JISC IE Metadata Schema RegistryFunctions of the IE Metadata Schema Registry |
 |
![]()
JISC IE Metadata Schema RegistryFunctions of the IE Metadata Schema Registry |
|
![]()
| Home | Background | Dissemination | Contacts |
| Phase 1 | WP1: Project management | WP2: Model/Use | WP3: Tools | WP4: m2m | WP5: Validation | WP6: Policy | WP7: Evaluation |
A metadata schema registry is an application that provides services based on information about metadata vocabularies, the component terms that make up those vocabularies, and the relationships between terms [1]
This information about metadata vocabularies and their components is provided in the form of schemas. That is, schemas themselves are sources of metadata: the resources described by that metadata are metadata vocabularies and the terms within those metadata vocabularies. The services provided by a metadata schema registry are built on the aggregated data from many different schemas.
In a centralised architecture, the registry acts as the "repository" for this data, with schemas stored at a single location and made available from that central location through the services of the registry. In this model, tools for the creation of schemas may also be tightly integrated with the registry itself. While responsibility for maintaining the content of the schemas may lie with the owners, responsibility for the security and continued availability of the data lies with the central repository.
In a distributed architecture, the schemas are created and maintained by the owners of their content, and published to the Web in standard formats either by the owners or by a third party acting for the owner. The data is made available to many different applications, only some of which may be metadata schema registries. And responsibility for the security and availability of the schemas, as well as the maintainance of their content, lies with the owners (and/or publishers) of the data. The registry may serve as one point of discovery of, and access to, that distributed data, but the sources of that data are distributed on the Web. Many other applications may support discovery of, and access to, that data, or provide other services using that data. Under the distributed model, tools for schema creation may be offered by the providers of the registry service, but schema owners may choose to generate their data using their own preferred tools.
Because a registry works with the relationships between terms, and those relationships extend across the boundaries of a single schema, a distributed registry must aggregate the data from those distributed sources. A registry may obtain these distributed schemas by:
It may be important for the registry to track the provenance of the data it aggregates, so that it can present to users information on the source of the data it uses in its services, and when the registry last read/received a copy of that data.
The functions of the services provided by a metadata schema registry may vary, but might include:
Metadata schema registries may be designed to support different data models, but if a registry is to be based on data from distributed sources, it is essential that that data is based on a shared model. Establishing a shared model that can be applied across the two principal metadata standards used within the JISC IE, the Dublin Core Metadata Element Set and the IEEE Learning Object Metadata (LOM) standard is one of the challenges for the implementation of the IEMSR: Dublin Core is based on a model of simple statements about resources, whereas the IEEE LOM is based on a hierachical tree structure [2].
For example, the following applications are all RDF-based registries, but employ different models:
Finally, the users of the services provided by a metadata schema registry may be human beings or software agents i.e. in the terms of the JISC Information Environment architecture, a metadata schema registry may provide both unstructured and structured network services. The primary role of the shared services within the JISC IE is to provide structured network services i.e. the primary users of the IEMSR are other software components within the JISC IE.
The Joint Information Systems Committee (JISC) administers the provision of a wide range of digital content for use in higher and further education. That content is of diverse types (text, still images, maps, video, audio, datasets, software, learning resources) and is made available by different classes of content provider (individual educational institutions, sector-wide providers operated by JISC, commercial publishers, other public sector sources) and under varying different terms and conditions (open access, institutional subscription).
The JISC Information Environment is a "set of networked services that allows people to discover, access, use and publish" resources within the UK HE and FE community [10]. The JISC IE is not itself a single system or service; rather, it is a framework of services that can be used in combination as components to deliver functionality of interest to an end user. Furthermore, the environment is not a closed one: some of the service components used in the JISC IE to support educational users are also used to deliver services to other user communities.
