a list of references that include those two words, ranked in order. When I tried this the other day, I was amused to find the synopsis of this very talk sitting there on the Web for everybody to read!
Over the past year, at least five major projects have indexed the Web. Lycos is one; the others are Yahoo from Stanford, Infoseek, Webcrawler, and Harvest. All except Harvest have now progressed from research to production; they are out of the initial research phase. A couple of months ago I searched for these five projects in Inspec, which is the standard indexing and abstracting service for computer science literature. I found no hits on any one of them. This field of research went though the entire cycle from first steps to completed research so rapidly that nothing was published in the normal traditional literature, during the whole cycle. If you monitored the traditional literature you would not have been aware of this entire area of research. This example shows how much the paper literature is irrelevant in these fast moving areas of research.
In passing, you will notice that Lycos has become a commercial service. The address is "Lycos.com". Yet it is still providing a no fee service, paid for entirely by advertising. When you do your search and get a result you receive a little advertisement, perhaps for Windows 95 or a similar product.
A year ago, the second general complaint about the Internet was that there was no good information on the network. That has changed. Today, almost all the major journals, magazines, and traditional publishers either have on-line products or are making attempts to develop some. For example, this next example is probably the best review of the Internet.
In July, "The Economist" had a special section of the Internet. They call it "The Accident al Superhighway". It is excellent and it is on-line, placed on the World Wide Web for the world to read.
I do not want you to think that my on-line library is synonymous with the World Wide Web, because I use many other sources of on-line information . Earlier, for example, I mentioned Inspec. Let me just show you an Inspec example. (This is not an on-line demonstration. Instead, I shall show you some screen dumps. This slide is an example of an Inspec search, but it has been edited slightly. I deleted some of the text because the screen was too cluttered to show on a slide, but the content is unchanged from the on-line system.)

This is output from the Mercury system, one of the early digital library systems, which we developed at Carnegie Mellon University in the late 1980s. As you can see, I have carried out a series of searches with a variety of keyword combinations, looking for information about preservation of acidic paper. The next screen shows an abstract that I found. This is an article about a joint project between Xerox Corporation and Cornell University.

Traditional library theory says that at this stage I should now say, "This is an exciting article. I will get a copy by Inter Library Loan." I may be unusual, but I never go to that next stage. Often all the information I want is in the abstract; on other occasions I know the author so that I can send electronic mail; on other occasions I use Lycos or other tool s to search for the author's Web pages; occasionally I look the author up in the directory.
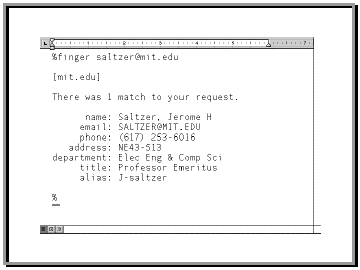
When I look people up in the directory I do not have a paper directory. I use an old Internet program, Finger. Here for example I 'fingered' a colleague at MIT. I typed "finger Salzer at mit.edu". The program replies that there is one match to my request, 'Jerome H. Salzer, Professor Emeritus of Electrical Engineering and Computer Science' .
I showed you these examples (and I could show many more) as a basis for what I want to talk about for the rest of this evening. To summarize, I have a very effective research library at my fingertips, that I am able to use from my office, at my home, over a dial -up modem from my lap top computer, or wherever I happen to be. As I am sure you all know, in most disciplines there is still a long way to go before the library is complete, but I hope you will accept that for some people, in some disciplines, the on-line libraries have already surpassed the traditional paper libraries.
I now want to pause slightly and state my fundamental premise for this evening. Within ten years the on-line library will be the standard research library in most disciplines. That is my premise. Within ten years the on-line library will be the standard research library in most disciplines.
I admit that, at present, only a few disciplines have reached this point. I am sure that many of you will question whether the date of t en years is too soon. However, the rate at which change is occurring is so fast that I am confident that within a very short period of time, in most disciplines, the standard on-line research library will be the on-line library. The change is fastest in well financed, current fields, particularly the sciences, technology, medicine, law, and business, but I expect the same in many other disciplines. (A corollary to this prediction is a belief that the traditional paraphernalia of journals, with their indexing and abstracting services, will pass through a horrible, wrenching transformation.)
However, I do not want to spend more time talking about this prediction. Either you believe it or else you do not. If you do not, I doubt if I can persuade you to change your mind. I want to talk about how the technology behind the digital library is emerging, where the technology of today's Internet library has come from and where it is going.
The technical research being carried out today will shape the libraries of the next fifty years. A period that began five years ago and will finish five years in the future is likely to be the definitive period in librarianship for the next fifty years. So, if you are interested in t he welfare of libraries, you should be interested in this technology and the process by which it happens. Therefore, I will now look at the sources of some of this technology.

