PRIDE Logical Components and Integration Designs
Work Package 2 of Telematics for Libraries project PRIDE (LB 5624)

Title page
Table of Contents
|
PRIDE Architecture and Interfaces &
PRIDE Logical Components and Integration Designs Work Package 2 of Telematics for Libraries project PRIDE (LB 5624) |
Title page Table of Contents |
This section introduces the functional units that will form the PRIDE demonstrator. The descriptions given are high level in nature and will be refined over time. At this stage in the design process we are concerned with what the building blocks will be and what they will do, rather than the details of how they will function. The refinement and finalisation of the design will be addressed in the deliverable D3.1.1 - Consolidated PRIDE Design.
Two major issues have arisen during the work leading to the production of this document:
This section introduces the classes of component that will form the PRIDE demonstrator. This basic classification is a refinement of that presented in the original proposal document [PRIDE1].
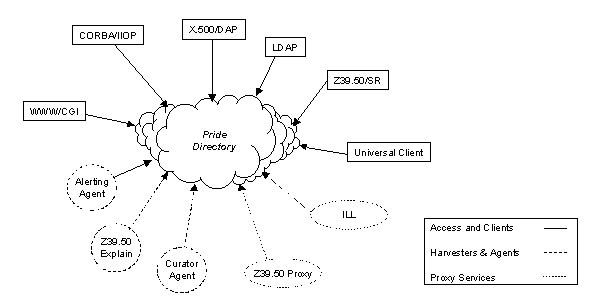
Figure 1 - Classes of components in the PRIDE
demonstrator
With reference to Figure 1, we can see the PRIDE Directory itself at the heart of the system. The directory will be a hybrid of X.500 and LDAP technologies.
The PRIDE Directory forms the heart of the demonstrator. The directory holds all of the data that enables our implementation of value-added and directory-enabled services. This data will cover a range of patron and service information. The schema of the directory is, in itself, a significant outcome of the project. The directory will be a hybrid of full-blown X.500 and of LDAP. LDAP servers will be tied transparently into the X.500 DIT.
As introduced above, the PRIDE Directory will be a hybrid of X.500 and LDAP. We will profit from the scalability and data management facilities of X.500, while integrating with LDAP thus allowing lost cost participation in the system.
This hybrid approach is manifest in two aspect of the design:
The PRIDE Directory will consist of inter-connected X.500 DSAs and LDAP servers. Our approach is to use X.500 to provide a scalable and manageable DIT. Then at particular points in the tree we will register LDAP servers. X.500 client (DAP) requests which resolve to those points in the tree will be transparently forwarded to the relevant LDAP servers for resolution.
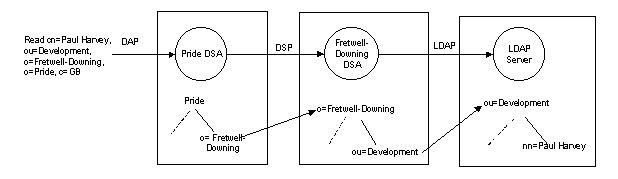
Figure 2 - Integration of LDAP and X.500 in the PRIDE
Directory
In Figure 2 we can see a DAP read request made by an X.500 user agent for the entry:
cn=Paul Harvey, ou=Development, o=Fretwell-Downing, o=PRIDE, c=GB
The bound DSA has knowledge indicating that this entry may be found in the Fretwell-Downing DSA. A DSP request for the entry is sent to the second DSA. This DSA is able to gateway between X.500 and LDAP. It is configured to resolve requests for ou=Development in a local LDAP server. The read request in the DSP is transformed into an equivalent LDAP request that is sent to the appropriate LDAP server. Any results follow the mirror path and translations (LDAP->DSP->DAP) to the original request and are presented to requesting DUA.
In as far as possible a neutral directory access SDK will be used to implement the PRIDE demonstrator.
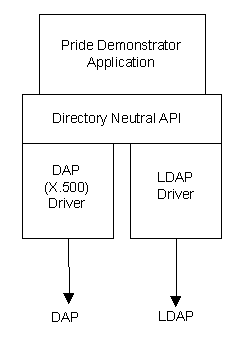
Figure 3 - The PRIDE Directory Neutral SDK
This will provide a simple and consistent LDAP-style [LDAP2] API for developing both LDAP and DAP based applications. Thus it should be possible with minimal effort to deploy our tools in different directory scenarios.
One of the most important outcomes of the consolidated design phase will be the schema for the PRIDE Directory. This will build on international standards that specify schema for X.500 directory systems [X.520][X.521][LDAP3]. Additional schema classes will be added as necessary. Where possible these will be sub-classes of those standard classes already defined.
The PRIDE Directory schema will cover the following broad areas:
This section introduces the mechanisms for interaction with the PRIDE Directory. Primarily there are two classes of access mechanism:
The PRIDE Universal Client (PUC) will provide the primary administrative and end user access route to the demonstrator.
