This file is available primarily to allow the Good Practice Guide to be printed in a single file.
This section is available at <http://www.ukoln.ac.uk/nof/support/gpg/Introduction/>
This guidebook provides advice on standards and best practices to organisations involved in the development of cultural heritage Web services. The content of the guidebook is based on the advice provided by the NOF-digitise Technical Advisory Service (and others) to projects funded by the NOF-digitise programme.
NOF-digitise was a nationwide digitisation and publication programme funded by British National Lottery proceeds. Its scope and ambition was unlike anything that has been attempted before and it has broken new ground in the understanding and expectations of digitisation projects. This significant undertaking was funded through the New Opportunities Fund (NOF), now rebranded as The Big Lottery Fund, and resulted in 152 projects receiving support for a huge variety of initiatives across a very diverse range of cultural, academic and educational spheres.
During the course of the programme, a Technical Advisory Service (TAS) was provided by UKOLN and AHDS for the benefit of the participant projects and the central administrative team at the New Opportunities Fund. In its lifetime, the TAS provided a wealth of technical advice and support to the participants and stakeholders of NOF-digitise. This guidebook captures, reformats and builds on the strong output that the TAS and partners generated for this programme.
Although we hope that much of the advice provided in this handbook will be helpful to those involved in the development of digital cultural heritage resources, it should be noted that the guidebook is essentially a snapshot of the advice provided during the lifetime of the NOF-digitise programme. Before attempting to implement any of the advice provided, you should read the terms and conditions which govern the development work you are involved. in.
![]()
![]()
![]()
This section is available at <http://www.ukoln.ac.uk/nof/support/gpg/ProjectManagement/>
This section covers the key issues, tools and activities associated with managing a project. Where possible, examples have been shown for illustration or links to relevant Web sites given. Selected key texts giving fuller coverage are listed in the Bibliography and if you have not managed a project before, we would recommend items from this for further reading and/or attending a training course. Some Web sites offering courses are listed in the Human Resources section of the guidebook. Whilst the principles described here can be applied to any project from moving house to setting up a new business, we have tried to draw out particular aspects that apply to managing a technical project such as digitising collections of resources.
Firstly it is helpful to try to define exactly what a project is - what makes it different from other activities such as running an inter-library loan service or maintaining an online catalogue, and we will look at the distinguishing attributes of a project.
A project is an activity which achieves specific objectives through a set of defining tasks and effective use of resources.
Projects have a number of distinctive attributes:
The specific project objectives can be grouped under three general headings: quality (which we can define as fitness for purpose or specification level), costs i.e. the budget, and time (to completion). Each project will have some key objectives which tend to be more important than the others e.g. the quality of the digital images is paramount and the purchase of (relatively) expensive scanning hardware may be acceptable in order to achieve this aim.
In any project, people are a fundamental key to success and provide the links which facilitate the achievement of the project objectives. This is shown below in Figure 1 as the Triangle of Objectives [1].

Figure 1: Triangle of Objectives
All objectives must be SMART:
Specific: expressed singularly
Measurable: ideally in quantitative terms
Acceptable: to stakeholders
Realistic: in terms of achievement
Time-bound: a timeframe is stated
Projects have a defined time frame or finite life span with a beginning and an end. Unlike the example of maintaining a service, such as an online catalogue which is an on-going and continuous activity, a digitisation project will have agreed start and end dates, which are frequently determined by the availability of project funding and/or the availability of project staff (or others) to carry out the work.
Projects are often unique either because they have never before been attempted or because the mix of parameters is customised for the particular activity.
Projects can be described by using a life cycle approach and the four phases of the life cycle are shown below in Figure 2 [2].

Figure 2: Project Life Cycle
In the first phase, a need is identified by the client, customer or funder and this results in a Request for Proposals (RfP) which describes and defines the needs and requirements. We can call this phase Initiation. In the case of the NOF-digitise programme the initial call for proposals was issued in 1999, to which a large number of organisations and consortia responded.
The second phase is characterised by the development of proposed solutions and the Bidding process. This was characterised in the case of nof-digitise programme by a structured bid form which requested specific items of information related to project costs, staffing and other resources, timescales, description of the activities, compliance to technical standards and key deliverables.
The third phase in which the project is executed covers detailed planning and Implementation and we will return to this in some detail shortly.
The final phase is terminating the project or Closure. In some cases this is marked with formal acceptance by the customer or client with signed documentation.
There are two important additional activities associated with projects that are worthy of special mention here: evaluation and dissemination. It should be noted that both evaluation and dissemination are not confined to the later phases of the project. The process of liaising with users and stakeholders, gaining feedback and facilitating interaction should begin as early as possible. Similarly, the mechanisms for disseminating information about project activities must begin at project start-up and continue throughout the duration of the work.
The remainder of this section concentrates on the key activities of the third phase Implementation, and covers planning, monitoring, and controlling.
In order to achieve the objectives of any project it is essential to look at the details of the work required, which includes identifying specific tasks and estimating time to complete them, estimating associated costs, identifying who will perform the tasks and highlighting areas of risk together with devising appropriate contingency plans. In some cases, an outline of this information is required in the bid for funding.
It is usually part of the responsibility of the project manager to create the project plan and to update it on a regular and frequent basis. This is an important point - project plans are not made in tablets of stone! They are dynamic and must reflect the current situation. In most projects there are a number of "unexpected" challenges or events which may affect the timescales, costs and outcomes of the project. With good planning these unexpected events can be dealt with effectively and will not cause insoluble difficulties to the project team.
At this initial planning stage of the project it would be useful to refer to the Good Practice Guide sections on the Digitisation Processes and Content Management Systems.
There are a number of tools available to assist with the planning process and these are described in more detail below. Which tools are used will depend on the size and nature of the project.
There are a number of formal methods for managing projects. One such example is Prince 2.
PRINCE is an acronym for PRojects IN Controlled Environments and is a complete methodology frequently used for managing large-scale projects in UK government departments and agencies. More information is available at <http://www.ogc.gov.uk/prince/>
There are also a number of software packages which facilitate the planning process by providing simple ways of employing the techniques described below. Which package you use (if any) will depend on a number of factors such as size of the project, organisation preferences, licences available and previous project experiences. Some sites where more information can be found are given here:
We have already noted that the project objective(s) must be clearly identified in order to inform the planning process.
A detailed project plan should be prepared and will usually be a requirement of the funders. For example in the NOF-digitise programme projects were required to submit a project business plan at stage two of the application process. A number of tools or methodologies can assist the creation process.
It is useful to begin the process by identifying all the tasks and elements of the project. The creation of a Work Breakdown Structure (WBS) is a systematic approach to scoping the project work in which a logical, hierarchical pattern is devised which may resemble a family tree. An example for moving a set of offices and staff to a new building, is given in Figure 3 [3]. Each branch contains work items which are further broken down into work packages. Note that tasks may have already been grouped into Work Packages as part of preparation for the bidding process.

Figure 3: Office Move Work Breakdown Structure
The level to which tasks are identified will depend on the size and nature of the project, the level at which a single individual or team can be assigned responsibility and the level at which costs are allocated. Not all branches of the WBS have to be broken down to the same level.
Once tasks have been identified, they need to be scheduled within the project time-frame. A visual representation of this process is helpful and a Gantt Chart or bar chart is a valuable aid to planning and achieves this aim. Named after the American industrial engineer Henry Gantt (1861-1919), they can easily be created with the project management software tools described above. It is also possible to indicate the inter-dependencies of tasks using cascading arrows (i.e. instances where one activity cannot begin until another is completed). Project milestones (time points that indicate completion of key phases) and deliverables (defined and tangible outcomes of the project) can also be marked.
An example Gantt Chart is shown below in Figure 4 (click on the image to enlarge).

Figure 4: Gantt Chart
A more recent development is network analysis which covers a number of different methods which had their origins in the late 1950s, and were used successfully in the management of various US defense projects. Their particular strength is in their ability to show the various inter-dependencies of related tasks, however they require some initial learning and practice to become adept at their interpretation. There are two main systems:
The notation convention for an activity in precedence notation is given in Figure 5 [4]. The flow of work is from left to right.

Figure 5: An Activity in Precedence Notation
Each activity is given a unique identification number and they are linked by arrows. Duration estimates can be made in days, weeks or months as appropriate and the total project duration calculated by passing from left to right (the forward pass). The latest permissible times to finish activities can be calculated by a backward pass which identifies the float or amount of slack available for starting and finishing an activity.
The chain of activities where the earliest and the latest times coincide showing a zero float also show the completion of the project in the earliest possible time - the critical path. A worked example of which can be seen at: <http://www.mindtools.com/critpath.html>
All projects have elements of risk associated with them, largely because they involve new activities and innovative work. A general analysis of the risks associated with the project should be performed at an early stage to identify them and scope their potential impact.
For a digitisation project, an analysis of risks would include consideration of factors such as:
Staff: do you have the right mix of people and skills employed on the project?
Equipment: is appropriate equipment in place? Is it reliable?
Dependencies on external factors: extent to which successful delivery of the
project relies on external parties, such as other consortia members or suppliers.
Extent of innovation or novelty of project: to what extent does the project involve
new and innovative work?
Risks can then be graded with a hazard rating low, medium and high and the likelihood of their occurrence estimated. Contingency and containment plans for activities with a degree of risk associated with them, should be created which include any relevant adjustments to timescales and costs.
For a more detailed analysis of the likelihood of identified risks occurring, software is available for calculating statistical probabilities, such as OPERA which is part of the Open Plan Professional system.
A more detailed exposition on risks and risk management can be found in Chapman and Ward 1997 [5].
Project activity is costed at the bidding stage. This is a critical stage and you should ensure that all activities and resources included in the proposal are costed as accurately as possible. Requirements of funders will differ, but it is usual that the bid includes quotes for large items of expenditure such as equipment or specialist services that you intend to contract out. NOF-digi projects, for example, were required to obtain at least two quotations for all capital and revenue costs contracted to external suppliers.
Personnel departments should be able to provide information on staff costs. Don't forget to include the total cost of employing staff in your overall project budget (i.e. recruitment, salary, employers National Insurance and pension contributions as well). Other costs such as travel or the production of promotional materials for example may have to be estimated as accurately as possible. Your budget should also include office accommodation costs for staff and overheads such as heating and lighting.
Closely defining the budget at the bidding stage will be helpful when you later go on to plan the project in detail and finally implement it.
It will be the job of the project manager to ensure that the aims of the project are met whilst keeping expenditure within the limits of the budget. Thus monitoring spending throughout the duration of the project is critical. Expenditure monitoring and reporting should be built into the project plan. You may expect, for example, that monthly reports on expenditure are presented at project meetings. In addition to monitoring and reporting for internal purposes, funders will usually require regular updates on expenditure. For example the NOF-digitise programme required projects to make quarterly progress reports throughout the payment period of grant. As staff effort is likely to be a significant resource, you should consider using timesheets to monitor effort. These are particularly important if staff are only spending part of their time on the project. Depending on how the project plan has been compiled, you may want staff to breakdown their effort into the identified tasks and workpackages of the project.
When costing activity you may also want to take into account the potential your project has for income generation. Consideration of this could also occur at the stage of the project where exit strategies and sustainability of the project once the initial funding has ceased are under consideration. For a discussion of these issues, see the section on Income Generation and Sustainability.
Once implementation of the project has begun, progress must be monitored. Various routine staff management and supervisory approaches can be adopted or more formal methods introduced where updates on tasks are gathered regularly. Reports may be produced as part of this process. One type of monitoring is to use exception reports which only cover areas or activities which are at variance or diverging from the plan. The advantage is that "paperwork" is kept to a minimum and only appropriate level of detail and content is passed up the management chain. However the drawback of this approach is that it relies on good team communication and awareness to ensure that the project manager is kept informed.
Regular management and financial reports with expenditure monitoring are essential and are frequently a requirement of the funders. The NOF-digitise programme required that quarterly progress reports be completed and submitted to coincide with the revenue payments cycle. These reports followed the format of the NOF-digitise business plan and required reporting on the progress of individual work packages, income received and expenditure by the project during the reporting period and any variations to cashflow forecast in the business plan, as well as a checklist of compliance with the Programme's technical standards. In addition to this, organisations are required to complete an annual monitoring return once services are publicly launched, in order to monitor the benefits the digitised materials are delivering.
A project generates a large amount of documentation. There will be a project plan which is constantly updated. There may be an evaluation plan and a dissemination strategy. There may be a technical or requirements specification, software documentation and user guides.
There will be interim reports and more lengthy annual reports and regular summary updates for the funders.
There may be notes from project team meetings. More formal meetings with stakeholders or with consortia partners will have agendas and minutes.
In all cases, version control is vital to maintain an audit trail and for archiving purposes, it may be necessary in larger projects to consider some form of document management system.
Depending their size, projects may have only one or two staff or comprise of multiple teams with many team leaders reporting to the project manager. In larger organisations, a project director may manage multiple projects.
We have identified five key roles within a digitisation project whist acknowledging that there will be additional roles depending on the nature of the project, which could include designers, digitisers, interpreters etc. Whilst the Project Manager and Technical Officer would normally role assigned to individuals, the other roles would not necessarily be ascribed to specific individuals as each project will need to determine its spread of roles and posts according to its individual circumstances.
Project Manager: responsible for managing resources including the project team and the overseeing the budget
Technical Officer: responsible for systems maintenance, software development, and providing technical support to the project team
Information and Communications Officer: responsible for creating and implementing a dissemination/marketing strategy
Evaluation: responsible for creating and implementing an evaluation plan
Learning resource creation: responsible for developing learning resources from digitised content
More detailed job description templates for the first three of these posts are given in the section on Human Resources.
A project is more likely to be successful if the team is working well together and the team dynamics are good. More detailed information on building successful teams and the various roles identified within a team is provided in the Human Resources section.
Projects should normally have a Steering or Advisory Group. This is a group of experts, stakeholders or other interested parties who meet on a regular but infrequent formal basis (e.g. two to four times a year) to advise, guide and help the project team. They should also receive more regular reports so that they can maintain an overview of progress between meetings. There is usually a representative of the funding agency and a senior member of the host organisation. Sometimes if appropriate, there may be "user" representation.
Updates on progress, finance, evaluation, dissemination and future plans are common agenda items. The meetings are often chaired by a senior representative of the organisation.
It is advisable to establish agreed Terms of Reference at an early stage to guide the activities of the Steering Group. The name and membership of the group will need to be agreed and a draft set of terms is listed below which covers conduct of meetings and functions of the group.
Conduct of meetings:
Functions of the group:
Steering Groups can be very useful fora for airing ideas, testing political views, seeking external expert advice and gaining support for particular approaches.
There are many benefits both for programme administrators and applicants of consortia working. At a practical level, good value for money will be achieved through, for example, eliminating duplication of effort, using economies of scale to good effect and sharing experience and expertise. At programme level, the themed-bid consortium approach will deliver the basis for a coherent, managed body of content consistent with other major national initiatives. It will also offer added value and greater potential for sustainability.
The NOF-digi programme, for example, defined three models of consortia working:
Managing a consortial project is more complex than running a project from one organisation. There are inevitable additional politics to negotiate, more complex finances to manage, an increased need for good communications, particularly between teams and individuals at different locations, and more complicated planning. Whilst more frequent progress meetings may be desirable, there is an increased cost associated with bringing people together face-to-face and video-conferencing or conference calls are ways of achieving discussion without unnecessary expenditure.
Partnership agreements or a letter of understanding should be drawn up between consortia members. The agreement should outline how the services/activities are to be shared between partners, their estimated costs, the proposed structure of the partnership and how it will be managed. It is essential to consider how disagreements between partners would be dealt with and what to do if you find that your consortium cannot move forward, particularly where you are adopting the fully or partially integrated consortia models. There are various mechanisms you could use, such as agreeing to majority voting procedures, or alternatively the steering or advisory group could arbitrate in disputes.
The robustness of the partnership agreement depends on the level of integration of the partnership. Partners in fully integrated consortia who have delegated responsibility for their projects wholly to the lead partner will need to ensure they have a detailed agreement with the lead. Consortia where one partner is taking responsibility for services on behalf of other partners and thereby creating a dependency which could affect the outcome of their project may need a less rigorous agreement.
It is recommended that agreements are checked by legal representatives and that periodic reviews are built into the text.
As part of the standard process for assessing and selecting suppliers, projects will obviously be checking for the financial longevity/strength/suitability of suppliers. Whilst consultancies will have specialised tools for such purposes, it is sometimes difficult for culture-sector organisations to establish their own accurate information.
Some potential sources of this information follow, most of which offer some information for free and some at a cost:
http://www.companieshouse.gov.uk/
The home page for Companies House, provides basic name/address listings and status for free;
reports and accounts can be downloaded at a cost.
http://www.businesslink.gov.uk/
Your local Business Link will usually have an information team who can provide
tailored reports (usually at a quite reasonable price). The following link will
take you to a searchable directory of local Business Links:
http://www.businesslink.gov.uk/bdotg/action/directory
The Business Links may also be able to review sole traders, as most credit
referencing/business scoring agencies will not store information on such businesses/individuals.
http://www.192.com
Finally, a less "official", but potentially effective service is 192.com,
which provides a range of personal and business services. The range of information here is broad.
As an aside, if you are concerned about your own data privacy, have a look at
http://www.192.com/privacypolicy.cfm
- you have the ability to remove yourself from their lists.
This section is available at <http://www.ukoln.ac.uk/nof/support/gpg/HumanResources/>
Human Resource Management is concerned with the processes of acquisition, development, motivation and maintenance of people. We will be focusing on the recruitment and selection of staff, team building and the roles that individuals play within teams, and the training and development of staff.
Projects by their very definition are finite activities with staff employed or seconded to the project team for the fixed duration of the project - which can vary from a few days or weeks to a number of years. The short-term nature of project work can be challenging to the management of people. Because of the short time scale you need to ensure that the right people are recruited to the project as there will often be little time for extensive periods of training to get people 'up to speed'. Indeed training and development of project staff can often be overlooked entirely whilst the goals of the project take priority. This is a rather short-term view however as effective training and development can lead to greater motivation and satisfaction of staff; both of which can be beneficial to the achievement of the ultimate aims of the project. A successful project will often lead to follow-on activities being developed and staff from the original project will go on to manage and develop these subsequent programmes. You also need to be aware of how project staff will fit with your existing staff and organisation structures. It can be a cause of resentment amongst existing staff if you have to pay more to recruit good, IT aware staff, for example.
Recruitment and selection are fundamental in the HR management process particularly, as we have explained, when managing project work. It is recommended that some time is spent establishing the 'profile' of a vacant post through the three documents of job analysis, job description and person specification.
The first step in recruiting to a vacant post is to carry out a job analysis to identify the:
The information identified for the job analysis provides the data used in the job description and person specification.
A job description states the purpose, responsibilities and reporting structure of a job. It clarifies exactly what a job involves and provides the individual, their line manager and others in the organisation with a clear picture of the purpose of a post. Documenting tasks and responsibilities provides an opportunity of ensuring that these are always contributing to the overall aims of the project. As well as a recruitment tool the job description is a valuable documents for individuals. Having a set of defined job tasks and responsibilities is an aid to self-evaluation and can be used for initiating an appraisal discussion or other staff development activities.
The exact layout of the job description will depend on your organisational circumstances and in-house practices but it should include the following:
Title: which should be descriptive of the post
Purpose: probably one sentence describing the overall purpose and objectives of the job
Reporting structure: job titles of the line manager and any posts reporting to the post
Tasks and responsibilities: a list of responsibilities and duties which should be clear and precise, using adjectives such as 'designing', 'planning'; avoid vague terms such as 'in charge of'.
Scope of the post: an indication of the importance of the job, how it fits into the organisation, external contacts
Other information: statements on (for example) equal opportunities and other terms and conditions of employment.
Templates of job descriptions for the key roles of Project Manager and Technical Officer have been provided. The bullet pointed suggestions of areas to include in the descriptions can be included/excluded as required. It is acknowledged that organisations may have their own 'house style' and that local recruitment practices will have to be followed. However the templates included here are an attempt to demonstrate best practice in HR management.
In addition to the job descriptions, a list of tasks and responsibilities for information and communications activities have also been provided.
Project Manager
Purpose
To define, plan, schedule and control the tasks that must be completed to achieve the [project] goals.
Reporting structure
The post-holder will be a member of the [team/department etc.], supervise the work of the [project team] and will report to the [Job Title].
Tasks and responsibilities
General activities:
Contacts outside of the organisation
Maintain contact with the funding body and join all relevant mailing lists.
To collaborate with other projects and other relevant organisations tasked with similar work.
Equal opportunities
The post holder will carry out their job responsibilities with due regard to the organisation's Equal Opportunities policy.
Terms and conditions
These will be stated in the Contract of Employment.
Date of completion: xx xxx, 2004
Technical Officer
Purpose
To contribute to the development and management of a Web-based project delivering digitised learning materials to the public.
Reporting structure
The post-holder will be a member of the [team/department etc.], supervise the work of the [xxx] and will report to the [xxx].
Tasks and responsibilities
General activities
Contacts outside of the organisation
Liaise with any Technical Support Services from funders
Join appropriate mailing lists
To collaborate with other projects and relevant organisations.
Equal opportunities
The post holder will carry out their job responsibilities with due regard to the organisation's Equal Opportunities policy.
Terms and conditions
These will be stated in the Contract of Employment.
Date of completion: xx xxx, 2004
Information and communications tasks
In addition to the specific posts of project Manager and Technical Officer, it is likely that staff employed on the project will be carrying out tasks associated with information and communications activities. Whilst most projects may not have a specific person dedicated to these tasks (unless the project is very large) they are crucial tasks and should be incorporated into the work of others employed on the project.
The purpose of such tasks will be to:
To develop and implement a dissemination/evaluation/marketing strategy for the [XXX] service.
Tasks and responsibilities would include:
The person specification relates to the human characteristics and attributes that are considered to be necessary to perform the job effectively. They outline the attributes a candidate should possess to be suitable for the post. These attributes are usually divided into those that are 'essential' and those that are 'desirable' and would include:
Skills: that the candidate should have or be capable of acquiring to be able to perform the job effectively
Knowledge: technical, professional, administrative or organisational relative to the effective performance of the job
Experience: amount of relevant experience necessary in relation to the requirements of the job
Attitudes: behavioural qualities such as ability to work in a team, take initiative or work without supervision
Two well known and widely used methods used for compiling person specifications are Rodger's seven-point plan and Fraser's five-point plan which use criteria such as attainments; general intelligence; special aptitudes; disposition; and circumstances, impact on others; innate abilities; and motivation [1].
Once the recruitment documentation has been drawn up and you are ready to advertise, you will need to decide whether you are going to recruit new staff from outside of the organisation or redeploy existing staff.
Recruiting externally is likely to be more costly and will usually take more time, however it will introduce 'new blood' and fresh ideas into the organisation.
Recruiting internally is likely to be cheaper and quicker (but you can be left with another vacancy to fill). It does however give existing staff the opportunity for development and their existing knowledge of the organisation can be a benefit. They will also probably need less time to 'settle into' their new post.
Staff within the organisation who are keen to be considered for secondments to project work could be encouraged to keep up to date copies of their CVs on record. Then, when vacancies do arise the requirements of the post, as identified in the job analysis and person specification can be matched with the skills and attributes of existing staff.
An alternative to recruiting to fill a vacancy might be to contract out the work. Although this may initially be more expensive you can save time by contracting for specific items of work to be completed to a fixed timescale. If you employ a contractor you will immediately have someone on site to carry out specified work without a 'lead in' time for training or induction into the organisation. You can also save on having to purchase specialist equipment. Outsourcing particular activities allows you to get in the expertise that you don't have and can't easily recruit for in-house - especially if it is for a very particular or specialised skills set. Indeed for less experienced organisations outsourcing (digitisation) work may be particularly appropriate. However, do bear in mind that if you do outsource work the opportunity is missed to develop new skills in-house for the future and by using subcontractors existing staff are not given the chance to develop new skills. There may also be issues relating to pay and conditions if contractors, who you would expect to pay substantial more for a fixed, short term period, are working alongside employees of the organisation.
You could also consider outsourcing specialist tasks, such as bulk scanning for digitisation, for example, to agencies. The work would normally be carried out off site, at the agencies premises. This would be particularly appropriate if the activity is a one-off, where training your staff would not be cost effective and would require the purchase of expensive equipment that might only be needed for a short time.
Well-qualified staff with appropriate technical skills are in short supply, particularly in the public sector so you should think carefully about targeting your recruitment advertising to make the best use of limited recruiting budgets. Vacancies may be suitable for recent graduates from local universities and colleges for example, so you might consider getting in touch with appropriate college departments who may advertise posts at little or no charge. You may have to be prepared to offer on the job training for someone with the technical skills but who lacks knowledge of your organisation or community. When recruiting for specialist jobs, such as highly skilled technical staff, recruitment agencies may be useful.
Once they have been recruited, retaining staff on a fixed term contract (if it is for a longer period) or to work on future projects and activities can be difficult. Ideally you should be able to offer the same levels and quality of training and development including appraisals and career guidance to project staff as that which is available for all permanent staff in the organisation. As well as formal training and development activities however, there are a variety of other initiatives that can provide the motivation and job satisfaction that staff need to encourage them to remain with the project/organisation.
Digitisation projects will range from small teams of one or two people to projects consisting of multiple teams reporting to the project manager. Whatever the size, there are some basic elements of team building and the roles that individual perform within the team that it is useful to be familiar with whether you are managing or contributing to a team.
A team is a small number of people with complimentary skills who are committed to a common purpose, performance goals and approach for which they hold themselves mutually accountable [2].
The effectiveness of a team depends to a large extent on its members. Appreciating the particular skills and attributes of team members and understanding the roles that individuals are best able to play will ensure that a team has the full range of skills and attributes it needs to be effective. Belbin, through extensive research has identified nine team roles that are important to a team and which individuals may have as strengths or weaknesses. Individuals can play one or more of these roles and each role has positive and negative aspects, which it is important for other team members to recognise.