Central to the concept of the Information Environment is the principle that service components are combined to deliver functions to a user. Indeed as many of the resources of interest are physical resources (books, paper documents), users frequently combine the use of digital services (discovering, selecting and locating an item by querying a library catalogue) and physical services (requesting and accessing the located item by using the reference or lending service of a library lending or a document delivery service).
The JISC IE technical architecture [11] distinguishes the two high-level problems of:
However, the architecture acknowledges that the underlying issue is the capacity to "join up" combine digital service components, whatever function they are providing. In the past this join-up has depended on human effort: for example, a researcher might obtain information from (the human-oriented interface of) one service and then use that information as input to a second service, in the course of that process working with different interfaces - typically Web sites - and perhaps making adjustments to account for differences in the semantics used by the two interfaces. Often the task at hand requires the discovery of, and access to, multiple resources, through the use of multiple services - and the human labour involved may be considerable.
The JISC IE technical architecture specifies a set of standards and protocols [12] that service components should support so that they can exchange information effectively with other service components, i.e. it provides standards for machine-oriented interfaces between service components, with the aim of reducing the effort required by the human user to use services in combination.
The architecture also categorises services according to the general class of activity they perform: that categorisation may be useful in outlining how different service components within the IE might interact with the IEMSR:
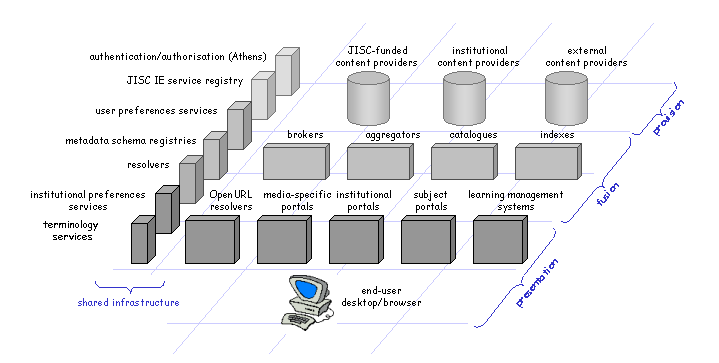
Fig 1: The JISC Information Environment Technical Architecture
These categories are "ideal types" rather than mutually exclusive divisions: they are intended to reflect the primary "core" functionality of a service. In practice real service components provide functions which overlap these high-level categories: almost all service components have a human-readable interface, for example, so they all have some facet of "presentation".
The JISC IE Metadata Schema Registry is one of the "shared infrastructural services" that deliver services to provide functions of common interest to many of the other service components in the IE.
The core functions of the JISC IE are to support discovery of, and access to, information resources, and many of the functions provided by service components within the IE involve operations on metadata describing those information resources.
The technical architecture describes three mechanisms by which metadata can be made available (by content providers, but also by fusion services) to other service components. Metadata is exposed for:
Semantic interoperability for metadata within the JISC Information Environment is based on the deployment of two metadata standards: the Dublin Core Metadata Element Set [12] and the IEEE Learning Object Metadata (LOM) standard [13], more specifically on two application profiles of these standards: Simple Dublin Core and the UK LOM Core [15]. While the Dublin Core vocabularies are designed primarily to support resource discovery, the LOM metadata standard is designed to support a much wider range of functions and operations, particularly the (re)use of a learning object in a range of contexts.
All content providers in the JISC IE are encouraged to support either a distributed search interface (using Z39.50 conforming to Functional Area C Level 1 of the Bath Profile) or a metadata harvesting interface (using the Open Archives Initiativde Protocol for Metadata Harvesting). In each case they must be able to return simple Dublin Core metadata records; and if the resources are of value to the learning and teaching community they should also offer metadata records conforming to the UK LOM Core. The metadata records must use the XML bindings specified for those application profiles [11].
(Although Z39.50 targets may return LOM metadata records, they are not, at present at least, required to support searches using the semantics of LOM metadata, i.e. a search might be conducted using the semantics of simple Dublin Core, but the result set might provide LOM metadata records. It is possible that searches using LOM semantics may be required in the future.)
