The third major WebWatch crawl took place in November, 1997. The WebWatch robot software analysed eLib project web sites. A report on the analysis follows.
The WebWatch project analyzed eLib project websites as defined at <URL:http://www.ukoln.ac.uk/services/elib/projects/> following a trawl that took place on 3 occasions in November 1997. This report gives a summary of the findings. The report is intended primarily for eLib project webmasters, but eLib project managers may also find it of interest.
The trawl took place on 14/15, 21/22 and 25 of November. Although it was initially intended to carry out the trawl in one run, the size of eLib project websites revealed a number of problems with the WebWatch robot and so a number of runs were needed.
Since the runs provided different sets of data, this report is based on a combination of data. Note that eLib project websites were not completely covered.
Two files of data from separate trawls have been analyzed which contain samples of HTML data, images and other resources.
Fifty-five eLib project sites were cited for crawling. Some of these were not indexed as fully as intended as a result of problems including time-outs and various interpretation difficulties (see later).
Where relevant, we refer to % of sites rather than actual numbers to avoid misinterpretations over our analysis of two differing summary files.
Of the 55 sites considered:
The following are expressed as percentages of all HTML-typed files encountered.
Figure 1 shows a pie chart of the Web servers encountered.
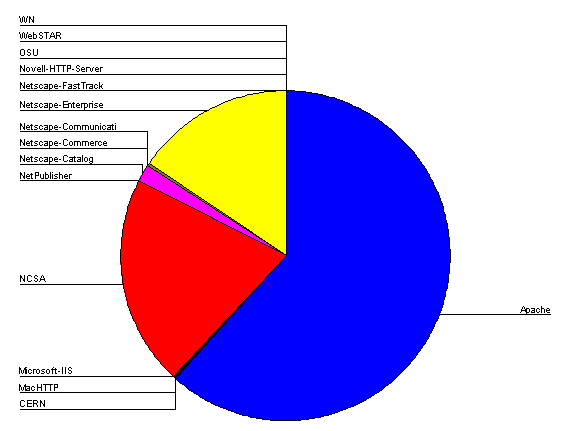
Figure 1 - HTTP server software usage
The top three web servers are Apache(~62%), NCSA(~22%) and Netscape-Enterprise(~17%).
Figure 2 shows the frequency of HTML file sizes.
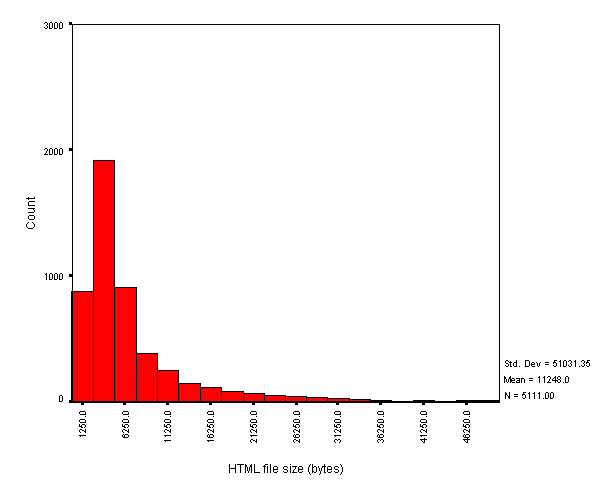
Figure 2 - HTML file size
The majority of HTML documents were under 25 Kb, the mean being about 10 Kb. There were a number of extreme values for HTML file-size (the standard deviation is roughly 49 Kb), on closer inspection these are usually large indices or server logs. The smallest document encountered was 49 bytes - a CGI generated error message and the largest document was about 1 Mb - site server statistics.
Figure 3 shows the frequency of image file sizes encountered.