The absence of some or any of these roles can reduce team effectiveness whilst too many individuals playing the same type of role in the team can cause friction and damage the team effectiveness. The team roles are as follows:
Co-ordinator: able to see clearly team objectives and is skilled at inviting contributions from other members. Recognises others strengths and weaknesses, less good at crisis management, likes participative, consultative management style.
Shaper: drives the team to get things going, promotes own views, can be pushy and aggressive.
It is usually co-ordinator or shaper types of individuals that assume leadership of a team.
Plant: source of original ideas and challenges the traditional way of thinking, not such a good communicator, can be over sensitive to criticism or praise.
Resource Investigator: good at bringing in information and support from outside, outgoing and communicative, good negotiator, strong networks of contacts. Can be quick to lose enthusiasm for tasks.
Implementer: good at turning big ideas into manageable tasks. Disciplined, conscientious, practical, trusting tolerate, but degree of rigidity, not always open to new ideas.
Team Worker: most aware of the needs and concerns of others in the team, sensitive and supportive, will build on others suggestions, but lacks leadership.
Completer/finisher: drives the deadlines and makes sure they are achieved, good attention to detail, high standards but intolerant of those that do not share same standards.
Monitor/evaluator: can see all the options and has a strategic perspective, but can be over critical.
Specialist: provides specialist skills and knowledge, has dedicated single-minded approach.
The roles described above are extremes of behaviour and an individual will usually be strong in one or two areas and weak in others. The important point is that teams that are well balanced in terms of the roles that their members play will be more effective than teams where one or more of the essential roles are missing [3].
In real life of course it is not always possible to select the exact balance of attributes to form a balanced team. But by being aware of the team roles it is possible to know why some teams are more effective than others and be able to recognise shortcomings within the team [4].
To maximise team performance the team leader needs to:
Effective teams are characterised by:
They depend on:
Motivating factors of teams:
Demotivating factors of teamwork:
Training and development of staff should be a major area of activity for all organisations. Staff are the most valuable asset an organisation employs, and therefore developing their potential to assist in achieving the aims and objectives of the organisation and project is critical. And, as we have explained in previous sections of this manual, effective development and training can be a positive force in recruiting and retaining staff onto project work. In this section we will identify some of the more widely used development activities and suggest strategies for maximising job satisfaction.
The staff development and training process benefits the organisation and the individual at all stages of their career:
Stage 1: Recruitment and induction
Benefits to the organisation
Benefits to the individual
Stage 2: In-service training
Benefits to the organisation
Benefits to the individual
Stage 3: Moving on/career development
Benefits to the organisation
Benefits to the individual
Appraisals provide a framework to facilitate communication between the individual and their manager. The individual and organisation will only benefit from the process if all understand the purpose of the appraisal system and the benefits that can be delivered. Appraisals can have a number of objectives:
Performance review: identifies training needs, provides motivation, praise and constructive criticism. The aim is to improve the performance of the individual by reviewing existing performance and deciding on future goals and training needs. Staff need their managers view of their existing performance in order to be stimulated to improve.
Potential review: predicts the level/type of future work an individual could do. Identifies potential for possible internal promotion.
Reward review: allocate rewards fairly.
An important objective of all appraisals is establishing effective two-way communication between the appraiser and appraisee. Many staff welcome systematic feedback on their performance and advice on how to improve. Appraisals need to be viewed in association with training and development; organisations must be able to deliver training once it has been identified.
Implementing appraisals
It should be appreciated that the appraisal is a very personal experience. It must be confidential and staff must feel confident to speak frankly about their strengths and weakness and any problems they may be having. It must be made clear to all staff that all records of the appraisal are confidential.
To implement an appraisal system successfully the benefits must be made clear to staff. The aims of the system should be clearly started and the process explained. Management must show commitment to the process and staff must be able to see the outcomes of the process. The developmental role of appraisals should be emphasised rather than a management/control role.
A clear structure must be established for the meeting. Appraiser and appraisee should complete forms before the meeting and an agenda should be agreed.
Prior training should be given for both roles.
An appraisal is an important occasion and should be treated as such. A degree of formality is necessary, there should be no interruptions during the meeting for example. If a system is imposed without the aims being adopted by staff there is a danger that they will simply 'go through the motions' and not benefit to the fullest extent.
Performance should be reviewed in the light of goals set in the previous year. Actions set as outcomes of the appraisal need to be regularly and effectively followed up throughout the year.
It is necessary to monitor and evaluate the process in order that it can be developed for continued success. Views on the success of the system should be sought from all participants.
The training needs of individuals can be identified by conducting a training needs analysis and/or as part of the regular staff appraisal system.
Training can involve staff attending specific in-house or external training courses, conferences and workshops. Other training activities include:
The training and development process should be monitored and evaluate and feedback should be sought from all participants through forms/questionnaires/interviews.
The activities listed below can all contribute to the development of an individual, but are worth considering in addition to more formal training activities.
Job enlargement: extra tasks at same level of responsibility, increased variety.
Job enrichment: more responsibility and autonomy (balance with the danger of exploitation).
Job rotation: change tasks every six months, long enough to understand all processes.
Work shadowing: within own organisation or outside, watching how other jobs are performed, gaining an insight/different way of doing things, makes you think about the way that you are doing your job.
Job exchanges: actually doing someone else's work, longer than shadowing, not substantially different work from your own.
Secondments: to project or specific job for a set period of time, need to fill seconded employees job during the period of secondment.
Conferences: presenting project outcomes and experience as part of the dissemination activity.
Training courses on all aspects of managing (digitisation) projects are widely available. Some organisations that provide courses, which may be of particular interest, are listed below.
TASI Training Programme
http://www.tasi.ac.uk/training/bookingform.html
HEDS presentations are available from the conference held in June 2001 on planning and
implementing a digitisation project.
http://heds.herts.ac.uk/conf2001/conf2001.html
LA Training and development
http://www.la-hq.org.uk/directory/training_dev.html
ASLIB Training
http://www.aslib.co.uk/training/
Compiled from material within the University of Bath Safety Manual.
Under the provisions of the 1974 Health and Safety at Work Act both employers and employees have responsibilities with regard to safety in the workplace.
Use of computer equipment can lead to lead to problems such as muscular skeletal disorders and eyestrain. The Health and Safety (Display Screen Equipment) Regulations 1992 governs the use of computer equipment at work. Computer workstations should be periodically assessed for their compliance with the provisions of the Act. An assessment should cover the following factors:
Display screen: is this adjustable for tilt and swivel, brightness and contrast? Are screen images clear, stable and free from flicker? Is the screen free from glare and reflections?
Keyboard and mouse: does the keyboard have a shallow slope to it, does it have a separate numeric pad? Is the mouse positioned as close as possible to the keyboard? Is the mouse suitable for use with the user's dominant hand?
Software: is computer and software sufficient for tasks undertaken? Has suitable training been provided for the software used?
A good workstation requires good ergonomic design to allow a comfortable working position. Good posture is vital for preventing physical stress and fatigue, especially to the wrist, arms, shoulders, neck, back and legs.
Seating: a comfortable chair made to BS 5490 is essential for achieving a comfortable working position. However, there is some variation and one model may not suit everyone. Many users prefer a chair with arms. However, arms can prevent a user from sitting close enough to their desk so care is needed during selection. Adjustable (especially adjustable "T" shaped arms) or removable arms permit the greatest flexibility. Many users have found a back roll to be highly beneficial. These are relatively cheap, but they improve support for the lumbar region and encourage good posture. Various sizes and shapes are available.
Setting seat height: chair height should be set so that your elbows are at the same height as the middle row of keys on your keyboard with your forearms parallel to your desktop. In this position your wrist should be in a relatively neutral position while you are keying. Help from a colleague can often be helpful when finding this position. Periodic readjustment may be necessary to maintain a comfortable working position.
Foot rests: some users may find that when their seat is set up at the correct height their feet cannot be comfortably placed flat on the floor. This can cause discomfort due to pressure on the thighs. An adjustable footrest should be provided in these circumstances.
Setting monitor height and position: with your seat set at the correct height you should be looking slightly downwards at your monitor. This places your neck in a comfortable working position. If you have to look upward or too far downward this will place a strain on your neck muscles. The minimum viewing distance should be 400 mm. The user should sit square on to their keyboard and monitor otherwise the user has to adopt a twisted posture. This can contribute to neck and back problems. Monitor screen displays should be clear and free from flicker, glare and reflections.
Keyboard and mouse position: the keyboard and mouse should be placed within easy reach during use. Stretching to reach a keyboard or mouse can cause arm, shoulder and back discomfort and should be avoided. Keyboard and mouse mat wrist rests are popular as they can increase comfort.
Working practices: to prevent eyestrain you should work away from the monitor for brief periods during the day. A 10-minute change of activity after 50 minutes of monitor work is usually enough to prevent the onset of eyestrain.
Office environment: is the lighting suitable and sufficient during both daylight and night time hours? Is noise generated in work area acceptable? Is space in the work area sufficient for the number of persons & the equipment & furniture provided?
This section is available at <http://www.ukoln.ac.uk/nof/support/gpg/ProcurementTendering/>
Digitisation projects will inevitably be dealing with other companies, whether as a result of outsourcing particular tasks, such as web design, digitisation or programming, or in order to procure services supplies and equipment, such as systems, scanners or computer software. Working with limited budgets, and within the public-sector domain, it is essential that projects get value for money when involved in obtaining such services or equipment. This section of the guidebook offers advice on the process of procuring such equipment or services. While each project will have different purchasing plans, a generic set of guidelines offers some basic pointers in what can be a complex field.
Before starting any procurement process, it is worth establishing whether it is essential to purchase. There may be the possibility that your organisation or a related institution already has the piece of equipment required, and organising the temporary loan of that equipment would be enough to suit your purposes. Alternatively, it may be possible to hire the equipment in question. Hiring for a three year period, especially in the case of IT equipment, can often be cheaper than outright purchase, saving as it does on initial outlay and long-term maintenance costs. Equally, hiring temporary space via Web hosting services can be cheaper than purchasing dedicated system to run Web sites.
Solutions such as these are more suitable for short fixed terms, where project managers can be sure of the time for which the equipment or service will be required. The advantages of non-purchase can quickly evaporate should it be discovered that the goods in question are required for a considerably longer period than originally envisaged.
When participating in a large digitisation programme with many partner projects it makes sense to explore the possibility of joint purchase. Spreading expenses among several institutions or projects can greatly reduce the cost of equipment, or services. It is especially apposite for expensive technology that is essential for a small number of tasks, as opposed to cheaper equipment that will be used on a more routine basis.
While initial costs might be lowered by joint purchase, it can result in greater pressure on project managers to organise the use of the technology. If careful attention is not paid to the allocation of the equipment, there is greater possibility for workflow bottlenecks. There is also more likely to be a greater number of bureaucratic obstacles during purchase, and, in the long-term, possible disputes over final ownership of the equipment.
Competition is the essential factor in the procurement process. There are very few products available where no choice is available. Purchase of any goods or services will involve the comparison of possible suppliers followed by the considered selection of the option that offers the best value for money. Value for money, however, should not be taken to indicate the cheapest purchase price. Customers need to consider a range of criteria and choose a product that will work for the specific aims of their project. If these aims demand an expensive outlay then projects must be prepared to accept this. Ignoring these aims for the sake of finance will only cause problems later on, and may eventually lead to greater expense.
The time spent on a procurement process should be related to the expected outlay. Extended deliberation is required for the purchase of goods or services that are expensive and of essential strategic importance to the project. Project managers need spend less time on the process as expense and importance decrease. Indeed, in the case of cheaper goods, many institutions forgo procurement, as the resultant savings would not be worth the staff time spent on the process.
For some of the more standard IT goods (PCs, printers etc.), projects working within local authorities will already have specific suppliers nominated. The GCAT framework [1] supports those working within local authorities by providing a pre-tendered range of goods. Universities normally have their own purchasing offices or consortia that also provide a list of pre-arranged suppliers. When this is the case, the procurement process can become much simplified, individual purchasers dealing with one or two particular suppliers. However, when there is no such arrangement, it is essential that projects consider various possible suppliers to achieve value for money. The NOF-digi programme stipulated that for purchases estimated to be between £500 and £4999, two quotes were sought, while three quotes were sought for any amount of £5000 and above.
Most institutions specify that for a projected outlay over a certain cost, the procurement must involve formal tendering procedures. The essential element of any call for tenders is the composition of a detailed specification. The purpose of the specification is to describe clearly and accurately a project's essential requirements in terms of equipment or services. A specification will form the basis of all offers made by potential suppliers, and act as the foundation for any later contract. If a specification is not well prepared there is greater likelihood of vendors failing to deliver the aims expected by a project, or not even offering their services. Creating a clear specification also permits suppliers to formulate quicker, more accurate and less costly responses.
Specifications should be based around the following key sections: procurement aims/background, statement of requirements and the selection process. Depending on the nature and cost of the goods or services under consideration, project managers may wish to include other particular sections in their specifications. This might include a table of contents, security issues, training requirements, delivery terms, a glossary etc. However, such sections are often subsumed within the statement of requirements section.
The first section of a formal tender should include a declaration of the project outcomes that the customer requires the vendor, via its equipment or services, to supply. Each outcome should be succinct and not more than a short paragraph, or even a single sentence. The specification may also articulate how the tasks required of the vendor will slot into the high-level goals of the project. So a project specification might begin by declaring that the project is looking to have a Web site developed as part of its remit to deliver learning packages associated with its collection of digitised images. Another project might indicate that, as part of a regional consortium, they are looking for a digitisation bureau to digitise its collection of local nineteenth-century newspapers.
The project aims should be placed in the context of a summary of the project's background, introducing readers to the purchasing organisation. As well as explaining more about the eventual goals of the project, this background information may provide a summary of what decisions led to the purchasers putting out this particular call for tenders.
This is the key section of the specification document. It identifies the performance requirements (for equipment and services) or outputs (for services) or functionality (for software) that the project requires, and gives details of how these requirements, outputs or functions will be measured once a contract has been signed. While it is likely that these elements will be refined during the course of the tendering process, specification writers should ensure the details are as precise as possible so vendors are clear about the parameters of the project's needs. Projects need to make a close examination of their workflow, pinpointing each section where work done by the suppliers will have an effect. Each of these sections should then be converted into a requirement or series of requirements. It is important not to include requirements that could be broken down into others. If a project fails to clarify its precise needs, then suppliers will be slower in offering effective responses. Any programme-level or funder-stipulated technical standards will have to be included into the document, such as, in the case of the NOF-digitise programme the nof-digitise Technical Standards and Guideline [2].
For outsourcing the digitisation of a set of images, some of the requirements will again be shaped to fit the technical standards (for example, the required format/s) whilst others will be dependent on the particular demands of the project (for example, delivery of a certain number of images per month). So that the performance of the digitisation unit can be examined, quality-control tests would also be included in the statement of requirements.
It is highly likely that some requirements will be of the utmost priority, whilst other will not be quite so important. Therefore, it is often worthwhile ranking each requirement as being mandatory, highly desirable or desirable. Being able to rank requirements will also allow for greater flexibility when it comes to negotiating and refining the specification with suppliers.
The selection process should offer the potential supplier details on how to respond to the call for tenders. It should outline what structure any replies will take, and the level of detail required. It is prudent for purchasers to ask for additional information such as general company information and reference to similar work that potential suppliers have done in other projects. This could include the contact details of previous customers, who might be able to provide their own assessment of the company in question.
Administrative details such as the project contact point, the relevant address, and the number of copies required should all be included. A timetable indicating deadlines for initial responses, negotiations and acceptance of the final tender should also be present.
Specifications often give a brief indication of how the tenders will be assessed, indicating any particular criteria that have been established. These criteria should be weighted by relative importance. Including such information allows the vendors to produce tenders more focused on the project's requirements.
Once a specification is complete it can be placed within a formal document, ready to be disseminated as a call for tenders.
If the contract is likely to be over a certain amount, it is necessary to follow European Union Directives on Tendering. At the moment the threshold is £153,376 for services or supplies, this level having been set in January 2004. All projects that are intending to make purchases over this amount must advertise their call for tenders for services or supplies in the Official Journal of the European Communities. Additionally, the EU directives stipulate that tenders cannot be received until a set number of days after the appearance of the advertisement in the Official Journal. This delay is in the region of five to seven weeks. More information on the directives is available from the EU Web site [3].
Should the projected outlay for procurement be below the levels prescribed by a project's host institution, then there is no formal need to construct a specification. Nevertheless, projects should still develop their own internal list of requirements for a particular service or piece of equipment. Creating such a document can serve many of the useful functions that a specification document serves in projects following formal tendering procedures.
Having completed a specification or list or requirements, purchasers must seek out potential suppliers in order to obtain a quote or notify them of the existence of a call for tenders. This can be tricky, especially as there are numerous competitors for IT goods and services. In some cases, previously-used suppliers might be able to offer their services or equipment. In other cases, however, it will be necessary to locate new suppliers. Initial research via the Internet, the relevant trade magazines etc. is a time-consuming process, but will give one a broad idea of the purchasing environment. Trade shows at professional conferences and commercial exhibitions, such as the Online Information show [4], are also helpful, allowing purchasers to compare quickly a large number of potential vendors. This should be accompanied by recommendations from colleagues, consortium partners, specialised review sources etc.
Once suppliers have been notified about the existence of a call for tenders, placing the contents of the call on the Internet can facilitate responses.
When tenders and quotes do arrive from potential suppliers, it is important to scrutinise the documents with the same care that went into developing the list of requirements. In assessing suppliers' replies, the actual financial cost quoted should only be one variable under consideration. The quality of the service or equipment supplied, possible maintenance or backup costs and, most importantly, the supplier's ability to perform the task according to the project's exact specifications, are all vital factors that need to be considered. Purchasers might also contemplate having pre-trials to test the particular equipment or service under question. This might be particularly useful when assessing candidate digitisation bureaux, where projects could offer a small section of their collection for test digitisation.
Purchasers should also make sure that the price is stable, or, if there are to be price increases over a period of time, the mechanism for determining such increases is transparent. Purchasers should also be aware of possible additional costs such as delivery and installation. There might also be hidden sundry costs - the cost and availability of spare parts and consumables required for the equipment to function, accompanying handbooks and instruction manuals, and any possible need for staff training.
One should also consider the broader history of the suppliers in question. Are they economically healthy (it is difficult to get maintenance support from a bankrupt company)? Do they have sufficient quality controls? Do they have a history of sustained after-sales involvement? As always, it is worth asking colleagues and other professionals in the field, as well as the suppliers themselves, about all these issues.
Once purchasers and suppliers have exchanged specifications and tenders, it is important to engage in more detailed negotiation/discussion. This may follow a shortlisting process, where the most unsuitable quotes and tenders have been discarded. Suppliers will expect negotiation; their first quotes may reflect initial reactions, and they will be interested in exploring the details of each specification. An active dialogue may suggest alternative approaches and new ideas of how to fulfil a project's aims. It is worthwhile negotiating with each potential supplier rather than restricting oneself to just one option, although good practice in certain organisations, particularly within local authorities, calls for purchasers to concentrate on negotiating with a single, preferred supplier. Sometimes, negotiation will lead to suppliers making a better offer. This can be a straightforward reduction in cost, but could also mean slightly different equipment or (for the purchaser) more convenient payment terms. But vendors may also offer additional facilities for the original quoted price, such as extra equipment or training, or additional 'free' after-sales support. Beware, however, of any supplier that cannot meet your essential outputs or requirements.
As with writing specifications, negotiation can be a tricky art; it is well worth using someone with experience in the field. Within local authorities, universities or other organisations, there may be someone within the purchasing office designated for such tasks. Alternatively, attendance at purchasing workshops [5], consultation of various briefing papers and case studies will help improve the novice's negotiation skills.
If permitted by the project's host institution, it is important that suppliers are aware they are involved in a competitive process (although it is not considered good practice to reveal the identity of their competitors nor their quoted prices). Suppliers will be more inclined to offer attractive deals if they think they are under-cutting their rivals. This process should be continued even when only one supplier remains, making sure that the chosen supplier is unaware they are the final choice.
During an informal tendering process, it is important to draw up a supply agreement once a supplier and purchaser have agreed on a deal. For more routine equipment, however, this may simply be a standard contract already developed by the suppliers. For formal tendering, the updated specification should be used as the basis for a contract stipulating the expected outcomes or services that the vendor will provide. Again, this should be done with care. Signing a contract makes the relationship between purchaser and vendor legally binding. Should there be any disputes at a later date, it is to this contract that both parties, and any legal intermediaries, will return. Ambiguities within or omissions from the contract could catch up with projects that did not pay sufficient attention to the details.
Signing a contract can often take longer than expected. Where purchasers are unsure about the possible ramifications of certain sections of the contract, experts from organisation's legal departments will need to be drafted in to clarify the situation. Even where the wording seems clear, it may be better to consult legal experts to ensure contracts are watertight. Suggestions from legal advisors may necessitate further negotiation between supplier and purchaser. Both parties must also make sure that any updates from the original specification are agreed upon and incorporated into the final document.
The core of the contract will be the updated specification. Other issues previously discussed between the parties will also be incorporated into the document, including ubiquitous issues such as price, method of payment, timetable for delivery, and specific issues relating to aspects of the particular purchase in question.
Once the relevant parties have signed the contract, the suppliers can commence delivery of their product or services.
1. Procurement aims
2. Statement of requirements - a list of detailed requirements, indicating each section of project where suppliers' work will have an effect. This will include:
3. Selection process
Links to two calls for tenders are listed here, providing some examples of how others have set out their specifications. Each call is for a different service or product and therefore has a different level of specification. Nevertheless the key elements outlined above are present - a list of procurement aims, a statement of requirements and details of the selection process.
The AHDS portal specification is available at <http://ahds.ac.uk/ahds_portal_specification.html>. This is a very detailed specification, indicating the precise technical requirements of the Arts and Humanities Data Service in the construction of its new portal.
A call for tenders put out by the Macauly Institute for the development of a national archive of aerial photography is available at <http://www.mluri.sari.ac.uk/landcover/tenders.doc>.
Further guidance and help on procurement and tendering can be found via the Web site of the Office of Government Commerce: <http://www.ogc.gov.uk/ogc/procurement.nsf/pages/CUPGuidance.html>.
This section gives an anonymous account of the process followed by one organisation in attempting to locate a Web site designer. It shows what steps were taken in creating a specification, developing a shortlist and then making a final selection.
1 Brief
1.1 The Project Team in consultation with the webmaster and Library and Information Services staff prepared a brief.
2 Invitation to tender
2.1 The project team prepared a long list of potential designers. Team members compiled a list of web sites with design and content features relevant to our project. Each institution was then contacted and asked for details of their designer, together with their comments on the design process. A further list of designers was compiled through responses to enquiries to a number of email discussion lists. In the end a long list of nine companies was prepared (which are referred to as ONE to NINE in this document). Of these one (FOUR) was selected on the basis of past association with the Institution. The remaining eight were selected against the following criteria:
2.2 Each was sent a copy of the design brief, together with more detailed information on the content, a sample pack of primary resource materials and a critical review of sites examined by the project team. Each designer was asked to submit a costed proposal to meet the requirements set out in the brief. Companies were also invited to contact the project team by email or telephone if further information were required.
3 Shortlist
3.1 Of the nine designers contacted, eight submitted costed proposals. One company (FIVE) was not able to submit a full proposal, but made a preliminary submission.
3.2 The project team assessed the proposals. Each proposal was rated against the following criteria:
3.3 The Table below summarises the main points considered for each designer.:
| Company | Comments | Shortlist |
|---|---|---|
| ONE | Addressed brief; concerned over navigation; costs £25,000 but not including project management | Y |
| TWO | Could not guarantee to meet timetable. Cost £12,400 | N |
| THREE | Misunderstood brief : overemphasis on database integration. Cost £28,200 | N |
| FOUR | Did not respond adequately to particular requirements of brief : more concerned with a 'generic' solution. Cost £22,300 | N |
| FIVE | No submission | N |
| SIX | Cost low; doubts over management and ability to deliver project of this scale based. Costs £6000 | N |
| SEVEN | Extensive relevant experience; sound technical approach; costs £24,200 | Y |
| EIGHT | Cost £42,000 | N |
| NINE | Relevant experience; addressed brief; Cost £28,900 | Y |
3.4 The designers had not been supplied with an outline project budget. Although the project team had allocated £20,000 for design many of the proposals were in excess of this. One proposal was ruled out on grounds of cost alone. The others were assessed against the remaining criteria and three companies were shortlisted. Before being invited in the companies were contacted and asked whether their costs could be reduced, and to revise their proposals to meet the outline budget. All three companies did this.
4 Selection
4.1 The shortlisted companies were invited to give a short presentation to the project team, followed by a discussion with the team and with the Webmaster.
4.2 The outcome of the selection process was as follows:
| Company | Comments | Selected |
|---|---|---|
| SEVEN | Liked the team; demonstrated obvious understanding of our material; own experience directly relevant; able to meet schedule and to meet outline budget. | Y |
| NINE | Good track record, but doubts over personality of team; lacked technical expertise and couldn't answer some questions; more used to working with larger institutions | N |
| ONE | Disappointing presentation; had not understood technical issues; did demonstrate any appreciation of the kinds of subject matter worked with. | N |
The company selected for the project is SEVEN. The team has directly relevant experience of producing web products based on similar materials. After negotiation, they were able to meet the outline budget cost with minimal changes to their original proposal.
This section is available at <http://www.ukoln.ac.uk/nof/support/gpg/CreatingOnlineLearningMaterials/>
Acknowledgements
This paper was originally commissioned by the New Opportunities Fund from Keith Shaw of Keith Shaw Associates and first published on the UKOLN Technical Advisory site in March 2002.
This section is based on the information paper which was provided for the NOF-digitise programme which provided advice and guidance to projects funded by the NOF-digitise programme on creating online learning resources. However the advice provided in this section should still be appropriate for new projects.
The use of information technology to deliver learning resources has a 30 year old history. There have been examples of outstanding success in this time as well as initiatives that have failed to engage the interest or motivation of the intended learners.