So the exchange of Simple DC and UK LOM Core metadata records provides a "baseline" for interoperability. However, content providers may (and often do) offer a richer level of semantic interoperability by exposing additional metadata formats for harvesting or in alerts, or returning additional formats in the results of searches. Typically the sharing of such richer metadata takes place between a closed (or semi-closed) group of service providers and depends on prior co-ordination between the partners on the metadata semantics and, if necessary, on extensions to the syntactical bindings.
|
The JISC IE Metadata Schema Registry is a shared infrastructural service, or middleware service: it provides functions of potential interest to many different service components, which may be "located" in any of the functional categories outlined in the technical architecture and which may themselves perform widely varying functions. In common with the other infrastructural services, the primary users of the IEMSR are software applications. However, it is quite likely that a human-readable interface to the IEMSR will also be of value to the designers of metadata application profiles, to the developers of metadata-based applications within the JISC IE and indeed to the creators and maintainers of metadata standards. The primary purpose of this document is to outline the general role of the IEMSR, in order to provide a basis for further exploration of the functions of the services the IEMSR might offer. 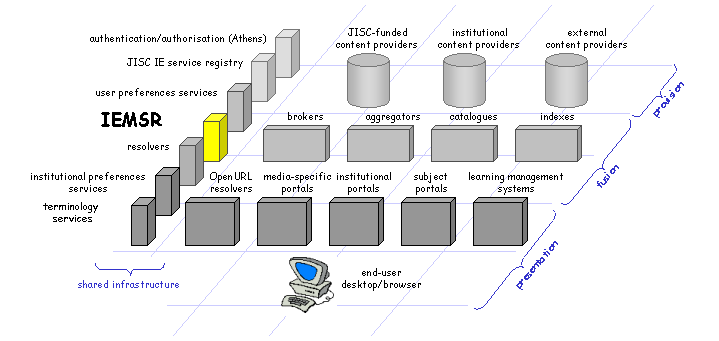
Fig 2: The IEMSR in the JISC IE Technical Architecture |
It should be noted that none of the mechanisms described above for exchanging metadata within the IE require the services of a metadata schema registry: indeed metadata is currently being searched, harvested and used in alerting throughout the IE without the existence of a metadata schema registry. However, the services provided by a metadata schema registry may improve the current position in two ways:
The emphasis in the previous section was on the exchange of metadata between service components, and it is this that the IEMSR is intended to support. Like the IE Service Registry [16], the IEMSR is concerned with the interfaces between a service component and other applications. Several important consequences follow from this:
It is perhaps worth noting that the emphasis above is on applying descriptions of metadata vocabularies to support the disclosure and interpretation of the semantics and structure of metadata records (and using that data to support the creation or processing of metadata records). There is a related issue of whether and how the IEMSR might support the creation of queries to be submitted to search interfaces, and this may be an area that requires further investigation since (using the Z39.50 protocol at least), the attriutes used in the query may have a different set of semantics from those of the fields/elements present in the metadata records that are returned.
It is expected that the IEMSR will use a distributed architecture i.e. the registry will not be a repository for metadata schemas. Rather, the schemas that serve as input to the registry will be maintained by their owners and published to the Web so that they can be read by the registry. Some of those schemas have already been published on the Web by the owners of standard metadata vocabularies; some schemas will be created using tools provided by the registry; some may be created by other tools according to the preference of their creators. In each case, however, responsibility for the creation of the schema, for the maintainance of the content, and for its continued availability lies with the owner of the schema.
Where the owners/publishers of schemas are unable to guarantee the continued availability of their schemas, it may be necessary to consider the provision of a centralised storage facility alongside the registry, but this is not a core part of the registry's functionality.
