Manjula Patel
UKOLN
University of Bath
Claverton Down, Bath, BANES BA2 7AY
United Kingdom
Robina Clayphan
National Bibliographic Service
The British Library
Boston Spa, Wetherby, West Yorkshire, LS23 7BQ
United Kingdom
This paper describes the BIBLINK project and some of the issues arising from it. BIBLINK is a project funded by the European Commission. It began in May 1996 and is due for completion in February 2000. The aim of the project is to establish an automated flow of information, between publishers and national bibliographic services, in order to create authoritative bibliographic data which benefits both sectors. The project examines the way in which electronic publications are described for catalogues and other listings, and how this information can be easily transmitted.
National bibliographic agencies (NBAs) across Europe differ in their selection policies, which are typically based on the prevailing legal or voluntary deposit arrangements. Currently however, they are all facing similar challenges with regard to the changing practices in publishing brought about by developments in electronic publication. Until a few years ago material was published by a relatively limited number of organisations in any one country, most of whom had well established lines of communication with their national library and were well aware of the legal and commercial framework in which they operated. Given the explosion in electronic publication, it has been envisaged that significant numbers of valuable publications could go unrecorded since they would by-pass established national bibliographic procedures.
The need to research and develop systems to address the ensuing issues was recognised by CoBRA (Computerised Bibliographic Actions)[1]. A proposal was therefore put forward to develop a system which would allow publishers to provide an agreed minimum level of data to NBAs. The data could then be enhanced to national library standards and transmitted back to the publishers for inclusion in the publication or within their promotional literature. The purpose of the BIBLINK project[2] is to create a prototype system that will provide an automated flow of metadata between the two sectors.
The benefits for the national libraries is clear, an early receipt of bibliographic information in machine readable form would provide for editing and entry into the national bibliography with the attendant possibilities of developing new products and services relating to electronic publications. The pincipal benefit for publishers would be the recording of the publication in the national bibliography with the concomitant prospect of wider public awareness of its existence.
To carry out the work of the project five European national libraries (UK, France, the Netherlands, Spain and Norway) joined with two academic institutions (UKOLN at the University of Bath and the Open University of Catalonia) and two publishing trade organisations (Book Industry Communication and CD-ROM Standards and Practices Action Group) to form the BIBLINK Consortium.
The BIBLINK project was proposed with the objective of developing a demonstration system for acquiring metadata for electronic publications directly from publishers. Not only does this enable electronic documents to be incorporated into the national bibliography, but it also allows for the resulting data to be returned to the publisher so that it can be embedded in the publication itself, or be used in other applications, such as sales promotions. In addition the enhancement of the author data, by means of authority control, and the addition of authoritative subject data could potentially enhance customer searches of their own catalogues and other listings should publishers choose to use the returned bibliographic metadata. The overall objectives of the project can be summarised as follows:
The project officially started on 15 May 1996 and was divided into two distinct phases, each of which was expected to be eighteen months in duration. The first phase was primarily for research and consensus building and the second for software development, implementation and testing.
During the first stage, in addition to the scope of the project being more precisely defined, information was gathered and analysed about the various components that contribute to a data generation, transmission and conversion system. This included detailed studies relating to data formats, numbering systems, encryption, authentication and format conversions. The research entailed considerable discussion with publishers and consensus with them as to the most promising technical solutions to implement. Further information may be found on the project's web-site[2].
In the second phase of the project, work began by formalising the user requirements and producing a detailed functional specification[3] which has resulted in a prototype system[4]. An exploitation plan is being developed to provide a framework for library partners to assess the possibility of incorporating the system into their operational procedures. At the time of writing, the project is in the Demonstrator phase, during which use of the system will be verified by several national libraries and over twenty publishers.
A metadata study[5] undertaken during stage one, identified current approaches to encoding metadata. A comparative analysis was carried out and recommendations made as to which were most likely to be of use in the project. Given the range of publishers involved it was felt that offering only one format would not be realistic. The recommendation was to use the element set defined by the Dublin Core Metadata Initiative (DCMI)[6], extended as appropriate to accommodate the minimum requirements specified by the libraries. These were mapped to the MARC formats in use in libraries to ensure the data provided would produce a sufficiently rich record.
The element set adopted is shown in the table below. It comprises twelve of the fifteen Dublin Core (DC) elements plus another ten defined by the partners as the minimum data set libraries would require. Those shown with a DC prefix in the table are the elements taken from the Dublin Core, and those with a BIBLINK prefix are the ones added by the project.