Let us look at the examples that I demonstrated and ask the question where do they come from. The first thing to examine is the Internet itself. The Internet was developed in a most un-American way, by centralised government activity. It was created in the late 1960s by ARPA, which is the Advanced Research Projects Agency of the Department of Defense. A group of people recognized a general purpose network as an interesting and valuable project. They worked through small organisations, such as BBN and ISI. Now that the Internet is so successful, it is remarkable how many people claim to have invented it, but I think that nobody would argue that the foundation was the ARPAnet which developed the idea of free-standing networks with routers, the various protocols, notably TCP/IP, the naming conventions, and so forth.
The ARPAnet ran out of capacity about 1984/85. Too many people were using it. The National Science Foundation then added money and leadership for a broad expansion. The NSF's initial focus was a backbone to connect the supercomputing centres that the foundation was then founding in the United States, but the NSF also provided money to support the development of regional networks. The development and success of the whole Internet really depends on the inspiration of a few very far-sighted programme managers at ARPA and NSF, and their willingness to put a lot of money on the table.
My first demonstrations were of the World Wide Web. The World Wide Web is one of a series of Internet information services that have been developed over the last five or seven years. The creative work was done at CERN in Geneva; I assume that the funding for it came from European governments, since I assume most of the funding for CERN comes from them. I have heard that the origins of the World Wide Web were a project for internal management of documents at CERN.
The World Wide Web made steady progress, but its breakthrough came in 1993, with the introduction of a user interface known as Mosaic. This was developed at the University of Illinois supercomputing centre. The combination of Mosaic, the World Wide Web, and the Internet created the technology for the on-line library that I use. The Illinois Supercomputer Centre is a National Science Foundation centre. Their core funding comes from the NSF. For the Mosaic developments, they also had funds from ARPA, the same funding agency that supported the early developments of the Internet.
In my demonstrations, I did not actually use Mosaic. I used Netscape. Some of the people who did the original Mosaic work left the university and set up a small corporation called Netscape which a year later went public. Its initial market capitalisation was over a billion dollars. Some might say that this shows the spirit of the South Sea Bubble is yet alive in the United States of America, but actually it has been a fantastic example of work that went from an academic development to very widespread use in a short space of time.
Let me continue my survey of the sources of technology. The Lycos system, which I use to search the Web, was developed by basically one person, a member of the Center for Machine Translation at Carnegie Mellon University. I know something about Lycos because we were able to help him with some funding through an ARPA project of which I was a principal investigator. He developed the Lycos system during spring and summer 1994. Now he has sold the system and, with licence fees from Microsoft and others, I assume that he has a pretty sum of money to put in his pocket. Once again, it was ARPA money provided to an already well funded computer science research lab that enabled Lycos.
The Mercury project, which I showed as an example at the end of my demonstration, was an earlier project. Its funding shows the same trend. It was developed by our group at Carnegie Mellon, another well funded group, with grants from the Pew Foundation, a private charitable foundation, and Digital Equipment Corporation.

The pattern that you see here is, I think, very important. Some of the observations may be a little bit surprising. First, large corporations had little to do with the development of the underlying concepts of the Internet, the World Wide Web and the major services. I do not want to belittle the contribution of IBM and MCI in establishing the NSFnet, or Digital Equipment in providing money for university research, but fundamentally all the initiatives here came from academic or research labs, from individuals and small companies, including the companies that they founded after the basic creative work had been done.
The second observation is that most of what I have described is now international standard, but the work was done first, became a de facto standard, and then became an official standard later. One of the factors that holds up European developments is working on standards too early. The American system seems much better. Typically, individuals go their own way and then try to persuade the world to accept their ideas as standards.
A final observation, which is rather scary for those of us who have worked in libraries or who work with publishers, is that librarians and publishers have had little part in any of these technical developments. They have used the technical tools when they have come along, but did not develop them.
The conclusion is that the new library is being created by people who belong to large well funded technical research groups; they are being created by scientists, physicists, computer scientists - technical people in other words. Basically, they are developing the systems that they want for themselves. The traditional establishment is following the lead of these young, energetic, entrepreneurial, very well funded scientists.
Notice that I have used the term 'well funded' several times. We are talking about big science. The key developments are coming from the big teams, and individuals within the big teams.
Now, I do not want to imply that people from other disciplines are not involved in this work. In fact, one of the things that has been spectacular is how people from other disciplines, notably people from libraries, have seen the potential of these new systems and are building information services on top of them.
You might ask me the question do I think that it is good or do I think that it is bad for the fundamental design work to be done by technical people, who are building the systems that they want for themselves. Fundamentally, I welcome this pattern for academic libraries. These libraries are for the people who do the research to communicate it to the people who want to know about the research. When these researchers build the library they want for themselves they get good results. Over the years, I have be en in too many discussions with people who forget why we have scholarly publications. You will sometimes hear some publishers talking as though the object of scholarly work and scholarly libraries is to keep publishers in business. It is extremely important that scholarly publishers stay in business, but it is even more important to remember that they are in business to give a community of researchers and students what they want, not the other way round. So, basically, I welcome the way that things are being developed, but there are risks involved.
Now I want to move on. Most of the work that I showed in my examples was funded by the United States government. Therefore, if we want to look at where the next generation of digital library technology is coming from, one obvious place to look is where the United States federal agencies are putting their money at present. My next slide shows some current major activities. The focus is on activities of which the individual components are funded at the level of a million dollars a year or above, not the smaller projects, though nowadays a million dollars a year is not a large budget in scientific research.