If the IEMSR is to serve as "an authoritative source for information about metadata", then appropriate policies and procedural controls must be established for the data that is submitted to the registry. The versioning of metadata vocabularies and the terms within them is a complex problem, and the appropriate use of persistent identifiers for metadata vocabularies and for the terms within those vocabularies will be critical.
Further, if one of the aims of the registry is to promote the reuse of existing metadata vocabularies and their component terms in new application profiles, then it is important that the descriptions of vocabularies that are submitted include clear indications of the status and provenance of vocabularies and of individual terms. (For example, the FOAF RDF vocabulary assigns a status of 'unstable','testing' or 'stable' to each class and property in the vocabulary [17].)
This section introduces some potential use scenarios for the IEMSR, based on services of the different high-level activity functional categories described in the IE Technical Architecture: content provision, fusion, presentation and shared infrastructure [18]. It is hoped that these (and other scenarios) might be elaborated into more detailed use cases.
Sections 3.1 to 3.4 are intended to represent the exchanges between service components in these different categories and the IEMSR: these are interactions between software applications. To reflect the fact that a human-readable interface to the IEMSR is likely to be of value, section 3.5 represents this interface as a "metadata vocabulary portal". In terms of implementation this interface will almost certainly be tightly integrated with the IEMSR, but functionally this is a presentation layer service, rather than an infrastructural service and is represented as such below. Further, representing this presentational facet of IEMSR as a distinct service component highlights the fact that the human-readable interface developed as part of the IEMSR is not necessarily the only human-readable interface to the data aggregated by the IEMSR: a separate service provider could take advantage of the machine interfaces to the IEMSR to build another such presentation service - perhaps one which presents the data aggregated by multiple metadata schema registries - quite independently of the development of the IEMSR itself.
|
Content providers are concerned primarily with the provision of information content, in various forms. They are also concerned with the provision of metadata about that content: the creation and management of metadata records and the exposure of those metadata records to other services. Examples of content providers are: institutional repositories, nationally-managed repositories, and commercial publishers. |
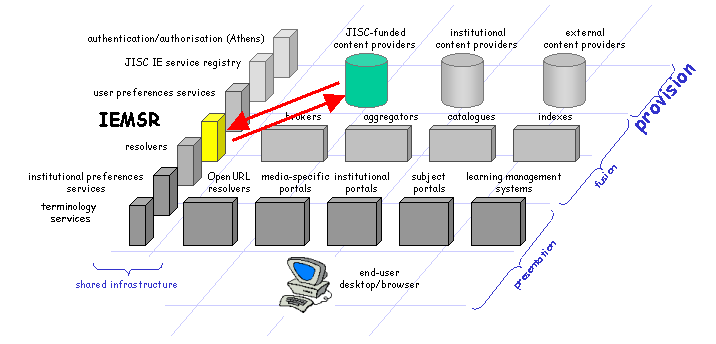
Fig 3: Content providers and the IEMSR |
Human administrator/developer of content provision service:
Software components:
|
