The Problem
The client had to have the following capabilities:
- Create and edit application profiles, and (for more advanced users) element sets and encoding schemes.
- Encourage reuse of existing elements and encoding schemes.
- Allow submissions to a remote registry server.
1 and 2 are the problematic areas.
Creation of application profiles, element sets and encoding schemes, of course, equates to the creation of RDF data. This is clearly impractical for non-experts, so the client must simplify the process greatly. Happily the data model is relatively simple. There are essentially seven kinds of object, each of which contain a number of fields: for example 'Agencies' have a name an associated home page.
Complications arise because some objects refer to others, for example 'Element Usages' may refer to 'Encoding Schemes'. This breaks the simple 'filling in fields' approach. The client had to have some obvious method to let users indicate that they want 'that' encoding scheme.
Encouraging reuse is the second major issue. What we wanted to prohibit is the case where a user creating an application profile felt compelled to create elements and (perhaps) encoding schemes for the profile, potentially wasting time duplicating effort and creating isolated data where interoperation is entirely possible.
The natural solution is to ensure that it is easier to find suitable preexisting items than it is to create new ones. Registries, convieniently for this purpose, provide a large store of existing elements and encoding schemes. So provisionally the problem became one of searching remote registries, and presenting the results so users can make informed decisions about whether use of found items is appropriate.
Available Software
Currently there are few options for RDF authoring. I looked at three applications: RDFAuthor [1], IsaViz [2], and Protege [3].
RDFAuthor and IsaViz are similar, so I'll discuss them jointly. (I should also declare an interest since I wrote RDFAuthor). These two applications present a graphical representation of what might be termed the 'raw' rdf data model. This is, in general, a graph structure with nodes (being URIs or literal strings) connected by properties. Taking as an example 'http://example.com' (node) 'homepageOf' (property) 'mailto:bob@example.com' (node): in both application this is displayed as two objects, labelled according, connected by an arrow labelled this 'homepageOf'. The following screenshots show more complicated data: (IsaViz first, RDFAuthor second)
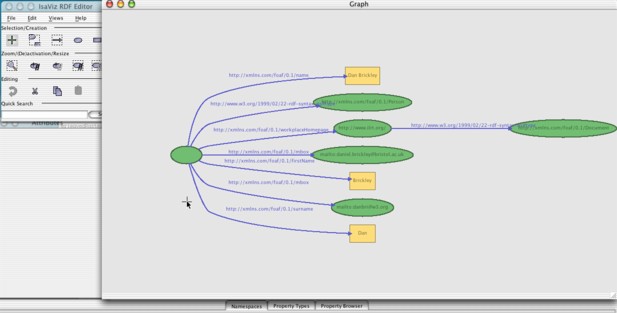
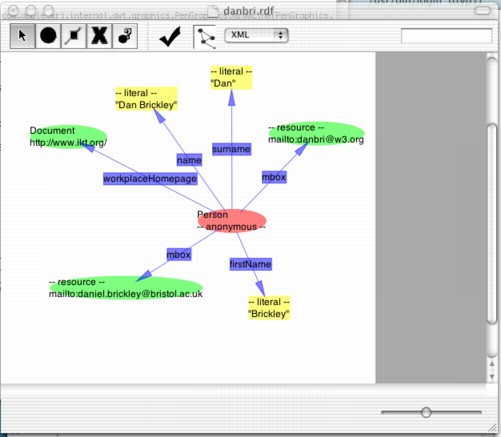
Authoring data consists of 1) making nodes and 2) connecting between nodes with properties. As a consequence any RDF datastructure can be created.
For the purposes of SCART neither application was suitable. They could probably have been augmented to talk to registries (problems 2 and 3 above), however although they hide the syntax of RDF neither hides the graph model. Using either tool would require a familiarity with the registry data model that is unreasonable.