Success is associated with material that presents information in an active and engaging manner with much to commend it over more traditional learning methods. Interaction is more than simply presenting a limited range of objective style questions (predominantly poorly constructed multiple choice) or presenting material in a book-like manner. Best practice examples identify the circumstances in which the medium can make a unique and valuable contribution to the experience of learners.
It is important at the start of the development process to examine the questions 'for whom?', 'why?' and 'how?' which hold the keys to acceptability and success. Whilst the following is considered to be 'best practice' it is recognised that many projects will not have direct access to their prospective audience (as, say, a college would) so that addressing the following considerations will present a more difficult challenge.
'For whom?' is sometimes addressed rather superficially. The target population needs to be defined carefully and the desired learning outcomes specified appropriately for the audience. Analysis of what the learners currently know or can do, and what they need to know or be able to do, will identify the performance, knowledge or skills gaps (although in some cases this can be readily identified). A description of the desired learning outcomes, and how these will be recognised and assessed, should then follow.
Defining a target population includes describing their known or predictable characteristics, where the material is likely to be used and anticipated access environment. Characteristics include likely prior knowledge or experience, educational attainment, and anticipated familiarity with the media to be used for delivery. In some cases it may be desirable to state that prior knowledge is important and to provide references or links to other sources of information that will help to prepare the learner.
Defining the learners and the outcomes Developing a justification in response to the question 'What added benefits do online materials bring?' demands a rational analysis of the contribution the medium can make in the envisaged circumstances of application and identifying the features of the medium that create an advantage over alternative means of presentation?
One of the most powerful justifications is that the technology allows approaches which might not otherwise be possible, for example the simulation of events which are inherently dangerous, difficult or time consuming. Alternatively it can facilitate investigations which require accessing information from a variety of sources, analysis and application of this information, and solving problems or undertaking other challenges which actively engage the learner in making decisions and drawing conclusions. Transforming otherwise bland qualitative exercises into ones where quantitative exploration can be carried out through the rapid replication of otherwise tedious calculations and exploring 'what happens if …' is another valuable application. In all these cases there is the opportunity to create circumstances which lead to the establishment of understanding as well as acquisition of knowledge, and to create mechanisms whereby this understanding can be demonstrated and confirmed.
Other well rehearsed justifications are those applying to any open and flexible learning approach such as the ability to study at one's own pace, in a variety of environments and at a time of choosing. The starting point is often a desire to teach a larger body of knowledge or even a whole topic, even though it might be broken down into small, digestible, elements or 'learning objects'.
The challenge here is to avoid unnecessarily didactic approaches or the creation of electronic books. The outcome should warrant the justification that it gives rise to more effective learning. This leads on to the next question: 'how?' (ie. the design of the learning experience and the construction of the material).
A crucial task is the establishment of an appropriate development team with adequate resources. Successful teams require a variety of skills and expertise. People with an understanding of how technology can be applied to good educational effect, and experience of designing effective interactive learning materials (sometimes called instructional design), is very important. Equally fundamental is subject matter expertise, experience of mediation in the subject and graphic design. Other essential skills are a thorough knowledge of the capabilities and limitations of the technology and the ability to construct, implement and support the technical aspects of the project.
There are features of on line learning which make it unique in the spectrum of open and flexible learning technologies, such as the ability to communicate remotely with experts and other learners, and accessing other resources. These features can help learners manage and structure their approach to learning, and ensure that learning outcomes can be consolidated. Designing these types of experience presents new and complex challenges to the creators. They are deciding about more than content; they are designing a complete and integrated experience utilising a variety of resources and activities. They have to determine which features of on line learning to incorporate, such as communications with subject experts, communications with other learners, sharing applications and access to other Internet sites.
They have to devise the activities, research and review resources, determine appropriate strategies for the use of these resources, anticipate how learners might approach a discovery learning exercise, and ensure the structure is sufficiently flexible to accommodate the alternatives yet capable of delivering a coherent learning experience.
They also have to decide how the learner will be directed and supported. Too much freedom can create insecurity in the learner and inhibit learning, too little may frustrate the learner.
These heuristic approaches are lengthier and more costly to develop and implement than their more didactic counterparts. They also generate a number of interesting questions such as:
The advent of on line learning has raised a number of significant questions as well as creating a wealth of opportunities. These opportunities need to be exploited wisely and the mistake of assuming on line equates to intrinsically motivating must be avoided. Materials must be engaging and require active participation by the user; they should generate a desire in the user to learn and to develop. They should be sufficiently flexible to allow different modes of use and they should appeal to a wide variety of users at very different life-stages.
The diagram below illustrates the different stages that you will need to consider when planning your project.
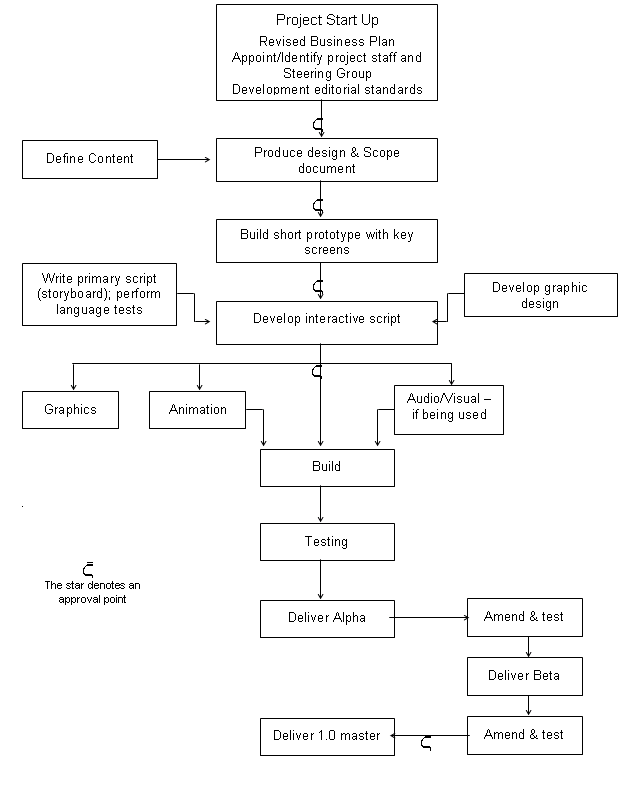
Figure 1: Stages To Consider When Planning Your Project
Standards should be established for spellings (e.g. -ise or -ize), abbreviations, punctuation, use of italics, emphasis, gender, style for lists, rules for numbers (in figures and words), spacing after full-stops and line spacing. Frequently used terminology should also be standardised at the beginning of the project - so that every team member uses the same terms.
The interaction of the learner with the materials is one of the most significant factors affecting how the learner progresses and should be considered central to the design of your materials. It is important that a clear approach to learning is demonstrated in the design. For instance, the materials might enable differentiation in subject, level, learning styles, learning rates and access to learning. They should also support learners with special needs, as far as possible. You should consider the following within the design of your materials:
Thought should be given to the functionality of the materials and any interactions to be used should be fully defined in your documentation. The following items should be planned and described:
The style of the materials will need planning and consideration given to the branding and overall graphical treatment.
Careful consideration needs to be given to the content and subject experts should be used to make decision about:
The structure of the material needs defining in terms of:
The number, the location and the characteristics of the learners should be documented. Characteristics may include familiarity with computers.
A storyboard sets out the content of the materials to be developed and describes the format in which it will appear in the finished product. It should be checked by the subject expert before it is committed to screen.
The storyboard is the presentation of the material to be delivered in the package in a narrative format, including screen content, audio script and a description of any interactions and graphics specified for each screen.
The storyboard should detail:
A storyboard can be used as a basis for testing ideas with potential users of the site, to help generate ideas and test your assumptions.
Creating the look and feel of your learning materials will probably be thought to be the 'fun' part of the project but if they are to be accessible to all groups of learners the design will need serious care.
You will normally have to comply with a set of issued technical standards and guidelines from your funders. Standards are designed to enable optimum accessibility and usability of the materials that you develop and to help preserve the materials for future re-use. Remember that users will include those with physical, language or cognitive disabilities, and those who are visually impaired and people who are hard of hearing or deaf. Some learners may have multiple disabilities. Other users will be using slow internet connections, or will be using a wide range of devices which will not support the use of plug-ins. You should consider testing your site with a text-to-speech browser at an early stage in the design process.
Some projects may additionally wish to consider recognising IMS Guidelines for Developing Accessible Learning Applications ( http://www.imsglobal.org/accessibility/accwpv0p6/i msacc_wpv0p6.html - note this is a White Paper due for release early in 2002 ).
The following notes provide important basic guidelines for screen design, use of text and graphics, navigation, multi-media, assessments and activities.
Screens should be uncluttered, and data and information should be ordered consistently, so as not to confuse learners with learning difficulties. Try to ensure that screen elements share similar appearance, location, and behaviour. The learner interface should be consistent throughout.
Try to use appropriate colours that all individuals can recognise, taking into account colour blindness. Use high contrast colours such as white on a black background, so that the text is clear to the learner. The use of more than five colours (including black and white) may be confusing. Where possible, use strong shapes as well as colour, to help learners discriminate between objects/images.
Present the key information at the top of each page.
Ensure all links are identified/named logically and clearly - a blind person may navigate using these. For example, "Click here" is not informative to the user.
Links to other pages or related resources need to be easy to find. Try to ensure that there are no more than three levels of menu before reaching the content. If links or resources are difficult to find then this will discourage learners, de-motivate them and they may lose their way. Ensure that the most used links come first so that if learners are using the tab key they will meet these first. Limit the number of links per page to about 20. Make sure there is space between the links.
Try to minimise the number of hypertext links that appear in a single line of text. In preference to this use vertical lists of links.
Menu options should be self-explanatory and limited in number.
Layout of Text - the material should be broken down so that between five and nine points are made at a time. This will avoid information overload and ensure that the learner can access the materials in bitesize chunks. Lengthy sections should be broken down into chunks and paragraphs should be kept short. Bulleted and numbered lists should be used rather than lists in prose.
Label graphical images with text (see below for use of Alt Text and Longdesc).
Icons should be clearly visible, customisable in size and named logically and clearly.
Try to avoid using images made up of bitmapped text. Screen readers cannot read the text contained in images.
Any interactive content that requires the learner to press a key should not be time-limited. Animations that use text should show the text long enough for a slow reader to read it. Essentially, this should be under learner control. Learner control should also be available for selection of sound and its alternative representation.
Document metatags should be used to improve searching. Ensure the search facility is forgiving in terms of spelling.
Consider a system for version control which will display the date, version number and the date it was created. This will assist in user-testing and piloting of your site.
Text should be a mixture of upper and lower case letters and should be left justified with a ragged right edge. The length of a line of text should ideally be between eight and twelve words for some user groups.
The clarity and legibility of information depends upon the visual contrast between fonts, text blocks, headlines and surrounding white space.
Do not specify the text in pixels as it is difficult to magnify. For more background information see - http://www.lighthouse.org/bigtype/universal_graphic_des ign.htm
Potential problems include:
Italic text - some learners may find this difficult to read.
Underlining text- this is also difficult to read and some users may think the text is a hyperlink.
Tables for formatting, because the cell contents may be presented in a wrong or misleading order. Tables to control text width may not work if larger (or smaller) font is selected; it is generally better to let users control the window size.
Flashing text - many users find this difficult to read - especially those with dyslexia or epilepsy.
Upper case text should be avoided, even in headings because it is not accessible to all groups of learners. Unnecessary capitalisation should be avoided.
Too many Acronyms and Abbreviations should be avoided as screen reading software may read them as a word.
Other considerations include:
It is recommended that animated or moving graphics are not used, unless the animation is necessary to illustrate important information, such as animation demonstrating how a machine works. It is best to place the animation on a different page, or to set it up to start only when activated by a mouse click or keystroke.
The size of text and graphics affects usability as well as accessibility. For those with visual impairments, magnification can make the difference between being able or unable to use the application.
Where multimedia is used, displaying more than three rows of text at once may prove impractical, as the viewer may have difficulty reading the captions and keeping up with the video.
There needs to be an easy-to-use facility to print, copy and save the desired portion of text (as a text file - not HTML) or a picture.
Provide information for learners to change their default settings. For more background information see http://www.lighthouse.org/text_only/t_about_browser.htm
There must be keyboard access for all menus, controls and buttons, in the form of single key. Note that these may already exist in an application and any additional keystrokes should be consistent and compatible.
Some learners using a screen reader will navigate via links - make sure links are labelled logically and meaningfully.
Pages should be broken down into meaningful self-contained chunks, which do not overflow onto the next page; this will enable the learner to absorb the information contained in the chunk of learning, before progressing.
Units should be structured into sufficiently small elements so that learners can easily leave and return to the current point, using a bookmarking facility or a system of menus.
Buttons or keystrokes should be provided for ease of navigation to allow the learner to exit the current section, move upward within a hierarchy of menus and, from the top level, to exit the material. It should be difficult for the learner to close the application down accidentally (by exiting a current section) - there should be a logging off procedure.
The learner should have access via buttons or keystrokes to help and/or hints on the materials and technical issues.
The learner should be provided with the facility to play, pause, stop and restart any audio or video associated with the current screen, to ensure that they can control their own speed of progress through the material.
Progress indicators (breadcrumbs) should be located at the top of the screen. A progress bar shows the learner how far through the material he or she is. Learners should know where they are within the package at all times.
All buttons should be located in the same position on all screens for ease of navigation.
The Back button allows learners to review screens that have already been viewed by moving backwards through the material, screen by screen. It is also used to enable learners to have another attempt at questions or activities.
The Menu will take the learner directly from any tutorial screen to the menu screen. Where the material has more than one menu, this button will take the learner back to the previous menu in the hierarchy. Avoid rollovers for navigation - this may be impossible for those with motor difficulties or those using keystrokes.
Avoid colour-dependent navigation, with instructions such as 'Click on the Green button'
Where larger buttons are used, the amount of screen space available for the learning material is reduced. It is often a good idea to use different versions of buttons: 'available' (out), 'selected' (in), and 'unavailable' (greyed out).
Titles or headings ensure that learners always know where they are within the package.
Choose a suitable point size for headings - so as they are clear but not too imposing.
Do not crowd the screen with too many headings.
The learner should also be provided with an introduction to the learning material - possibly through the use of an introduction screen, to include at least the following:
It is important to remember that graphical images should be used for instructional, motivational, or attention-focusing effects, and not simply for the sake of including them on the screen. Every item on the screen should earn its place. Graphics should be crisp and clear.
When graphics are used there should be a text alternative to the image.
Sound and video should be used with caution and only when they aid understanding.
Video and audio tracks can be used, and multiple text tracks may be included within the clip. Multimedia materials can also be used to overcome problems of accessibility, particularly for use by learners with special educational needs.
Users without the capability of playing sound, as well as the deaf and hard of hearing can benefit from the use of captioned movie clips in learning materials. Users can view captioned clips and follow the soundtrack visually rather than aurally. For maximum accessibility transcripts should always be used in conjunction with audio-only clips.
People who have special needs, whose first language is not English or who have low literacy skills may have problems downloading, using or accessing plug-ins easily.
Where an applet is used to play a video clip, a text description should be provided.
Try to ensure that at the specified minimum bandwidth there is a delay of no more than ten seconds in the loading of an image or animation. Audio effects should be free from extraneous noise, such as unnecessary hiss and page turns etc. which can be distracting to some groups of learners.
Examples of accessible media rich materials can be found at - http://ncam.wgbh.org/richmedia/examples/index.php
This is an area where many learners are often excluded due to inappropriate design.
Drag and drop should be usable by mouse or keyboard.
Multiple-choice questions can be difficult for learners to engage with. Avoid too much scrolling and it may be appropriate to open a new Window for each question.
Ensure different sources of information are available separately.
Avoid information that is available only in graphic format e.g. a pie chart
Provide alternative activities, for example it would be inappropriate to ask a visually impaired person or someone with a motor disability to draw a diagram. However, remember that equivalent access (providing your resources in a range of formats) is preferable to alternative access.
Revised by Shirley Evans, Royal National College for the Blind, Hereford.
Ideally, a pilot or prototype should be produced - even in small projects. The prototype should be run on hardware with the exact target specification and should be produced early in the project. This will reveal any potential technical problems and 'look and feel' conflicts before they become serious, preventing costly changes later on.
The purpose of the functional prototype is to demonstrate how each element will function and test how users interact with the material. The prototype should also demonstrate the proposed interface, functionality and screen layout. The prototype should be tested with as many end-users as possible, and if appropriate, use their feedback to develop a further prototype.
What should be included in a functional prototype
The functional prototype is a fully working sample, and as such should contain an example of every element of functionality to be used in the material. A functional prototype typically comprises the following:
The functional prototype should be submitted to your 'client' who must check:
At the start of the project you should identify the quality expectations for the learning materials and at an early stage in the development the proposed design, in the form of the functional prototype, should be tested on a sample of users.
The purpose of the trial, is to ensure that the material will function correctly and is effective for the target users before the majority of the content has been incorporated.
Users, or, where applicable, subject specialists should be used for content testing. In the case of a consortia those involved in the trialling should be drawn from more than one group to avoid bias. This trialling team should be responsible for approving the content of the learning materials, beta testing and providing user evaluation of the materials. A checklist-based approach should be used to assess the learning materials against quality criteria. End user testing must be conducted at each stage.
You should record your observations on a Usability Trial checklist. Remember to attribute problems to the product rather than to the user. Record your observations and use prepared prompts on areas of particular interest, such as new types of functionality, or for example ask - 'Do you find the Help facility useful?' 'Are the question feedbacks helpful? etc.
Log the following information about users, e.g.:
Establish and record the motivation of users towards the product, and towards the use of a computer as the means of delivery.
To assess how easy the prototype is to use you will need to record the actions of users, noting:
To assess how easy the prototype is to understand record the actions of users, noting:
To assess the effectiveness of the delivery style record the actions of users, noting:
To assess how the delivery environment will affect the use of the materials you will need to record the actions of users, noting:
You will also need to compare and record any differences between the trial environment and the intended delivery environment.
This section will be used to provide notes on the section, including details of any changes.
This section is available at <http://www.ukoln.ac.uk/nof/support/gpg/DigitisationProcess>
Acknowledgements
Commissioned from HEDS by UKOLN on behalf of NOF in association with the People's Network
This section is based on the information paper which was provided for the NOF-digitise programme which provided advice and guidance to projects funded by the NOF-digitise programme on digitisation. However the advice provided in this section should still be appropriate for new projects.
This document looks at the essential issues of the digitisation process that should be addressed during the project planning stages and discusses techniques for creating digital files that will conform to the guidelines.
This document is intended to be used as a means of focusing attention upon the key issues associated with the digitisation process. The advice that it contains is intended as guidance rather than as the only solution to these issues. There may be valid institutional or curatorial reasons for following or discarding different aspects of this guidance, especially in relation to the handling of original materials that may make certain processes unsuitable for that class of material.
The fundamental issues associated with the digitisation process are as follows:
Having a good knowledge of the contents of the collections that are intended to be digitised will make it much easier to decide on processes and techniques for converting the originals to digital form.
The physical processes required to create a digitised version of an original item depend on many factors, including:
For paper and photographic originals, issues to consider include the following:
Photographic media (transparencies, prints, negatives)
What size are the originals, are they all the same size?
What proportion of the items have colour content? Is it important to capture the colour?
What condition are they in, for example, are they dirty from heavy use?
What format are they in?
Are the photographs flat or have they bowed?
What is the quality of the original?
Paper media
What size are the pages, are all items the same size?
What general condition is the material in?
Can books that are bound be stripped to loose pages for scanning?
Is there any artwork? Is it black and white or colour photographs or line art?
Is the text size particularly small or large?
Objects require a different approach. Artifacts, art works and sculptures cannot generally be successfully scanned using the techniques available for 'flat' media such as photographs. It will therefore be necessary to use photography, either traditional or digital, to get an image of the original.
Guidance on the relative cost of various procedures is available from HEDS [1] and [2]. There is also a detailed review in DigiNews [3] by Steven Puglia, of the National Archives and Records Administration.
Remember that real costs and prices are bound to vary from those given in any guidance documents and it is essential that such guidance is used purely as a starting point in accurate costing.
It is important that digital preservation issues be observed when producing digital content. A good baseline to creating a digital file that will be long-lasting would be Scan Once for All Purposes : this means that all the complex and expensive preparation work will only need to be done once.
The guidelines recommend that projects consider the value in creating a fully documented high-quality 'digital master' from which all other versions (e.g. compressed versions for accessing via the Web) can be derived. This 'digital master' file should be created at the highest suitable resolution and bit depth that is both affordable and practical. This master file then becomes the source for every other version of that item that the project will require, such as Web surrogates, versions for high quality printing and so on.
The 'digital master' file will become an archive version of the data : it remains as pure a representation of the original as possible. Ideally more than one copy should be stored on more than one media type and in more than one geographical location, thus providing a degree of protection against data corruption, media failure and physical damage to equipment.
'Surrogate' or 'access' versions of the digitised item can be created from the 'digital master' using image manipulation software such as Adobe Photoshop or Paintshop Pro.
The CEDARS project [4] gives in-depth information about digital preservation and links to further reading and the National Preservation Office have published Digital Culture: maximising the nation's investment [5], for which a synopsis and details of how to obtain a copy are available.
Resolution is usually expressed in dots per inch (DPI) and relates to the density of information that is captured by the scanning equipment. Broadly speaking, the higher the DPI the more detail is being captured. The amount of resolution required to get a useful image of an item is determined by the size of the original, the amount of detail in the original and the eventual use for the data. For example, a 35mm transparency will require a higher DPI than a 5x4 print because it is smaller and more detailed. An A4 sized modern printed document that is intended to be processed into a searchable text will need less resolution than a similar sized photographic original. There are also upward limits on resolution : file size is one (increasing resolution will increase the file size) and another is preventing the capture of extraneous information. For example, postcards are often printed on poor quality paper and if they are scanned at too high a resolution the texture of the paper will be captured and can obscure the content. There is also a point where putting more resolution into the capture process will no longer add value to the information content of the digital output.
Suitable resolutions for digital master files for various media types are discussed in the HEDS Matrix [2] and the JIDI Feasibility Study [6] contains a useful table of baseline standards of minimum values of resolutions according to original material type.
Bit-depth relates to the level of colour that will be captured. A 'bit' is the binary digit that represents the tonal value of the pixel. As an overview, a 1-bit image is black and white (the pixel has 1 bit and is therefore black or white with no shades in between), an 8-bit image has 256 shades of either grey or colour (28 = 256 shades), and a 24-bit image has millions of shades of colour (224 = 16,777,216 shades).
A detailed discussion of resolution, binary and bit depth can be found on TASI's Web pages [7] and a good basic guide to colour capture can also be found on the EPIcentre Web pages [8].
Digitisation equipment can be separated into 'contact' and 'no-contact'. 'Contact' equipment, i.e. flatbed scanners, requires that the original be flat against the scanbed to get a scanned image. This approach will only work if your original is flat or can be pressed flat without damage to it.
No-contact equipment includes overhead scanners or book scanners and digital cameras that are able to obtain a digital image with the bare minimum of contact with the original.
Choosing the equipment for scanning your originals will depend largely on the characteristics of the collection: in general terms, photographic materials are usually scanned on a flatbed or a transparency scanner while bound volumes and oversized flat materials such as maps and plans require a digital camera or an overhead scanner.
The Feasibility Study for the JIDI project [6] gives information about the type of equipment that is most suitable for broad groups of media types.
If you have a mixed media collection then it may not be possible to use one scanner for everything. A flatbed that is ideal for high speed, high volume paper scanning may not be capable of the resolution required for high quality scans of transparencies. A digital camera studio set-up will be overkill for loose leaf paper scanning and for most general photographic materials.
Generally, make sure that your requirements match the capability of the scanner(s) that you buy. Look carefully at the resolution that the scanner is capable of, the scanner will often be listed with a maximum optical resolution and an interpolated or software resolution. The optical resolution is the figure to look for : interpolated resolution uses software to 'guess' the values of pixels that are between those that the scanner can optically register. Interpolation should be avoided in an archive-quality scanning exercise. Where resolution is listed as, for example, 600x1200 DPI the maximum optical resolution will be 600.
The dynamic range of the scanner is important: it describes the tonal density of the information that the scanner will be able to capture and generally speaking the higher this is the better, particularly for dense originals such as photographic prints and transparencies.
A good flatbed scanner is often the keystone to a scanning unit. They range in price from tens to thousands of pounds : if this equipment is the key to the success of your project then investing in a good flatbed is essential.
Production-level flatbed scanners usually have either an A4 or an A3 sized scanning area. Larger ones are available but are specialist equipment and therefore rather expensive. In order to choose a flatbed you need to know what size your originals are, whether they are reflective (i.e. light is bounced off them to capture the image, as in photographic prints) or transmissive (light is passed through the original to capture the image, as in transparencies), the resolution and bit depth you will be capturing and the volume of the work.
The software that runs the scanner is also important. It should be straightforward to use and an ability to run batch scans will save time as the scan bed can be loaded with originals and more or less left to get on with it.
The Digital Eyes Web site [9] lists flatbeds by suitability and price.
Colour management software is essential to ensure that the digital representation is as accurate as possible. This can often be purchased with the scanner. RLG DigiNews December 1997 (Vol 3 number 3) has a technical review of colour management software [10] which is a good starting point.
Transparencies can be scanned on a flatbed if it is capable of sufficient resolution and has a transparency adapter fitted that will shine light through the transparency into the scanning head. However, faster and potentially better results will be gained from a dedicated transparency scanner. These scan strips or mounted 35mm negative or positive transparencies to high resolutions. Scanning un-mounted strips or single frame transparencies on a flatbed is difficult and time consuming because they have to be either placed in holders or taped to the scan bed to stop them moving in the heat of the light - using a transparency scanner can alleviate some of this effort and would be a good investment if 35mm is a considerable part of the collection.
Digital cameras. Digital cameras are developing for both the home and professional market and are priced from several hundred to thousands of pounds. 'Home use' cameras are aimed at non-professional users for taking general casual photography. Listings of home use cameras and their comparative features can be found on the Imaging Resource Web site [11].