|
Element Name |
Element Definition |
|
DC.Title |
The name by which the resource is known |
|
BIBLINK.TitleAlternate |
A title other than the main title; including subtitle |
|
DC.Creator |
The person primarily responsible for the intellectual content |
|
BIBLINK.CreatorOrganisation |
The organisation primarily responsible for the intellectual content |
|
DC.Contributor |
A person responsible for making contributions to the content |
|
BIBLINK.ContributorOrganisation |
An organisation responsible for making contributions |
|
DC.Identifier |
A unique number or alpha-numeric string e.g. DOI, ISBN,URN |
|
DC.Publisher |
The agent responsible for making the resource available |
|
DC.Date |
The date of availability of the resource |
|
DC.Format |
The physical or digital manifestation of the resource |
|
DC.Subject |
The topic of the resource. Key words or phrases |
|
DC.Description |
Description of content or an abstract |
|
DC.Language |
The language of the content |
|
DC.Rights |
A rights management statement or link to it |
|
DC.Source |
Information about another resource from which the present resource is derived |
|
BIBLINK.Price |
A simple retail price – for physical resources such as CD-ROMS |
|
BIBLINK.Extent |
The size of the resource – in bytes, number of files or CD-ROMs |
|
BIBLINK.Checksum |
A hash value computed for authentication purposes |
|
BIBLINK.Frequency |
The frequency of issue for serials |
|
BIBLINK.Edition |
A statement indicating the version or edition of the resource |
|
BIBLINK.PlacePublication |
Geographic location of the publisher |
|
BIBLINK.SystemRequirements |
Hardware or software requirements for the system needed to view the resource |
Table: BIBLINK Core Metadata Set
The elements of the BIBLINK Core (BC) were mapped to UNIMARC as an intermediate format. Since an SGML format used by more than one publisher could not be found, Chadwyck-Healey’s DTD was also mapped to UNIMARC to prove the feasibility of using SGML. USEMARCON, an existing conversion tool developed by another EU project[7], was extended to accept and process the incoming data. The output formats needed were the MARC formats of the participating national libraries (UKMARC, IberMARC, InterMARC, BibsysMARC) with the exception of the Netherlands whose MARC format does not comply with the ISO2709 standard generally used for MARC records. In addition a DC tagged HTML view was needed so that records could be cut and pasted into the source code of a web publication. The system also generates a simple listing of the element labels and their values.
A study of identifiers[8] resulted in a list of requirements to cover the range of resources included in the scope of the project. The chosen identifiers had to cover both on-line and physical items as well as exhibiting the characteristics of persistence, global uniqueness, extensibility, human-readability, and of being capable of transported over the internet. Ideally they would be standard and come from an authorised naming authority.
No one identifier was found that would meet all these requirements. It was recognised that it was beyond the scope of the project to enforce the use of any particular scheme in any case and that the project should offer a range of options. Those actually incorporated into the project include the established schemes of SICI, ISBN, and ISSN, and those currently under development for digital items: URN and DOI. For all its shortcomings as an identifier the URL was also included as it would be unrealistic to exclude the scheme that was most likely to be offered by publishers.
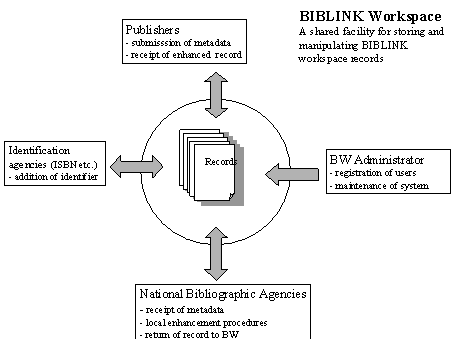
An overview of the system produced is shown in the figure below. The BIBLINK Workspace (BW) can be characterised as a computer-mediated shared workspace for the creation, processing and transmission of metadata. At its core lie the database of records, the conversion software and the system control software. These communicate with email and Web interfaces for the receipt and automatic onward transmission of metadata.
There is a two-way channel of communication for publishers to submit data and receive enhanced data in return, similarly, an interface for NBAs to receive publisher data and return it. If identification agencies are to be involved they can be given the right to read the record and add data to the identifier field only. Access to the BW is governed by a user name and password allocated by the BW Administrator.
Each channel of communication is available using either an email or Web interface. Publishers can elect to use whichever they feel is most appropriate to in order to submit their bibliographic data. The Web interface was intended for those who have no systematic bibliographic database from which to extract data. It provides a straightforward method for entering text and the option of nominating a scheme for identifiers if appropriate.
The email route is also simple but perhaps less straightforward. There are two ways of using it: an email message can be constructed using a syntax specified for BIBLINK with the data in the body of the text. Alternatively an existing SGML or HTML dataset can be sent as an email attachment. Either way the process could be semi-automated by writing a simple script to harvest the data from a database in the prescribed format and using an email template for the commands.
The following sequence of events relates to the BW installation hosted at UKOLN and used by the British Library.
Having specified UKMARC as the preferred format in their user profile, the National Bibliographic Service (NBS) at the British Library receive an email notification of the creation of a new BW record and the UKMARC version of that record is attached to the message. Cataloguing staff download the record into a MARC editing application and enhance it by means of adding a Library of Congress Subject Heading, Dewey Decimal Classification and applying the Name Authority File to the creator. The record is then saved to a file for use in NBS products and a copy returned as an email attachment to the BW. Receipt of this record at the BW triggers the updating of the original publisher data and the generation of an automatic email notification to the publisher, again with an attached BC or UKMARC record. The HTML version of the record can be requested separately by email or from the Web interface using the display or search functionalities.
