A trawl of UK University entry points was initiated on the evening of Friday 31 July 1998. The results of this trawl are compared with a trawl of the same community which was carried out on 24 October 1997.
The NISS list of Higher Education Universities and Colleges [1] was used for the trawl. This file contains 170 institutions. The WebWatch robot successfully trawled 149 institutions. Twenty-one institutional home pages could not be accessed, due to server problems, network problems, restrictions imposed by the robot exclusion protocols or errors in the input data file.
A total of 59 sites had robots.txt files. Of these, two sites (Edinburgh and Liverpool universities) prohibited access to most robots. As these sites were not trawled they are excluded from most of the summaries. However details about the server configuration is included in the summaries.
Note that when manually analysing outliers in the data it was sometimes found that information could be obtained which was not available in the data collected by the robot.
A brief summary of the findings is given below. More detailed commentary is given later in this article.
Table A4-1 Table of Server Usage
As can be seen from Table A4-1 the Apache server has grown in popularity. This has been mainly at the expense of the NCSA and CERN servers, which are now very dated and no longer being developed. In addition a number of servers appear to be no longer in use within the community (e.g. Purveyor and WebSite). Microsoft's server has also grown in popularity.
The popularity of Apache is also shown in the August 1998 Netcraft Web Server Survey [2], which finds Apache to be the most widely used server followed by Microsoft-IIS and Netscape-Enterprise. The Netcraft surveys are taken over a wider community than the academic sites looked at in this paper. The community surveyed by Netcraft is likely to consist of more diverse platforms (such as PCs) whereas academic sites show a bias towards Unix systems. This may explain the differences in the results of the next most popular servers.
Table A4-2 shows a profile of HTTP headers.
HTTP/1.0 |
50% |
HTTP/1.1 |
50% |
Cachable resources |
54% of HTML pages and 60% of images |
Non-cachable resources |
1% of HTML pages and 0% of images |
Cachability not determined |
36% of HTML pages and 40% of images |
Table A4-2 HTTP Headers
Note that this information was not collected for the first trawl due to limitations in the robot software.
In Table A4-2 a resource is defined as cachable if:
* It contains an Expires header showing that the resource has not expired
* It contains a Last-Modified header with a modification date greater than 1 day prior to the robot trawl.
* It contains the Cache-control: public header
A resource is defined as not cachable if:
* It contains an Expires header showing that the resource has expired
* It contains a Last-Modified header with a modification date coinciding with the day of the robot trawl
* It contains the Cache-control: no-cache or Cache-control: no-store headers
* It contains the Pragma: nocache header
The cachability of resources was not determined if the resource used the Etag HTTP/1.1 header, since this would require additional testing at the time of the trawl which was not carried out.
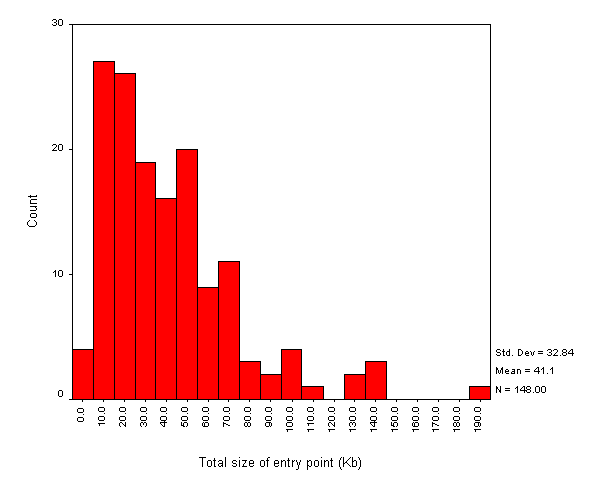
Figure A4-1 gives a histogram of the total size of the institutional entry point.
As shown in Figure A4-1, four institutions appear to have an institutional web page which is less than 5Kbytes. The mean size is 41 Kb, with a mode of 10-20 Kb. The largest entry point is 193 Kbytes.
Note that this information is based on the size of the HTML file, any framed or refresh HTML pages, inline images and embedded Java applets.
It does not include any background images, since the current version of the robot does not parse the <BODY> element for the BACKGROUND attribute. Subsequent analysis showed that 56 institutions used the BACKGROUND attribute in the <BODY> element. Although this would increase the file size, it is unlikely to do so significantly as background elements are typically small files.
