|
JISC Information Environment JISC IE Discovery to Delivery (D2D) Reference Model |
|
|
JISC Information Environment JISC IE Discovery to Delivery (D2D) Reference Model |
|
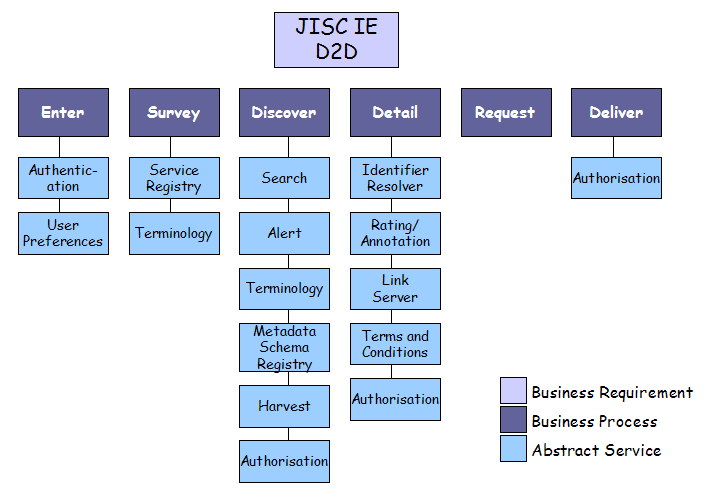
This document presents the JISC Information Environment (IE) as a 'reference model' (as that term is used by the DLF Abstract Service Framework Working Group).
| Business requirement: An identifiable segment of an organization's overall mission, purpose, or functional scope. |
The JISC Information Environment allows the end-user to discover, access, use and publish digital and physical resources as part of their learning and research activities. Discovery to delivery (D2D) is the process by which an end-user moves from identifying a need to obtaining a resource that they can use to address that need.
| Business process: An identifiable portion of a business requirement. |
The 'JISC IE D2D' business requirement comprises the following business processes:
Each business process is described in more detail below, using UML use case notation.
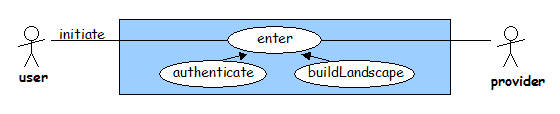
In order to support personalised services and to limit access to licensed resources, end-users are likely to have to be authenticated before interacting with the JISC IE. On initiating the 'enter' use case, by visiting the top-level Web page for a service for example, the user may be prompted for a username and password. This results in a new session being started. An initial 'landscape' is presented to the end-user based on their user-profile. The landscape may consist of a view of the resources to which that user has access rights and that correspond to the subject interest of the user.
Note that a 'guest' account may be available that offers a restricted landscape and functionality.
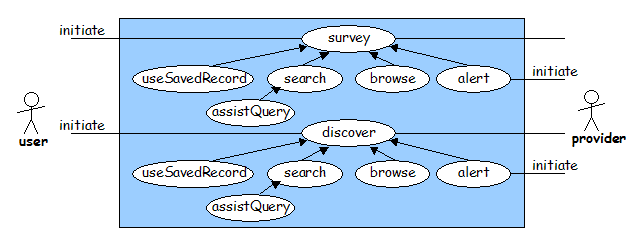
An initial phase of discovery, the 'survey' use case, is concerned with identifying the collections that are worthy of further investigation. This process is likely to involve narrowing down the collections presented as part of the 'landscape'. However, it may also involve the discovery of new collections that are not yet listed within the landscape.
The results of the 'survey' use case are a set of collections that warrant further investigation.
The 'discover' use case drills down into each of the collections identified during the initial survey. The intention is to discover a particular item of interest. The result of this activity is not the item itself, but a metadata record about that item.
It is likely that survey and discover can often be considered as parts of the same activity. Both make use of four 'discovery' strategies. Either a search-based approach is used (the 'search' use case), or a browsing approach is used (the 'browse' use case) or some kind of 'bookmark' list is used (the 'useSavedRecord' use case). The 'useSavedRecord' use case may make use of a personal set of bookmarks or a shared list - for example, a course reading list or a set of bookmarks exchanged between research colleagues. Finally, alerting mechanisms may be used (the 'alert' use case). In this case, the content provider alerts the end-user to the existence of a new or updated resource (items or collections), typically using email, an RSS channel or a Web-based alerting mechanism.
As part of the 'search' use cases the system may provide some assistance with the search terms used, the 'assistQuery' use case. Typically this includes the use of a terminology service or thesaurus to improve the search terms used by the end-user in constructing a search query.