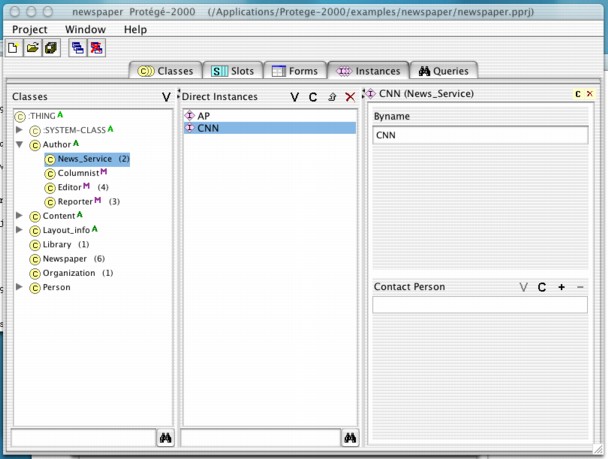
Protege (shown above) is quite different in scope and intention. It is a complex tool, but to simplify grossly it allows users to 1) create ontologies (vocabularies) 2) use ontologies to create interfaces for entering instance data and 3) query that data. Protege includes plugins for the DAML [4] and RDF Schema [5] vocabularies to describe the ontology. The latter was particularly interesting since the registry vocabulary can be seen as an extension of RDF Schema.
Protege showed some promise in solving problem 1 (creation) and 3 (submission to remote registry) could probably have been accomplished with an additional tool; 2 (reuse) however would have been a problem. A more significant diffculty was that Protege's notion of an ontology is a great deal stronger than the rather weak registry vocabulary. In particular the interface includes many items whose functionality does not exist in application profiles. The interface is, consequently, rather confusing.
An alternative approach would be to use enter load the Registry RDF Schema into Protege. The 'instance data' would then be profiles, elements, encoding schemes et al. This showed more promise, but the reuse issue remained. I was also concerned that users might edit the Registry vocabulary, or at least be confused by its appearance.
None of this is meant to imply that Protege, IsaViz, or RDFAuthor are unsuitable for their tasks. The recurring issue was simpy that they are general purpose tools, when the project really needed something tailored for its intended audience.
SCART
SCART was custom built for the project, using Java [6], which had a clear advantage due to its mulitplatform nature. SCART is known to run on Windows 2000, Mac OS X and Linux. The promise of Java is that it will run on other platforms (eg other Windows versions, BSD) as long as they has a version of Java. It should be noted that the user interface toolkit in Java (sometimes called 'Swing') has revealed some quirks, but generally is has been very useful. There is also an RDF toolkit for Java (Jena [7], written by Hewlett Packard Labs) which has made life easier.
To understand SCART it is best to start with a brief outline of the data structure:
- Agencies. These are people or institutions which can create all of the following:
- Application Profiles. These are collections of Element Usages, which refer to Elements (which might not have been created by the same agency). They might also be associated with Encoding Schemes (which, again, might not have been created by the same agency).
- Element Sets. These are collections of Elements. Elements (like Element Usages) might be associated with Encoding Schemes (again, they might not have been created by the same agency).
- Encoding Schemes. These may have associated Values.
SCART can support multiple documents (each a self contained window). Each document is associated with an Agency. When a new document is created the user has to supply a name for the agency, and an identifier (a URI which identifies the agency). They can optionally supply a URL for the homepage of the agency.
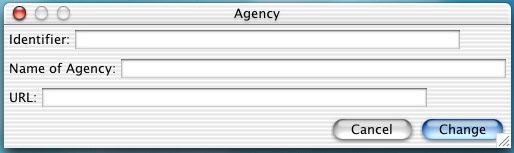
Here I enter an agency called (imaginatively) 'Example Agency'. The user has to give the agency a name and identifier before starting. The identifier is particularly important due to the nature of RDF. However this is the only time the user will be required give an oject an identifier.