The histogram also does not include any linked style sheet files. The WebWatch robot does not parse the HTML document for linked style sheets. In this the robot can be regarded as emulating a Netscape 3 browser.
Figure A4-2 gives a histogram for the number of images on the institutional entry point. As mentioned previously this does not include any background images.
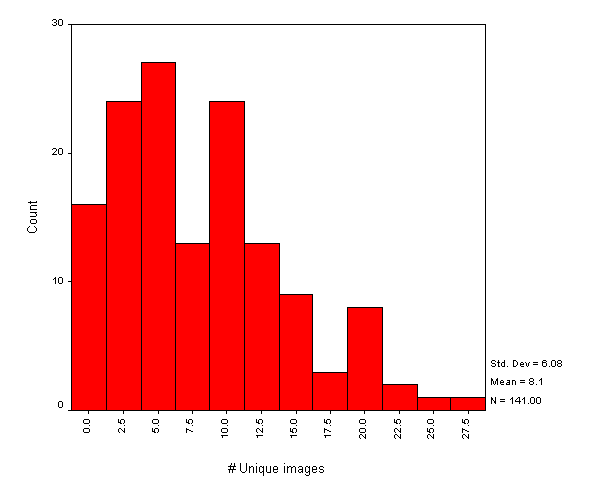
Figure A4-3 gives a histogram for the number of hypertext links from institutional entry points.
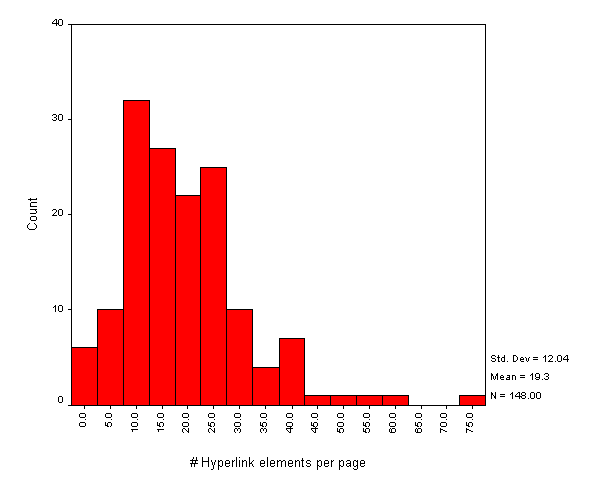
Note that Figure A4-3 gives the total number of links which were found. This includes <A> elements and client-side image maps. Note that typically links in client-side maps are duplicated using the <A> element. No attempt has been made in this report to count the number of unique links.
In this section we discuss the findings of the trawls.
The discussion covers the accessibility of the pages and the technologies used. In the accessibility discussion we consider factors relevant to users accessing the pages, including the files sizes (which affects download times), whether the pages can be cached (which also affects download times) and the usage of hyperlinks (which can affect the usability). In the technology discussion we consider the technologies used, such as server hardware and software, and web technologies such as use of JavaScript and Java, metadata and style sheets.
The results of the WebWatch trawl are intended to correspond closely with those that would be observed by a user using a web browsers. This is unlike, for example, many indexing robots which are not capable of processing frames. Robot software can also have problems in downloading linked resources, such as style sheet files, parsing HTML elements which may link to external resources, such as images, or processing HTTP headers, such as redirects. Robots developers often have a conservative approach to implementing new features in order to minimise the dangers of robots recursively requesting resources or causing other network or server problems.
The WebWatch has a similar conservative design. In a number of cases the automated analyses were modified by subsequent manual investigation in order to provide results which are applicable to a human view of a website (for example the size of a framed resource is the sum of the framed elements and not the hosting frameset). Where it has not been possible to do this, commentary is provided.
Size of Institutional Entry Point
The majority of institutional entry points appear to be between 10 Kb and 100 Kb (excluding background images which, as stated previously, were not included in the analysis).
Details of the largest and smallest institutional entry points are given in Table A4-3.
Table A4-3 Summary Details of Largest and Smallest Sites in Current Trawl
Although perhaps not noticeable when accessing the page locally or across the SuperJANET network the large differences in sizes between, for example, the entry points for the University of Plymouth University and the Kent Institute of Art and Design are likely to cause noticeable differences in the download time for overseas users or accesses using modems.
It was also noted that all of the large sites which were available for manual inspection contained animated images.