There are two kinds of professional digital camera; the first has developed from medical and industrial uses and is a complete unit. The second is where the film from a traditional camera is replaced with computer sensors which transmit the image to a computer rather than to film; this is known as a digital scanning back. The first type has been around for longer and has been used in imaging projects for several years. Digital scanning backs are developing for professional photographers as a replacement for traditional film cameras, although they are also being used in project work. One of the advantages of the scanning backs is that they use the lenses and camera body of a traditional professional camera.
Professional digital camera set-ups will generally require the operator to understand the basics of photography and this is a cost that projects need to consider.
The EPIcentre Web site has reviews and feature comparisons of professional level digital cameras [12]. TASI also has a section on digital cameras [13].
The conversion of the materials can be done either in-house on specially purchased or existing equipment or sent to an external agency or commercial bureau.
Setting up a digitisation unit gives the institution the value of equipment and trained staff for future projects and the movement and treatment of the materials can be closely controlled. Using an external supplier to do the scanning means that the equipment and expertise of a third party can be exploited while the project team concentrates on their specialist area of the project. Using a bureau also means that the cost of buying and maintaining specialist and expensive equipment is not borne by the project.
Both approaches have their merits but there are certain situations where the choices are more clear cut.
Using a bureau: Major reasons for sending materials to a bureau for digitisation rather than attempting to scan them in-house include that the originals are not capable of being scanned successfully in-house (for example the equipment is excessively expensive) or that the intended product is beyond the experience and abilities of the project: for example requiring advanced colour management skills. As an example, the type of equipment used for the scanning of items such as bound books or microfilms tends to be so expensive that it may be difficult for a project to justify the expenditure on such equipment, particularly given the short life-span and high maintenance costs of scanning equipment.
Other reasons for outsourcing may include where there is a large volume of work to be done in a short period of time or where the project has space, infrastructure or staffing constraints which preclude the setting up of in-house facilities.
In-house unit: Alternatively, the project manager may decide to use in-house resources for several reasons including that:
It may also be that the project can call on existing staff knowledge and equipment which would mean the project could be done in-house with limited further capital expenditure.
There are some baseline infrastructure requirements for in-house digitisation:
This is assuming that the in-house operation wants to approach anywhere near the unit prices of production available from outside agencies.
A further reason why many projects are undertaken in-house is that the staff time, overheads and some consumables such as file storage can often be swallowed up by the institution and do not become apparent as a costed factor of the project, thus making this appear to be a cheaper option than out-outsourcing.
There is no easy answer to the question of whether to scan in-house or to outsource because it depends so closely on the project team, the institution and the materials.
Choosing a scanning bureau
If the project decides to use an external body to digitise the materials then it is important to carefully look at the available service providers. A good place to find scanning bureaux is in the Cimtech Electronic Document, Records and Content Management Guide and Directory [14] which has up-to-date listings for UK suppliers of digitisation bureau services.
Among the most important things that you should ask potential suppliers are:
Can they conform to all relevant specified technical standards and guidelines?
Do they have safe storage facilities for the originals away from the production area?
Will your originals be worked on by them or do they intend to contract to another supplier?
Develop a tight specification of requirements and a contract that sets out what you expect from the vendor, including technical procedures, output formats, handling requirements and timescales. Insist that they will rework any data that fails your quality assurance procedures (i.e. that falls outside the requirements of the contract) without further cost.
Some suppliers will claim to be able to do any type of media that you ask them to tackle but HEDS' experience is that bureau tend to specialise in certain types of conversion, for example high volume paper materials or high end colour image based work. Where this is the case they may not be as good at some media or they may outsource those media to a partner bureau. Insist on samples, undertake a vendor assessment or seek third party advice before contracting.
If the work is of such a volume that the job has to go out to tender, bear in mind that the cheapest quote may not be from the best bureau for the job. Ask each of the short-listed bureaux to undertake samples to your required specification and ask them to provide a detailed description of the processes used to achieve the output along with a price. You should then choose the supplier that provides the best value for money in terms of quality, price and the suitability of the conversion procedures.
A digitisation project can cover a wide range of complex activities and it is often easy to lose track of the underlying project aims and objectives. Digitisation is a tool and not a purpose and should always be used to facilitate the end result of the project rather than becoming the sole focus of it. It is hoped that this document will help to make the process of digitisation less fearsome and more tangible and therefore something to be harnessed to help to create useful and exciting digitisation projects.
This section will be used to provide notes on the section, including details of any changes.
This section is available at <http://www.ukoln.ac.uk/nof/support/gpg/WebsiteSetupGuidelines/>
Acknowledgements
Author: Brian Kelly, UK Web Focus, UKOLN
Originally commissioned as part of the Information Paper series from the NOF-digi Technical Advisory
Service.
This section is based on the information paper which was provided for the NOF-digitise programme which provided advice and guidance to projects funded by the NOF-digitise programme on setting up project Web sites. This section has been updated to ensure that the advice given is appropriate for general Web site development work.
This section provides advice and guidance on best practices for setting up Web sites. The information provided in this section is intended to be used during the planning stages for a Web site.
Before setting up your Web site it is important to identify its purpose(s). The primary purpose of many cultural heritage Web sites will be delivering cultural heritage and learning materials to end-users. However organisations may also choose to make available information about development activities, its development, remit, etc. to partners, funders and other interested parties. The site could be structured in such a way that different audiences are targeted for specific sections of the site, whilst ensuring that all the materials digitised are freely accessible to the public.
It is necessary to have a clear idea of the purpose of the Web site at the planning stage in order to help with the planning of the structure of the Web site, identify the potential costs, management support, technical resources required and staffing numbers and skill levels, etc.
Users often find it easier to remember a short project- or organisation-specific URL, rather than a long and non-intuitive one. Organisations might wish to consider registering their own domain name (<www.my-project.org.uk>, say) rather than requiring users to remember a less friendly URL (such as <www.my-organisation.gov.uk/projects/nof/my-project/>).
If your Web site is hosted on an organisational server there are several options available. Web sites are often set up within a deep hierarchical structure (e.g. <www.my-organisation.gov.uk/depts/library/projects/NOF-digitise/bar/>). Such URLs can be difficult to remember and are prone to errors when typing. In addition many search engines are believed not to index deeply within a Web site.
Another alternative is to make use of the ~ (tilde) convention (e.g. www.my-organisation.gov.uk/~bar/). Although this approach can provide a short URL novice users may find the ~ key difficult to find. Also users may regard content on Web sites which contain ~ to be personal home pages rather than quality services.
If you change the domain name for your Web site you should ensure that you inform relevant parties, such as the funders of the Web site.
What is the expected life time of the Web site? The information contained on a Web site is likely to be valuable even after the project has finished. You should try to ensure that the Web site will continue to exist after the funding has finished and that bookmarks and published URLs will continue to function.
Resources on your Web site should be located within its directory (e.g. if the directory is <www.my-project.gov.uk/about/> this should be the project entry point and not <www.my-project.gov.uk/about.html>). This allows the Web site to be treated as a unified collection - e.g. to allow the Web site to be downloaded onto a PDA or by an offline browser, without having to download the entire organisation Web site.
A preliminary site may be up and running before the development work is complete and the full version of the Web site launched. You should note that once a Web site has been set up it may be indexed by search engines or linked to from other Web sites. Since the index and links may persist after the official project Web site has been launched it may be desirable to manage the dissemination of the pre-release Web site. For example, you may wish to provide text on the Web site informing users of its status. You should also consider use of the robots.txt file or equivalent <meta> tags in HTML pages to prevent robots from indexing the site until it is officially launched [1].
Once your Web site has been developed and checked for compliance with appropriate standards and best practices is ready it should be promoted in order to ensure that end users know about the service.
You should make use of a robots.txt file to ensure that quality areas of your Web site are indexed: for example, you may wish to exclude draft documents or personal pages from being indexed by search engines such as Google.
You are advised to be pro-active in submitting your Web site to key search engines (e.g. Google) and directory services (e.g. Yahoo). You should consider use of submission software and services [2].
You should be aware of the difficulties which search engine software can have in indexing your Web site if you provide frames-interfaces (especially if you do not provide a no-frames alternative for accessing the full content of your Web site), if you use 'splash screens' or if you use proprietary file formats, such as Flash.
The use of metadata on key areas of your Web site may be a requirement of the funding body. Metadata (information about a Web resource, such as the author, keywords, brief description, etc.) may be used by search engines such as Google and also by local search engines.
During the lifetime of the Web site there are likely to be several deliverables and items of news which you would like your users to be aware of. You should consider providing a news area on your Web site. You may wish to use an automated notification service such as Trackengine [3] so that users will receive an automated message when the news page is updated. You should also consider use of RSS [4] to allow your news items to be automatically syndicated to remote Web sites.
For further information on Web site promotion see [5].
The content that your Web site will provide will influence the design of the site, particularly the navigational elements on the Web site. In addition the nature of the content will help in structuring the content and defining the underlying directory structure.
It may be useful to produce a diagram showing the key areas of content which defines how the content will be grouped: try to think about how the Web site will be structured in a couple of year's time. The Web site should be designed to ensure that it will not have to be re-organised as the site grows as this can be very time-consuming and can lead to many broken links.
Cultural heritage Web site should make use of open standard file formats wherever possible in order to maximise access to resources. Open standards (such as HTML and XML) are developed by consortia (such as W3C) and are designed to be platform and application independent. There will often be freely available tools to create and view formats based on open standards.
However, in some cases there may be no relevant open standards or the relevant standards may be sufficiently new that conformant tools are not widely available. In some cases therefore, the use of proprietary standards may be acceptable. Ideally you will document the reasons for selection of the proprietary formats and have outlined a migration strategy to use of open solutions if they become available. Proprietary formats (such as Macromedia Flash and Adobe PDF) are owned by commercial companies and may only work on limited platforms. Use of proprietary formats may require licensed products, and even when their use is free, there can be no guarantee that this will continue.
You may be required to follow the technical standards which may be mandated by a funding body. For example, projects funded by the NOF-digitise programme were required to follow the NOF-digitise Technical Standards and Guidelines [6] which described the recommended file formats for creation and storage of digital resources.
HTML will be used extensively on your Web site. In order to maximise the range of browsers which can access your Web site you are advised to ensure that your Web site conforms to HTML standards (currently HTML 4.0 or XHTML 1.0 [7] standard) and that you avoid use of proprietary extensions.
HTML or XHTML should be used to describe the main structural elements on your Web site. Cascading Style Sheets (CSS) [8] s hould be used to define the appearance of the elements on a browser. Separation of the structure of resources on the Web site from its appearance will enable the appearance to be more easily changed and will ensure that resources can be accessed by a variety of devices (digital TV, PDAs, etc.)
Although HTML/XHTML and CSS are the recommended formats for Web sites, unfortunately many older browsers fail to support CSS adequately. Until standards-compliant browsers are widely deployed you may wish to consider use of 'safe' CSS features which can be used with all browsers and which degrade gracefully (see [9]).
Validation of HTML/XHTML and CSS resources will help to detect errors. Your Web pages may not be displayed correctly or function correctly in all browsers if they contain errors. You should ensure that you systematically check Web pages using validation tools, which may be built into the authoring tool, may be independent applications or may be provided on the Web, such as W3C's validation services [10] and [11].
Your Web site may contain a variety of images, such as navigational icons, photographs, flow-charts and organisational diagrams, etc., and may also contain sound and video resources. The following requirements may apply to the delivery of resources funded by public sector funding bodies.
Browser plugin technologies allow a range of other file formats to be provided on the Web such as Macromedia Flash and Adobe PDF. It should be noted that such formats are proprietary and there is no guarantee that plugins will continue to be free. There may also be accessibility considerations for plugin technologies: the content may not be accessible to speaking browsers, digital TVs, etc. For these reasons plugins should be avoided if possible. However in certain circumstances their use may be permitted, e.g. in the design of games, etc. and a case can be made in your project's business plan for their use, provided this case does not contradict any of the 'must' requirements of any technical guidelines document provided by your funder.
A number of approaches to creating HTML documents can be taken. Experienced HTML authors may make use of text editors to create HTML markup manually. However this approach can be time-consuming and is prone to errors. Many HTML authors prefer to make use of dedicated HTML authoring tools such as FrontPage or Dreamweaver.
If you have large numbers of documents in proprietary formats, such as a word processing format, you may wish to make use of a conversion tool. Some dedicated HTML authoring tools allow formats such as MS Word to be imported and converted, although the quality of the conversion may be poor. Dedicated conversion tools may do a better job, or enable large numbers of documents to be converted in bulk.
Another way of providing access to documents which use a proprietary file format is to use 'on-the-fly' conversion software on the server (i.e. files are dynamically converted by software typically running on the Web server).
Another alternative is to make use of a content management system. A content management system may be regarded as a database which provides management functionality for a Web site. Content management systems normally provide facilities such as reuse of resources, automated removal of expired resources, personalised interfaces, etc. Content management systems may provide a dedicated data entry system in which knowledge of HTML is not required. Content management systems should also provide support for new file formats which may supersede or extend HTML (e.g. provide support for WML to provide access to users of mobile phones). Further information on contentmanagement systems is given elsewhere in the document [13].
As the underlying Web technologies and file formats are constantly being developed it is important to keep up-to-date with developments in order to be in a position to exploit new developments in a timely manner. Important developments to be aware of include XML, XHTML and XSLT.
XML, the Extensible Markup Language, will act as the basis for new file formats [14]. It enables richly structured resources to be described in an open and extensible format. XML is already widely used in many large-scale commercial Web sites and will grow in importance as new browsers become available which will provide native support for XML. In addition to XML itself, there are many related developments which will enhance the functionality of services based on XML.
XHTML [15] is an XML version of HTML. It is designed to provide the benefits of XML (i.e. structured, reusable documents) while allowing resources to be accessed by existing browsers.
XSLT [16] is a transformation language which allows XML resources (such as XHTML pages) to be transformed into other formats such as WML pages for use by mobile phones).
A well-designed Web site will be quick and easy to use and will reflect positively on the organisation. A poorly designed Web site is likely to be difficult to use and will give a poor impression of the organisation. When designing your Web site think about the following issues:
Who designs? Who will be responsible for designing the Web site? Will it be done inhouse, or by an external designer? What skills do they have? Are the design skills relevant to a Web site?
The design brief. It is important to produce a thorough design brief and methodology for approving the proposed designs.
Technologies. What technologies will be used to implement the design? Will the use of technologies such as Shockwave or Flash be acceptable? Are the technologies backwards compatible?
Accessibility. Is the design accessible to people with disabilities or users of older browsers or specialist devices?
The navigational aids on a Web site should be part of the overall site design. It is desirable that consistent navigational aids are widely available throughout the Web site. It should enable users to quickly access the key areas of the Web site such as the 'home page', a search facility or site map and help information or frequently asked questions.
A search facility is essential for most Web sites. A wide range of search engines are available, many free-of-charge. If you cannot install a search facility for your project Web site (for example if the institution hosting your Web site does not provide searching across specified areas) you can make use of an externally-hosted search engine. For further information see [17].
Your Web site's 404 error page (the message which is displayed when a user selects a Web page which does not exist) can play an important role in helping users navigate. A well-designed 404 page will provide access to a search facility or a site map. For further information see [18].
In order for a Web site to continue to provide a quality service after it has been launched it will be necessary to maintain the service.
The content on the Web site will need maintaining to ensure that it remains up-to-date and relevant. The maintenance process can by assisted by the inclusion of contact details or clearly defining the person or group with responsibility for the information content. User feedback mechanisms, such as email links or Web forms can help to encourage users to report on inaccuracies. The inclusion of a user form on your Web site may be a requirement of your funding body in order to enable users to provide feedback on the quality of your service.
Broken links on a Web site are always irritating. You should ensure that you provide systematic link checking. This should cover both internal links to resources within your Web site and links to external resources.
Although there are many link checking tools available you should bear in mind that broken links can be caused not only by use of the <a> and <img> elements to link to resources and images, but also by technologies, such as style sheets, forms, etc. You can check for other broken links by analysing your Web server's log file. The error log file (which may be a separate file) will give more complete information on errors.
You should ensure that you have procedures for monitoring the availability of your Web service. If you do not have procedures available locally you may wish to make use of remote services such as WatchMyServer [19] and InternetSeer [20].
You may be expected to provide performance indicators for your Web site to your funders. You may wish to record performance indicators for your own use and to give information to your management group, to help with future planning for growth of the service.
Web statistics can provide a useful performance indicator, although they should be treated with caution. For example a substantial growth in the number of hits on our Web site may simply indicate a redesign of your Web site with greater numbers of images or that your Web site is being accessed regularly by robot software rather than users. Information on the number of page impressions or user sessions is probably better than number of hits, but again this can be misleading. For example growth in the number of page impressions and user sessions may be the result of large numbers of users finding your Web site using a search engine and leaving the Web site after reading one page and deciding it is not relevant.
Despite these reservations, Web usage statistics should be collected and summaries produced. There are parallels with the published statistics on TV viewing. Audience viewing figures for TV programmes are also difficult to define rigorously: for example the TV may be on but either nobody is watching or many are; the figures may be skewed by videoing programmes for later viewing, etc. Despite these reservations TV viewing statistics are collected and published and for the basis for decision making.
The important point to be made is that any figures must be regarded with some scepticism and care must be taken before using usage figures for making any decisions or comparisons with other services. It will also be important to ensure that a consistent approach is taken towards the collection of the data and any data processing. For example, you should seek to ensure that you collect and process the data in a consistent fashion during the lifetime of your project Web site. For example, should you record only accesses from outside the organisation; should you remove access data from robots; etc.? As well as ensuring that you process the data in a consistent fashion within your organisation, it is also desirable that similar approaches are taken by your peers, such as project work funded by the same funding body.
You must also ensure that care is taken if you aggregate summaries of the usage statistics. For example, if monthly Web log analysis reports shown that you get 1,000 unique visitors per month, you cannot say that over a year you have received 12,000 unique visitors. You may, in fact, have received only 1,000 unique visitors over the year. On the other hand, you may indeed have received 12,000 unique visitors (although this is unlikely).
Other performance indicators are available, such as the number of links to your Web site, the coverage of your Web site by search engines, Web server uptime, user feedback, etc. For further information see [21].
You may find it useful to carry out periodic auditing of your Web site. This can help in spotting errors, evaluating the accessibility of the Web site, evaluating the success of your dissemination, etc. For further information on approaches to monitoring and auditing Web sites see the survey of eLib project Web sites [22].
You may also find the Advice to Content Providers document useful (note it is in PDF format).
This section will be used to provide notes on the section, including details of any changes.
This section is available at <http://www.ukoln.ac.uk/nof/support/gpg/ContentManagementSystems/>
Acknowledgements
Originally commissioned from Alice Grant, Consultant, in October 2000 for
inclusion in the NOF-digitise programme manual
With thanks to Fiona Marshall, Content Manager, British Museum COMPASS Project.
This section is based on the information paper which was provided for the NOF-digitise programme which provided advice and guidance on use of content management systems. However the advice provided in this section should still be appropriate for new projects.
This information paper explains what a content management system is (and is not!), and why your NOF Project needs one. It also explains how to set about finding the best one for your project, including some tips on questions to ask potential suppliers. Finally, there are two case studies, demonstrating approaches which might be taken by smaller and larger projects respectively.
A content management system (CMS) is a database which organises and provides access to all types of digital content - files containing images, graphics, animation, sound, video or text. It contains information about these files (known as 'digital assets'), and may also contain links to the files themselves in order to allow them to be located or accessed individually. A content management system is usually used to manage digital assets during the development of a digital resource, such as a Web site or multimedia production. It might be used by staff digitising images, authors and editors, or those responsible for the management of the content development process (content managers). Content management systems range from very basic databases, to sophisticated tailor-made applications. These more complex systems can be integrated with the eventual digital resource in order to enable access to digital assets and to allow regular updating.
This type of product is relatively new and there are very few content management systems available as off-the-shelf packages, although an increasing number of companies have ready-made applications which can be quickly adapted for different projects. Content management systems can be used to carry out a wide range of tasks, including those described below.
A content management system is not any of the following:
Content management systems do not contain information about the presentation of the digital content (e.g. end-user interface, navigation, design or layout). Content management systems are not aimed at ordinary users; they require training and may have different interfaces depending on the type of user (e.g. editor, system manager, image manager etc.).
Content management systems are essential for large or even small-scale projects which involve the capture or creation of digital assets. They also are increasingly necessary for the creation of any but the most basic Web sites.
Managing the capture or creation of digital images requires metadata to be recorded which documents the capture, ownership, location and licensing conditions relating to each image. Even for a few dozen images, this may add up to hundreds of different pieces of information, the management of which would not be possible without some automated assistance. For a learning resource containing hundreds or even thousands of images, the job is larger still.
Similarly, managing a Web site with even a few pages is a time-consuming task when updates are required, perhaps when a page is added which requires the navigation menu to be updated on other pages, or when a logo changes which then needs to be reflected on all pages. For this reason, the use of templates which draw on content held in a database, is a vital management tool. Without this type of application, the Web site would either fall out of date very quickly, or would require ever greater staff resources to retain its currency.
Content management systems hold information describing digital assets. This information is known as 'metadata' (information about other information). The metadata held in a content management system can be used to manage and provide access to, digital resources. Metadata held in a content management system might include:
Examples of metadata used to manage digital assets can be seen at the University of Berkeley's contribution to the Making of America project, at http://sunsite.berkeley.edu/xdlib/servlet/archobj?DOCCHOICE=moa2ucb/48.xml
Metadata held should support local management processes and should also allow access and resource location functions, by complying with the Dublin Core. Metadata should also comply with domain-specific standards as required, including AACR2 and MARC (for libraries), SPECTRUM (for museums) and ISAD (for archives).
Content management systems may store narrative text for publication on the web. Text can be recorded together with author, version and currency information, which enables the publication of information online to be managed more effectively. Systems may also provide direct links to digital assets, enabling users to browse through images, sound or video clips as part of the authoring process.
The system should enable content managers and editors to keep a close eye on the digitisation process, including monitoring the capture of images, or tracking the authoring and editing of narrative text. This can be done using simple checkboxes or by completing data fields which document progress. Some systems allow the pre-publication process to be tracked more visually, using workflow management tools which represent the progress of a piece of text through the authoring process - for example, using coloured 'traffic lights' to indicate when a piece is ready to be published online, or alternatively by displaying a 'route-map' with milestones indicating how far an article has progressed down the editorial route.
Any content management system should have a mechanism allowing it to make this content available to a Web site. Depending on the complexity of the system, this might be done in different ways.
At a basic level, the system might export the content in a pre-defined format, to a separate database used to run a Web site. This would require regular exports to be made as content was updated, and is an effective, if labour-intensive means of enabling the online publishing of digital content.
An alternative would be to use a content management system able to be integrated with a Web site. In this type of arrangement, a web manager would create templates for different types of web page. Layouts for different types of page could be set up, pre-defining the type of content which would be displayed in each template. For example, an organisation's logo might always be displayed, as well as a navigation bar, and a special template might be designed to hold information about an items held in a collection.
This template might then be selected to create a page containing, for instance, an image of an illuminated manuscript, together with a caption and a transcription. This could be done by hand - for instance an image or text could be copied from the content management system and inserted into the correct place in the template. However this would mean that whenever the text was updated, the web page would need to be recreated by hand. For this reason, it is better to create a web page by linking the database directly to a template.
This could be done by selecting the template to be used for a specific page, then instead of adding in the image or text by hand, inserting a database query for each component of the page which includes a digital asset to be drawn from the database. Immediately before the web page is 'published' (i.e. copied to the live Web site), a programme is run which ensures that the web pages are updated by running their database queries on the content management system. The image of the manuscript, the transcription and the caption are retrieved directly from the database, copied to the web page and displayed whenever the page is called up. When content is changed (for example, the caption might be updated, or a better quality image created), the Web page is re-published using a single command - i.e. one or more database queries are re-run - and updated images or text are automatically uploaded, replacing the previous versions. In this type of system, the database is held within the organisation's security firewall and the newly-published web pages are mounted externally.
More sophisticated content management systems can deliver digital content direct to web pages which are constructed 'on-the-fly' as users browse through a Web site. For example, a user might wish to select items from a collection by searching on a keyword. The relevant items would be retrieved directly from the content management system, based on the metadata describing the subject of each digital record. A web page is then created to display details of each item online, using a template designed for that specific purpose. As before, the template places the relevant content for each item within a pre-defined layout as it is displayed on the screen. The web 'page' however, only exists at the time of display, and is effectively a temporary composite of design, layout, text and images. The benefit of this type of system is that it allows updated content to be constantly updated, rather than published in batches which may take time to upload. It also makes the management of the Web site much easier.
Clearly security and access for this type of system need to be more sophisticated. In some applications a 'source' database is held within the organisation's firewall and extracts automatically copied to the external version whenever content is updated. Alternatively, additional security measures may be built into the content management system to prevent unauthorised access.
Although the market for this type of system is by no means mature, in all but the smallest and simplest projects it would not be advisable for an organisation to attempt to develop one in-house. The process of selecting a content management system is the same as for any other computer system. It may be governed by local rules, prescribed by European law, government or local authorities for example. The process of procurement will normally include the steps described below, although depending on the size of your project, you may wish to simplify the process, or you may be required to include certain formal stages. If in doubt as to the process you should follow, contact your organisation's Finance officer. The steps to procurement include the following:
Based on the size and complexity of the planned project, decide from the outset the scale and scope of the system which is required to support the development and delivery of the project. Take into account existing systems and skills. One issue for many museums, archives and libraries will be that they already have integrated collections management systems which enable the recording of metadata relating to digital assets. They may be able to extend the use of existing systems to encompass some additional functions, in which case their requirement for a content management system is restricted to a database to run the Web site which will allow content to be drawn from the existing collections management system. (see Case studies below) Once it has been decided to proceed, it may be useful to set up a Project Committee (if one does not exist already) to act as a decision-making body throughout the procurement process.