Depending on their function, fusion services may be both consumers and providers of metadata so are concerned with both discovering the characteristics of metadata records provided by others and disclosing the characteristics of the metadata records which they expose to others. Aggregation services (which harvest metadata from multiple sources and then provide machine interfaces to the aggregated data) and brokers (which take in a query, pass it to one or more search targets, merge the results, and return them to the original query source) are the "classic" examples of fusion services. Both library catalogues and commercial abstracting and indexing services are located in the fusion layer because their primary purpose is the provision of metadata rather than the provision of content. |
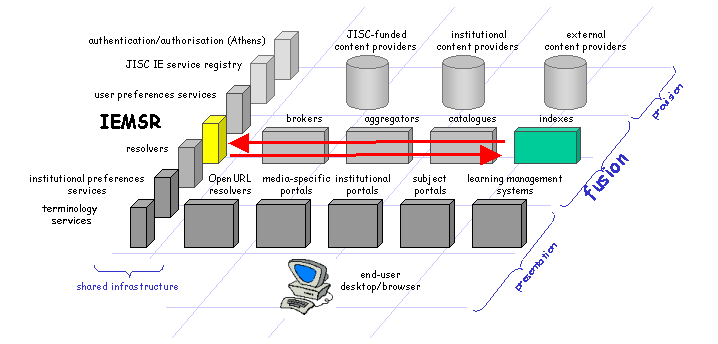
Fig 4: Fusion services and the IEMSR |
Human administrator/developer of fusion service:
Software applications:
|
Presentation layer services are primarily consumers of metadata so are concerned with discovering the characteristics of metadata records provided by others. Presentation services include "portals" of various types and scopes, but also Virtual Learning Environments. Although the majority of presentation services are Web browser-based, other desktop tools such as reference managers and news readers also provide presentation functions. |
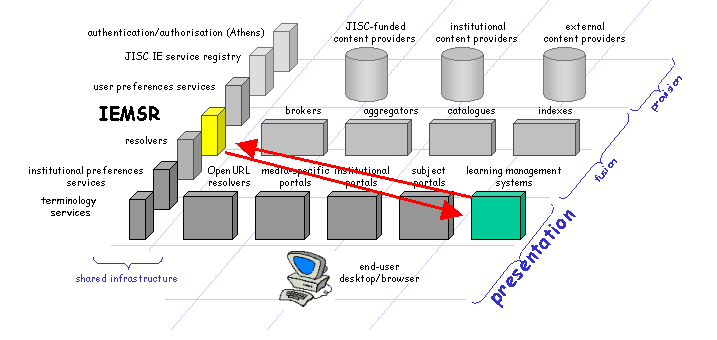
Fig 5: Presentation Layer Services and the IEMSR |
The human users of the presentation service are seeking to discover and/or access resources made available by content providers (or perhaps metadata records describing those content resources). Such a service is concerned with the processing of metadata describing resources made available by content providers, and presenting these metadata records and/or the content resources themselves to the human user. The presentation service interacts with the IEMSR only as is required to achieve this (c.f. section 3.5 below)
Human administrator/developer of presentation service:
Software applications:
|
Although the IEMSR is itself a shared infrastructural service, other shared infrastructural services will also be users of the functionality provided by the IEMSR. Like fusion services, infrastructural services may be both consumers and providers of metadata records, so may wish both to discover the characteristics of metadata records provided by others and to disclose the characteristics of metadata records which they expose. |
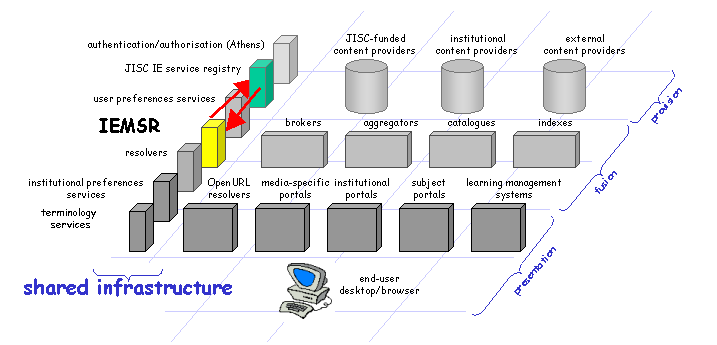
Fig 6: Shared Infrastructural Services and the IEMSR |
Software applications:
|
Here the presentation service is concerned with presenting data from the IEMSR itself, not metadata about content resources. Indeed, the "metadata vocabulary portal" - such as the human-readable interface to the IEMSR - probably has no immediate requirement to interact with service components in the content provision layer in order to provide this function. (c.f. section 3.3 above) |
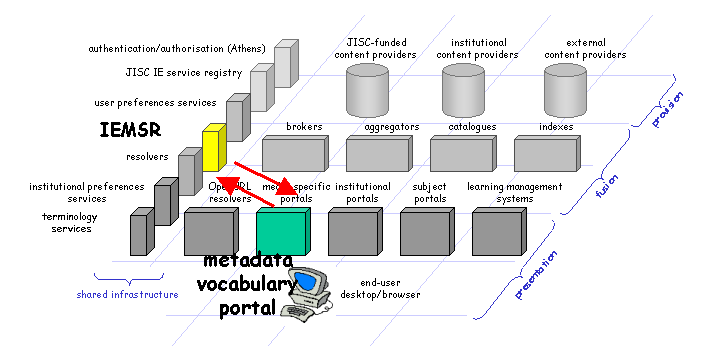
Fig 7: A Metadata Vocabulary Portal and the IEMSR |
(Indeed from this perspective the IEMSR might also be considered to be a "fusion service" that aggregates metadata (the content of schemas) where the resources described by that metadata are either "conceptual" (metadata vocabularies, the terms within them) or digital (documents describing use of those vocabularies, documents describing bindings, structural schemas etc).