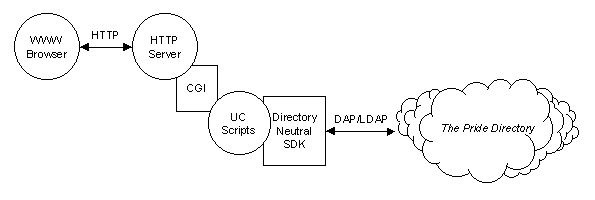
Figure 4 - Architecture of the PRIDE Universal Client
As depicted in Figure 4 the PUC will be accessible through any standard WWW browser. It will be implemented as a set of CGI scripts which build upon our directory neutral SDK in order to access the PRIDE Directory.
The most important feature of the PUC to note is that it is not intended to be a generic directory user agent. Rather, it will provide a task-specific interface. By this we mean that, for example, in order to register a service with PRIDE a user will be presented with a particular service registration screen rather than a generic interface to edit whatever objects may be required in the directory to properly register that service.
The PUC will provide the following areas of functionality:
The PRIDE demonstrator will provide CORBA [CORBA] access to the directory. This is of relevance as CORBA technology provides the most likely candidate for the future common integration technology to be used as the glue in the development of distributed systems.
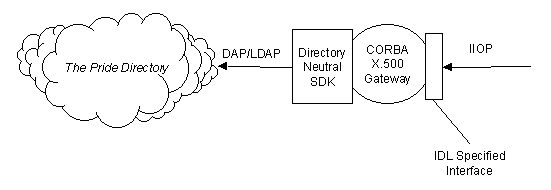
Figure 5 - CORBA Access to the PRIDE Directory
In this respect PRIDE will build on work carried out in the ACTS GAIA project [GAIA].
Figure 5 shows how we will provide an interface, defined using the CORBA Interface Definition Language (IDL), onto software which gateways to our directory neutral SDK and hence onto the PRIDE Directory itself.
The PRIDE project is considering the implementation of a Z39.50 to PRIDE Directory gateway.
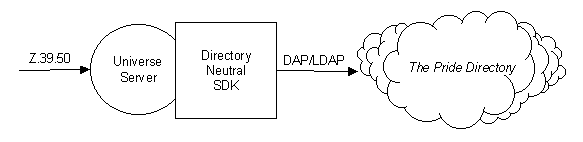
Figure 6 - The Z39.50 to PRIDE Directory gateway.
The purpose of this gateway is to provide a mechanism to directory enable existing software which can already interact with Z39.50 targets. Specifically we are considering Fretwell-Downing's library system clients as part of the final integrated demonstrator. Further design and investigation will be undertaken in order to determine whether the gateway approach is the most appropriate.
The gateway will be developed from the results of the Universe Telematics project [UNIVERSE].
As the PRIDE Directory natively supports both DAP and LDAP (and supports Z39.50 via a gateway), generic access is possible via any appropriate standard client.
The PRIDE demonstrator will implement a number of automated agents. These will be responsible for automatic population of the directory from other sources, automatic reforming of the DIT to produce useful shadow structures and for issuing alerts based on SDI profiles.
PRIDE agents will be developed using the PRIDE agent toolkit.
The PRIDE agent toolkit will provide a scriptable interface onto the directory. This will then allow the straightforward implementation, experimentation and customisation of agent software.
The PRIDE agent toolkit will be implemented as a Perl [PERL] layer on top of our Directory neutral SDK. This provides the immediate benefits of a powerful scripting language and flexible access to the PRIDE Directory.
The Curator agent is responsible for crawling the PRIDE Directory in order to build and to organise other useful structures within the directory. It will, of course, be built using the PRIDE agent toolkit.
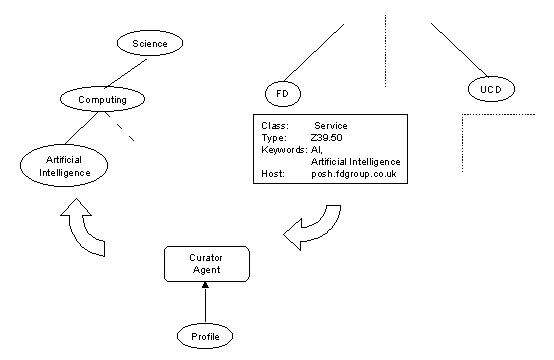
Figure 7 - The Curator Agent
Our aim here is to enable the automatic maintenance of references to related services. In the PRIDE scenario we have many services whose descriptions are registered and maintained in a widely distributed directory.
Now, say for example, I am interested in Z39.50 targets that contain information regarding "Artificial Intelligence". I could use the PRIDE Universal Client to search the entire directory tree (high level X.500 DSAs permitting1) for appropriate services. However this would be slow and inefficient and cannot support browsing for relevant services.
Instead, we define a set of nodes under which clumps of related services may be registered. This registration may take place on a service-by-service basis via the Universal Client. Alternatively the PRIDE Curator will, based on a configurable profile, trawl the directory and will build alternative shadow trees grouping related services.
So we have a combination of manual and automatic collection of service clumps - allowing efficient searching, browsing and dynamic discovery of resources.