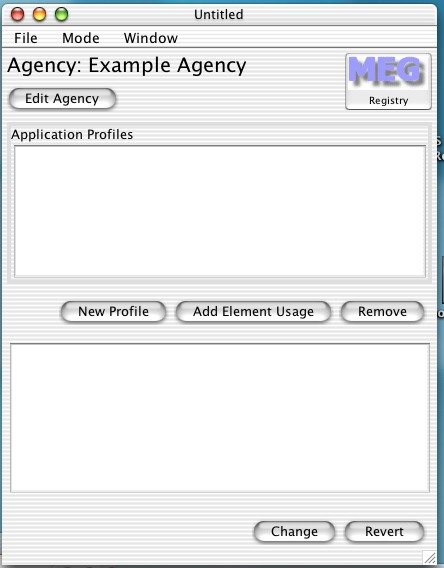
Everything created in this window will be associated with the agency (shown at the top). There is also one other window, which is not a document window:
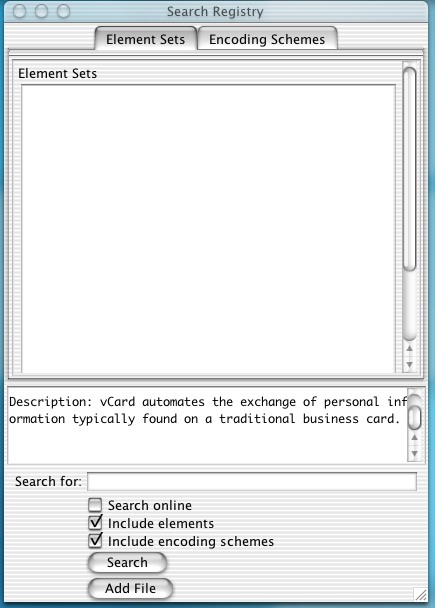
This window provides the 'reuse' incentive. It provides an interface to 'external' elements and encoding schemes (these being the items that may be used in profiles), where 'external' most commonly would be a remote registry. However data can be loaded from local files, allowing offline use.
Users can perform simple keyword searches to find elements and/or encoding schemes on the registry or just local files. Results are displayed in the window where they can be used in the profile.
At this point it is most informative to go through an example. Initially users can only create profiles and element usages (hopefully this will encourage the use of existing data, and also keeps the interface clean) however (as we shall see below) element sets and encoding schemes can be created in an expanded (perhaps 'expert') interface.
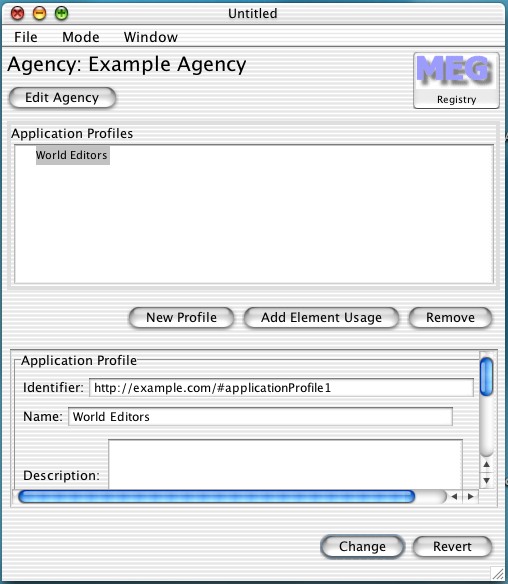
Firstly I create my application profile, called 'world editor'. Creating a profile adds it to the profiles list. My profile is intended for the description of editors and their locations in the world. Below the list is a box containing a list of fields for profiles. I edited the 'Name' field and clicked on 'change' to set the name. Similarly descriptions, versions, etc. can be set. Note that this is my profile (i.e. Example Agency's).
Next I want to add an element usage for 'Editor'. Now I could make up my own. However it is worth checking whether on exists already. Moving to the search window I try 'editor', deselect 'Include encoding schemes', and click 'search'.
