 Components
Components Contents of this part of OAI for Beginners, the Open Archives Forum online tutorial
Contents of this part of OAI for Beginners, the Open Archives Forum online tutorial
| General: first questions | Top |
Before implementing OAI-PMH, you must consider a number of organisational decisions that will affect your implementation.
Data Provider
Service Provider
Data Provider & Service Provider
| General: metadata formats | Top |
As has already been noted, unqualified Dublin Core (DC) is the metadata format required for basic interoperability. However, within some subject areas and communities other metadata specifications may be required. It may be necessary to describe resources with complex structures in a specialised way, as is the case, for example, in the archival community. Whichever metadata format is chosen, agreement between Data Providers and Service Providers on its use must be reached, and the definition of an XML schema must be made publicly available for validation. The procedure for defining and declaring an XML schema is described in the final part of this tutorial. An OAI DC XML schema has already been made available. In addition, you may find another XML schema already in place that meets your requirements.
NOTE: At the time of preparation of this tutorial, a discussion had been initiated in the OAI community that may result in the status of unqualified DC from "mandatory" to "recommended". See the OAI official site for the latest news on this issue.
| General: sets | Top |
Support for the Set construct is optional within OAI. However, sets have been found to be particularly useful in supporting the provision of specialised services based on selectively harvested metadata. Sets define groups of metadata within a repository, and metadata may be grouped by any characteristic that provides sensible partitioning for selective harvesting. Examples of sets that have been defined within organisations and communities include those based on journal or series titles, on subject classifications or categories, on collections (e.g. topic or discipline based), on resource types and on authors of works. Individual metadata records may be included in one set, more than one set, or no sets at all. A repository may support Sets based on as many different defined groupings as it finds useful.
OAI sets may be hierarchical. In this case, members of child sets are harvested as part of their parent set. The meaning of sets or of set hierarchies is not defined in the OAI protocol. The definition of a set or set hierarchy may be internal to a repository, but is often based on an agreement between Data Providers or between Data Providers and Service Providers.
| General: organisational structure | Top |
An aggregator may set between Service Providers and some Data Providers. Where this is the case, Service Providers must be aware of the identity of the Data Providers that have been aggregated. This will enable Service Providers to avoid duplication that would arise from harvesting both the aggregator and the original Data Providers.
Service Providers that provide subject gateways will be able to implement selective harvesting if corresponding sets have been defined and implemented by the Data Providers they harvest.
| General: tools for implementing OAI-PMH | Top |
While you may want to develop your own OAI software, this is by no means necessary, as a number of software tools are available, many of them under open source license (or similar) terms. The OAI maintains a list of OAI software tools (http://www.openarchives.org/tools/) with links for the sources of the tools. At time of preparation of this tutorial, the list included Repository Explorer for interactive exploration and validation of OAI repositories, as well as tools with specific support for OAI-PMH, such as GNU EPrints (eprints.org) from Southampton University, DSpace from HP Labs and MIT Libraries, and the PHP OAI Data Provider from Oldenburg University. The tools you choose will depend on such considerations as the type of repository or service you are implementing and the technical skills available to you in-house. For example, if you are setting up an e-print archive then you may want to consider using the GNU EPrints software package, while DSpace provides a digital asset management framework that includes preservation considerations, and the advantage offered by PHP OAI Data Provider is support for on-the-fly output compression aiming at a significant reduction in data transfer load. A number of general software tools relating to XML and Unicode that may be useful for implementing OAI-conformant data and service providers are also listed by OAI.
In addition, about thirty OAI-related tools are described in the OA-Forum Final Report on Technical Issues (download from http://www.oaforum.org/documents/). This report also includes a detailed comparison of GNU EPrints and DSpace.
| Data Provider: prerequisites | Top |
These are the things you must, should, or may have in place in order to implement OAI-PMH as a Data Provider:
| Data Provider: components and architecture | Top |
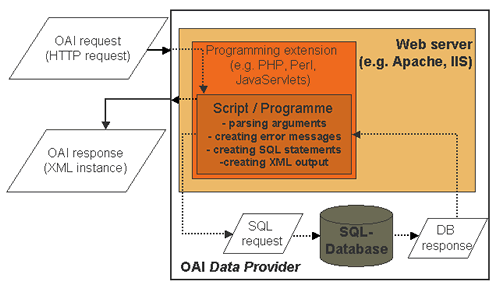
Components
Argument Parser validates OAI requests.