The two funding agencies which have been involved all along, ARPA and the National Science Foundation, are both active in this field. (Part of my own salary is paid by ARPA.) ARPA is part of the Department of Defense, but ARPA believes that leading edge technology can contribute both to society and to defense. ARPA had a big three to four year project that is just coming to an end, the Computer Science Technical Reports Project. This has been a wide ranging project, much broader than the title implies. Some of the money used to fund Lycos, for example, came from that project. Another activity that I am currently involved with is also part of the Computer Science Technical Reports Project. It is with the Library of Congress's Copyright Office. The objective is to register digital objects for copyright.
You may have seen another major project reported on in the newspapers recently. This is the Digital Library Initiative. It is funded by ARPA, the National Science Foundation and NASA, which is the aeronautics and space administration. Together, the three agencies recently funded six big university based research projects in digital libraries. Those six projects are carrying out very broad research across a wide variety of areas. In each project, the principal investigators are scientists, computer scientists, or people with a technical background.
The national libraries are another important area where federal funds support the development of digital libraries. The Library of Congress and the National Library of Medicine have quite substantial projects which add up to a great deal of activity. Finally, one other place in the United States where there is major research that is not federally funded is OCLC, the library cataloguing consortium.
If the US Government is putting big money into digital libraries, and even increasing it at a time of tight budgets, somebody in the Government must think it is good to fund library research. The next two slides are pieces of Americana. They are two slides that were used for a White House briefing on library research. I think that they will strike you as a curious example of how the United States is different from Britain.

The first states why the US Government should fund digital library research. The title on this slide, 'Benefits for Society', is my addition, but everything below the title was clipped from White House briefing materials. High-quality information, available when and where it is needed, promotes an open democratic society, an educated and informed population, good information for economic and business decision making, dissemination of science and medical knowledge, effective government, social services and military information. A British presentation on the same theme would b e very different.

The second slide is also interesting. It argues that one of the reasons for carrying out digital library research is that digital libraries and electronic commerce are, from a computer science point of view, two of the most interesting, difficult, wide ranging and fascinating computer science problems to be tackled on large scale distributive network systems. This slide points out that electronic commerce and digital library technology have some things in common. You will note that this slide echoes the theme that digital library research is being done by people who do not come from a library or publications tradition. It is being funded by people who need to justify expenditure by criteria other than the justification that we normally use for the existence of libraries. In the United States, you can not ask for support for libraries for their own sake.