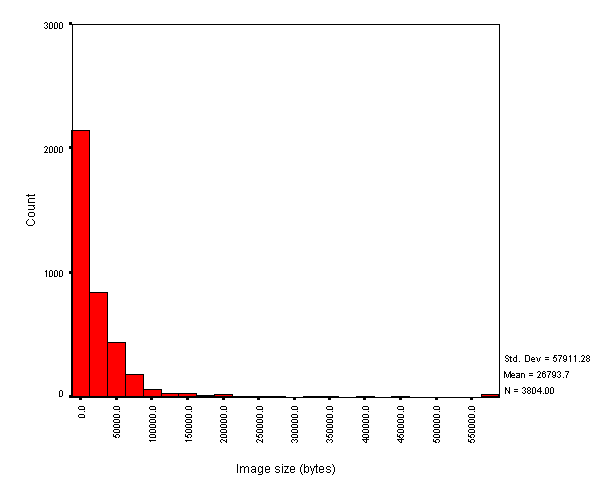
Figure 3 - Image file size
The rough attenuation of the tail compared to HTML file sizes is not really an effect of the different interval-sizes. This might be due to our incomplete trawling of some sites.
We encountered mostly JPEG and GIF formats, the later being roughly 9% more prevalent than the former. The GIF size distribution is of a similar shape to Figure 3 (but with mean 18,732 bytes). The JPEG size distribution is slightly different and had mean 34,865 bytes.
Figure 4 shows the frequency distribution of the size of the entry point to the site. This is defined as the sum of the filesizes of the HTML page and all inline components (mostly inline images).
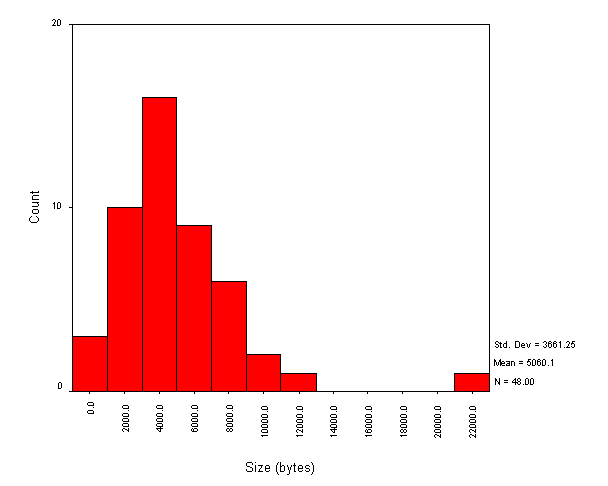
Figure 4 - Size of entry point to site
The mean value is 5 Kb. Over a 28.8 Kbps modem connection, this would take about 1.4 seconds to download.
Figure 5 shows the number of unique HTML elements found on each page.
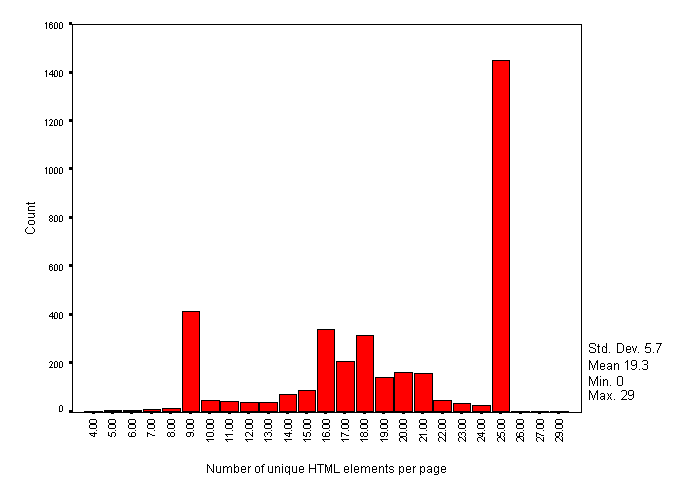
Figure 5 - Number of unique HTML elements per page
The number of unique HTML elements on each page of HTML trawled peaks at 25. However we suspect that the distribution is approximately normal and that the peaks at 9 and 25 are due to 'in-house style' of a number of sites that were trawled completely, dwarfing others that were incompletely trawled.