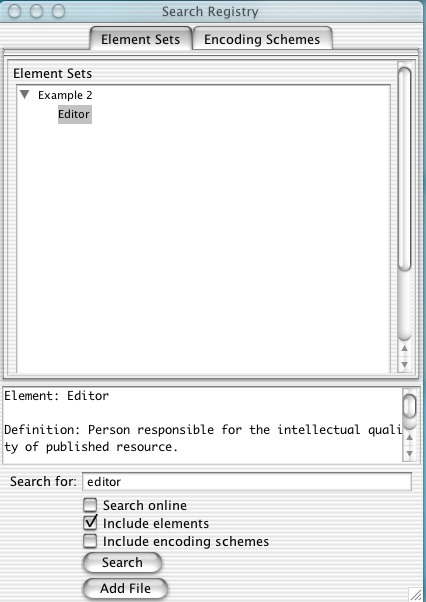
I find one result, whose description is shown when it is selected. The description fits what I want, so I use it by dragging the element onto the application profile.
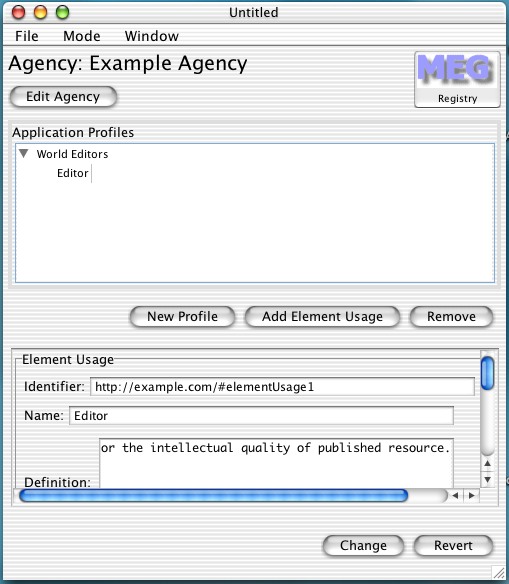
There are several things to note here. Firstly 'Editor' appears as a child of 'World Editor' in a tree view. Secondly dragging in 'Editor' (the external element) creates an element usage with the same name and description, with 'Editor' as the element (this can be seen in the 'Element' field). Profiles contain element usages, not elements (directly). However it is such a common operation that this is included. The alternative is creating a new Element Usage for the profile, then naming it and dragging the element to the 'Element' field.
Finally this illustrates how reuse is made easy. Searching is simple, and the use of drag and drop enables users to easily link in existing data. Drag and drop is used extensively throughout SCART. Encoding schemes and elements can be dragged to any place where their inclusion makes sense.
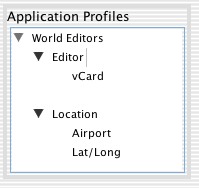
Next, suppose I want to use an encoding scheme for the author. One possibility is something like vCard, which seems suitable for the purpose. Just like Author we can search for an encoding scheme .mentioning vCard (which exists). Dragging it onto the Author element usage results in the following:
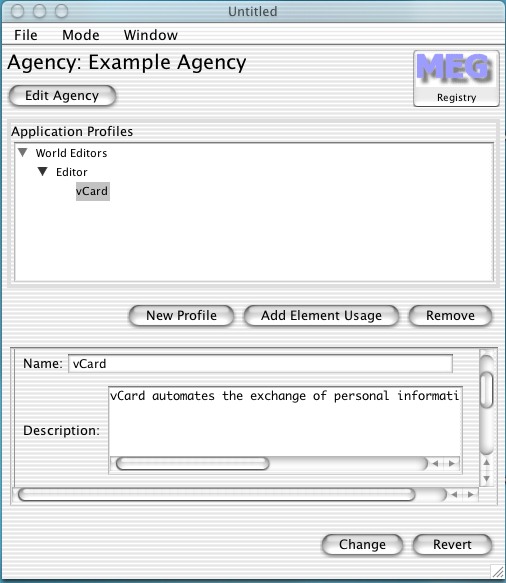
vCard is now a child of Author. Many element usages can be added to profiles, and many encoding schemes can be associated with element usages.