Now, let me look at some of the research areas that are currently very active. First, the development of digital collections. The collection development activities fall into two categories. Most of the work that has been done until now involves the digital equivalent of conventional materials. I have a couple of examples.
This is the home page of the Library of Congress. The Library of Congress is an organisation that combines considerable resistance to change with a surprising willingness to press ahead and do innovative things. They have a number of major projects. Earlier I mentioned the project to register digital objects for copyright. Another very interesting project has the imposing title of the "National Digital Library ". Really, it should be called the National Digitization Library. They are converting about five million items from traditional forms and formats into digital forms. The items include texts, manuscripts, audio tapes, maps, etc. The collections are chosen primarily from materials that are important to the American heritage. They include items of historic interest and value, people who were important in developing American culture, and so forth. This work at the Library of Congress is typical of the projects that are converting old materials and putting them on the computers.
Another group of projects are putting traditional journals on-line. This slide shows the Journal of Biological Chemistry. It is an experiment which is being run out of Stanford University. Personally I am not a great fan of these activities. I will tell you why. Something that was designed for production on paper has all sorts of design assumptions built into it that are different from a product that is designed as an on-line service. One of the many reasons the World Wide Web has been so successful is that it is primarily an on-line system. You can print things out if you want, but that is incidental. I, myself, am on the publication board of the ACM, the Association of Computing Machinery, and this is one of the problems that we are wrestling with. The publications board has been encouraging the ACM staff to think of the on-line version of the journals as the definitive version.
One of the problems in putting journals on-line is that traditional printing, coming from hot metal printing, uses an enormous range of character sets. Thus a chemistry journal may have thousands of symbols in it. Publishers have been working extremely hard to re plicate these symbols on a screen, but still the displays look cluttered and are not very readable. To be read on a screen, items need to be designed by people who are thinking about screens, not people who are thinking about paper and converting afterwards. One thing the Library of Congress does well is to have an excellent graphic designer who is a member of the team.
Before leaving the discussion of collection development let me mention another area which really interest me, the areas of collection development where the collection is made up of objects that you execute as computer programs. The object can be as simple as a data base; it can be a simulation; it can be an active agent that goes out looking for things on your behalf. In each case, there is no document-like equivalent. In this area there is some very good research going on. If I was giving three talks I would spend one of them talking about this area.

In the time that I have, I can only sketch the technical research that is going on in library research. There are two broad types of technical research. One area you can call, roughly speaking, enhancement to the World Wide Web. The World Wide Web is built is on very simple technology, brilliantly simple technology, technology that has achieved an enormous amount out of very simple primitive building blocks. All of the primitive building blocks need refinement, and some of them need complete replacement and change. Some of you were at Cranfield last week when I talked about this particular area. I talked about four categories of design decisions within the World Wide Web. In each case I believe that the decisions made were brilliant under the circumstances, but what is needed in the long term is something more powerful.
One is digital objects. What is in the digital library? What do we have in our digital library when we want to store objects that we can execute as programs rather than as documents which we display in fancy ways?
The next is how do we name things? Naming proves to be a very difficult and important topic. I do not need to tell librarians that. On the World Wide Web, things are fundamentally named by the location in which they are stored. Clearly over time that is not a good way to name things. You may want to move objects from one computer to another; you must be prepared for the owner of some information to move from one location to another. CERN for example, at one stage built up a big collection of on-line information and then decided not to be a World Wide Web service supplier to the world. Much of that information has moved to MIT. You want to have names that reflect what an object is, for instance, the manual for HTML version 1 .0, not an identifier that says that this object was stored on this particular computer in Geneva on the 1st August 1995. Earlier, I showed the title page of a paper on the Handle System, an Internet draft that David Ely and I had worked on. This is one of the pieces of work that is being done on naming systems. It is a system that we developed as part of the computer science technical reports project. We are using it on a number of major projects.
The third area is text. I talked a little about text in conjunction with the Journal of Biological Chemistry. How to handle text on computers is a difficult and interesting research area. There is much research being done in natural language processing; for example, automatic generation of abstracts. All the indexing programs I know of have at least some natural language processing in their background. (Lycos comes purely from that tradition.)
The fourth area that is extending the work of the Web is repositories and protocols. If you are going to look after information, you have to store it carefully and you have to have well-defined protocols for talking to those stores. The World Wide Web protocol, http, is very simple. Currently, there is a lot of discussion as to how to get over its weaknesses.
This ends my quick summary of technical areas that are extensions or enhancements to the World Wide Web. The other group of research topics go beyond the World Wide Web. What are the concepts that the World Wide Web does not have at all?
I have listed a few on the slide and will mention just one, the area of security, authentication, and protection. Security and protection may be very simple; for example, I might require that you do not quote me unless you quote me verbatim. Authentication is the question of proving that you are the person (or computer) that you claim to be. Security, authentication, and protection come together if people want their information services to be for money. You may have noticed that the Inspec search that I did earlier was the only time that I used information that was not publicly available and had to authenticate myself with an ID and password. One characteristic of our early Mercury project was that it had excellent distributed authentication security features, which we still miss from the World Wide Web. We need them.
The final technical area to mention briefly is archives. The traditional role of libraries is to keep things for a long time and to be able to preserve them and keep them available for use. Archiving and preservation of electronic information may be one of the most challenging of all tasks we have to solve over the next twenty years or so. Instead of having shops that sell rare books, we may have shops that sell rare PostScript interpreters.
Rather than talk about all of these technical areas in detail, let me mention a couple that I have been involved personally with. The first is another Carnegie Mellon project. It is called Netbill.
This slide is a World Wide Web page of a press release. Netbill is an interesting example of how research is done in the United States these days. It began as a series of student projects; I supervised two of them. Many of the fundamental ideas came from student projects to devise the equivalent of credit cards for Internet resources. To implement a large scale prototype, needed support from somebody with money. Netbill is now sponsored by ARPA and by the Visa Card group. Clearly Visa is not supporting Netbill because they are philanthropists who fund digital libraries. They are supporting it because they hope they will make money out of it.