By the end of the 'discover' use case the end-user will have discovered a resource, for example a book (in which case they might know its title, author and ISBN) or a Web page (in which case they might know its title and URL).
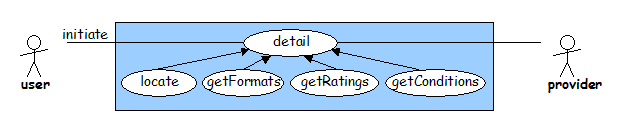
The 'detail' use case builds up knowledge about a particular resource to the point where enough is known that there is no ambiguity about the item that must be requested.
Note that Web resources often present the minimal case here because the URL is known at the end of the 'discover' use case - no further information is required in order to request the resource.
More generally, for example in the case of obtaining books or journal articles, it may be necessary to locate the most appropriate format, cheapest or nearest copy of a resource. The 'locate', 'getFormats', 'getRatings' and 'getConditions' use cases facilitate this process.
It is arguable whether the 'detail' use case forms the last phase of the discovery process or the first phase of obtaining the resource, or whether it is a separate process. Specific implementations may choose to implement the 'detail' use case in a variety of ways. In particular, selecting between multiple mirrored copies of a Web resource may be presented as an explicit choice to the end-user (as part of the 'detail' use case) or may be done behind the scenes as part of the 'deliver' use case below (in much the same way as Web caching is typically done).
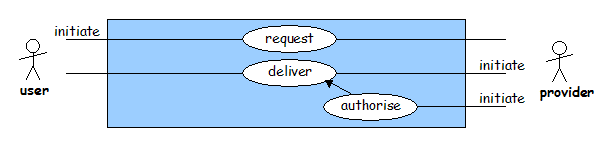
Having sufficiently identified the particular resource that he or she is interested in, the end-user may attempt to obtain it. The 'request' use case allows the end-user to ask for a particular item. For Web resources this is typically as simple as clicking on a link. Delivery is initiated by the content provider - in response to the end-user clicking on a link or an inter-library loan (ILL) request for example. In some cases authorisation will be required before the item is delivered (the 'authorise' use case) typically based on the authentication credentials presented earlier or on the IP address of the end-user's browser. Where items are not available free at the point of use, payment may be required before delivery. This would be covered by a 'pay' use case and would typically result in a credit card transaction, though this is not considered here.
Although the business process are presented here in a linear way, in practice they will tend to be used in a more cyclic fashion, as shown below:
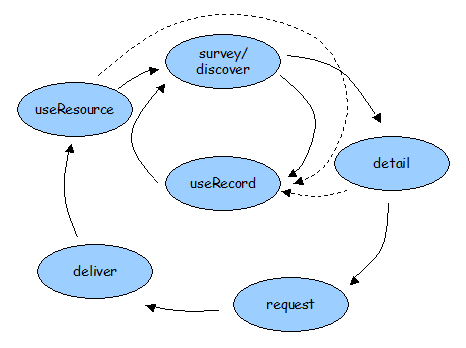
Note that this diagram introduces two new use cases, useRecord and useResource, which are not described in detail here. These two use cases are concerned with the end-user's use of the metadata records (e.g. saveRecord, annotate and share) and resources (e.g. unpack, view, process, incorporate and store) that are the results of the use cases above.
| Abstract service: An identifiable portion of a business process. An abstract service includes a description of its functional scope, and an abstract model of its behavior and data. |
The following abstract services are used to deliver the business processes described above:
| Service binding: A specific instantiation of an abstract service. A service binding elaborates on an abstract service by providing all of the following which are applicable: 1) a specific data representation; 2) an Application Programming Interface (API) specification; and 3) a Web service specification. |
This is currently a very minimal list of appropriate protocols and standards.
| Deployed service: A service that is made available on the network and that conforms to a service binding. |
This appendix is indicative, rather than providing an enumerated list of deployed services, since there may well be many hundreds of deployed services making up the JISC IE. JISC IE deployed services can be mapped according to the diagram below:
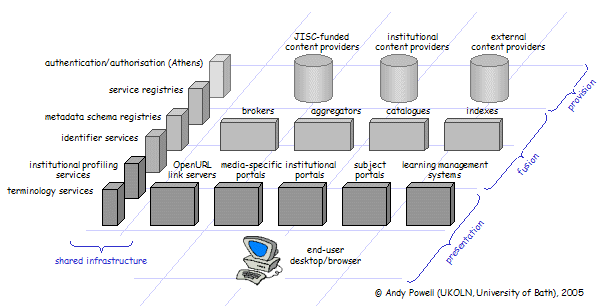
List of example deployed services to be supplied