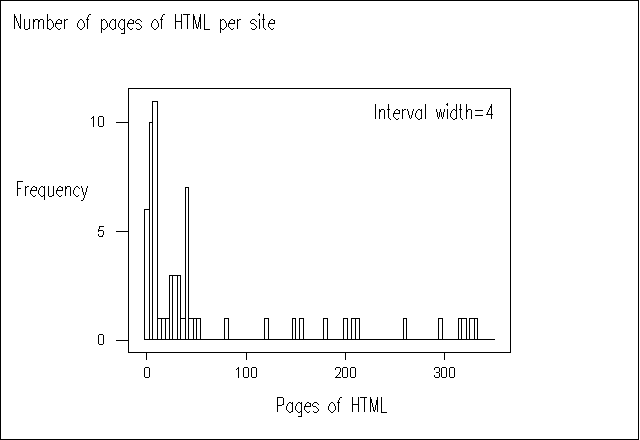
Figure 1 Size of Website (by number of HTML pages) Versus Frequency.
UKOLN has been active recently analysing UK Public Library websites. Brian Kelly, Sarah Ormes and Ian Peacock report on their findings.
If you have eaten a packet of crisps, read a newspaper or watched a TV commercial over the last week you have probably, at some point, come across the increasingly ubiquitous http://... of a World Wide Web address. At times it seems that having a website is as essential as having a phone number.
Public libraries in the UK have also been following this trend. In late 1995 the 'Library and Information Commission public library Internet survey' [1] showed that already 25% of library authorities were providing some sort of information over the Internet. By the time of the publication of 'New Library: The People's Network' [2] Sheila and Robert Harden's 'UK Public Libraries' web page [3] had links to about 90 public library websites.
Whereas many company websites are little more than hi-tech adverts for their products a website offers a public library a real opportunity for enhancing current services and developing new ones. Libraries in Denmark, the UK and America, for example, are already using the Web to provide networked services to their readers - whether this means logging in to the library OPAC at home, emailing a reference query, viewing digitised images from the local history collection or even finding out where the local allotments are.
These type of networked developments were highlighted in the 'New Library: The People's Network' report as being essential components of the public library of the future. Public library authority websites will be the gateways though which an increasing number of people will use their library services. Considering the importance these websites could play we know very little about public library authority websites in the UK. We know roughly how many there are but other statistics are difficult if not impossible to find.
Although we are all familiar with the quotation 'there are lies, damned lies and statistics' statistics can be useful, enlightening and essential. We now need statistics about public library authority websites which will give an indication of the strengths, preparedness and shortfalls of current sites so we can begin to develop the networked library services of the future.
The WebWatch project is funded by the British Library Research and Innovation Centre (BLRIC). The main aim of WebWatch, which is based at UKOLN (the UK Office for Library and Information Networking), is to develop and use robot software for analysing various aspects of the World Wide Web within a number of UK communities, such as academic institutions and public libraries.
The work plan for WebWatch includes:
The publication of the 'New Library: The People's Network' report and preparatory work for the National Libraries Week coincided with the plans for the initial run of the WebWatch robot. Following discussions within UKOLN and with representatives of the UK public library community it was agreed that the initial launch of the WebWatch robot would cover websites for UK public libraries.
Following some initial test runs, the WebWatch robot trawled UK public libraries’ websites on the evening of Wednesday, 15th October 1997 the day of the launch of the New Library report. The robot took its list of public library websites from the Harden’s UK Public Libraries web page.
The WebWatch robot is based on the Harvest software [4]. Various modifications to the software were made in order to tailor the software for auditing and monitoring purposes. Developments are still being made as we gain experience in using the software.
The Harden list of UK Public Library websites has 90 entries. The WebWatch robot successfully trawled 64 sites. Eight of these sites which could not be accessed were hosted by the NIAA (the Northern Informatics Applications Agency) which was in the process of upgrading its web server while the WebWatch robot was in use.
As can be seen from Figure 1, the majority of sites contain a small number of pages, with a median of 24 pages. Thirteen sites contained over 100 pages, with only four sites containing over 300 pages.
A manual analysis of some of the large websites indicated that the robot had analysed non-library pages, such as information on museums, leisure services, etc.
Figure 2 shows the number of (inline) images on public library websites. Again we can see that most websites used a small number of images, and that the websites containing large numbers are probably distorted by the analysis of non-library resources.
Figure 3 shows the total size of public library websites. Again we can see that most of the websites are small, with a median value of 190 Kbytes. The mean value of 730 Kbytes is again likely to be skewed by the analysis of whole council websites.
In addition to analysing the numbers and sizes of the websites, we also analysed the domain names. We were interested in whether public libraries used their own domain name (such as www.ambridge.org.uk) or if they simply rented space from an Internet Service Provider.
The WebWatch robot took its input data from a list of Public Library websites. The total number of websites is taken from this list. However in some cases these may refer to Public Library Authorities.
The WebWatch robot analysed resources located beneath the directory defined
in the input data. In one case the library website had its own domain name
(e.g. http://www.lib.ambridge.org.uk/). In most other cases the
library stored its resources under its own directory
(e.g.
In some cases, however, the main library entry point was located in the same directory as other resources (e.g. http://www.ambridge.org.uk/library.html and http://www.ambridge.org.uk/leisure.html). This case is more difficult to process automatically.
In the analysis the figures for the sizes of a number of public library websites are likely to be inflated by the robot indexing non-library pages.