This next slide a Web page is from Cornell. I mentioned the Computer Science Technical Reports Project. Cornell's contribution to this project was to build a prototype on-line library of computer science technical reports. It is an interesting project because they are looking at how you search a body of material that is scattered around many, many sites. In computer science today, technical reports are the primary way that research is first published. More and more, these working papers and technical reports are published by the individual computer science labs, departments, and so forth. The locally published material is where the real exchange of research ideas is taking place. A researcher needs a system to search all of these.
Netbill and the Cornell project are typical examples of important work that is going on at present. There is enough big money in the United States to support research in digital libraries that I expect to see a lot of very good work produced. An advantage of this high level of funding is that some very good people indeed are working in these areas. T he question is whether enough input is coming from the traditional information community. I do not know, but I believe strongly that the definitive work on the development of libraries is being done by these big scientific groups, funded by big money, typically American government money. They are shaping the next generation of libraries and librarianship.
Before I end, let me show you that not all news is bad news. I have with me a clipping from "The Washington Post" last Monday , a week ago. It is an article about public libraries in the area around Washington, including Maryland and Virginia. The headline is: "Libraries find life on-line is good for business and budgets." The article states that since libraries, particularly public libraries in Maryland, have provided computers attached to the Internet for their patrons, they are seeing at least a 25 percent jump in the number of people who come into their libraries. This is despite the fact that typically all they have is a single computer in each public library with a slow speed connection. The examples of use are really interesting. An area that is growing very fast is public access to medical information. One of the driving forces behind this was the Aids epidemic. Communities where there are many cases of Aids have built up Aids information services, with direct access for individuals.
Here we see a good examples of how this technology that was developed by scientific researchers for their own use is spreading out and making all libraries better for everybody. In the past, one of the great problems of research libraries was that they were physical places. If you have a reader's ticket to the British Museum Library you have access to a tremendous range of materials, but if you are in some remote place or if you do not have that reader's ticket you have no access to that material. As the major libraries put their collections on-line, they become available for everybody. Thus, although I have emphasised that t he work is being done by the research community for their own ends, the overall impact on libraries big and small is potentially a very, very good one.
I will end with just one last thing that I am personally leading. The funding agencies are concerned that their money be used well. There is always a tendency in scientific research for people to do research, write it up and then leave as they move on to new research. The National Science Foundation and ARPA are keen to see the money they are putting into digital libraries research produce results that people build on. We, at CNRI, have been given a pleasant task to coordinate the work that they are funding. Our charge is to make sure that the people working in digital library research who are funded by the various US Government initiatives talk to each other, share their expertise, and work together. This programme is called D-Lib.
My final demonstration shows part of this programme, "D-Lib Magazine." (You notice I d o not call it an "on-line magazine." I call it a "magazine," with the alternative being a "print magazine," This is important terminology.) The aim of this magazine is quite simple, we know that the people who work in library research come from an enormous range of disciplines; we are often quite horrified to find people who do not know about major digital library projects in fields slightly different from their own. There is no obvious conference to go to, no obvious place for people to publicise things. "D-Lib Magazine" comes out once a month. Its address is www.dlib.org. If you skim through it for ten minutes once a month, within a year you will know about all the major projects, and you will be fairly up to date in what is happening.
Let me show you a recent issue. You can see that we have some serious articles. Here is one on the Medical Library at the University of California in San Francisco. Here is a technical article about using wavelets to represent images. This article is about an notations and other rating information. At the bottom, we have clips and pointers to things that interest us and we think other people would be interested in. We also have, here, a technology playpen in which we encourage people who have developed new technology to tell us about it. You can try things out. We plan to build up a collection of technology in the playpen that will be a good place for people to experiment. I strongly recommend that everybody interested in these fields should read D-Lib Magazine. If you forget where to find it, you can search in Lycos and it will be there.
Let me end by repeating my main themes. Within a few years, I suggest ten years, the on-line library will be the standard research library in most disciplines. The technological research that is going on today will shape the library of the future for a very long time. We want to see as many knowledgeable and informed people involved in that research as possible.
wya
Revised, December 29, 1995