Cachability of Institutional Entry Point
Interest in caching has grown in the UK Higher Education community since the advent of institutional changing for international bandwidth. In addition to interest in the cachability of resources from overseas websites, institutions are interest in the cachability of their own pages, especially key pages such the main entry point. Speedy access to such pages from local caches can be important when attempting to provide information to remote users, such as potential students. Unfortunately the need to provide cache-friendly pages may conflict with the need to provide attractive customised pages.
A study of the cachability of institutional entry points was carried out in order to observe the priorities given by institutions.
Over half of the institutional entry points have been found to be cachable, and only 1% not-cachable. 40% of the HTML resources used the Etag HTTP/1.1 header which is the current recommended method of establishing cachability. Unfortunately in order to identify if a resource can be cached the Etag value needs to be rechecked on a subsequent trawl and this was not carried out during this survey.
Links from Institutional Entry Point
The histogram of the numbers of hyperlinks from institutional entry points shows an approximately normal distribution, with a number of outliers indicating a small number of institutions with a large number of links. The institutional with the largest number of links on its entry point was Royal Holloway at <URL: http://www.rhbnc.ac.uk/>. The entry point contained 76 hyperlinks.
Providing a simple, uncluttered interface, especially to users accessing an institutional entry point for the first time, is arguably preferable to providing a comprehensive set of links to resources, although it could be argued that the a comprehensive set of links can minimise the navigation though series of sub-menus.
Future WebWatch trawls of institutional entry points will monitor the profile of hyperlink usage in order to determine any interesting trends.
"Splash Screens"
"Splash screens" are pages which are displayed for a short period before an alternative page is displayed. In the commercial world splash screens are used to typically used to display some form of advertisement before the main entry page, containing access to the main website , is displayed. Splash screens are normally implemented using the <META REFRESH="value"> element. Typically values of about 5 seconds are used. After this period the second page is displayed.
In the initial WebWatch trawl, a total of five occurrences of the <META REFRESH="value"> element were found. Of these, two had a value of 0. This provides a "redirect" to another page rather than displaying a splash screen.
In the second WebWatch trawl, a total of four occurrences were found (at the universities of Glamorgan, Greenwich, Sheffield and Staffordshire). Further investigation revealed that a number of additional sites use this feature which weren't detected in the robot trawl, due to the site being unavailable at the time of the trawl. Further details are given in Table A4-4.
Institution |
Trawl Oct 97 |
Trawl July 98 |
De Montford University |
Refreshes after 8 seconds |
Refreshes after 8 seconds |
Glasgow School of Art |
Redirects after 10 seconds |
Redirects after 10 seconds (Note site not trawled due to omission in input file) |
Glamorgan |
Redirects to static page |
Redirects to static page |
Greenwich |
Redirect to static page containing server-side include |
Redirect to static page containing server-side include |
Queen's University Belfast |
Refreshes after 10 minutes |
No refresh |
Ravensbourne College of Art and Design |
No refresh |
Redirect (Note site not trawled due to omission in input file) |
Sheffield |
No refresh |
Refresh after 10 minutes |
Staffordshire |
No refresh |
Redirect to CGI script |
Table A4-4 Comparison of Client-Side Refreshes
Metadata can aid the accessibility of a web resource by making the resource more easy to find. Although the management of metadata may be difficult for large websites, management of metadata for a single, key page such as the institutional entry point should not provide significant maintenance problems.
The main HTML elements which have been widely used for resource discovery metadata are the <META NAME="keywords" VALUE="..."> and <META NAME="description" VALUE="...">. These elements are supported by popular search engines such as Alta Vista.
The resource discovery community has invested much time and energy into the development of the Dublin Core attributes for resource discovery. However as yet no major search engine is making use of Dublin Core metadata.
Metadata Type |
Oct 1997 |
Jul 1998 |
Alta Vista metadata |
54 |
74 |
Dublin Core |
2 |
2 |
Table A4-5 Use of Metadata
As can be seen from Table A4-5, the metadata popularised by Alta Vista is widely used, although perhaps not as widely used as might have been expected, given the ease of creating this information on a single page and the importance it has in ensuring the page can be found using the most widely used search engines.
Dublin Core metadata, however, is only used on two institutional entry points: the University of Napier and St George's Hospital Medical School. Although this may be felt to be surprising given the widespread awareness of Dublin Core within the UK Higher Education community, the very limited use appears to be indicative that web technologies are not used unless applications are available which make use of the technologies.