The full database of records is retained within the BW and can be searched, and records downloaded in any of the available formats via either the email or the Web interface.
Two further scenarios are described in [9]. The first involves a publisher and an NBA, while the second includes an ISSN agency in addition to the publisher and NBA. Both scenarios serve to highlight the flow of information that takes place between the various participants.
The attribution of a URN to BIBLINK records is under consideration. The Nordic Metadata Project already makes use of the national bibliography number as the basis for the generation and attribution of this identifier. There is an opportunity for national libraries to undertake the development and expansion of this model on a larger European scale, both in controlling the registration of namespace identifiers and assigning URNs to publications.
In the future, it could be the case that the national bibliography becomes used significantly as a means to access electronic works. It has been suggested that an on-line national bibliography could contain a link to the catalogue of the publisher, enabling the user to access or acquire the publication directly.
The possibility arises of using the electronic link with publishers to establish an alerting service. This could make use of the publishers minimum data at or just before the time of publication. The records need not necessarily be quality checked but simply made available to users as an alerting service. Developing from this is the possibility of interconnecting these alerting services for a European-wide service.
It is possible for publishers to insert URLs in the reference section of a publication, leading to metadata on other publications (from other publishers), via the National Bibliography. This could lead to useful hyperlinked citation structures that would benefit the researcher in his quest for relevant literature.
At the time of writing the BW Demonstrator has been operational as hosted by UKOLN for only a few weeks and it is too early for a full report of the findings. Apart from minor technical matters with the software, issues that are becoming apparent include:
Some Web publishers already create DC records for their publications. From the samples that have been seen it appears that there is some variation in the interpretation of the semantics of the DC elements.
A publisher has defined extensions to DC elements to accommodate different publisher roles (DC.Creator.Role.1). Whilst this is useful information, the BW is not sufficiently flexible to recognise these extensions and will simply ignore the field. It should be noted that the publisher in question was an early adopter of the Dublin Core and a means of differentiating between various roles in the creation of a resource is being actively pursued by DCMI.
Data is not consistently represented in the DC records of a publisher's resources. For example, the name of the Creator is variously entered as: John Doe, Doe, J and JD for resources made available by the same publisher. This metadata was produced independently by the publisher before participation in BIBLINK.
Records produced using the Web interface have been of a better standard than those extracted from data already embedded in some on-line resources. The Web form has the advantage, from the library's point of view of concentrating attention on the task, limiting errors that can be made and causing the user to create the record following the guidelines provided.
The BIBLINK project has produced software that can be used by individual organisations to fulfil a valuable role in record creation and alerting functions. The modular design of the system caters for customisation and will allow the component parts to be further developed as procedures and work-flows are revised to meet the new processing needs for electronic publications.
Research during the project has highlighted many issues that need to be resolved both internally in libraries and between the library and publishing communities. The reports from the studies and findings from the demonstration of the system will assist in this process.
Work to date has contributed to the debate within the libraries relating to electronic publications. Consideration of bibliographic information leads directly to discussion of the related issues of deposit arrangements, public access to and long term storage of digital material and is therefore an integral part of the major policy developments that are taking place in all national libraries. Discussions with publishers have indicated that they too are engaged in parallel internal debates, seeking solutions to the ramifications of electronic publishing in a market place offering great opportunity but still in a state of flux with regard to standards and procedures. Indeed it has been remarked that in the areas of identifiers and metadata requirements participating in BIBLINK has provided a timely learning opportunity.
The BIBLINK project is sponsored by the European Commission. It is funded under the Telematics Application Programme of the European Union Fourth Framework Programme.
[1] Lehman K-D., European national libraries and the CoBRA forum of the EU Libraries. Alexandria 1996 8(3) 155-166
[2] The BIBLINK Project Web-site http://hosted.ukoln.ac.uk
[3] BIBLINK Workspace Functional Specification. BIBLINK D8.1, June 1998 http://hosted.ukoln.ac.uk/biblink/wp11/
[4] BIBLINK Workspace at UKOLN: http://biblink.ukoln.ac.uk/biblink (an account and password are required for access)
[5] Heery R. et al. Study of Metadata. BIBLINK D1.1, December 1996 http://hosted.ukoln.ac.uk/biblink/wp1
[6] Dublin Core Metadata Initiative: http://purl.org/dc/
[7] USEMARCON software and documentation http://www.konbib.nl/kb/sbo/bibinfra/bibin.htm
[8] Hogas H. et al. Identification. BIBLINK D2.1, May 1997 http://hosted.ukoln.ac.uk/biblink/wp2/d2.1
[9] Powell A., BIBLINK Usage Scenarios http://www.ukoln.ac.uk/metadata/biblink/wp8/usage-scenarios/
[1] Day M., Heery R., Powell A.,
National bibliographic records in the digital information environment: metadata, links and standards. Journal of Documentation, January 1999, 55(1)16-32.
[2] Noordermeer T.,
A bibliographic link between publishers and national bibliographic agencies concerning electronic publications: project BIBLINK. International cataloguing and bibliographic control, January/March 1999, 28(1) IFLA UBCIM Programme. ISSN 1011-8829.