Based on the business case, draw up a list of the functions and the recording capabilities which the system will require. If the business case and your knowledge of the market suggest that a simple, off-the-shelf package is required which will not cost a large amount, then it may simply be necessary to follow your organisation's internal rules for purchasing software and demonstrating value for money. However larger projects will almost certainly require more complex systems which require the project to go out to tender, using an Operational Requirement to invite responses from vendors and developers. If this is the case, the Operational Requirement should include the following components:
The functional and technical sections will contain some requirements which are 'mandatory' (i.e. any system must deliver these in order to be considered). Other requirements may be assigned different levels of importance. Try and restrict the mandatory requirements to those areas which you really could not do without - otherwise you may find yourself without a system - or with one which is beyond your budget.
The draft Operational Requirement alongside demonstrations and initial discussions with suppliers, may be used as a basis for establishing the likely cost of the content management system. Approval to proceed will normally be required from the Project Committee, who may suggest that the Operational Requirement is refined to the point where it can reasonably be expected that the eventual system will fall within budget.
A minimum of 28 days is normally required by suppliers to respond to the Operational Requirement. Try and be as helpful as possible - bear in mind that responding to requirements is an expensive and time-consuming process. Invite suppliers to ask questions during the response period - but ensure that any responses are copied to all those submitting tenders. Provide a template for responses - preferably in the form of a spreadsheet.
Make sure that you have decided on your evaluation model before opening tenders from suppliers. For larger projects, or those involving consortia, you may wish to set up two evaluating teams in parallel - remember that involvement in the evaluation will help ensure ownership of the selected system across your organisation(s). Assign a ranking of importance for each question (e.g. 3 for important or mandatory requirements; 2 or 1 for less important areas). You might also assign an overall rating to the different sections of the requirement which are being evaluated. For example there may be many more functional than technical requirements, but you may decide that each section is worth 40% of the overall score, with the remaining 20% based on your evaluation of a vendor's ability to deliver and track record. Once this evaluation model is agreed, then you can open the tenders and score the responses to each question, using the spreadsheet.
Finally - remember that the cost of a system is not what matters, so much as the value for money which it represents, and the cost of ownership over its lifetime - including the equipment and people needed to run it. If the ideal system is out of your budget, it might be an indicator that you have asked for too many mandatory requirements - or equally, that your organisation had not recognised the importance of the system to your planned operations. In either case, your Project Board may need to be consulted.
Once the system has been selected you will need to notify the vendor and agree terms of delivery. For larger, more complex systems, you may need to keep a vendor in reserve in case the contractual process breaks down with the initial supplier. You should not begin the implementation process until the contract has been signed. It is sometimes possible to exchange formal letters of agreement as a temporary measure to allow initial stages of work to proceed, but in such circumstances approval should be obtained from the Project Committee and other formal sources as required by your organisation. Any work carried out in this way should be extremely closely defined and managed. It is normal to retain a proportion of the cost (5%-10%) until formal tests have been carried out on the system and the implementation has been carried out successfully. This is known as the acceptance process.
The content management system you select will need to assist you in the management and/or delivery of digital resources, depending on the scale of your project and existing systems in place. Your business case will help you decide the scope of the system you need and the functions you require. You may need to consider the following areas when deciding on what your content management system should do:
Unless specific terms are agreed, the IPR in any application developed specifically for your organisation, should normally be retained by your organisation, excluding the rights in any underlying or third-party software which will be owned by the developer or third party supplier respectively.
If you are a museum, library or archive with an existing collections management system, find out what content management functions can be undertaken by that system. Similarly, if you are a member of a consortium, find out who has existing systems within your group. Even if you don't use an existing one, you're going to have to ensure that everyone can either contribute content in a standard form, or share a common system at some level.
Fora for asking questions about content management systems can include:
In order to decide whether a system is worth considering, try asking the following questions of yourself and of potential suppliers - but bear in mind that no supplier is likely to respond directly when asked 'how much does it cost' on a trade stand or on the phone - you may need to be a bit more subtle!
| Ask yourself... | Find out... |
|---|---|
| What's the budget? | How much does it cost over its lifetime? |
| What skills do we have in-house or in our consortium? | What skills does it require to run it? |
| What hardware and network will be needed to run it? | |
| How IT-literate are the staff who will be using it? | How complicated is it to use? |
| How many people & how much content do we have? | How many users can it support - and how much content - while maintaining good performance? |
| How tight is our timetable? | How many people in the company - and how many other projects on the go? |
| What other systems will it need to work with? | Can it interoperate with our existing systems? |
| What kinds of data will we want to record and access? | Can it handle data in a wide range of standard formats? |
| Do we have any special, or difficult problems and what do other organisations like us use? | Have the suppliers dealt with your type or organisation/requirements before and can they provide reference sites for you to visit? |
| What if the system goes wrong? | What support and maintenance services are available? |
To ensure that your content management system will be useful in three or five years time, and that your content will be secure and accessible in perpetuity, there are a number of issues which you will need to consider including the following:
Lastly - but MOST important - how will your new system be maintained and supported? Do you have the necessary internal skills to run the system, and is your chosen supplier able to provide you with effective support? To ensure this, you should consider taking out a separate support services contract, particularly for larger, more complex systems
Five organisations who are in a consortium review their existing systems and find that one organisation, a museum, has a Web site and underlying database which could be extended to provide the proposed NOF-funded service. They review their metadata and publishing requirements however, and find that although the existing database is able to publish pages on-the-fly, it isn't able to provide them with the digital asset management and process management functions they require. Together, the partners draw up a requirement for these functions, stipulating that the system should be able to export content to the Web site system, and should be licensed to each of the partners individually, but at a reduced rate, with shared support services. The system is procured jointly by the partners, under the oversight of a project committee comprising a senior staff member from each partner, and a seconded project manager from the largest partner, funded by NOF.
An individual from each partner organisation is designated the project leader within that organisation, responsible for ensuring that local metadata and functional requirements are met, and for planning the local implementation.
At the end of the project they have not only saved on the cost of project management for the procurement, but also on the cost of the system since they were able to negotiate a favourable rate. They are able to share skills and knowledge by using the same system, and the export process which is used whenever the central Web site is updated, only has to be worked out once, after which it can be run as often as necessary. They also share the cost of developing additional templates for NOF content, using the existing Web site, thereby saving on procurement and development costs, even though the templates reflect each of their identities, while providing the public with a single point of access.
A small archive comprising various printed and manuscript documents and some physical artefacts, is covering a subject area not addressed by any other NOF applicant, and therefore decides to 'go it alone' with the digitisation of 500 key items in their collection, as part of a local community project. They contact another organisation of a similar size and with comparable collections to find out what was used for their recent HLF project, as well as ringing round various other archives and posting a query on the NOF-digi email list. As a result, they establish that many of the available solutions are too complex for their needs, and also require skills not available to them. However the first place they contacted has an Access database which was developed by a local company to meet the requirements of Dublin Core metadata, as well as to help with the management of a CD-ROM which they produced. They contact the company who agrees to let them use the database for a small fee, and to support it for the duration of the project. Meanwhile following their query on the NOF-digi email list, a local library involved in another NOF bid offers to host their service within the local authority's Web site, provided the archive is able to pay for the development of new templates for its content, and for support services. The archive duly specifies its requirements, ensuring that the library's Web site can import content from their planned Access database. They also ensure that the database developer is able to provide an export routine which enables them to publish their data to the library's Web site without requiring specialist skills to do so. With approval from senior staff, and with formal agreements in place with the developer and with the library, the archive is able to proceed with the digitisation of its resources without undertaking development or procurement work beyond its capabilities, thereby saving time and money, and ensuring the long-term success and sustainability of its project.
This section will be used to provide notes on the section, including details of any changes.
This section is available at <http://www.ukoln.ac.uk/nof/support/gpg/Metadata/>
This section is based on the information paper which was provided for the NOF-digitise programme which provided advice and guidance to projects funded by the NOF-digitise programme on use of metadata. However the advice provided in this section should still be appropriate for new projects.
This paper explains how the use of XML might contribute to your ability to share information about the valuable resources that your project is developing. Although its coverage is of necessity general, it may help you to evaluate some of the comments made by vendors and developers in this area.
The first part of the paper contains a very brief overview of the subject of metadata, with particular emphasis on metadata for resource discovery. The purpose of this section is not to make detailed recommendations about what metadata you may require to describe your resources, but rather to try to highlight some of the ways metadata is used, and how those uses create particular requirements for its exchange.
The main part of the paper explains what XML is. It provides some background to the development of the XML specification, a brief overview of some features of XML, and some examples of how XML is used. It includes a simplified summary of XML syntax, but does not provide a detailed treatment of this area, as such information is widely available elsewhere. The main aim is to highlight exactly how XML supports the effective sharing of information in different contexts.
Finally, we examine how well XML meets the requirements for the exchange of metadata. This part of the paper seeks to draw out some of the limitations of XML and to explain some related specifications and technologies that seek to address those limitations.
By way of conclusion, the paper offers a short set of questions that your project may wish to consider. These questions represent an attempt to move the discussion from the general issues covered in the body of the paper to their relevance in the particular context of NOF-digitise projects, though the breadth of the subject area means that they remain fairly general.
This paper does not make specific recommendations for the use of particular XML-based markup languages or metadata schemas within NOF-digitise projects: the potential range of uses are simply too wide to address in a general paper. The paper concentrates on the structural and syntactic aspects of sharing metadata, rather than the specific semantics of that metadata.
Note: In the context of this paper the expression "metadata sharing" that is used in the title is employed in a general sense to refer to the "disclosure" or "publishing" of resource descriptions. It is not intended to carry the more specific sense of the re-use of existing metadata records under some form of "collaborative cataloguing" model.
Metadata is structured information about resources (including both digital and non-digital resources) that can be used to help support a wide range of operations. The activity most often considered in discussions of metadata is that of resource discovery - locating resources of interest by using the descriptions of resources which have been disclosed (published) by their creators, distributors or custodians (or indeed by third parties). The content of resource discovery metadata should allow a user to evaluate the relevance of a resource, and metadata may also provide information on the mechanisms required to access resources once they have been selected and located. Metadata may also help a user interpret the content of a resource.
However, metadata may also support many other activities related to the management of resources by their custodians, including the administration of rights associated with the resource and issues related to its preservation [l]. Metadata is created within a specific context and for specific purposes. It is hardly surprising, then, that different purposes and different contexts have different metadata requirements.
The following definitions of metadata highlight a number of issues:
Metadata is machine understandable information about web resources or other things [2]. Metadata is data associated with objects which relieves their potential users of having to have full advance knowledge of their existence or characteristics. A user might be a program or a person [3].Both these definitions emphasise that metadata is to be used by programs as well as by human readers. Berners-Lee takes a broad view of the range of "resources" that metadata might describe. He envisages metadata used to describe not only the objects we might think of as "Web resources" (HTML pages, images, databases etc) and physical resources (books, manuscripts, artefacts), but also people and places and even "abstract" resources like concepts and events.
Dempsey and Heery's definition suggests that a metadata record is a surrogate for - "stands in" for - the resource itself, albeit in some specific, limited ways. A user can access metadata about a resource quite separately from the resource itself, and some user requirements may be met through reference to the metadata alone with no need to access the resource it describes.
It proves almost impossible to sustain a clear distinction between "data" and "metadata". A pragmatic approach suggests that information is metadata when it is used as metadata! However, by examining some of the functions that metadata is created to support, it is possible to suggest some features of metadata use that condition its content and the form in which it is made available.
For example, taking the case of resource disclosure and discovery, we can suggest some actions that various agents may wish to perform. This list is not intended to be exhaustive.
Typically the users (or potential users) of resources wish:
Resource providers wish:
In addition, third parties may wish
To support these functions, the (possibly diverse and distributed) descriptions of individual resources (or at least some data extracted from those descriptions) must be brought together - aggregated - with metadata about other resources by a service which then makes that aggregated data accessible to users through some form of search interface.
The scope of such a service may vary: it may be within a single project, across a cluster of projects, across the whole of a funding initiative like the NOF-digitise programme, or within the scope of a subject area or a geographical domain. Indeed a resource provider may make metadata available on the basis that it can be used by any service which locates it. This is typically the approach underlying the creation of simple metadata embedded in the headers of HTML documents on the Web: the resource provider expects that it will be indexed by the "spiders" of search engine services but does not make specific agreements with those services. Of course, those different services process such metadata in different ways and it is sometimes difficult to predict how (if at all) the presence of metadata affects the ranking of a resource in their retrieval services.
The mechanism by which that aggregation takes place may vary: a resource provider may actively submit metadata records to the service (information "push"); or the service may "harvest" those metadata records from the resource provider (information "pull"). The Open Archives Initiative (OAI) metadata harvesting protocol represents a standardised approach to harvesting (based on the use of XML) so that metadata is made available to any service which seeks to use it [4]. In a "closed" context, the harvesting may take place according to system-specific procedures: indeed the use of the OAI protocol presumes that some level of aggregation will be performed internally by the resource provider before it is made accessible to external services through OAI.
The indexing of metadata records in situ for the purposes of enabling a central service to "cross-search" that distributed resource might be regarded as a distinct option. However, the objective in this case is usually to present to the end user a view of that distributed dataset as a unified whole. The records may not be copied to a single central database, but the results of a query are presented to the user as if that is the case - with many of the same challenges.
While the mechanism chosen may impose some constraints on the form and content of the metadata records, the key point is that metadata is created by resource providers with the expectation that it will be aggregated in some way by a service. As a prerequisite, it must be available in a form which that service can locate, access and use.
This has implications for the form in which metadata is created. Some file formats and resource creation tools provide some means of embedding metadata within the resource: the use of HTML <meta> elements was noted above; the document summary information available within word processor tools like Microsoft Word is another example. However, that information has little value as metadata unless it can be extracted from the resource and made available to an aggregation service, and for proprietary file formats that may be a complex task.
An alternative to embedding metadata within a resource is to create it as a separate but related resource: that may be a separate file or a record in a database. The resource may contain a pointer to the metadata (for example an HTML <link> element) and the metadata will almost certainly contain a pointer to the resource.
In short then, metadata for resource discovery may be created in diverse forms and made available to a range of parties using many different mechanisms. However, we can say with some certainty that metadata is created with the intention that it will be.
These two factors create requirements for the effective sharing of information which go beyond the requirements for information exchange within a community.
The Extensible Markup Language (XML) is a recommendation of the World Wide Web Consortium (W3C), a member organisation that develops technical specifications for the infrastructure of the Web [5]. The XML 1.0 specification defines a means of describing structured data in a text-based format. Within a short period of time (the XML specification was published in 1998), XML-based formats have been employed widely for storing data and especially for exchanging data between programs, applications and systems.
Within NOF-digitise projects, it may be appropriate to use XML for either or both of these functions. The main emphasis in this paper is on how XML can be used to share information about your resources. And while there may be many reasons for sharing such resource descriptions one will be the fundamental requirement for you to disclose information about the existence of your resources in a form which enables potential users to discover them.
It is worth considering briefly some of the reasons for the widespread success of XML. The specification emerged at a time when there was a clear demand to address precisely this problem of how to share effectively data created on one system with a recipient working on a remote system with quite different characteristics. Such data exchange did, of course, take place before the advent of XML, but it often represented a complex and costly part of application development.
So, the owner or manager of the information can have confidence that the data they create can be read on a remote system (or indeed on their own system after a change of software). And the software developer is freed from at least some of the work in having to read or write many different (and rapidly changing) file formats. Many major commercial vendors have an interest in facilitating such data exchange, and several of the largest contributed to the development of the XML specification and have subsequently invested heavily in software initiatives that build on XML.
A note of caution is necessary, however: XML is not a "silver bullet" solution to all the difficulties involved in the effective exchange and reuse of information. Indeed, claims that an application or system "uses XML" provide little basis on which to judge how well it meets those challenges. This paper recognises the valuable role that XML plays, but also emphasises that XML addresses only one facet of the problem.
Markup is text that is added to the data content of a resource in order to convey information about that content [6]. The notion of markup pre-dates the use of automated information systems: the annotations that provided instructions about layout to typesetters were an example of markup. A "marked-up" document contains both data and markup. A markup language is a set of conventions for providing markup so that the reader can interpret accurately the intentions of its creator. At a minimum, the rules of a markup language must specify:
The Standard Generalized Markup Language (SGML) is the precursor of XML. It is an ISO standard (ISO 8879:1986), which, like XML, defines a means of describing structured data in text format, using markup embedded in the data. The description of SGML and XML as "markup languages" is slightly misleading, as neither the SGML standard nor the XML specification meets all the criteria listed above for a markup language. SGML and XML are sometimes described instead as "meta-languages". They both provide a general syntax for markup (i.e. they address the first of the three requirements above, and some parts of the second element), and they also provide a set of rules for defining an unlimited number of specific markup languages. So when someone says they are "using XML", what they usually mean is that they are using one or more of these specific markup languages in accordance with the general XML syntax rules.
The difference between SGML and XML is that the former provides a great deal more flexibility. That flexibility makes it a powerful tool, but the cost is one of complexity both in terms of the standard itself and the software required to implement it. XML is a subset of SGML that sacrifices some of that flexibility in return for the benefits that it is easier to use, with all the advantages mentioned in the previous section.
SGML evolved from the 1960s to the 1980s. It was designed primarily to meet the requirements of large scale document publishing systems, and some of its features are a reflection of the characteristics and constraints of automated processing systems at that time. Nevertheless, most of SGML's fundamental approach has been inherited by XML.
The premise underlying the "document-oriented" approach to markup is that all documents have structure, that is, they are made up of component parts and those parts have relationships with each other. The most visible facet of a document's structure (at least in the domain of printed documents) is that it has a physical structure: a document may consist of a number of pages, for example. Physical structure is contingent: the same document may be rendered with a different physical structure (e.g. printing more words per page will reduce the number of pages, or using a continuous scrollable screen display abandons the concept of the page completely).
However, a document has a logical structure that is independent of its physical rendition. Typically that logical structure is communicated to the reader through the use of presentational conventions - a heading is formatted "bigger and bolder" than the text of a section - and indeed when such formatting is removed, the reader is confused precisely because they lose the cues required to interpret logical structure.
Within automated systems, presentation is defined by using markup that instructs a program how to render text.
The problem faced by the publishing industry was that such formatting instructions are usually specific to individual programs, and furthermore the presentational requirements may be different for different output media. So embedding presentational markup in a document ties the document to a particular rendering program and limits the ability to re-publish in different formats.
The solution proposed by SGML is to use markup to identify the logical components of a document and to apply the formatting as a separate process. This use of markup is referred to as "descriptive markup": the author identifies "headings", "quotations" or "captions" without saying anything about font weight or size or indentation. This means that the source document is no longer tied through presentational markup to a particular rendering process, and that it can be re-published in multiple formats and multiple media through the application of different formatting processes.
The HyperText Markup Language, HTML, was conceived as a descriptive markup language: it provides (a fixed set of) markup for identifying a very simple set of structural components of a document (headings, divisions, lists, paragraphs etc) [7]. However, HTML also includes markup which is explicitly presentational (describing alignment, font size etc). Furthermore, the use of HTML has become inextricably associated with the formatting behaviour of a very few "user agents" (programs which render HTML documents), namely the small number of Web browsers which dominate the market. As a result, many authors have deployed HTML markup so as to achieve presentational effects using those formatting programs without considering the structures which that markup is describing - so for example, list structures are used simply to achieve indentation, headings for emphasis, and so on. The problems of the approach are highlighted when such HTML documents are "rendered" using other agents such as audio browsers, which depend on a coherent description of document structure. The W3C's promotion of the use of Cascading Style Sheets (CSS), and the associated "deprecation" of the presentational features of HTML, represent an effort to re-emphasise the descriptive aspects of HTML [8].
A further benefit of descriptive markup is that it makes the logical structure of a document available to other software applications that are not concerned with formatting. For example if occurrences of personal names in the text are explicitly identified, then an index of those names could be built.
The success of all of these operations (both formatting and more complex manipulation) depends on the document creator and the agent processing that document sharing the same understanding of the markup language - in all three of the aspects identified at the start of section 3.
From this point, the discussion will focus on XML. Many of the concepts are inherited from SGML, but because XML has attracted the interest of a different use group, there are often differences of emphasis and of terminology between the XML and SGML communities. And at the level of syntax, XML imposes its own layer of constraints.
It is not the main purpose of this paper to provide a detailed study of the syntax of XML, but this section presents a very brief overview with an emphasis on those features most relevant to the discussion of information sharing below. The basic principles of XML syntax are very simple, and will be familiar to anyone who has used HTML - though it should be noted that there are some important differences and the syntactic rules of XML are less permissive than those to which many HTML authors are accustomed. Again, those differences are not discussed in detail here [9].
XML uses tags embedded in the content of a document to delimit and label parts of the document, and those parts are known as elements. Tags themselves begin and end with special characters (<....>) so that they can be distinguished from the data content, and element end tags can be distinguished from start tags by a special character combination (</...).
The start and end tags include an element type name and may also contain attributes (see below). Elements may contain character data (only), other elements, a combination of character data and elements - or nothing (i.e. elements can be empty).
Attributes are pairs of names and values that occur within the start tag of an element. An individual element can contain only one occurrence of each attribute, and attribute values can contain only character data.
In section 3.1, we noted that strictly speaking XML was not a markup language. Rather, the XML specification provides rules to define specific markup languages. It also provides a means of formally describing those specific markup languages in a standard, machine-readable form so that the description of the language can be shared.
The purpose of markup is to describe the structure of a document. Further, individual documents can be classified by their type - we recognise classes of documents like memos, minutes, manuals, reports, timetables, and so on, and we do so on the basis that members of a class (or "instances") share a common structural model. Two different reports will contain a different number of sections and paragraphs, but they both conform to the same general model. Markup languages are created on precisely this basis: the designer identifies the common structural characteristics of a class of documents and constructs a markup language that can be applied to all the instances of that class.
The XML specification describes how to encode this common structural model in the form of a Document Type Definition (DTD). A DTD lists all the element type names and attribute names that are available to label the component parts of an instance document. It also describes constraints on the use of these elements and attributes that must be followed if an instance document is to conform to the model. So for example, a DTD specifies the names of attributes associated with an element type, or that occurrences of an element type should contain only certain other element types, and that they occur in a certain sequence, and so on. For example, a DTD which described the structural model for a (much simplified!) "report" could specify that the document should contain a main heading, followed by the name of the author, and then one or more sections, each of which should have a heading followed by a number of paragraphs.
A more recent specification from the W3C, XML Schema, specifies a second mechanism for capturing this class of information [10]. The XML Schema specification includes more powerful mechanisms for controlling element content than DTDs and also supports a more modular approach. Also, unlike DTDs, XML schemas are themselves encoded using XML syntax.
This paper will not describe DTDs or XML Schemas in detail. The key point is that both describe the structural model of a class of XML documents and define and constrain the markup that can be used in instance documents that conform to that model. A model might be described either by a DTD or an XML Schema, though the latter permits more information to be expressed and is generally more flexible. For example, XML Schema allows a schema creator to specify that the content of an element should be a date or a URI. New XML applications, and particularly data-oriented applications (see section 3.5), tend to use XML Schemas in preference to DTDs. Data-oriented applications are more likely to make use of XML Schema's capacity to express tighter constraints and the fact that the model itself is expressed in XML and the schema can itself be processed as an XML document. Sometimes the literature on XML uses the term "schema" more generally to encompass both DTDs and XML Schemas.
In terms of the requirements for the rules of a markup language listed at the start of section 3, a DTD or XML Schema provides the remaining parts of the second element - it describes what markup is allowed in an instance document. It defines both the "vocabulary" (the element type names and attribute names which may be used in an instance document) and the "structure" of the language (how elements and attributes may be related in an instance document). A DTD or XML Schema says nothing about what the markup means. It does not explain the semantics of the vocabulary (even if an XML Schema specifies that an element is of type "date", it can not express what sort of date that is) and it does not express the meaning conveyed by the structural relationships between component parts of the document. This point is explored further in section 4. However, since a description of the meaning of markup is an essential part of the description of a markup language, a DTD or XML Schema must be supported by additional documentation that provides this information to its human users. Such documentation consists at the very least of a "tag library" or "data dictionary" which lists the vocabulary of the markup language and describes its semantics; usually it includes more detailed guidelines on the use of that markup language. That documentation must support both the document creator applying markup to a document, and the recipient of a document who must interpret the markup of others.
Because DTDs and XML Schemas are machine-readable documents, if an instance document is associated with a specified DTD or XML Schema, a program can validate the document against that DTD or schema i.e. check that the element types and attributes used in the instance are defined in the DTD/Schema and that they are used in the instance in accordance with the constraints expressed in the DTD/Schema. Validation checks that the structure of the instance conforms to the structural model of the document type. Many XML parsers incorporate the capacity to validate against a DTD or XML Schema, though it should be noted that in XML, such validation is optional: there is no requirement that an XML document conforms to a DTD or XML Schema. The only structural constraints which an XML document must follow are the rules of "well-formedness", which, for the purposes of this discussion at least, require that elements have start and end tags, and are correctly nested.
This level of structural validation using a DTD or XML Schema performs only minimal checking of the textual content of XML elements or attributes. DTDs provide only very limited functionality in this area, and although XML Schemas extend this functionality, the validation provided at this level is rarely sufficient, particularly for "data-oriented" applications (see section 3.5), and there will usually be a requirement for some additional validation to be performed by application-specific software.
The control of content is, then, a major consideration for the creator of an XML document. That control may be as loose as conforming to general rules for the style and coverage of the content an element or it may be as specific as the selection of terms from "controlled vocabularies" (classification schemes, thesauri, taxonomies etc). Such controls remain largely outside the domain of XML itself, and can not be enforced by general purpose XML tools.
The generic structural "paradigm" used within XML is that of a tree structure. Simplifying slightly, a single "document element" (or "root element") contains a number of "children", which may in turn have "children" of their own, and so on to an unlimited number of levels, with the lowest levels, or the "leaves" on the tree, being text data. In XML syntax, the tree structure is represented (in its simplest form) as a set of nested elements.