In contrast, Figure 6 shows the count of total number of HTML elements per page.
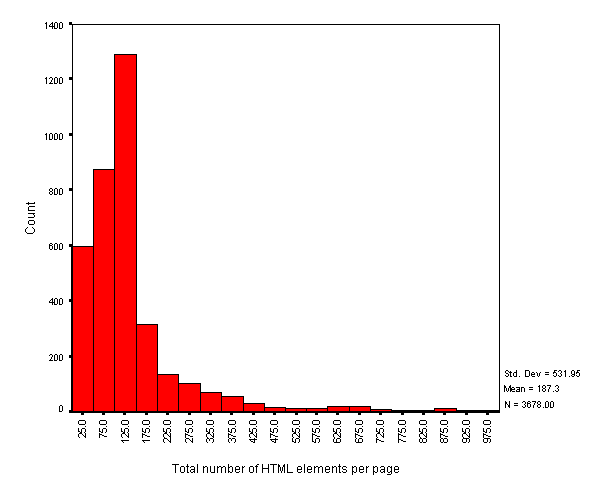
Figure 6 - Total number of HTML elements per page
The mean number of elements for Figure 5 is 187, with standard deviation 532.
The ten most popular elements used per page are shown in Figure 6.
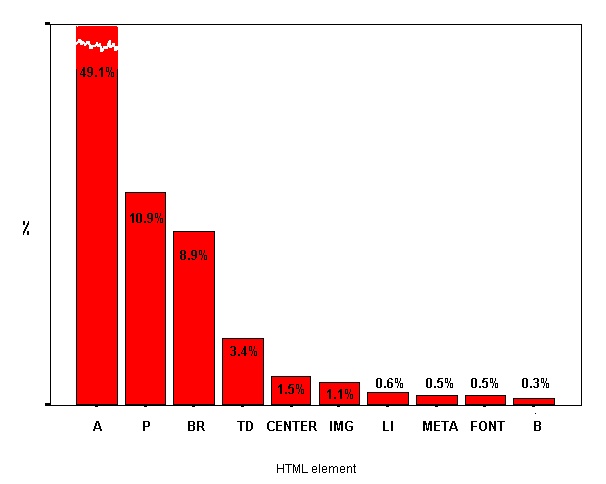
Figure 7 - Top ten HTML elements (per page)
Figure 7 shows that the A element is by far the most widely used HTML element in the eLib project pages which were analyzed. This could be due to extensive linking to external resources, or extensive cross-linking within the website. The Access to Network Resources (ANR) projects (such as OMNI, which was completely indexed,) are likely to contain large numbers of hyperlinks. It is perhaps surprising that eLib projects generally contain such a high proportion of hyperlinks.
We looked at specific uses of the META tag, namely for HTTP-EQUIV=refresh, search-engine metadata specifications (e.g. as recommended by Alta-Vista), Dublin Core metadata specifications and PICS metadata specifications. Around 19% of all trawled pages of HTML contained such instances of META usage. See Figure 7 (HTTP-EQUIVs are not shown).
Figure 8 shows usage of the META element.
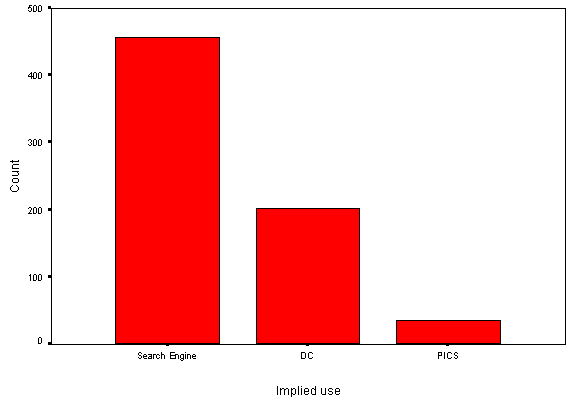
Figure 8 - Use of the META element
A more in-depth look at the use of Dublin Core metadata is presented in Figure 9.