The PRIDE alerting agent is responsible for informing users and administrators of interesting additions and modifications to the information contained in the directory.
The meaning of interesting is defined by SDI profiles that are themselves contained in the directory and are configurable via the PRIDE Universal Client. Notification may take place either via an Email message or through the PRIDE Universal Client.
The PRIDE Explain harvester is responsible for the automatic creation of Z39.50 server records in the directory. In order to do this it will query target's standard Z39.50 Explain databases to build a service record that it will then store in the directory.
The PRIDE RDF harvester [RDF] will trawl selected areas of the Web, retrieving RDF-based descriptions of individuals, organisations, networked services, clumps and other resources. It will use the information to automatically populate the PRIDE Directory with records describing those objects. This work will use the directory schemas developed above as the basis for RDF schemas, defined using the RDF Schema Definition Language [RDFS].
The RDF Harvester will provide an indirect way for end-users to provide information to the PRIDE demonstrator and aligns the PRIDE project closely with the current metadata work of the W3C. It will be based on current development of the Harvest suite of resource discovery tools [HARVEST].
In PRIDE, a proxy is a piece of software that offers an enhanced level of service as a result of directory integration. The demonstrator will include a Z39.50 proxy, which will use the directory for target selection and query routing. In the light of this experience we may then go on to implement an ISO ILL [ILL] system which will use the directory for location and policy information.
The PRIDE Z39.50 will make use of data in the directory in order to provide an enhanced level of service.
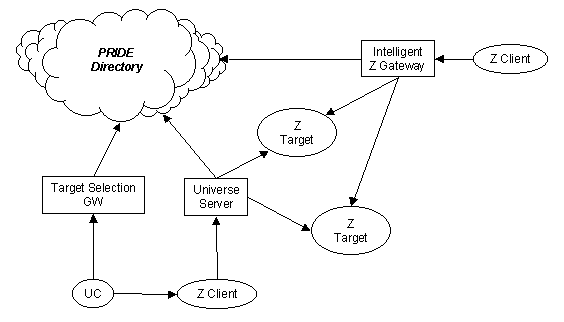
Figure 8 - The Z39.50 Proxy
With reference to Figure 8, we are considering 3 operational scenarios.
In the first scenario, the PRIDE Universal Client (PUC) is used to locate an interesting set of targets. This may be done either by browsing or searching the directory and may make reference to clumps of services (which may themselves have been automatically collected by the Curator agent). The user may then select from this set of possible targets and have their selection passed on to a Z39.50 client for use in subsequent queries.
In the second scenario, a modified a directory enabled version of the Z39.50 parallel search gateway developed in the Universe Telematics project is used. It is configured to read its set of available targets from a configurable location in the PRIDE Directory. The information in the directory is one of the clumping points as in the first scenario. Hence the server can dynamically discover and present relevant lists targets to the user. The server can act as a subject gateway for any standard Z39.50 client.
The third, and most experimental, scenario again involves a modified version of the Universe Z39.50 parallel search gateway. In this version, the Universe server uses properties of queries it receives to intelligently route to relevant targets. The intelligent routing is, of course, based on information held in the directory, for example forward knowledge about the contents of each target and the attribute sets, schema and record syntaxes supported. This may be combined with information obtained from the user's interest profile.
The subject gateway functionality (as exemplified in the first two scenarios) will be supported in the PRIDE demonstrator. The viability of the intelligent query routing mechanism described in the third scenario is not confirmed and will be further explored as a low priority item during the detailed software design and development phase of the project.
The PRIDE project will allow an ILL system to obtain relevant location information from the directory service. Our work here will build on the outcome of the DALI project [DALI] and the Universe Telematics projects.
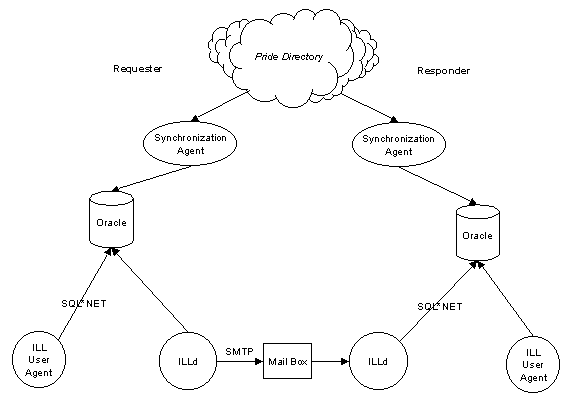
Figure 9 - The ILL Proxy
The most highly functional approach to take here would be to directory-enable the ILL system, thus implementing a true proxy. However the structure of the base software on which we will build makes this approach too costly for the project timescales. Instead we will implement a synchronisation agent which will replicate the master location information held in the PRIDE Directory into the local databases used by the ILL software. This synchronisation agent will be built using the PRIDE agent toolkit.
| 1999-02-26 |
PRIDE Architecture and Interfaces &
PRIDE Logical Components and Integration Designs |