Error Generator creates XML responses with encoded error messages.
Database Query / Local Metadata Extraction retrieves metadata from the repository, according to the required metadata format.
XML Generator / Response Creation creates XML responses with encoded metadata information.
Flow Control realises incomplete list sequences for 'larger' repositories. It uses resumption token as the control mechanism.
This diagram illustrates an example architecture for a Data Provider.
| Data Provider: example flow chart | Top |
This diagram charts the flow from receiving an HTTP request to issuing an XML response to the request. It is an example showing the processing of one particular request type.
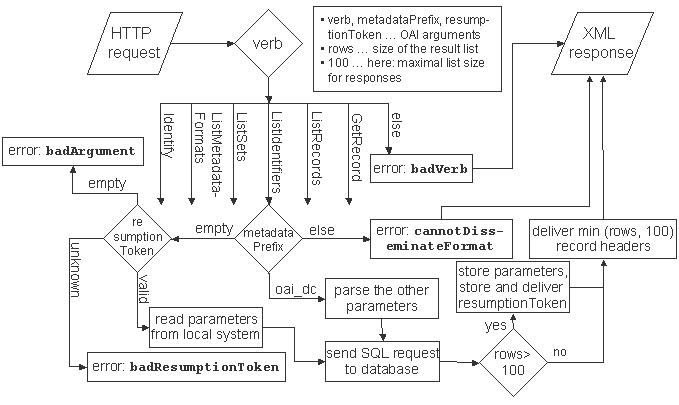
This is a flow chart for the processing of an example request within the Data Provider. In general, the diamonds represent conditions, and within the rectangles actions are described informally. When receiving an OAI request the Data Provider has to parse the query and firstly has to decide which of the six valid request types is issued or if the request type is illegal. The latter case (verb parameter has a nonstandard value) results in an error message to the Service Provider (badVerb). In case the issued request type is ListIdentifers the next parameter the parser has to check is metadataPrefix because this argument is mandatory for the request type ListIdentifiers.
If the parameter has not been provided the only possibility for the request to be valid is to have a resumptionToken parameter which has to be known to the Data Provider. In this case the Data Provider reads the locally stored parameters representing the arguments of the original request and cursor information indicating how many identifiers have already been delivered to the Service Provider. If the resumptionToken argument is emtpy as well or has an unkown value error messages have to be generated.
The only valid value for the metadataPrefix parameter is oai_dc because the example Data Provider assumed here can only deliver metadata sets in the unqualified Dublin Core schema. If this is the case the other optional parameters have to be parsed, which in the chart has been described informally for reasons of simplicity. The possible parameters are from, until and set. In this process, error messages have to be issued if the parameters have illegal values or if the query contains other parameters not allowed for this request type.
Subsequently, the given parameters received by the query or - in case of a resumed resumptionToken query - read from the local system have to be assembled to an SQL query which then has to be issued to the database. If this results in more than 100 records (100 in the example is the maximum number of delivered indentifiers at once) the Data Provider has to generate a new resumptionToken and to store it locally together with the query parameters and the cursor information. The resumptionToken has to be included in the XML response to the service provider as well. Of course, the XML response also contains the identifiers returned by the database.
| Data Provider: resumption token | Top |
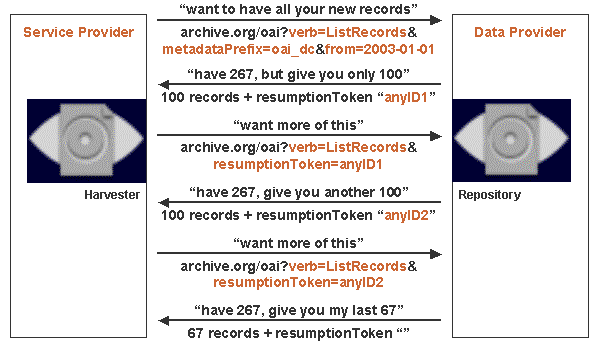 This diagram illustrates the use of Resumption Token in controlling the flow of the dialogue between a Service Provider and Data Provider.
