The WebWatch project developed a set of Unix-based tools to support its work. In order to provide easy access to these tools, a Web interface was developed. The Web interface has been enhanced and these Web services are now freely available. A summary of the services is given below.
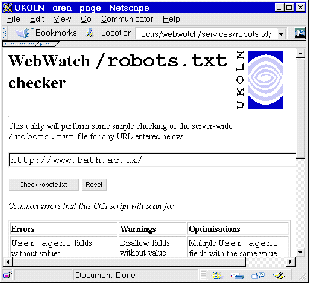
The robots.txt checker is a Web-based service which tests for the existence of a robots.txt file on a web server, and runs some simple checks for common errors in configuring the file.
The robots.txt checker is available at <URL: http://www.ukoln.ac.uk/web-focus/webwatch/services/robots-txt/ >.
The robots.txt checker is illustrated in Figure 7-1.
A typical robots.txt file is illustrated in Figure 7-2.
# robots.txt file
User-agent: CharlieSpider
Disallow: /
User-agent: *
Disallow: /UCS/mail-archives/
Disallow: /cgi-bin/
Figure 7-2 A Typical robots.txt File
In this example the CharlieSpider robot (referred to as a user-agent in the file) is prohibited from trawling the web site. All robots are prohibited from accessing files storing in and beneath the directories /cgi-bin and /ucs/mail-archives.
The CharlieSpider robot is probably banned because it is known to be unethical. For example, it could download email addresses for spamming purposes, or it could simply place unnecessary load on the web server due to inefficiencies in the design of the program.
Robots are expected not to access the /cgi-bin directory as this directory contains software and not documents, and so it would not be sensible for the contents of the directory to be indexed.
Robots are expected not to access the /ucs/mail-archives as this directory contains archives of mail messages which the institution does not want to be indexed by search engines, such as AltaVista.
The robots.txt checker service is a useful tool for information providers who wish to check if their web server contains a robots.txt file, and for webmasters who wish to check their robots.txt file and compare it with others.
HTTP-info is a Web-based service which displays the HTTP headers associated with a Web resource.
HTTP-info is available at
<URL:
http://www.ukoln.ac.uk/web-focus/webwatch/services/http-info/ >.
The HTTP-info interface is illustrated in Figure 7-3a. Figure 7-3b illustrates the output from the service.
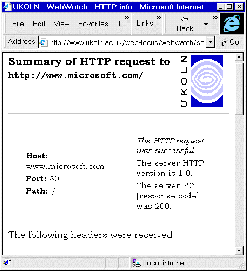
Figure 7-3a HTTP-info Interface Figure 7-3b Output From HTTP-info
In Figure 7-3b the headers for the resource at <URL: http://www.microsoft.com/ > were displayed using HTTP-info. The output shows the host name, port and the path. The server is using HTTP/1.0. The return code (RC) of 200 shows that the document was successfully retrieved. The HTTP headers which were retrieved (which are not all shown in the diagram) show that, for example:
* The server using the ETag method for cache control.
* The document was last modified a day ago.
* The server software is, not surprisingly, Microsoft-IIS/4.0.
HTTP-Info is a useful tool for information providers who wish to check the HTTP headers for their web resources, for end users who wish to check the HTTP headers of services they are accessing and for webmasters who may wish to check server configuration options.
The functionality provided by HTTP-Info can be obtained by simple use of the telnet command. However HTTP-Info provides a simplified interface, for those who aren't familiar with or have access to telnet.
Doc-info is a Web-based service which displays various information about an HTML resource.
Doc-info is available at
<URL:
http://www.ukoln.ac.uk/web-focus/webwatch/services/doc-info/ >.
The Doc-info interface is illustrated in Figure 7-4a. Figure 7-4b illustrates the output from the service.
Information provided by Doc-Info about HTML resources includes:
* The names of embedded resources (e.g. images).
* The size of embedded resources.
* The total size of the resource.
* Details of links from the resource.
* A summary of the HTML elements in the resource.
* Details of the web server software.
* Details of cache headers.
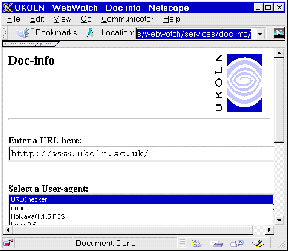
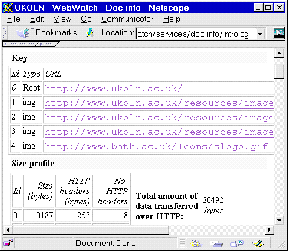
Figure 7-4a The Doc-Info Interface Figure 7-4b Output From Doc-Info
Although the WebWatch services provide a simple user interface for getting information about web resources, the need to go to the page, either by entering the URL or using a bookmark, and then enter the URL of the resource to be analysed can be a barrier to use of the services. It is desirable to access the services directly when viewing a page.
Use of the Netscape personal toolbar enables the services to be accessed directly. A link to the underlying CGI script for the WebWatch services can be dragged onto the toolbar. Then when an arbitrary page is being viewed, the option in the personal toolbar can be selected. The WebWatch service will analyse the page being viewed. The output from the WebWatch service will be displayed in a separate browser window, as shown in Figure 7-5.
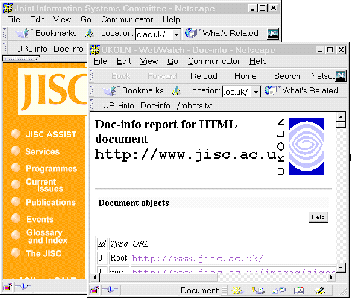
The list of WebWatch services at <URL: http://www.ukoln.ac.uk/web-focus/webwatch/services/ > contains details of how to include the services in the Netscape personal toolbar.