Note that this is simply one way of representing the tree structure using the XML syntax: it represents the decision of one designer, and it is not the only way i.e. the same tree structure could have many different expressions using XML. This is a very important point and we return to it at the end of this section (see Figure 10.)
The tree-structure model is a simple but powerful one, and a wide range of structured data can be represented in this way - including the classes of data that are typically stored in a relational or object-oriented database.
Indeed the most widespread use of XML is in this area, rather than in the "traditional" area of "document markup" (though XML continues to be used in the latter area too). This capability was already present in SGML, but the complexity of SGML and its software tools made it much too costly and difficult to deploy in this context. In contrast, the simplicity of XML and the lightweight nature of its tools make it much better suited for this purpose. This assertion should be qualified by a note of caution that, even within the reduced complexity of XML, this sort of exchange depends on the careful management of several variables.
It should also be emphasised that such data exchange did take place before the advent of XML, using technologies designed specifically for that purpose (e.g. the Common Object Request Broker Architecture (CORBA)), and indeed that continues to be the case. From a strictly technical viewpoint, an XML-based approach may not be appropriate in all contexts, but there has been a massive deployment of XML in this area. Indeed that deployment has led to moves to improve the integration between the XML-based and non-XML-based technologies [11].
The term serialisation is used to describe the process of creating an XML-based representation of structured data that either is stored persistently in another form or has been created by an application within memory, in order to transmit that data to another application or system. At the other end of the transmission channel, it is read, parsed and de-serialised and, depending on the nature of the application, the data may be added to a persistent store (e.g. a database) at the "target" side of the exchange. In some cases the XML document might exist only for the brief duration of its transmission over a network; in other cases it may be stored in a semi-permanent form which is accessed by the target application some time later. The capability of XML to support this sort of exchange between different operating systems is one of the main reasons for its widespread use, and some major database vendors have begun to integrate such XML serialisation / de-serialisation functionality into their systems.
An analogy is sometimes drawn between XML elements and attributes and nouns and adjectives, with the suggestion that the designers of XML markup languages should represent "primary" content as character data and reserve attributes for "information about content". Such assertions perhaps reflect a rather narrow "document-oriented" perspective or experiences of the behaviour of a small subset of software tools. In fact, no such universal rules can be applied and different designers make different decisions about the use of elements and attributes. Figure 8 described one way of serialising a record from a database table using XML syntax, and in that form the data content of the fields in the table was represented as element content in the XML document. A second designer may take the decision to serialise the data using attribute values instead:
It is perhaps worth repeating at this point that while XML documents are human-readable, it is rarely the case that human readability is the primary design consideration - and this is especially true of data-oriented applications where the primary generators and consumers of the XML documents are software tools.
In fact, although the XML specifications use the SGML-based terminology of the "document", such a document may be any collection of information processed as a unit, and not necessarily one which we would label as a "document" in the more general sense of the word. Such a "unit" might be a report or a technical manual, but it might also be an employee record, a purchase transaction, or a metadata record describing an information resource - or indeed an aggregation of several of these units to be processed as a whole. Many "data-oriented" XML-based applications have little relationship with the "document-oriented" domain of publishing and formatting - though it should be noted that there are also a large number of XML applications that do retain precisely these concerns.
The document-data distinction should perhaps be thought of not as a simple opposition but as a continuum, with individual applications lying somewhere between the two poles. There is some correspondence between the position of an application on this document-oriented/data-oriented continuum and the way the XML document is created. Although there are exceptions to this generalisation, XML documents in a "document-oriented" application are typically created by the direct action of a human author using a text-based software tool (an "XML editor") to apply markup to the data content of a document. Such tools make use of the rules recorded in a DTD or XML Schema to ensure that the author can use only the markup that is permitted by the structural model.
This process of "marking up" a document is sometimes described as "encoding", and perhaps the most widely known "document-oriented" applications are those which make use of the of the Text Encoding Initiative (TEI) DTD to encode literary and linguistic texts for academic research, or the DocBook DTD for structuring technical documentation [12].
In contrast, in a data-oriented application the XML document is usually created by the action of an export or serialisation program that applies markup to data stored elsewhere, probably in a database. If a human creator created the content initially, they probably did so by entering it using a form without even being aware that it would be "marked-up" as an XML document! In such applications, the use of XML is completely invisible to the human users of the application, both the information manager and the end user - though of course not to the application designer or software developer.
The case of the Encoded Archival Description (EAD) DTD illustrates perhaps that the document-data distinction is not always clear-cut. EAD is a DTD for the encoding of archival finding aids [13]. Archival finding aids are highly structured documents that describe archival materials, and such finding aids are created in accordance with a number of structural and content standards. Usually, such finding aids have a hierarchical structure that incorporates description at various levels, from that of a high-level aggregate of material, through sub-groups of that whole, possibly down to the description of individual items. The standard documentation that supports the use of EAD tends to emphasise a "document-oriented" approach to the encoding of this information. It is certainly true that the higher levels of description within an archival finding aid usually consist of extended pieces of textual description. At lower levels, however, the descriptive information within the finding aids often has a regular tabular structure that has many of the characteristics we might associate with the data-oriented perspective. The tools and processes used to create EAD-encoded documents are a matter for the individual implementer to decide, but a "hybrid" approach is quite possible, with some information encoded using an XML editor and other parts created by exporting the content of database tables.
Some of the popular literature on XML suggests that "XML lets you make up your own tags". It is quite true that XML permits the document creator to choose whatever element type names and attribute names they wish (subject to XML's limitations on the use of special characters). Further, because validation against a DTD or XML Schema is optional, the XML specification itself imposes no requirement that the markup used in an instance is checked against a pre-existing model: the only requirement is that the document should be "well-formed". You could use element type names and attribute names that are not pre-defined elsewhere. However, it is vital to remember that the primary purpose of using XML is to share structured data (or documents) with another party.
As was emphasised in section 3.4, XML says nothing about the meaning of the element type names and attribute names that you assign. Even if you choose names that you consider meaningful, precise and unambiguous, you can have no certainty that a human recipient of your XML document will interpret your names as you intended or that a software agent will process your data elements as you expected. To avoid misinterpretation, you must establish prior agreement with the recipient in advance on exactly what your markup means: you must use a common markup language.
In theory your project could design your own markup language, create and publish a DTD or XML Schema and the supporting documentation to describe the language, and then ensure that all of your communication partners understand its meaning. This may be sustainable for XML-based information exchange within a "closed" community with a small number of partners, but even in this case it should be emphasised that the design of a markup language is not a simple task.
In short, then, you should only consider "making up your own tags" for XML documents which you are certain will be circulated only within the boundaries of your own system - and even then it is vital that you document the meaning of your markup for the benefit of other developers who will have to maintain that system in the future.
For sharing of information beyond the boundaries of a system, it is almost always preferable to adopt an existing DTD or XML Schema that reflects the consensus of a community. As the use of XML increases, there are XML markup languages for a wide range of applications in a number of domains, and many of these are recognised as standards for information exchange within particular communities.
The use of XML Schemas is a key component of the UK government's e-government Interoperability Framework (e-GIF) [14]. The e-GIF initiative is defining XML Schemas to describe and (through validation) control the structure (and to some extent, through data-typing constraints, the content) of information which is exchanged internally between government systems and in at least some transactions between government and external communication partners. Such schemas are central to the management of transactions to be conducted via the "Citizen's Portal" [15].
At this point, it is useful to consider a little more closely the requirements for the effective transmission of information using language. Consider the example of making a simple statement using the English language. For my statement to be interpreted correctly by a reader, we need to have agreement about (at least!) three things:
If my reader's interpretation of any of these factors differs from mine, then there is risk that my statement will not be interpreted as I intended.
A language community is defined by consensus on such conventions, and the same is true for the exchange of information using XML i.e. we can think of "markup language communities" where
This is best illustrated through some simple examples.
Suppose that I prepare a music catalogue using the (imaginary!) MusicCat XML Schema and publish my catalogue on the Web, and a remote collector prepares and publishes a catalogue using the same XML Schema (see Figure 11).
<catalogue>
<album identifier="http://pj.org/album/245">
<title>The Spotlight Kid</title>
<artist>Captain Beefheart</artist>
<track identifier="http://pj.org/track/723">
<artist>Captain Beefheart</artist>
<song identifier="http://pj.org/song/999">
<title>Grow fins</title>
<author>Van Vliet, Don</author>
</song>
</track>
<track identifier="http://pj.org/track/724">
<!-- and so on... -->
</track>
</album>
</catalogue>
<catalogue>
<album identifier="http://johnsmith.org/album/777">
<title>Clear Spot</title>
<artist>Captain Beefheart</artist>
<track identifier="http://johnsmith.org/track/888">
<artist>Captain Beefheart</artist>
<song identifier="http://johnsmith.org/song/999">
<title>Big eyed beans from Venus</title>
<author>Van Vliet, Don</author>
</song>
</track>
</album>
</catalogue>
Figure 11. Two MusicCat XML catalogues
Then I can read their XML document and locate tracks by a specified artist, but more importantly my software can search their document because I have already programmed it with the following mapping:
| User request: | Program action |
| Find identifiers of all songs with author "Van Vliet, Don" | Find values of identifier attributes of song elements which have an author child element with content "Van Vliet, Don" |
As with natural language, the difficulties arise when information must be shared beyond the boundaries of the community - and this is a primary requirement in the use of metadata.
Continuing the example above, suppose that a museum has published a description of its holdings using the (imaginary...) ArtCat XML Schema.
<catalogue>
<collection>
<identifier>
http://museumofmodernart.org/collection/12
</identifier>
<title>The Magic Band Sketches Collection</title>
<creator>Van Vliet, Don</creator>
<items>
<picture>
<identifier>
http://museumofmodernart.org/picture/63
</identifier>
<details>
<title>Zoot Horn Rollo</title>
<artist>Van Vliet, Don</artist>
</details>
</picture>
<picture>
<!-- and so on... -->
</picture>
</items>
</collection>
</catalogue>
Figure 12. An ArtCat XML catalogue
Then I can read their XML document and I can probably locate pictures painted by a specific artist in their catalogue. However, it requires either some guesswork on my part based on the element type names and attribute names or a reference to the documentation that describes the semantics and structure of the ArtCat schema.
To search across both catalogues, my software - the search component of my cross-domain metadata service - now has to be programmed with two mappings:
| User request: | Program action |
|---|---|
| Find identifiers of all "works" with "creator" "Van Vliet, Don" | MusicCat: Find values of identifier attributes of song elements which have an author child element with content "Van Vliet, Don" |
| ArtCat: Find content of identifier elements which have a picture parent element with a details child element which has an artist child element with content "Van Vliet, Don" |
In fact there are at least three separate problems to be addressed here, and these are considered in turn in the following sections.
The first problem is that two different XML Schemas can use the same term to express different concepts. In our examples above, both MusicCat and ArtCat use the element type name "artist". In this particular example, the difference in meaning is perhaps not so great and both might be seen as types of resource creator.
However, it is easy to think of examples where the same term is used with quite different meanings in different domains: the term "conductor" signifies three quite different concepts in the separate areas of public transport, classical music and electrical engineering - and yet it would be quite possible for three domain-specific XML Schemas to use the term as an element type name! As long as document instances are exchanged only within the domain - within the boundaries of that markup language community - then the name is interpreted unambiguously according to the conventions of that community. However, when this data is passed from one community to another or data from the three communities is combined (as in the case of a metadata aggregation service), we face the problem of the "collision" of names - the same term used with quite different meanings.
The W3C "Namespaces in XML" specification addresses this problem [16]. It allows names to be qualified by associating them with a "namespace". A namespace is a collection of names, and it has a unique name: the uniqueness of namespace names is guaranteed by making them URIs. Element type names and attribute names can then be qualified by a namespace name - which removes the ambiguity where two names from different schemas "collide".
At the syntactic level, the association between the "local part" of the name and the namespace name is made through the use of a namespace prefix. The prefix is associated with the namespace name (by a namespace declaration), and the prefix is then used to qualify names. The resulting qualified name has a local part and a namespace name.
The following example associates the element type name "title" with the namespace "<http://pj.org>".
<doc xmlns:my="http://pj.org/"> <my:title>XML and metadata sharing</my:title> </doc>
Figure 13. XML namespaces
A second example illustrates the use of two different namespaces to avoid a "collision" of names:
<doc xmlns:our="http://pj.org/"
xmlns:their="http://nof.org/">
<our:title>Metadata sharing and XML</our:title>
<their:title>
NOF Information Paper 5:
Metadata sharing and XML
</their:title>
</doc>
Figure 14. XML namespaces
Finally it should be noted that the title element in Figure 13 (my:title) has the same qualified name as the first title element in Figure 14 (our:title): it is not the namespace prefix which is significant, but the namespace name with which that prefix is associated.
The use of XML namespaces has probably caused more debate than any other XML-related subject. We certainly do not propose to revisit that debate here. The main point is that all XML namespaces do is provide a mechanism for qualifying names to make them unique (the use of URIs) and a shorthand syntax for applying this in XML documents (the use of namespace prefixes).
The second problem in the example above is that the two XML Schemas (MusicCat and ArtCat) use different element type names ("author" and "artist") to express the concept of the "creator" of two different types of resource. In fact the two names probably convey to their human reader rather more than the concept of "creator", since they express more information about two different processes of creation.
These differences are important to the manager of those resources and to the user of this information within the respective domains. From the point of view of a fairly simple process of resource discovery, however, the concept of "the creator of the resource" is often satisfactory. This is not the same as saying that the distinction between an "author" and an "artist" is irrelevant: rather, that there are some contexts where that distinction is not of primary importance.
The Dublin Core Metadata Element Set is usually presented as a small set of terms (only 15 elements in its basic subset) which describe properties common to most types of resource, and which can be used for composing simple descriptions of resources [17]. However, since we have approached the subject of metadata sharing as one of communication and the use of language, it is appropriate to apply this same perspective here. In an important article [18], Tom Baker presents the view that the Dublin Core element set is a small vocabulary that can be used to make simple statements: Dublin Core performs the role of a "pidgin" language. The markup languages of the many different resource description communities are certainly more powerful and expressive than the Dublin Core pidgin, and that power is appropriate for communication within those communities where it can be interpreted as its "speakers" intend. As with natural language, however, when information is shared beyond the community - as is the case with metadata - , some simplification of that expression is often the most effective means of communication.
At this point in the paper, we concentrate on the first aspect of the Dublin Core pidgin: its simple vocabulary. Baker's article emphasises the simple structure of its statements, and we return to this aspect in section 4.2.3. The proponents of Dublin Core do not suggest that this simple vocabulary serve as the "native" lexicon of each community (though in some cases it may prove adequate). Rather those communities should seek to "map" the terms of their local languages - or at least a subset of those terms - to the terms of the Dublin Core vocabulary and make descriptions of their resources available in this simplified form - which (it is hoped!) a larger proportion of readers outside of the community will be able to interpret and understand.
The Open Archives Initiative (OAI) metadata harvesting protocol recognises the value of this approach in its requirement that metadata records be made available using the simple Dublin Core vocabulary (and OAI provides a corresponding XML Schema for this purpose). OAI allows a resource provider to make available records conforming to other schemas, but the availability of simple DC records is mandatory. The Technical Standards & Guidelines for NOF-digitise also mandate that Dublin Core descriptions are produced:
In order to facilitate potential exchange and interoperability between services, item level descriptions must be capable of being expressed in Dublin Core and should be in line with developing e-government and UfI metadata standards. [19]If the MusicCat and ArtCat XML Schemas had made use of XML namespaces to disambiguate the names of all element types and attributes, and had made use of the more generic Dublin Core elements in place of the domain-specific names like "author" and "artist", the above examples might appear as:
<music:catalogue xmlns:music="http://music.org/"
xmlns:dc="http://purl.org/dc/elements/1.1">
<music:album dc:identifier="http://pj.org/album/245">
<dc:title>The Spotlight Kid</dc:title>
<dc:creator>Captain Beefheart</dc:creator>
<music:track dc:identifier="http://pj.org/track/723">
<dc:creator>Captain Beefheart</dc:creator>
<music:song dc:identifier="http://johnsmith.org/song/999">
<dc:title>Grow fins</dc:title>
<dc:creator>Van Vliet, Don</dc:creator>
</music:song>
</music:track>
</music:album>
</music:catalogue>
<art:catalogue xmlns:art="http://art.org/"
xmlns:dc="http://purl.org/dc/elements/1.1">
<art:collection>
<dc:identifier>
http://museumofmodernart.org/collection/12
</dc:identifier>
<dc:title>The Magic Band Sketches Collection</dc:title>
<dc:creator>Van Vliet, Don</dc:creator>
<art:items>
<art:picture>
<dc:identifier>
http://museumofmodernart.org/picture/63
</dc:identifier>
<art:details>
<dc:title>Zoot Horn Rollo</dc:title>
<dc:creator>Van Vliet, Don</dc:creator>
</art:details>
</art:picture>
</art:items>
</art:collection>
</art:catalogue>
Figure 15. MusicCat and ArtCat using XML Namespaces and Dublin Core
However, even with the use of namespaces to qualify names and the pidginisation of some of the terms drawn from domain-specific vocabularies, the cross-domain search service must still be programmed with two sets of mappings:
| User request: | Program action |
|---|---|
| Find identifiers of all "works" with "creator" "Van Vliet, Don" | MusicCat: Find values of dc:identifier attributes of music:song elements which have a dc:creator child element with content "Van Vliet, Don" |
| ArtCat: Find content of dc:identifier elements which have an art:picture parent element with an art:details child element which has an dc:creator child element with content "Van Vliet, Don" |
These multiple mappings are necessary because the two different XML Schemas employ different structural conventions to express relationships between units of information. For example, the statement that a resource (album, track, song, collection, picture etc) has a "creator" is expressed using different XML constructs in the two schemas - and within the ArtCat schema different conventions are used for the "collection" and the "picture". These are simply the choices of the schema designers and all are equally good and valid.
A human reader of the document may be able guess the conventions, but a software tool must be programmed with prior "knowledge" of the different structural conventions in use.
While this may be sustainable for a service operating over instance documents conforming to a small number of different XML Schemas, it is not scalable to a context in which the number of schemas and the number of structural conventions is ever increasing - which is quite likely to be the case for a service operating on metadata from several domains.
Tim Berners-Lee summarises the problem:
XML allows users to add arbitrary structure to their documents but says nothing
about what the structures mean
Berners-Lee, 2001 [20]
The solution proposed by Berners-Lee and the W3C is the adoption of a common simple model for the expression of statements about resources, and a set of standard syntactic conventions for representing those statements in XML. In adopting this standard model and the syntax to represent it, communication partners accept a common convention for the meaning of structures in their XML documents. This is what the Resource Description Framework (RDF) seeks to provide.
The Resource Description Framework (RDF) Model and Syntax is another recommendation of the W3C [21]. (There are a number of other specifications that build on RDF, RDF Schema being of particular importance, but they will not be discussed here.) The designers of RDF sought to address the requirements for exchanging metadata and for combining metadata from diverse sources, while leaving the description of the semantics of that metadata to the appropriate resource description communities.
The premise underlying RDF is that metadata consists of simple statements about resources. This is similar to Tom Baker's approach to the pidgin "grammar" of Dublin Core: as well as adopting a small vocabulary, pidgin speakers employ that vocabulary using simple sentence patterns that can be used in many different contexts.
In RDF, those statements take the form: a resource has a property which has a value, and the value may be a string (a literal) or a second resource. In RDF, a property is an "attribute" (in the general sense of the word!) used to describe that resource.
For example, Figure 16a represents the statement that:
Figure 16a. The RDF model
Figure 16b extends that first statement by adding that:
Figure 16c illustrates that the second resource can also be uniquely identified:
A resource is anything which can be identified by a Uniform Resource Identifier (URI) - which turns out to mean "anything that has identity" [22]. That "thing" need not exist as a physical or digital object, but if we assign a URI to it, that assignment enables us to make statements about it! Sometimes, when a URI has been assigned to a resource, then the resource is described as being "on the Web". Further, it is common practice for people making statements about resources to ensure the uniqueness of their URIs by using URIs constructed on the basis of the domain name of a Web server, and carrying the http: scheme prefix. This convention is a means of ensuring uniqueness, but that is all it is: the use of http:-based URIs does not mean that anything exists at the location identified if that string is interpreted as a URL.
So, anything can be identified by a URI. The properties used in an RDF statement can be uniquely identified by URIs, which is useful when we wish to combine statements which use the vocabularies of different resource description communities:
This simple model proves to be extremely powerful. It is extensible: RDF provides a pidgin grammar, but it has little to say about the vocabulary to be used. In fact, RDF allows properties to be drawn from any vocabularies, and multiple vocabularies can be used in the same document. Further, these simple statements can be combined to build up more complex ones. Because URIs provide unique identifiers for both resources and properties, statements created independently by different authors can be "merged".
Figure 17a. Merging RDF descriptions
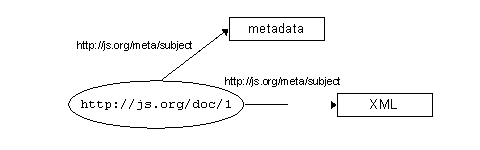
Figure 17b. Merging RDF descriptions

Figure 17c. Merging RDF descriptions
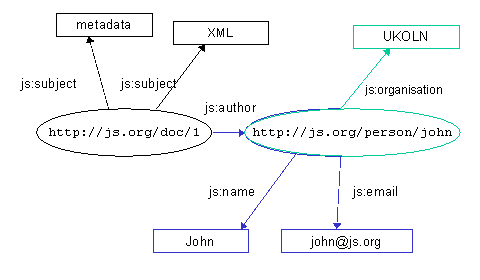
Figure 17d. Merging RDF descriptions
This model is independent of XML - RDF-based statements could be (and indeed are) recorded in many different forms - but the RDF Model & Syntax recognises the value of XML as a syntax for exchange and defines conventions for expressing RDF statements in XML. The document fragments in figures 18a to 18d correspond to the descriptions portrayed diagrammatically in figures 17a to 17d. Figure 18d represents the merged description:
<rdf:RDF xmlns:js="http://js.org/meta/">
<rdf:Description about="http://js.org/doc/1">
<js:author>
<rdf:Description about="http://js.org/person/john">
<js:name>John</js:name>
<js:email>john@js.org</js:email>
</rdf:Description>
</js:author>
</rdf:Description>
</rdf:RDF>
Figure 18a. Merging RDF/XML descriptions
<rdf:RDF xmlns:js="http://js.org/meta/">
<rdf:Description about="http://js.org/doc/1">
<js:subject>metadata</js:subject>
<js:subject>XML</js:subject>
</rdf:Description>
</rdf:RDF>
Figure 18b. Merging RDF/XML descriptions
<rdf:RDF xmlns:js="http://js.org/meta/">
<rdf:Description about="http://js.org/person/john">
<js:organisation>UKOLN</js:organisation>
</rdf:Description>
</rdf:RDF>
Figure 18c. Merging RDF/XML descriptions
<rdf:RDF xmlns:js="http://js.org/meta/">
<rdf:Description about="http://js.org/doc/1">
<js:author>
<rdf:Description about="http://js.org/person/john">
<js:name>John</uc:name>
<js:email>john@js.org</js:email>
<js:organisation>UKOLN</js:organisation>
</rdf:Description>
</js:author>
<js:subject>metadata</js:subject>
<js:subject>XML</js:subject>
</rdf:Description>
</rdf:RDF>
Figure 18d. Merging RDF/XML descriptions
Furthermore, the RDF model corresponds well to the data used within relational and object-oriented databases: it is relatively easy to express the information held in a database using the RDF model and to publish that information using the RDF/XML syntax. And once it is published in that form it is available for querying and processing in association with similar data from other sources. Returning to the example above, where three sets of RDF statements were "merged", imagine that the sources of those three sets of statements were records stored in three quite separate databases. The databases can be queried separately, certainly, and a human user could perform three separate queries and merge the results together. Once the data is published using RDF, programs can join the previously separate statements together - and other parties can begin to add new statements about those resources.
We noted above that in many cases XML documents are created by programs rather than by human authors, and this holds even more so for RDF/XML documents.
In short, then using RDF in association with XML means adopting specified conventions for the meaning of structures in an XML document. By constraining the options available, RDF enhances interoperability by reducing the risk that a document is misinterpreted. A reader of the document who is aware of those conventions and who recognises that the document is applying them can interpret the meaning of the structures without ambiguity.
Furthermore, the reader can do so on the basis that they may not be familiar with all the vocabularies used in the document, but they are able to recognise the statements made about resources and extract those statements which use the vocabularies they do recognise. For example, consider the instance document in Figure 19:
<rdf:RDF xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:js="http://js.org/meta/">
<rdf:Description about="http://js.org/doc/1">
<dc:title>Metadata sharing and XML</dc:title>
<dc:creator>John Smith</dc:creator>
<js:rating>3</js:rating>
</rdf:Description>
</rdf:RDF>
Figure 19. A multi-vocabulary RDF/XML description
Any RDF-aware application reading that document will interpret it as containing three statements about the resource http://js.org/doc/1. Suppose the application has been programmed to seek statements made using the properties of the Dublin Core element set - perhaps it is part of an aggregation service reading descriptions harvested from the Web in order to compile a database of Dublin Core-based resource descriptions. The properties of the Dublin Core element set are of course all identifiable by URIs. The application "recognises" that two of the statements in this description use Dublin Core properties and it can create the appropriate database entries. The third statement uses a property http://js.org/meta/rating which the application does not recognise - it is presumably of interest to another use community - and the application can simply ignore that statement. (If the application had access to additional information about the relationships between terms from different vocabularies, then it might be able to establish that it was in fact the equivalent of a Dublin Core property, but that is beyond the scope of this discussion.)
For a cross-domain metadata service, then, the use of RDF/XML addresses the scalability issue of having to manage the structural conventions of an ever-expanding number of domain-specific XML Schemas. It also permits the use of multiple vocabularies in a manner which allows partners to communicate, at least on a basis of "partial understanding".