[ 1] Thomas Baker, Christophe Blanchi, et al.Principles of Metadata Registries
http://delos-noe.iei.pi.cnr.it/activities/standardizationforum/Registries.pdf
[ 2] Pete Johnston. Models for Metadata Application Profiles: A Review
[ 3] SchemaWeb
http://www.schemaweb.info/
[ 4] Dan Brickley. RDF Vocabulary Description Language 1.0 (RDF Schema), W3C Recommendation. February 2004.
http://www.w3.org/TR/rdf-schema/
[ 5] Deborah L. McGuinness & Frank van Harmelen. OWL Web Ontology Language Overview, W3C Recommendation. February 2004.
http://www.w3.org/TR/owl-features/
[ 6] DCMI Registry
http://dublincore.org/dcregistry
[ 7] DCMI Usage Board, DCMI Grammatical Principles, November 2003.
http://dublincore.org/usage/documents/principles/
[ 8] Metadata for Education Group (MEG) Registry
http://meg.ukoln.ac.uk/
[ 9] Rachel Heery & Manjula Patel, "Application Profiles: mixing and matching metadata schemas". Ariadne, 25 (September 2000)
http://www.ariadne.ac.uk/issue25/app-profiles/
[ 10] JISC Information Environment Architecture: General FAQ
http://www.ukoln.ac.uk/distributed-systems/jisc-ie/arch/faq/general/
[11] Andy Powell & Liz Lyon. The DNER Technical Architecture: scoping the information environment. May 2001.
http://www.ukoln.ac.uk/distributed-systems/jisc-ie/arch/dner-arch.html
[12] Andy Powell. JISC Information Environment Architecture: Standards Framework. May 2001.
http://www.ukoln.ac.uk/distributed-systems/jisc-ie/arch/standards/
[13] Dublin Core Terms, November 2003.
http://dublincore.org/documents/dcmi-terms/
[14] IEEE LTSC. 1484.12.1 - 2002 Learning Object Metadata (LOM)
http://ltsc.ieee.org/wg12/par1484-12-1.html
Final Draft available at:
http://ltsc.ieee.org/wg12/20020612-Final-LOM-Draft.html
[15] UK Learning Object Metadata Core, August 2003.
http://www.ukoln.ac.uk/metadata/education/uklomcore/
[16] JISC IE Service Registry
http://www.mimas.ac.uk/iesr/
[17] Dan Brickley, Libby Miller. FOAF Vocabulary Specification. RDFWeb Namespace Document 16 August 2003
http://xmlns.com/foaf/0.1/
[18] Andy Powell, "Mapping the JISC IE service landscape". Ariadne, 36 (July 2003)
http://www.ariadne.ac.uk/issue36/powell/
![]()
Web page content by
Pete Johnston of UKOLN
Page last revised on:
6 March 2004
Email comments to webmaster@ukoln.ac.uk