Server Profiles
Since the initial trawl the server profile has changed somewhat. A number of server which were in use in October 1997 (Purveyor, BorderWare, WebSite, Roxen Challenger, Windows PWS) have disappeared. The major growth has been in usage of Apache, which has grown in usage from 31% to 42%.
Unfortunately it is not possible to obtain the hardware platform on which the server is running. Certain assumptions can be made. For example, Apache probably runs on Unix platforms since the Windows NT version is relatively new and reports indicate that the Windows NT version is not particularly fast. The Microsoft IIS server probably runs on a Windows NT platform. The CERN and NCSA server probably run on Unix. Unfortunately it is difficult to make realistic assumptions about the Netscape servers since these have been available for Unix and Windows NT platforms for some time.
Based on these assumptions Table A4-6 gives estimates for platform usage, based on the Netscape server being used solely on Unix or Windows NT.
Platform |
Estimated
|
Estimated
|
Unix |
89 |
115 |
Windows NT |
21 |
46 |
Other PC platform |
6 |
6 |
Macintosh |
4 |
4 |
DEC |
2 |
2 |
Table A4-6 Estimated Platform Usage
As may be expected the Unix platform is almost certainly the most popular platform. (This cannot be guaranteed, since the Apache server is now available for Windows NT. However as it has only been available on Windows NT for a short period and the Windows NT version is believed to be less powerful than Microsoft's IIS server, which is bundled free with Windows NT, it appears unlikely that Apache has made much inroads in the Windows NT world).
It will be interesting to analyse these results in a year's time, to see, for example, if Windows NT gains in popularity.
Java
None of the sites which were trawled contained any <APPLET>, <OBJECT> or <EMBED> elements, which are used to define Java applets. However it had been previously noted that the Liverpool University entry point contained a Java applet. Inspection of the robots.txt file for this site showed that all robots except the Harvest robot were excluded from this site.
The little use of Java could be indicative that Java does not have a role to play in institutional entry points or that institutions do not feel that sufficient number of their end users have browsers which support Java. The latter argument does, however, appear to contradict the growing use of technologies such as Frames and JavaScript which do require modern browsers.
JavaScript
In the initial trawl 22 of the 158 sites (14%) contained a client-side scripting language, such as JavaScript. In the second trawl 38 of the 149 sites (26%) contained a client-side scripting language, such as JavaScript.
The increasing uptake would appear to indicate confidence in the use of JavaScript as a mainstream language and that incompatibility problems between different browsers, or different versions of the same browser are no longer of concern.
With the increasing importance of client-side scripting languages in providing responsive navigational aids we can expect to see even more usage in the future. Future WebWatch trawls will help to identify if this supposition is true.
Frames
There has been a small increase in the number of sites using frames. In the original trawl 12 sites (10%) used frames. In the second trawl a total of 19 (12%) sites used frames.
HTML Validation
In the second trawl only three sites contained a page of HTML that validated without errors against the HTML3.2 DTD. Since it is reasonable to assume that most institutional webmasters are aware of the importance of HTML validity and have ready access to HTML validators (such as the HTML validation service which is mirrored at HENSA [3]) we might recommend a greater adoption of validated HTML pages.
Future Work
The WebWatch project has developed and used robot software for auditing particular web communities. Future work which the authors would like to carry out include:
* Running regular trawls across consistent samples in order to provide better evidence of trends.
* Making the data accessible for analysis by others across the Web. This would probably involve the development of a backend database which is integrated with the Web, enabling both standard and ad hoc queries to be initiated.
* Developing a number of standardised analyses. For example the development of an analysis system for analysing the accessibility of a website for the visually impaired, or the cachability of a website.
* Providing a web-based front-end for initiating "mini-WebWatch" analyses. Work on this has already begun, with the release of a web form for analysing HTTP headers [4].
References
[1] NISS, Higher Education Universities and Colleges.
<URL:
http://www.niss.ac.uk/education/hesites/cwis.html >
[2] Netcraft, <URL: http://www.netcraft.co.uk/ >
[3] WebTechs, HTML Validation Service. <URL: http://www.hensa.ac.uk/html-val-svc/ >
[4] UKOLN, URL-info. <URL: http://www.ukoln.ac.uk/web-focus/webwatch/services/http-info/ >