At the time of writing (late 2001), there is a good deal of enthusiasm about the potential of RDF. It forms the cornerstone of Tim Berners-Lee's vision of a "Semantic Web", and there is considerable activity in this area at the W3C and within academic research communities. There are some RDF applications in use outside this context - the most widely deployed is perhaps RDF Site Summary (RSS), used primarily to deliver metadata about news stories between content providers and portals on the Web [23].
However, RDF has not yet been adopted as widely as its developers and supporters might have hoped. In part, this is perhaps a problem of perception: because the interest in RDF is coming in the first instance from research communities, it is perceived as theoretical. And indeed, some of the discussions about RDF tend to be cast within a language which is not immediately familiar to the XML community. Further, at the time of writing (November 2001), a W3C working group is in the process of making some (minor) revisions to the RDF Model & Syntax specification and completing work on the RDF Schema specification [24].
As a consequence, there are fewer RDF-based software tools available, and considerably less expertise amongst application designers and software developers than is the case for XML - though this situation is changing.
However, there is a real danger of ignoring the existence of the problems that RDF is designed to address, and which this paper has sought to explain.
XML is designed specifically to support the sharing of structured data across applications and systems, and it has a vital role to play in the sharing of metadata to facilitate resource discovery.
The essential contribution that XML makes is to provide a syntax for data exchange, but this is only one of the requirements for effective sharing of information using XML. The adoption of a standard schema for resource description and the use of that schema in accordance with its supporting documentation provides a vocabulary and the semantics associated with that vocabulary.
Conformance to a community standard XML DTD or XML Schema represents adherence to a common structural model and consensus on what that structural model conveys - an agreement on grammar. XML document instances can be shared within that community and their syntax, semantics and structure will be unambiguous to their recipients.
However, one of the defining characteristics of metadata is that it is shared beyond the boundaries of a single community. In this open environment, the use of XML namespaces and of small "pidgin" vocabularies like the Dublin Core metadata element set provide support for syntactic and semantic interoperability, but the multiple XML DTDs and XML Schemas of the different communities lack a common convention for the meaning conveyed by structure - they do not share a common grammar.
The RDF Model and Syntax specification seeks to provide this common grammar by specifying the meanings of structures: by constraining the options available to express meaning through structure, the risk of ambiguity and misinterpretation is reduced and the potential for interoperability between systems is increased.
|
Does your project intend to use XML for data storage or for data exchange or both? |
|
What types or classes of data are to be stored or shared using XML? |
|
Do standard XML DTDs or XML Schemas for the description of this data exist? |
|
How will you create your XML documents? Will they be authored with a suitable editor or generated by software tools? |
|
With whom do you need to share your data or metadata? |
|
Are you exchanging data or metadata through specific agreements with a defined number of partners? |
|
Are you supplying metadata to specific services? Do those services specify requirements for the syntax, structure and semantics of the data they accept? Do those services specify conformance to XML DTDs or XML Schemas which they provide? |
|
Or are you intending to make data or metadata available in a more "open" environment, with the expectation that it may be used by a potentially unlimited number of services? |
|
Is it appropriate to make that metadata available through OAI? |
|
Is it appropriate to make that metadata available in an RDF/XML form, as well as a form based on a standard XML DTD or XML Schema? |
[1] For more information, see UKOLN, nof-digitise Technical Standards and Guidelines Version 3, (July 2001). Available at
http://www.peoplesnetwork.gov.uk/content/technical.asp
[2] Berners-Lee, Tim, "Metadata architecture", "Design issues" working paper (January 1997). Available at
http://www.w3.org/DesignIssues/Metadata.html
[3] Dempsey, Lorcan and Rachel Heery, "Metadata: a current view of practice and issues", Journal of Documentation 54 (2), (March 1998). Preprint version available at
http://www.ukoln.ac.uk/metadata/publications/jdmetadata/
[4] The Open Archives Initiative Protocol for Metadata Harvesting Version 1.1 (July 2001). Available at
http://www.openarchives.org/OAI/openarchivesprotocol.html
[5] Extensible Markup Language 1.0 (Second Edition) (October 2000). Available at
http://www.w3.org/TR/REC-xml
[6] This section draws heavily on the introductory sections of:
Goldfarb, Charles F. The SGML Handbook, Oxford University Press (1990).
[7] HyperText Markup Language (HTML 4.01) (December 1999). Available at
http://www.w3.org/TR/REC-html40/
[8] Cascading Style Sheets, Level 1 (December 1996). Available at
http://www.w3.org/TR/REC-CSS1
[9] Introductions to XML syntax include:
Ray, Erik. "Markup and Core Concepts", Chapter 2 of Learning XML: (Guide to) Creating Self-Describing Data (January 2001). Available at
http://www.oreilly.com/catalog/learnxml/chapter/ch02.html
Walsh, Norman. "A Technical Introduction to XML", xml.com (October 1998). Available at
http://www.xml.com/pub/a/98/10/guide0.html
[10] XML Schema is published in three parts:
Part 0: Primer (May 2001). Available at
http://www.w3.org/TR/xmlschema-0/
Part 1: Structures (May 2001). Available at
http://www.w3.org/TR/xmlschema-1/
Part 2: Structures (May 2001). Available at
http://www.w3.org/TR/xmlschema-2/
[11] For information on CORBA, and on the relationship of CORBA and XML, see the Object Management Group site at
http://www.omg.org/
particularly the CORBA, XML and XMI Resource Page at
http://www.omg.org/technology/xml/index.htm
[12] The Text Encoding Initiative web site is at
http://www.tei-c.org/
The DocBook website is at
http://www.docbook.org/
[13] The Encoded Archival Description website is at
http://www.loc.gov/ead/
[14] Cabinet Office, e-government: a strategic framework for public services in the Information Age, (April 2000). Available at
http://www.e-envoy.gov.uk/ukonline/strategy.htm
Cabinet Office, e-government Interoperability Framework, Version 3, (October 2001). Available at
http://www.govtalk.gov.uk/interoperability/egif_document.asp?docnum=363
[15] The UKonline.gov.uk website is at
http://www.ukonline.gov.uk/
[16] Namespaces in XML (January 1999). Available at
http://www.w3.org/TR/REC-xml-names/
[17] The Dublin Core Metadata Initiative website is at
http://dublincore.org/
[18] Baker, Thomas. "A Grammar of Dublin Core", D-Lib 6 (10), (October 2000). Available at
http://mirrored.ukoln.ac.uk/lis-journals/dlib/dlib/dlib/october00/baker/10baker.html
[19] UKOLN, nof-digitise Technical Standards and Guidelines Version 3, (July 2001). Available at
http://www.peoplesnetwork.gov.uk/content/technical.asp
[20] Berners-Lee, Tim, James Hendler and Ora Lassila, "The Semantic Web", Scientific American, (May 2001). Available at
http://www.sciam.com/article.cfm?articleID=00048144-10D2-1C70-84A9809EC588EF21
[21] Resource Description Framework Model and Syntax Specification, (February 1999). Available at
http://www.w3.org/TR/REC-rdf-syntax/
[22] RFC 2396: Uniform Resource Identifiers (URI): Generic Syntax , (August 1998). Available at
http://www.ietf.org/rfc/rfc2396.txt
[23] RDF Site Summary (RSS) 1.0, (December 2000). Available at
http://purl.org/rss/1.0/spec
[24] The RDF Core Working Group website is at
http://www.w3.org/2001/sw/RDFCore/
This section will be used to provide notes on the section, including details of any changes.
This section is available at <http://www.ukoln.ac.uk/nof/support/gpg/Preservation/>
This section is based on the information paper which was provided for the NOF-digitise programme which provided advice and guidance to projects funded by the NOF-digitise programme on preservation of their digital content. However the advice provided in this section should still be appropriate for new projects.
A basic definition of digital preservation is the maintenance of digital material over the long-term with a view to ensuring continued accessibility. Digital material refers to any material processed by a computer and includes both that which is "digitised" (reformatted to digital) as well as those resources that are "born digital". Long-term in this context should be taken to mean long enough to be concerned with the impact of changing technologies - and should include timescales of decades and even centuries. There has been a great deal of confusion around the term "digital preservation" mainly because of early projects that (perhaps inadvertently) equated the process of digitisation with preservation. In general, digital preservation involves a number of organised tasks associated with a variety of technical approaches or strategies for ensuring that digital resources are not only stored appropriately, but also adequately maintained and thus consistently useable over time. Day-to-day preservation is based around the management of archive copies of deposited data resources - i.e. copies that are independent of any online representation.
Put simply, a digital preservation strategy is a particular technical approach to the preservation of digital materials. There are three main technical approaches to preserving digital materials: technology preservation, technology emulation and data migration. The first two focus on the technology itself. In order to preserve the functionality of any digital resource there must be preservation, in some form, of the technical environment that created and employed it. Data migration strategies focus on the need to maintain the digital files in a format that is accessible using "current technology". In this strategy scenario, files require regular migration from one technical environment to another, newer one. Each strategy will be described briefly in turn but it is important to realise that even within each approach there are variations.
If digital material relies on the technical environment used to create it in order to preserve the functionality and "look and feel" of the product, then the most obvious approach is to preserve the original technology. This is a "museum style" approach and probably only suitable as a short-term solution. Hardware and software from the object itself are maintained so that access can be guaranteed. However, this generally means that access is limited to a specific physical location (i.e. where the hardware/software are kept) and the cost/space implications for storing this kit are probably beyond the realm of possibility on a large scale. Over a number of years the machines themselves will inevitably degrade making this approach problematic as a long-term strategy. The Science Museum and the Computer Conservation Society in the UK are interested in the merits of this approach and are currently maintaining old computer systems that may prove valuable resources for scholars in the future. For a library, archive or publisher, the sheer space and resources needed to maintain old systems would in all likelihood make this approach impossible.
Another approach based on the need to preserve the technological environment (and therefore original functionality) is emulation. Unlike the strategy described above, an emulation strategy seeks to preserve that environment not through the preservation of original hardware/software but by using current technology to mimic the original environment. This might involve emulation of the original software or (more likely) emulation of the original hardware (in this case the original software and operating system are stored along with the digital object itself). Either way, the strategy relies on a detailed description of the original environment on which to base the emulation in future. The emulator itself is not necessarily stored in the archive (although it may be, it may be created at a later date when there is demand for the material. The detailed technical descriptions (metadata - see below) on which this strategy is often based is a key component of an emulation strategy and. As yet, there are no standard approaches available for descriptions of this kind.
Although controversial, many experts are beginning to believe that for truly long-term preservation emulation is the best solution. It accepts the necessary conundrum of preserving the original technical environment but it ensures that material is not held hostage to obsolete technology. Instead it can take advantage of new technologies as they develop for emulation. Although we are unable to predict how future technologies will develop, we can be certain of some general principles - it will be more effective, cheaper and faster.
Unlike the strategies above, data migration focuses on maintaining digital material in current formats. At present many libraries and publishers are involved in regular migrations for image files e.g. moving images from one software version to a newer version. The attraction of this strategy is that material is maintained in an accessible format. The two strategies above both advocate storing the material as a bytestream in its original format and then making it accessible when necessary. Data migration means the material is maintained in the archive in a currently useable format.
However, there are also significant disadvantages to this strategy:
It is important to stress that data migration as it is described here is more complex than what is often called data "refreshing". All preservation strategies must include regular data refreshing which is the systematic transfer of stored material to newer and fresher media (e.g. from one magnetic tape to another). Refreshing does not imply ensuring the material is kept useable - it is only the transfer of a bytestream from one medium to another. Migration focuses on keeping the material functional with new technology.
The effective use of digital resources in an archive will rely on a robust system of resource description - for the purposes of resource discovery, managing access and ensuring preservation of the resources. Metadata research has continued to generate interest world-wide but, to date, most of activity has focused on metadata for resource discovery. However, there is increasing awareness that effective digital archives will depend on the creation and storage of relevant descriptive information (metadata) required to support a chosen preservation strategy, whether migration, emulation or technical preservation. This information will need to describe the data in detail including file format, software and hardware platforms. It may also contain information about rights management and access control. UKOLN has led a great deal of the work on preservation metadata for the Cedars project [1] and the first public draft of the Metadata for Digital Preservation: the Cedars Project Outline Specification was released in March 2000. Well-kept digital preservation metadata is essential and all NOF projects must comply with the technical standards and guidance published [2].
A summary of the three main strategic approaches to digital preservation
Technology preservation strategy: preserve the individual software (and possibly hardware) that was used to create and access the information; also involves preserving the original operating system and hardware on which to run it
Technology emulation strategy: programme future powerful systems to emulate older obsolete computer platforms/operating systems as required
Digital information migration strategy: ensure that digital information is re-encoded in new formats before the old format becomes obsolete.
Choice of strategy must reflect fitness for purpose. Certain technical factors will impact on this choice: the basic data types employed in each category; the application programs used to create them; the structures applied to them; the systems used to manage or distribute them prior to deposit.
Maintaining access to archived digital resources over the long term involves interdependent strategies in the short/medium term based on:
A preservation strategy is going to be most effective if it takes into account the full life-cycle of the resource - allowing for the greatest efficiencies between: data creation; access and preservation.
Unique numbering
Every data source accessioned should be allocated a unique identifier. This number will identify the resource in the institution's catalogue and be used to locate or identify physical media and documentation - if a resource is de-accessioned for any reason, this unique number should not be reallocated.
Preferred marking and labelling
At a minimum all physical media and hard-copy documentation should be marked with the unique number allocated to the resource, and any additional information required by the institution to easily identify content and formats.
Handling guidelines
From accessioning, guidelines should be followed that reflect best practice in storage/preservation handling for the different media involved.
Validation
Validation checks should be carried out by the institution on transfer media; content; structure of deposited data resources, and on any accompanying documentation.
Validation procedures may well need adapting in the light of the materials/resources available in the acquisitions/collections section - and some of these procedures will have to be undertaken manually.
Such checks may include:
Re-formatting file formats
Where the file formats used to transfer the resource are unsuitable for long-term preservation, the institution may reformat the resource onto its preferred file formats. In addition to archive formats, versions in other formats suitable for delivery to users may also be produced from the original
Reformatting storage media
Where storage media used to transfer the resource are unsuitable for long-term preservation - the institution may reformat the resource onto its preferred media
Copying
Multiple back-up copies of an item may be generated during accessioning as part of a storage and preservation policy and to enable disaster recovery procedures.
Digital Culture: Maximising the nation's investment
http://www.ukoln.ac.uk/services/elib/papers/other/jisc-npo-dig/
Dublin Core metadata Initiative
http://dublincore.org/documents
AHDS Guide: Creating a viable data resource
http://www.ahds.ac.uk/viable.htm
This section will be used to provide notes on the section, including details of any changes.
This section is available at <http://www.ukoln.ac.uk/nof/support/gpg/Accessibility/>
This section is based on the information paper which was provided for the NOF-digitise programme which provided advice and guidance to projects funded by the NOF-digitise programme on setting up accessible Web sites.
The document refers to the NOF-digitise programme. However the advice provided in this section should still be appropriate for new projects.
As the use of digital networks becomes pervasive, the imperative to develop Web sites and Web services that are accessible to all users becomes apparent. Much work has been done since the inception of the Internet to understand the issues surrounding accessibility and groups such as the WAI at the World Wide Web Consortium have produced structured guidelines to assist developers.
The subject of digital accessibility is a very broad one and encompasses many different sub-sets of user requirements accordingly. The challenge facing Web site developers is to harmoniously integrate the formal requirements of the design and function of their sites with the current accessibility standards and guidelines.
Responsibility for the publication of a publicly-accessible Web site demands that the developers understand the very diverse range of means by which their online resources may be accessed and used. Satisfactory appearance and usage of a site depends upon firstly understanding the audience and their requirements then applying that understanding in the specification and development of the site.
The two areas of accessibility and usability have significant overlap in scope and intent. Put simply, a 'usable' site can be considered to be one that is fully accessible to all users whatever their means of access and physical impairment. However, usability criteria extend into less definable elements regarding process and work flow required by both the site structure and the user interface. All projects aiming to develop material for Internet delivery should have as one of their foremost goals the attainment of a fully usable service and that within that goal there should be a clear acknowledgement that this is only achieved once all accessibility issues have been satisfactorily resolved.
The authoritive group concerned with the accessibility of Web resources is Web Accessibility Initiative (WAI), a group within the umbrella of the World Wide Web Consortium (W3C). The WAI have been active over many years in producing a structured set of guidelines representing 3 levels of compliance. These are referred to as level A, AA and AAA, with level A containing the minimum set of requirements and AA and AAA building deeper upon them. Each level is broken up into two parts: recommendations and requirements. It is not in fact possible to mandate and codify the measures necessary to be classed as 'accessible', as some of the issues cannot be assessed automatically and can only be assessed by human judgement - the selection of colour schemes, the judicious choice of alternative text for images and graphics, etc.
The NOF-digitise programme standards, for example, required all participants to achieve at least the WAI level A requirements. In practice it was found that most projects were able to fulfill all the demands and satisfy the guidelines to at least level A. Problems achieving compliance were mostly encountered with the use of JavaScript. We will therefore address some of these issue in some detail.
JavaScript is the predominant scripting language used to programme client browsers. JavaScript is a very useful tool, able to bring enhanced levels of functionality to pages and improve the visual interface in various ways - richer navigation schemes, selective layer visibility, mouse-triggered events and so forth. However, where these techniques become essential to the gain full access and use to the site, there is an accessibility problem. Level A compliance (and beyond) require a site to be fully accessible without JavaScript enabled. There are three reasons for making this demand:
Therefore, it is essential that pages are designed to fail gracefully when intended JavaScript functionality is not available on a client browser so that they do not result in the user being locked out from content or functionality on the site. It is necessary to distinguish between core and non-core uses of scripting: where scripting is used to enhance a page and does not result in any significant loss of experience in a non-JS enabled client, there is no real issue to resolve. However, where JavaScript has a core role on the page, for example in providing nested 'rollover' navigation devices, the non-JS client will not be able to fully access the site. This is not acceptable and other methods should be sought to provide the same level of functionality.
Due to the numerous applications to which JavaScript can be put to use on a page, it is difficult to produce effective advice covering all possible situations but the following general coding advice may be helpful in many common cases.
NOSCRIPT tags are very useful and should always be considered whenever a script block is inserted into a page. NOSCRIPT tags are ignored by browsers where scripting is enabled but interpreted when it is disabled. Combined with the use of 'document.write()' calls to insert HTML into the page, they allow areas of the page to be handled completely differently according to scripting capabilities. For example, if a polling script where to be inserted on a page that required JavaScript to function, the entire HTML necessary to display the polling utility on the page would be held within the SCRIPT tag and output using document.write(). The NOSCRIPT tag can then fill the same space with some alternate content.
The NOSCRIPT tag can also be useful to display a warning to a user, on the home page or elsewhere, notifying them that the site requires JavaScript to function properly or that some extra functionality may be lost if it is not enabled.
A common use of JavaScript is to control the display of large version images in pop-up windows. This is a good use of JavaScript but often causes problems. The following is advised:
EXAMPLE:
JavaScript dependent approach:
<a href="javascript:open_win('/img/large-image/y942_843_loa_85')">
<img src="/img/small-image/y942_843_loa_85.gif" alt=".." title="..">Click for larger photo </a>
Accessible approach:
<a onclick="open_win('/img/large-image/y942_843_loa_85'); return false;"
href="/img/large-image/y942_843_loa_85" alt=".." title="..">
<img src="/img/small-image/y942_843_loa_85.gif">Click for larger photo</a>
There are two main methods used to test a client's functionality in order to determine the (likely) functionality available and hence the compatibility of the browser with the JavaScript intended for the page.
Many scripts will parse the 'user agent' string written in to the browser to determine its type and version. However, this method may encounter problems as the user agent string value may be altered in any individual browser - some browsers give the user the ability to change or customise the user agent value, in other cases it is possible for a knowledgeable user to alter it - for example, the user agent value is held in a registry key in Windows Internet Explorer, and can be simply altered by editing the registry.
The preferred method to determine client-side functionality is to directly test for the desired capability. The required method / object / value is tested first and the code only executed if the test is passed. An (trivial) example:
if (document.images) {
//..script doing some manipulation on images in the document
}
else {
//..opportunity to inform user or quit script etc as appropriate
In this example, the block of code after the 'if' statement will only be executed if the test returns true, i.e. the Document Object Model (DOM) of the browser has an object called document.images. This style of coding will ensure that code will only be executed if the required functionality is available and is widely considered to be best practice, not only in client side JavaScript coding but in programming in general.
Where a site is unable to modify their design to deliver content in a way that does not rely on JavaScript, one solution is to offer a text-only version of the site.
The ideal way of achieving this is, conceptually, to maintain a separation between the content of the page and the presentation. This is not always easy to achieve and will usually have to be clearly specified at the time the system is commissioned, and will require a very well thought out system architecture and workflow process. Where this is attained, it should be straightforward to reformat the page content into multiple versions, using XSLT transforms, server-side templates or similar, therefore making it easy to provided an alternative, universally accessible version of a page alongside.
Page parsers can be also be used with some success. These utilities take the page code, strip out images and other extraneous items and produce a text-only version of the site. The results depend very much on the nature of the input page, and testing will be necessary to make sure that pages are satisfactorily rendered if this method is chosen.
Not recommended is the approach of maintaining a separate, text-only version of the site. Once content is stored in two separate, disconnected locations it can be a matter of time before the two become unsynchronised, usually resulting in the text-only version becoming out-of-date from the site it is intended to mirror.
This section will be used to provide notes on the section, including details of any changes.
This section is available at <http://www.ukoln.ac.uk/nof/support/gpg/Marketing/>
Acknowledgements
This section was first published as part of the NOF-digi Technical Advisory Service Programme Manual.
This section is based on the information paper which was provided for the NOF-digitise programme which provided advice and guidance to projects funded by the NOF-digitise programme on publicising their Web sites.
The document refers to the NOF-digitise programme. However the advice provided in this section should still be appropriate for new projects.
Marketing a cultural heritage Web site is vital if you want to increase the number of users accessing it. To carry out successful marketing you need to have some sort of marketing plan which may involve determining the needs of your users and a strategy to execute your plan.
Within the context of digital cultural heritage development work which takes place as part of a funded programme, the objective sof the PR and marketing plan should be to:
All of this can be done using traditional methods, but given these are Web sites that are being promoted, electronic marketing is very important.
In any publicity materials it is important to add your URL to all slides, handouts. In fact, make sure your Web address is on everything your organisation produces, including headed notepaper, email signatures, paper bags.
You will need to clarify the target audienes for your project. For the NOF-diigitise programme, for example, the material was targeted particularly at users of public libraries through the Peoples Network (PN) [1] and schools through the National Grid for Learning (NGfL) [2].
However, you should also remember that the Internet knows no geographical boundaries and access to Web sites is not restricted.
The object of the marketing exercise is to identify target audiences and then best means of promoting the projects deleverable and component parts to these audiences, using traditional and electronic strategies. The product is the resources and services created in this programme.
Target audiences will include (not exhaustive):
It is important that a brand identify is created for funding programmes. For projects funded by the NOF-digise programme, for example, it was required that the NOF funded mark appeared on news releases relating to all projects being supported under the programme. The funded mark also appeared on appropriate Web pages, enabling sites to be readily identifiable as part of an overall project.
If publicity photos are created that include children the consensus is that consent forms are needed. An example consent form is given at [3] and [4].
Some brief but relevant advice from NGfL on using children's images on Web sites is given at [5].
You should aim to use traditional marketing tools along side electronic marketing. Traditional marketing would include:
You should establish what your selling points are and build up a database of good examples. Web address should be on everything you produce.
You may want to write articles about your project or interesting aspects of the project for relevant publications, either printed or online. You are always entitled to include a URL in your author details for pieces about your NOF-project or any other areas of work you are involved in.
One of the most positive ways your Web site URL will get distributed is by 'viral' marketing, or word of mouth. This will happen if your resources are accessible, interesting and user friendly and your site well designed.
Electronic Marketing would include:
There are a number of ways that you can use the Web itself as a marketing tool. Firstly, by encouraging other sites to link to you. This can be done by approaching relevant sites, swapping links and encouraging others to bookmark your site. During this process the value of a short and persistent URL becomes clear. It may also be useful to have a logo with a small piece of HTML available for people to copy and paste onto their site. After your site is released you should try to join industry/subject related hub sites, you may also be able to register it with a number of portals, such as the NGfL [2]. Towards the end of the programme a portal may be developed which will further enhance access to your resources.
Another way of disseminating information about your Web site's arrival is through use of electronic mailing lists. JISCMail [6] host a number of different mailing lists in various subject areas. When writing to mailing lists you should try to tailor your message for the target audience. Don't forget to advertise internally too, such as within your department, University or organisation.
One of the most important ways of increasing awareness of your site is through submission to search engines and directories. The best strategy is to manually submit your key pages to the major search engines (Google, Excite, HotBot, Lycos etc.). It is possible to use a submission application or Web service but these can be fairly unreliable. Finding a link from a search engine home page to the page where you add your URL can often be quite difficult. Search engines page designers frequently move the location of the link, possibly in order to make paying for submission an easier and more appealing prospect. The link may be listed as 'Add URL', 'Add your Web site', 'List with us' or another. When you find the page for free URL submission you may need to give extra details, such as your email and a category for the page you are submitting. For further information on the use of search engines have a look at the Search Engine Watch Web site [7]. This form of promotion should really take place before your launch and may take some time (over a month).
In order to be successfully indexed by the search engine software there are certain areas of Web site that need to be considered.
You should give some thought to the keywords on your Web page. Search engine indexers pick up on two different types of keywords: the meta tags held in the HTML markup of your page and the keywords mentioned in the content of your page.
Metadata in the form of meta tags (information about a Web resource, such as the author, keywords, brief description, etc.) is often used by search engines when indexing and is sometimes provided as a description on a search results page. An example of a few of the meta tags available for use on a Web site is given below:
<meta name="keywords" content="SCRAN, scotland, scottish, scot, gael, scran, alba, past, history, image,
identity, scran, ethnography, archaeology, scran, education, school, college, university, museum, gallery">
<meta name="date" content="May, 2001">
<meta name="dc.title" content="SCRAN Web Site">
As you can see from the examples above basic meta tags can be used or information can provided in Dublin Core. It may also be useful to provide alternative spellings and language versions of keywords if relevant.