The initial run of the WebWatch robot was timely as it coincided with the launch of the 'New Libraries' report. However the robot is still in its infancy, and we intend to implement a number of new facilities. Our plans include:
Additional trawls of public libraries: To provide greater and more detailed coverage of public library websites.
Analysis of header information: This will enable us to determine when HTML pages were last updated.
Analysis of HTML elements: This will enable us to monitor usage of HTML elements (such as tables, frames, etc.) and technologies such as Java. This can be important in ensuring that web resources are accessible to large numbers of people, and not just to those running the latest versions of web browsers.
Analysis of quality and conformance: This will enable us to monitor conformance to HTML standards, HTTP errors (which can indicate broken links, misconfigured servers, etc).
More refined classification of resources: This will address the issue of the robot accessing non-library resources.
In addition to developments to the robot software, we will be looking to analyse server log files. Server log files provide useful statistics, including details of the browser (such as browser name, version number and the platform and operating system on which the browser is being used) used to access web resources.
The WebWatch analysis of the UK public library websites took place at a timely moment for the library community. It provided a snapshot of the community on the day of the launch of the New Libraries report.
The analysis indicated that, with a small number of exceptions, most public library websites consist of a small number of pages - it seems likely that the majority of public library websites would fit comfortably on a floppy disk! Although this is still early days for public libraries on the web, it is pleasing to note that our involvement with the public library community shows that a number of public libraries are developing comprehensive websites.
The analysis also indicated that refinements were needed to the robot, in particular to the definition of sites to be analysed.
UKOLN looks forward to working with the public library community in further surveys.
[1] 'Library and Information Commission public library Internet survey', see <URL:http://www.ukoln.ac.uk/publib/lic.html>
[2] 'New Library: The People's Network', see <URL:
http://www.ukoln.ac.uk/
services/lic/newlibrary/>
[3] 'UK Public Libraries', see <URL: http://dspace.dial.pipex.com/town/square/ac940/ukpublib.html>
[4] 'Harvest', see <URL:http://harvest.transarc.com/>
Brian Kelly is UK Web Focus, a national Web coordination post funded by JISC. Sarah Ormes is UKOLN’s public library networking researcher. Ian Peacock is WebWatch, and is responsible for software development and running the WebWatch robot software.
UKOLN is funded by the British Library Research and Innovation Centre and the JISC of the Higher Education Funding Council.
Figure 1 Size of Website (by number of HTML pages) Versus Frequency.
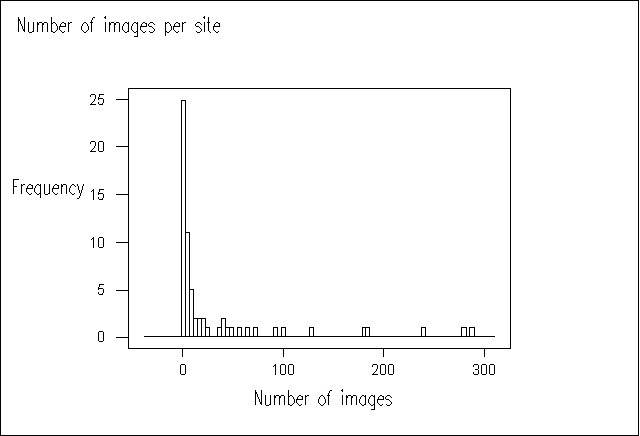
Figure 2 No. of Images Versus Frequency.
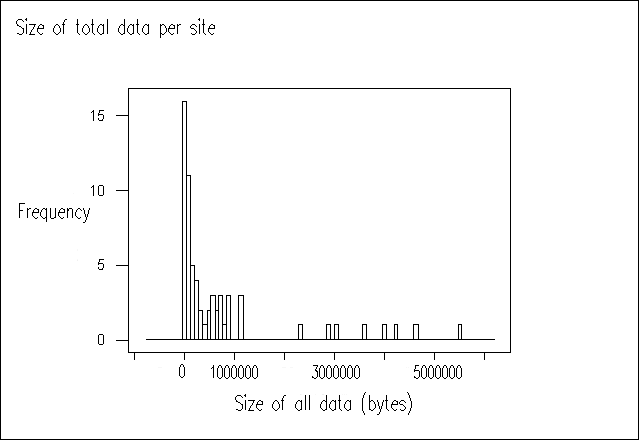
Figure 3 Size of Website (filesize, including HTML pages, images, etc) versus frequency.
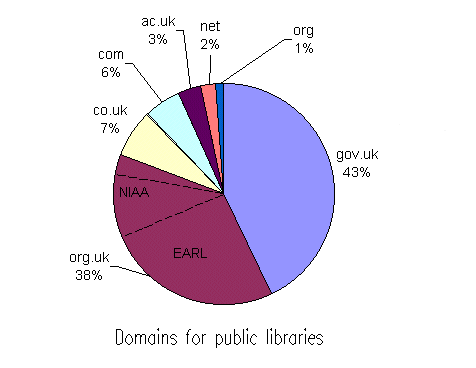
Figure 4 Domain Name Usage.
A web robot is an automated software tool, which retrieves web resources.
Web robots are often used for indexing the World Wide Web. For example the large search engines, such as Alta Vista and Lycos, use a web robot for retrieving and indexing web resources.
The WebWatch robot is based on the Harvest software, which is widely used, especially in the academic community, for indexing web services.
The WebWatch robot conforms to the Robot Exclusion protocol. It will not analyse resources which have been appropriately flagged. In addition we aim to run the robot overnight and at weekends when network and server load is likely to be at a minimum.