This diagram illustrates the use of Resumption Token in controlling the flow of the dialogue between a Service Provider and Data Provider.
Resumption Token should be implemented for handling "large" lists. It is initiated by Data Provider, and is used to store parameters (such as set or from) and the number of already delivered records.
The Resumption Token may contain the following optional XML elements giving the Service Provider hints on the total length of the list to be expected:
The protocol requires the ability of Data Providers to answer correctly if the most recent Resumption Token of a query is reissued. This feature allows Service Providers to recover from network errors without having to reissue the complete list from the beginning.
| Data Provider: resumption token and database changes | Top |
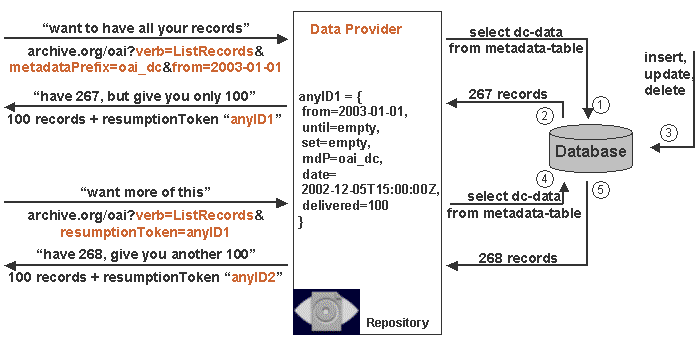
There is a problem regarding the implementation of Resumption Token if the database changes during the course of a harvesting operation, as illustrated in the diagram below. The chart shows the possible case that between the first request and the resumed request the content of the Data Provider's database has been changed. If the Data Provider only remembers the the total number of already delivered records to the request the combination of the resumed lists may have inconsistencies.
There are two possible solutions. One solution is to duplicate data in a "request table". The other is to store the date of first request with the other parameters and use it like additional until argument.
| Data Provider: data representation | Top |
Data Providers should use the following recommended data representations.
Data Providers should use one separate XML element for each entity in the case of multiple values for a data element, as in the following examples.
| Data Provider: compression | Top |
Compression is a method to reduce traffic and enhance performance. It is optional for both Data Providers and Service Providers. Compression is handled on the HTTP level.
Harvesters may include an Accept-Encoding header in their requests for specifying compression preferences. Harvesters without an Accept-Encoding header always receive uncompressed data.
Repositories must support HTTP identity encoding. Repositories should specify supported encodings by including compression elements in the identify response.
| Data Provider: testing | Top |
 When
you think your implementation is ready to run, create some OAI-PMH requests,
send them to your OAI interface and check the results.
When
you think your implementation is ready to run, create some OAI-PMH requests,
send them to your OAI interface and check the results.
You can use the Repository Explorer at Vermont University to do this (http://oai.dlib.vt.edu/cgi-bin/Explorer/oai2.0/testoai/) by browsing through your repository. Repository Explorer is an interactive, automatic compliance tester. It allows you to provide arguments via HTML forms. The responses are validated as conformant with OAI-PMH.
You can check your repository against each of the OAI-PMH verbs in turn, setting parameters where required for date ranges, metadataPrefix, identifier, set, and resumption token. Thus, all aspects of the protocol can be tested, and the results of queries are checked for conformance with the expected syntax.
Repository Explorer supports the following languages: Chinese, English, Spanish, French, German, Korean and Portuguese. You can choose how the results are displayed, either as parsed or raw XML, or both. There is also some provision for schema validation.
| Data Provider: registration | Top |
Once you have assured yourself your implementation is working as expected, you can register it at the official registration site for Data Providers. (http://www.openarchives.org/data/registerasprovider.html)
The registration requires that you provide the base URL for your Data Provider implementation. OAI then performs an extensive conformance test (including tests for error conditions, among others), and information on incorrect behaviour (if any) that was found will be notified to you. In the case of conformance, your Data Provider implementation will be added to the official list. OAI performs regular checks on registered Data Providers to confirm that all is well.