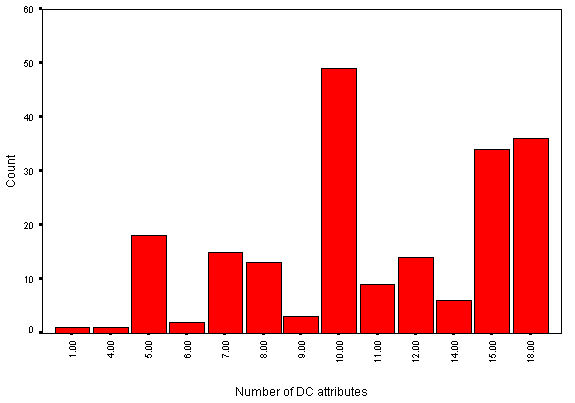
Figure 9 - Number of DC attribute values per page
As can be seen from Figure 9, up to 18 DC metadata attributes per page were used. eLib pages containing DC metadata tended to make extensive use of the DC attributes, with only a small number using a handful of values.
We monitored usage of the SCRIPT element. Event handlers within tags were not analyzed on this trawl.
A brief summary of the SCRIPT element is shown in Figure 10.
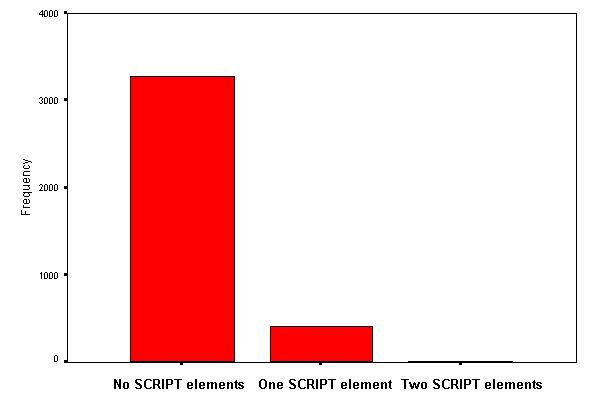
Figure 10 - Use of the SCRIPT element
An analysis of absolute URL references (i.e. http://foo.com/blah.html) within the usual hyperlink elements (A, AREA, LINK, MAP) provides information on the top-level domains linked to.
Figure 11 shows the ten most popular linked-to domains. Every link in each document was considered and the top-ten calculated. Note that the y-axis is logarithmic.
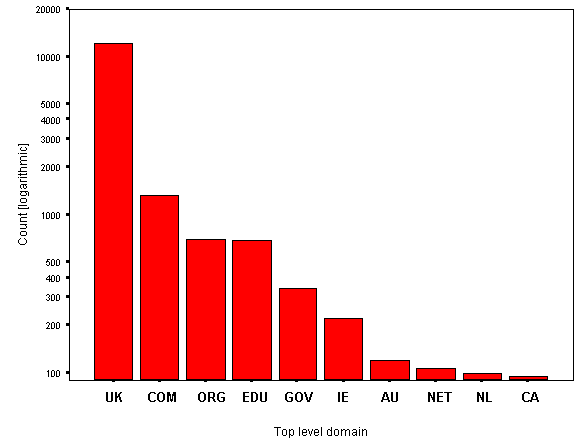
Figure 11 - Top ten linked-to top level domains (evaluated overall)
We have analyzed two files of data from separate trawls and have a large sample of HTML, images and other resources. When all bugs are ironed out from the software one file will suffice. Some problems with the new version of the robot meant that some sites were not being trawled completely. It may be useful to bear this in mind while considering this analysis.
Based on this crawl we are able to make a number of recommendations:
A number of issues emerge from the survey.
We would appreciate any feedback or comments, especially from the eLib community. Comments should be sent to webwatch@ukoln.ac.uk
Plans for future trawls include:
An object-oriented re-write of the software (currently under development) will simplify the addition of future enhancements. Ideas for this version include validation and detailed reports of errors.