You should make sure that you include a well-worded title in the <head> block. This will definitely be indexed and is weighted heavily in the results, in general: title words are ranked more relevant than free-text words.
However keywords used in your content are also important. If your site provides access to resources on the River Avon is this mentioned on your page? Are other keywords, such as the counties the river is in, mentioned? How are your keywords positioned? Is there a lists of links, tables or frames that move the valuable keywords further down the page? Make sure that all your graphics have alt tags as some search engines can use image alt tags for indexing. Note that most search engines have technologies that look for spamming so avoid excessive usage of a particular word.
Much relevancy ranking (where your site appears on a search results page) is done by the location and frequency (of keywords) method. Other search engines use the popularity method. This looks at the number of links to a site and the importance of those links, certain links to sites will be weighted. For example if the BBC links to your site this will count for more than a friend's home page. Reviewed sites that are found to be of good quality by directories will also appear higher up a search results page. Unfortunately more recently the most consistent way that you can guarantee that your Web site appears at the top of the search results is by paying.
After marketing your Web site you could check the popularity of your page using Linkpopularity.com which measures how many other sites link to yours. It is also possible to find out if you have been referenced by a search engine. For further information see the article on "Promoting Your Project Web Site" in Exploit Interactive [8]. To check that search engine indexers are visiting your site you can also check the server logs files to see if any robots (like googlebot) have visited your site yet.
Some search engines will have difficulties indexing your page if you use frames, splash screens, javascript, databases or have strange characters (~,*,?) in your URL. Try not to use frames and always offer an HTML alternative to proprietary file formats, such as Flash.
Marketing your project Web site should be an ongoing process. If your site is well designed and functional people will add it to their bookmarks; but reminders about your useful site will not go amiss. Keep people informed of interesting additions to the site, possibly by creating a database of interested users and emailing them whenever substantial changes are made.
Make sure that your Web site gets noticed by combining online and real world marketing and continually mentioning your resources. You need to consistently get more people to your site because 'magnetic marketing' is the best marketing there is. The more people who use your site, the more useful it will become.
Monitor your Web site's usage both qualitatively and quantitatively and adapt your site in line with this feedback. Monitor, evaluate, elevate.
The funding body for your cultural hritage project may be able to provide various support services for your project. This can include the following:
http://www.safety.ngfl.gov.uk/schools/document.php3?D=d27#1
This section will be used to provide notes on the section, including details of any changes.
This section is available at <http://www.ukoln.ac.uk/nof/support/gpg/IncomeGeneration/>
Acknowledgements
Commissioned from Harvard Consultancy Services Ltd by UKOLN on behalf of NOF in association with the People's Network.
This section is based on the information paper which was provided for the NOF-digitise programme which provided advice and guidance to projects funded by the NOF-digitise programme on income generation. However the advice provided in this section should still be appropriate for new projects.
Projects funded through cultural heritage programmes such as the nof-digitise programme will normally be expected to remain sustainable for at least three years beyond the lifetime of funding. Therefore projects must give consideration to ways of establishing a sustainable basis for development. Although it is a requirement that content funded through the programme must be made available free to users at the point of access, there are a number of ways in which this content can be used to generate income whilst still fulfilling this requirement.
This paper is intended to be used as a means of focussing on the issues associated with income generation and sustainability for digitisation projects. The advice given is for guidance and should not be seen as the only solution. It is recommended that each project should be reviewed on its own merits, using these guidelines as a starting point. The paper covers the following range of income generating options available and considers their advantages and disadvantages:
This paper has been written assuming that most projects will be working with a range of digitised content, which includes text, image, video and audio. However, as the most mature area in this sector for revenue generation is that for the digital image, we have focussed more in this area when giving examples.
It is also important to appreciate the difference between sustainability and income generation. The former does not necessarily rely on the latter. For example, an institution could decide that its digital library is a core service and should be maintained and developed from the central budget - particularly as many institutions' customers are coming to expect such digital services.
Finally, a few words on intellectual property rights and copyright. Before considering any of the income generating options, it is important that each institution understand the rights position regarding their collections. Each consortium must tackle this issue in its own way and come to its own agreement with all partners and suppliers of content/images. If there is any doubt about the rights position for a consortium's collection it is strongly recommended that it is not used in any way to generate revenue.
A useful book on rights and related issues, Guide to Copyright for Museums and Galleries, has been produced by Peter Wienand, Anna Booy and Robin Fry, in conjunction with the Museums Copyright Group [1].
The copyright consultant Sandy Norman has published a number of titles covering copyright across a range of libraries in conjunction with the Library Association. More information is available from the Library Association Web site [2].
An excellent paper by the Networked Services Policy Taskgroup covering copyright and the networked environment is available from the EARL Web site [3].
In addition, the Visual Arts Data Service (VADS) [4] has useful guidelines on good practice for digitisation projects. Digital content can also be deposited with VADS, through both voluntary submissions and strategic alliances. This benefits content providers by providing a long-term archival home for the materials in which they have invested time, effort and money. Providers also benefit from VADS promoting the digital collections and the organisations who created them. There is a licence agreement online [5] that may be useful, although it does not deal with the commercial sale of content.
There are a number of ways in which income can be generated directly from digitised material. Before looking at the specific mechanisms, it is important to understand the target markets available. Generally speaking, there are three main target markets:
This is a notoriously difficult sector to generate revenue from, especially when using the Internet as a channel to market. It is estimated that as at August 2000, there were over 17.5 million UK users of the Internet, representing almost one fifth of the population [6]. In the short to medium term, this is expected to continue growing at the rate of around 11,000 new users per day [6]. This rate of explosive growth has been greater than the take-up of almost any other technology platform, including radio, TV and telephone.
Usage started to accelerate in 1995, with the largest increases during 1999-2000. As such, it is still very much an immature medium through which to market (As an example, commercial direct telephone services - such as telephone banking and insurance services - only started maturing in the 1990s, 10 or so years after they first came to market and over 115 years after the phone was invented!) It is not expected that the Internet will take anything like this long to mature, but the reality is that it is still a very young medium, particularly for selling.
New business models are still developing and predicting successful models is not easy. Few could have predicted, for example, the success of online auction services, such ebay [7] and qxl [8].
The public are also very nervous of using online commerce, especially when using credit cards. Recent high-profile security scares from major organisations' Web sites have done little to help this.
It should be remembered also that a large percentage of the population still currently do not have Internet access or the knowledge of how to use it and many do not have credit cards. The demographics of the Internet consumer-base are not that of a typical retail or mail order business opportunity. This needs to be considered when reviewing potential business opportunities. However, the Government is committed to providing universal Internet access, and all UK public libraries will be offering public access to the Internet by 2002.
Typical revenue levels generated from sales directly to the public are very much lower than those for commercial sales. Experience of organisations that deliver digital content is that a typical content sale to the public will result in revenue of around £5 - £15 per item. To get a sufficient return on investment, selling in this area may require a high volume of sales per item of content.
Some examples of cultural institutions that sell content online include: The British Museum [9], The Natural History Museum [10], SCRAN [11], and HPAC [12].
Content sales are not the sole source of income into this sector, as there will be opportunities to generate additional revenue from other sources, such as advertising, affiliate programs and sponsorship. These are covered in more detail later in this section.
Finally, any business opportunities in this area will need to be supported by a marketing strategy and related resource and budget.
What does this mean to organisations planning to sell their digital collections?
Currently, direct selling to the public using the Internet is risky and revenue levels are likely to be fairly low. Any revenue plan based primarily around public sales needs to be realistic; detailed cash-flow forecasts should be prepared showing likely sales and revenue figures. There may be value in providing a public-facing sales opportunity as part of a wider offering, as long as it is not the primary source of income.
This sector presents the opportunity to generate the most revenue from the sale of digitised assets. However, it is not an easy route and is one that needs to be considered very carefully.
Some organisations can certainly generate income from the sale of content in this sector. For example many of the leading national museums and cultural institutions have commercial photo libraries that generate substantial revenues including The British Museum [9], Natural History Museum [10], SCRAN [11] and HPAC [12].
To illustrate the potential for business to business content sales in this sector, one cultural organisation, having similar content to a library or museum, sells conventional (non-digital) copies of its photos and transparencies. It does not market the images and relies on word of mouth. In 1998, they generated around £125,000 from the sale of around 5,000 images - mainly to publishers and media organisations for use as book covers, pictures for magazines and advertising. Although this is not a unique example it should be said that this particular organisation has excellent staff and some good collections that are in demand, however it proves a point that revenue can be generated from cultural content.
Few cultural institutions currently have operational business to business sites on the Web. Examples of institutions having their own internal commercial libraries include (note that these are links to the main site and not to a specific commercial service): The Victoria & Albert Museum [13], Science Museum [14], Imperial War Museum [15], Royal Geographical Society [16], Royal Photographic Society [17] and The British Library [18].
However, be very careful when trying to assess the value of your content, as many cultural institutions believe that they are sitting on a gold-mine and this is not always the case. It is all about the real value and saleability of content. Marketing is an important consideration too as the institution highlighted in the illustration above has a reputation and contacts built up over a long period of time that many institutions will not have.
ICT can provide benefits in automating many of the processes associated with meeting customer demand for commercial product.
However, there are several major issues associated with commercial content sales:
What does this mean to organisations planning to sell their digital collections?
To exploit these commercial opportunities institutions need to become, in effect, a commercial content library.
This may not be feasible or desirable for many. However, there are several choices available that could overcome this:
Content sales are not the sole source of income into this sector, as there will be opportunities to generate additional revenue from other sources, such as advertising, affiliate programs and sponsorship which are covered in more detail later in this paper.
Again, it is recommended that detailed and realistic revenue and cash-flow forecasts are created if this is a chosen option.
These sectors provide further opportunities to generate subscription or license revenue. This sector has the demand as well as the infrastructure (in most cases) to use such a service. However, funds to date have been limited and it is unlikely that cultural institutions or education establishments would commit to funding multiple services.
The guidance from the DfEE on the development of the National Grid for Learning in 2000/2001 requires 15% of budgets to be spent on 'developing and providing content' [19]. This is part of a long term strategy to encourage the continuing development of an educational software industry that will provide high quality resources. Schools, LEAs and Regional Broadband Consortia may therefore provide both a market, and also a mutually beneficial source of partnerships. The Regional Broadband Consortia are, in some cases, developing their own digital learning resources, and it may be possible to build long term partnerships which will include the hosting and delivery of digital learning resources [20]. Becta [50] have developed a Curriculum Software Initiative, giving information to support developers of educational software and digital learning resources.
It is this sector that is likely to provide more two-way transactions between projects and third parties - cultural and educational organisations probably offer the greatest opportunities for projects and consortia to work collaboratively with them to form longer-term partnerships to develop and deliver Web services.
A very successful and relevant model to consider is that used by SCRAN - the Scottish Cultural Resource Access Network [11]. SCRAN is a searchable resource base of history and culture with photos, objects, artwork, movies and audio. SCRAN has negotiated licensing arrangements through central bodies, such as JISC (the Joint Information Systems Committee of the Higher and Further Education Funding Councils) and Local Education Authorities and offers its full service to schools, further and higher education establishments for a license fee, ranging from £60 to £2000 per annum, depending on the type and size of institution. The five-year contract they have negotiated with JISC pays for access from every further and higher education authority. Two thousand schools also have access.
However, the SCRAN model is not just about sustainability, it also covers rights management, IPR issues and how contributor/providers are dealt with. SCRAN's licensing model ensures that the new digitised object remains the Intellectual Property of the owner of the original, while securing for SCRAN a perpetual, worldwide, non-exclusive licence for its educational use.
SCRAN's approach to rights management includes sophisticated authentication and authorisation, as well as a dynamic watermarking and fingerprinting system, which invisibly encodes into every copy image downloaded, a unique audit trail including the copyright status of the object, who downloaded it, when and on which machine. So downloads of high quality content can be restricted to users in licensed institutions, such as public libraries, and they have the means to police licensed users to discourage unauthorised use of SCRAN content.
What does this mean to organisations planning to sell their digital collections?
To market and sell to potential users effectively in this sector a collaborative approach is recommended. Approaches to schools, further and higher education establishments are best made centrally, through Local Education Authorities and the Regional Broadband Consortia, for example.
Another issue is ensuring that potential users in the education sector are aware of the resources that are available and understand how they might use them to meet their own requirements - in a classroom situation - for example. Projects may consider it worth while to address these issues. This may take the form of simple awareness training, but in some cases could extend to providing training resources, such as manuals or guidelines on how to use the service most effectively.
Essentially there are two main types of income generation for digitised assets on the Internet:
This includes online sales, royalty payments, license fees and subscriptions from the sale or provision of access to the digitised assets.
Sale of content online
This is where the rights to use content is sold online.
Users should be given the opportunity to search, browse and download content. It is recommended that wherever possible, processes connected with the display, download and billing for content should be automated, to minimise impact upon the institutions concerned.
It is important that consideration is given to the management and control of licensing and rights and that appropriate steps are taken to prevent abuse of copyright. This could include a rights management database, encryption, file locking and watermarking.
There are many providers in the market of digital library rights management systems and services. For more information, it is suggested that the mda [21] could be a good starting point as they have a register of technology providers active in the culture sector. Also providers outside of this sector should be considered as digital library and rights management tools are very mature in sectors such as publishing and medicine.
Issues surrounding copyright and licensing are outside of the scope of this paper however further information on IPRs can be found in the nof-digitise FAQs section [22].
To give a benchmark of likely image sales, commercial photo libraries work on the basis that 5%-10% of their collections will sell every year. The British Association of Picture Libraries and Agencies (BAPLA) [23] publishes a recommended scale of fees for image sales. The Tate Gallery has also published its scale of charges on the Web [24].
The advantage of this revenue generating approach is that if an institution has digital assets that are popular, the service can actively promote these to stimulate maximum possible revenue. However, there is a risk in developing a service focusing on generating revenue from the most popular digital assets, as it could 'skew' the service or divert the project from its original aim. Also, more complex processes and systems, especially billing, need to be put in place and the project may need to ensure that it makes a high volume of images available.
Subscription-based services
This is where a subscription fee is charged, allowing access to a library of images. Some sites operate on a multi-tier subscription basis, where basic information is given for free and more detailed information is accessible for a one-off fee or for a regular subscription. The best approach depends on the type of content and site structure. Projects must also be aware that the conditions of funding may require content to be made available free to users at the point of access.
As an example of a subscription-type service, see the Fathom Web site [25], which provides lectures, interviews, online course and trails, for example, from their member institutions - which include The Natural History Museum, Cambridge University Press, the University of Chicago and the New York Public Library.
The advantage of a subscription-based service approach is that the billing process and systems can be simplified, as only a regular subscription is required. It also allows a more regular cash-flow. However, there is a limit to the revenue levels that can be generated (limited by the number of users multiplied by the subscription fee). There is also a need for more behind the scenes sophistication with the underlying technology.
Licensing content to third parties
Another option for the generation of revenue from digital content is through the sale of licenses to third parties, such as commercial digital libraries or software companies producing, for example, educational software or games.
This would typically involve the agreement of a licensing arrangement. The third party would undertake the marketing and distribution of content, and in the case of a software company, repackaging of the digital content for use in a specific commercial product. In exchange, the project would receive a percentage of the sales revenue or a fixed fee for allowing the commercial exploitation of their content.
The leading organisations in this sector for digital images are Corbis [26],Hulton Getty [27] and Bridgeman [28]. For digital textual content see: Lexis-Nexis [29], Reuters [30], Dialog Corporation [31], Newsedge [32] or Ananova [33].
The advantages of this approach are:
The disadvantages of this approach are:
This includes advertising, affiliate programs, sponsorship and merchandising.
Advertising
Looking at general sites on the Internet, advertising is a principal source of revenue for many commercial Web sites. Indeed, some sites generate sufficient revenue to cover all of their running costs and make a substantial profit. This is particularly true of portal sites such as MSN [34], Yahoo [35] and Virgin.Net [36], which provide a range of services and links.
Advertising can take a number of forms. Banner adverts for example, are typically 468 x 60 pixels (16 x 2cm) 72 pixels per inch (ppi) and run across the page and appear on the menu/home pages of Web sites. Brian Kelly's paper Advertising on the network [37], although aimed at options for higher education institutions provides a useful summary.
If you regularly e-mail users, adverts could be incorporated into these messages - offering more revenue potential. This can be quite an effective marketing tool, especially if you hold user information and can target specific user groups with specific mails/adverts. There are data protection and data security issues to consider here of course, and it necessitates user-registration (which may put some people off from using your service). Also, if you are visibly associated with an advertiser or sponsor, users may be suspicious that you may be holding data about them for purposes other than in the context of your project.
The advantage of using advertising to generate revenue is that reasonable revenue generation levels may result.
The disadvantage is that advertising can cheapen a site if done badly, particularly if not relevant or contemporary with the subject matter, so approach with caution. Also, for advertising to be effective, you have to have a defined audience profile which the advertiser wishes to address and you have to be able to quantify the 'throughput' or number of visits to your site - there are Audit Bureau of Circulation [51] approved ways of counting the throughput - and you need to be able to tell the advertiser just exactly what the make-up of your visitor segments are.
Affiliate programs
Another important stream of revenue is through affiliate programs. This is where a site will feature a product or service and provide links to a vendor to supply it. The vendor will pay commission for any products sold. The most common examples are books and CDs - all of the major online bookshops and CD stores offer this sort of service.
The way this works is that after registering with the store, you will have a unique code and access to promotional imagery that you can use on your site. You set up a link to the affiliate site featuring your code and any time someone clicks through, the vendor registers that it has come from your site and credits your account if a purchase follows.
There are several options available, if you set up a simple link from a Web site to the home-page of the book or CD store, most vendors will pay a commission of around 5% on any subsequent purchase made. If you make a link from your Web site to a specific book/CD and this is subsequently purchased, typical commissions of up to 15% can be paid.
For examples of affiliate programs, see Amazon UK [38], WH Smith [39] or Internet Bookshop [40].
This could be an important source of revenue for sites and can be targeted more specifically. For example, if a project is featuring a specific period in history or type of collection/information, it could be very relevant to provide links from those pages to a handful of books which provide more information on the subject.
There are other affiliate programs, which will pay if people click through to (usually) a shopping portal or search engine. The revenue levels per click are much lower, for example $0.01-$0.02 per click (most originate in the US) and they can be another potential source of income. For examples, see Goto.com [41] and AskJeeves [42].
The advantages of the affiliate-based approach are that it is relatively simple to set up and can generate a steady stream of income. From a user's perspective, they will also have access to a broader range of information on the subject matter concerned. A good way to maximise the effectiveness of a range of affiliate programmes and other income generation opportunities is to create a portal, a option which is discussed later in this paper.
The disadvantages are that it needs more work to set it up. A considerable amount of research will be necessary to establish the most appropriate products and vendors. Also by engaging affiliate programs, you may be encouraging and creating ways for people to leave your site, rather than stay. Care needs to be taken in page design and layout to prevent or minimise this and to make sure that programs are presented in a way which does not detract from your site.
Sponsorship
Sponsorship is another form of revenue, although it is more difficult to obtain and needs time and patience in developing a sustainable strategy. This would normally manifest itself as a payment to the organisation or consortium, in exchange for which, sponsoring organisations would receive a range of benefits such as having their logo and/or adverts featured on the site, a guarantee of a certain customer 'reach' as the service will be available through a given number of outlets, etc. As an example, in some circumstances it may be appropriate to charge Web site designers and/or suppliers to feature their name in the text 'pages designed/made by xyz' or 'powered by abc company' that is included on every page of the project Web site. Think of your pages as your 'virtual real estate', looking at every inch of screen-space as a saleable commodity.
Although this approach is one that can generate reasonable revenue levels it can be difficult to find sponsorship and its use could potentially cheapen a service if a sponsor insists on being featured heavily across a site.
Shops
There are also opportunities to offer online shopping and to sell related products through the project Web site. However, there is likely to be a significant cost associated with this as, for example, a display, billing and shipping system will be required to manage transactions. Although it is unlikely to generate significant revenue streams, this option could be useful as part of a broader revenue package. Again, a collective approach is recommend for enabling this and to put the infrastructure in place.
For examples of an online shops, see The Tate [43], The Smithsonian Institute [44] or The Victoria and Albert Museum shop [45].
The advantages of this approach are that it is relatively straightforward to establish a shop and many institutions will already have merchandising and products which could be sold, although a key issue here is fulfilling and distributing orders - areas which have proved problematic for a number of even well-established retailers . It is important, of course, that such e-commerce opportunities are sensibly related to the project and thus provide a viable business case to justify time and resources invested in their development.
Portals
In an earlier section, reference was made to portals - gateways or one-stop sites for information, links, products and services relating to a specific subject or group of individuals. One of the limiting factors for many commercial portals is that they do not have sufficient content themselves and have to strike deals with a number of content providers to provide a viable service. A portal can successfully combine many of the elements mentioned in this paper (advertising, shops, affiliate programs, sale of content and subscription services) into one focused service.
This is one area where cultural heritage applicants have an advantage, in that they are rich in content. Therefore one potential route for applicants - whether consortia, groups of consortia or stand-only partnerships - is to consider the development of a portal. To better illustrate this multi-faceted option, an example is given below for a fictional organisation - The Museums, Archives and Libraries (MALs) of Sandfordshire:
Sandfordshire MALs are engaged in a digitisation program and have generated a large quantity of digital images, text, database records and digital multimedia assets. They have created a Web presence and because of their geographic location, have developed it into a portal aimed at people living in or with an interest in the region of Sandfordshire.
Visitors to the portal enter via an attractive home page. This presents many different options:
This example helps illustrate how a number of methods of revenue generation can be combined into a single service. However, it is important to note that this approach almost certainly will be beyond the reach of individual projects and would only really work if a collaborative approach is taken.
There are currently few examples of these portals in the non-commercial sectors (although this is expected to change). Examples of portals in different sectors include: Portsmouth.web - a portal covering Portsmouth and all it has to offer [46], Microsoft's flagship site [47], which has advertising, links, shops, affiliate programs and content derived from third party sources (see below) UK Plus, [48] - UK-based search engine and portal, and Cumbria - The Lake District [49], which provides tourist information and activities related to the area.
The key is to ensure that there are sufficient levels of visitors to the site and that 'stickiness' is encouraged - this is to ensure that visitors stay longer on the site and keep returning in the future. One effective way of encouraging this is to offer a broad range of additional information and links.
Sources of potential additional content (most of which is free) include:
| Type | Providers |
|---|---|
| News | Evening Standard (have a good site to which links could be made): http://www.thisislondon.co.uk |
| ITN: http://www.itn.co.uk/ | |
| BBC: http://www.bbc.co.uk/news/ | |
| Weather | The Met Office (have a local weather page to which links could be made): http://www.met-office.gov.uk/ |
| Yahoo have local weather pages to which links can be made: http://uk.weather.yahoo.com/ | |
| Multimap: http://uk2.multimap.com/ | |
| Places of interest | Official site of the UK tourist board: http://www.visitbritain.com/ could be a useful starting point for identifying attractions. |
| Travel | Railtrack: http://www.railtrack.co.uk/ for train timetables |
| Link to BAA site for airports (includes latest flight times): http://www.baa.co.uk/ | |
| TrafficMaster provides information showing delays, road-works and accidents on major UK roads: http://www.trafficmaster-online.com/ | |
| Euroshell offers a road route planning service: http://www.euroshell.com/UKD/EN/index.asp | |
| London Transport for tube and bus information: http://www.londontransport.co.uk/rt_home.shtml | |
| Entertainment | Scoot provides a free utility that can be deployed on a site to allow searching against their database for local restaurants, cinemas, places of interest, etc.: http://www.scoot.co.uk/ |
| Yell (Yellow pages on-line) provide a
similar free service, but also provide cinema listings: http://www.yell.co.uk/ |
|
| Time Out: http://www.timeout.co.uk/provides useful entertainment links | |
| NME run an online gig guide for concerts and gigs: http://www.nme.co.uk/ | |
| Miscellaneous | Mapping information: Mapquest, Global Insight and streetmap.co.uk provide free on-line mapping (streetmap.co.uk goes down to street level): http://www.mapquest.com/, http://www.globalinsight.com/, http://www.streetmap.co.uk/ |
| Air quality: http://www.aeat.co.uk/netcen/airqual/forecast/ provides localised air quality information |
This information is by no means exhaustive, but does give examples of types of services that could be made available.
When considering ways to sustain projects beyond the initial funding period, it is probably worth considering multiple income streams to generate the maximum possible revenue.
Each project should look at its own individual business needs when developing its business plan and business requirements specification, an approach that is standard practice for IT projects generally. The business plan should include revenue generation and cash-flow forecasts.
It is important that potential solutions, especially IT solutions, should not be considered until this process has been undertaken. Each solution can then be matched against the needs and it may be that one or more of the solutions outlined above are considered appropriate.
Cash-flow and revenue generation forecasts should be realistic, tested wherever possible upon the market and take into account each of the revenue streams.
Again, concerning IPR, before considering any of the income generating options, it is important that each institution understand the rights position regarding the material they are going to use. Each consortium must tackle this issue in its own way and come to its own agreement with all partners and suppliers of content. It is strongly advised that a licensing and rights management system be put in place. Some content might have been created with the permission of third party rights holders, and all of it will be created with public money. We all have a duty of care to protect this. Without an appropriate rights management system, anything put online will be effectively in the public domain and potentially used for the profit of others. Even if a project has established the right to exploit its content, entering into commercial activities may prejudice (future) relationships with content provides who may be reluctant to provide content (on favourable terms) if it is going to be exploited for profit. The New Opportunities Fund expects projects to demonstrate that they have understood this issue and will require successful applicants to indemnify the Fund against any future action over ownership or mis-use of content.
In conclusion then, although content must be provided free at the point of use, there is scope to generate income through exploiting content and services imaginatively, provided that adequate projection is afforded to the IPRs of the content and that a sound business case can be established.