| Service Provider: prerequisites | Top |
There are three technical infrastructure prerequisites for implementing an OAI-PMH Service Provider that will harvest metadata from Data Providers via OAI-PMH:
| Service Provider: components and architecture | Top |
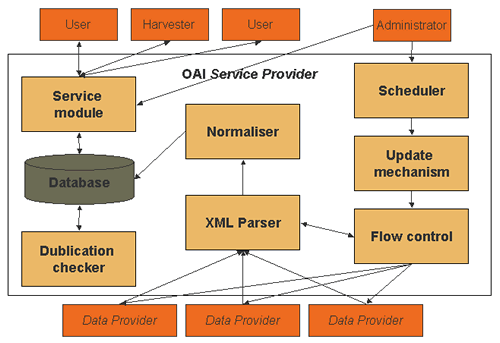 Archive
management involves the selection of repositories to be harvested. Entries
to your list of repositories to be harvested may be made manually or you can
automatically add or remove archives using the official registry.
Archive
management involves the selection of repositories to be harvested. Entries
to your list of repositories to be harvested may be made manually or you can
automatically add or remove archives using the official registry.
Request Component creates HTTP requests and sends them to OAI repositories (Data Provider). It demands metadata using the allowed verbs of the OAI-PMH. It may do selective harvesting using the set parameter.
Scheduler realises timed and regular retrieval of the associated archives. The simplest case would be manual initiation of the jobs, but this can be automated, e.g., as a cron job.
Flow Control is implemented via resumption token, partitioning of the result list into incomplete sections with a new request to retrieve more results. An HTTP error 503 (service not available) allows analysis of the response to extract a “retry-after” period.
Update Mechanism realises the consolidation of metadata which have been harvested earlier (merge old and new data). The easiest case would be to delete all ‘old’ metadata from each repository before harvesting it again. A reasonable alternative is to do an incremental update (from parameter) – insert new metadata and overwrite changed / deleted metadata (assignment using the unique identifiers).
XML Parser analyses the responses received from the repositories, with validation using the XML schema, and transforms the metadata encoded in XML into the internal data structure.
Normaliser transforms data in different metadata formats into a homogenous structure. It harmonises representation of, for example, date, author, language code. It may map between or translate different languages.
Database receives the output of the normaliser mapping the XML structure of the metadata into a relational database that will handle multiple values of elements. An alternative is to use an XML database.
Duplication Checker merges identical records from different data providers. One possibility for implementing this is by the unique identifier for each item (for example, by URN). However, this solution is often not easily practicable and is not risk or error free.
Service Module provides the actual service to the 'public'. The basis for a service provided is the harvested and stored records of the associated archives. That is, it uses only the local database for requests etc., and thus it does not make calls on the Data Providers during operation.
| Service Provider: resumption token | Top |
Resumption Token is optional from the Data Provider’s point of view. However, it is mandatory for Service Providers in order to retrieve complete lists in response to protocol requests that return lists (ListRecords, ListIdentifiers, ListSets) in order to resume sequences of incomplete lists. In order to provide flow control, Resumption Token must 'recognise' that the response from the Data Provider contains an incomplete list and then reissue the OAI request to the Data Provider in order to get next part of the list.
| Service Provider: test and registration | Top |
Test your OAI-PMH implementation by harvesting registered (as OAI conformant) Data Providers. There is a list of registered Data Providers on the OAI Web site, linked from the Community page, under the Interoperability Participants heading. Depending on your service, you may be planning to harvest from Data Providers that are not listed here. However, testing your implementation with some of the registered Data Providers will ensure that you have a working implementation of an OAI-PMH harvester.
This tutorial does not deal with implementing your end-user services, only with the implementation to harvest the records on which these services will, at least in part, be based. (Several examples of different types of OAI-based services are given at the end of this part of the tutorial.) Once you have tested the behaviour of your Service Provider harvesting, and once you have assured yourself your end-user service implementation is working as expected, you can register as a Service Provider at the official registration site (http://www.openarchives.org/service/registerasprovider.html). You will be asked to provide The full name of your service, a description of the type of service, the coverage offered (i.e., subject domain or topic), the URL of a Web page to be associated with your service, the email address of a contact person for your service, and a list of the Data Providers you harvest. This will be in the form of a Web page that you will put on your own server for ease of updating, and for which an HTML table template is provided. You simply have to email the URL for the page to OAI for addition to the list of Service Providers.
| Seven key definitions | Top |
Metadata
Structured information about resources (including both digital and non-digital
resources). Metadata can be used to help support a wide range of operations
on those resources. In the context of services based on metadata harvested via
OAI-PMH, the most common operation is discovery and retrieval of resources.