Next I come to creating element sets and encoding schemes. This, ultimately, should be exceptional, but is necessary on occasion. Imagine a fictional situation where I want to describe the location of the resource, as well as the editor. However (rather unlikely) no 'location' element exists.
The first step is to switch to 'advanced' mode. This adds two more views to the document window: 'Element Sets' and 'Encoding Schemes'.

I want a new element, so I select the 'Element Sets' table and add an element set. Once I've filled in the fields for the set I add an element called 'Location' to this set. This refines 'http://example.com/schema#location', which I type into the 'refines' field of the element (along with the name and so on). The result is the following:
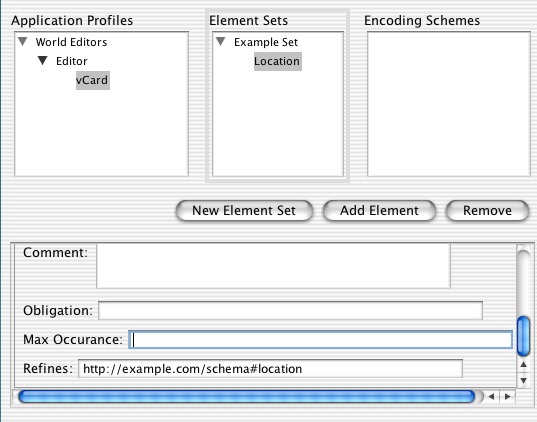
Clearly this takes longer than searching and using a preexisting element. The fact that 'Location' is part of 'Example Set' is indicated by the fact that it is a child of 'Example Set'. It can now be used by dragging it onto the 'World Editor' profile.
Before that I'll create an encoding scheme. This scheme will be for locating things by closest airport. Switching to 'Encoding Schemes' the process is very similar. I click 'New Encoding Scheme', edit the fields of the encoding scheme, then I can add values to this such as 'LHR' for London Heathrow.
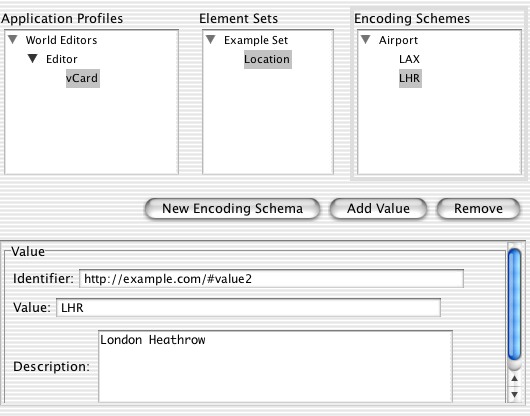
Now I'll add this to the element 'Location' as a possible encoding scheme. This is done by dragging 'Airport' onto the 'Location' element.
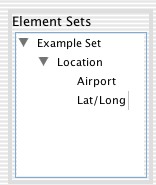
(Here I also found a latitude/longitude encoding scheme by searching the registry, so I've added that as well)
Finally I drag 'Location' to the profile. This element usage also gains the encoding schemes of the element, as well as the name and description which we saw before.
The result can be saved locally (in RDF/XML) and uploaded to the web, or reloaded for further editing. Alternatively the data can be added to a remote repositry, with the advantage that other agencies can reuse items.
Summary
SCART is designed to make creating profiles, element sets, and encoding schemes easy. I hope that it does. Certain chores could not be automated (eg filling in fields) but elsewhere I have tried to make the process as simple and intuitive as possible.
References
[1] RDFAuthor by Damian Steer. http://rdfweb.org/people/damian/RDFAuthor/
[2] IsaViz by Emmanuel Pitriga. http://www.w3.org/2001/11/IsaViz/
[3] Protege. http://protege.stanford.edu
[4] DAML. http://www.daml.org/
[5] RDF Schema. http://www.w3.org/TR/rdf-schema/
[6] Java. http://java.sun.com/