Acceptable use
Terms and conditions setting out which Service Providers can do what with metadata
harvested from a particular Data Provider or group of Data Providers. At the
Cornell meeting (September 2000) where the foundations for the OAI protocol
were agreed upon, an explicit choice was been made to hand over acceptable use
issues to communities implementing the OAI protocol.
The OAI-PMH does not address issues of acceptable use of harvested metadata, although it does allow for the inclusion of an "about" container attached to each harvested metadata record. Typically such an "about" container could be used to specify the terms and conditions of the usage of a metadata record. In this way, individual communities can express terms and conditions regarding metadata use at the level of individual records. In addition to that, at the level of a repository, the response to the Identify verb allows for the inclusion of an open-ended "description" container. Communities could use this container to include terms and condition information for all metadata records in the repository. From a technical perspective, these provide hooks are there to allow communities to specify terms and conditions for the usage of metadata harvested from their repositories.
Aggregator
An OAI aggregator is both a Service Provider and a Data Provider. It is a service
that gathers metadata records from multiple Data Providers and then makes those
records available for gathering by others using the OAI-PMH.
Flow control
The management of the flow of data between Data Provider and Service Provider
in order to assure that neither end of the transaction suffers overload.
Data representation
In this context, the format in which data of a particular type is set out in
order to provide interoperability across repositories.
Value-added service
A service that is based on harvested metadata, and adds value for its users
by means which may include normalisation and enriching of the harvested metadata
for example. Types of services which may be offered include search services,
citation linking, overlay journals, and peer-review services, among others.
Conformant
A repository is deemed to be OAI conformant if upon protocol testing by OAI
it responds to each of the protocol requests with a response that validates
with its XML schema, and also responds to malformed requests with the appropriate
errors and exception conditions.
| Sources of further information | Top |
-- Web sites and email lists --
Open Archives Initiative (OAI)
official site
http://www.openarchives.org
OAI-PMH protocol specification
http://www.openarchives.org/OAI/openarchivesprotocol.htmlOAI-PMH implementation guidelines
http://www.openarchives.org/OAI/2.0/guidelines.htmOAI tools
http://www.openarchives.org/tools/OAI general mailing list
http://www.openarchives.org/mailman/listinfo/OAI-general/OAI implementers discussion list
http://www.openarchives.org/mailman/listinfo/OAI-implementers/
Open Archives Forum
http://www.oaforum.org
OA-Forum Review of Technical Issues
Linked from http://www.oaforum.org/documents/OA-Forum Information Resource
http://www.oaforum.org/oaf_db/
Dublin Core
http://dublincore.org
-- Examples of Tools --
Repository Explorer
http://oai.dlib.vt.edu/cgi-bin/Explorer/oai2.0/testoai/
GNU EPrints
http://software.eprints.org/
DSpace
http://www.dspace.org/
PHP OAI Data Provider
http://physnet.uni-oldenburg.de/oai/
-- Examples of Service Providers --
ARC - A Cross Archive Search Service (experimental research service)
http://arc.cs.odu.edu/
Dokumenten- und Publikationsserver der Humboldt-Universität zu Berlin (search service, German language user interface)
http://edoc.hu-berlin.de/oaisearch/
iCite (citation index)
http://icite.sissa.it/
NCSTRL—Networked Computer Science Technical Reference Library (search engine)
http://www.ncstrl.org/
my.OAI (value-added search interface to a selected list of metadata databases)
http://www.myoai.com/
Physnet (simple search interface to an experimental OAI harvester)
http://physnet.uni-oldenburg.de/oai/query.php
ProPrint (printing-on-demand service, German and English language user interfaces offered)
http://www.proprint-service.de/
| Copyright © 2003 University of Bath. All rights reserved.
Author: Leona Carpenter (co-ordinating author) for OA-Forum and UKOLN |
Last modified: 14 Oct 2003 16:36 Authored in CALnet |