Work Package 2 of Telematics for Libraries project PRIDE (LB 5624)

Title page
Table of Contents
|
PRIDE Requirements and Success Factors
Work Package 2 of Telematics for Libraries project PRIDE (LB 5624) |
Title page Table of Contents |
SGML is the Standard Generalised Markup Language, the international standard for defining descriptions of the structure and content of different types of electronic document. Essentially, SGML is a method for creating interchangeable, structured documents. It allows one to:
SGML is based on the concept of document being composed of a series of entities. Each entity can contain one or more logical elements. Each of these elements can have certain attributes (properties) that describe the way in which it is to be processed. SGML provides a way of describing the relationships between these entities, elements and attributes, and tells the computer how it can recognise the component parts of a document.
SGML requires users to provide a model of the document being produced. This model, called a Document Type Definition (DTD), describes each element of the document in a form that the computer can understand. The DTD shows how the various elements that make up a document relate to one another.
To allow the computer to correctly identify where each part of a document starts and ends SGML requires that the user declares, in an SGML Declaration, how the computer is to identify markup, and what codes have been used to identify and delimit markup sequences.
There are four general classes of tools in an SGML system, namely Editors, Conversion Tools, Document Managers, and Formatters.
DSSSL (Document Style Semantics and Specification Language) is an International Standard, ISO/IEC 10179:1996, for specifying document transformation and formatting in a platform- and vendor-neutral manner. In particular, DSSSL can be used to specify the presentation of documents marked up according to the SGML standard.
DSSSL consists of two main components: a transformation language and a style language. The transformation language is used to specify structural transformations on SGML source files. For example, a telephone directory structured as a series of entries ordered by last name could, by applying a transformation spec, be rendered as a series of entries sorted by first name instead. The transformation language can also be used to specify the merging of two or more documents, the generation of indices and tables of contents, and other operations. While the transformation language is a powerful tool for gaining the maximum use from document databases, the focus in early DSSSL implementations will be on the style language component.
Within the style language, it is possible to identify a number of capabilities that for one reason or another should be considered optional for early implementations. Recognising this, the designers of DSSSL designated certain features of the style language as optional and created a Core Query Language and a Core Expression Language specifically in order to make more limited implementations possible. However, they did not define any particular subset of the style language component within the standard itself, but rather left that task to industry organisations and standards bodies.
SP <URL:http://www.jclark.com/sp/index.htm> for SGML parsing and entity management. Here is a brief summary of its features:
SP and Jade can be used for conversion of SGML documents into other formats, such as XML, RTF, TeX, MIF, as well as to perform SGML transformations.
XML is an abbreviated version of SGML, to make it easier to define custom document types, and to make it easier for programmers to write programs to handle them. It omits the more complex and less-used parts of SGML in return for the benefits of being easier to write applications, easier to understand, and more suited to delivery and interoperability over the Web. But it is still SGML, and XML files may still be parsed and validated the same as any other SGML file.
XML is designed "to make it easy and straightforward to use SGML on the Web: easy to define document types, easy to author and manage SGML-defined documents, and easy to transmit and share them across the Web."
It defines "an extremely simple dialect of SGML which is completely described in the XML Specification. The goal is to enable generic SGML to be served, received, and processed on the Web in the way that is now possible with HTML."
"For this reason, XML has been designed for ease of implementation, and for
interoperability with both SGML and HTML."
<URL:http://www.w3.org/TR/REC-xml]>
The Hypertext Mark-up Language (HTML) covers a set of standards defining document type definitions (DTD) corresponding to the various "official" versions of HTML. The standardisation procedure is W3C based though a number of Internet Drafts and RFCs represent the earlier evolution of HTML.
The latest W3C recommendation is HTML 4.0, which includes support for style sheets, frames, tables and forms. Internationalisation and accessibility issues are also represented in its design.
Although focus for the future has turned to XML, HTML will still be a key part of the web for some time. Notable developments in the evolution of HTML are covered below.
Forms where introduced in HTML 2.0 to interoperate with the CGI standard. A form is a template for a form data set (data captured by the browser which is sent to the server), an associated method (the HTTP method for uploading to the server) and an action URI (a reference to a server program that will process the form). The form data set is a sequence of name/value pairs, specified using form INPUT elements. Form submission usually results in the data set being transferred to the web server for processing.
Broadly, the META element can be used to identify properties of a document (e.g. author, expiration date, a list of keywords etc.) and assign value to those properties. Each META element specifies a name/value pair using the attributes name and content. Such usage is often used to provide keywords for indexing purposes, for example:
<META name="keywords" lang="en" content="national centre, network information support">
Note that in cases where the value for some property is a reference outside the document itself, the LINK element may be used, i.e. the following are equivalent:
<META name="DC.identifier" content="ftp://ds.internic.net/rfc/rfc1866.txt">
<LINK rel="DC.identifier" type="text/plain" href="ftp://ds.internic.net/rfc/rfc1866.txt">
Alternatively the http-equiv attribute can be used in place of the name attribute to create a header in the HTTP response. The value of the name attribute specifies the header name and the value of the content attribute its value. For example:
<META http-equiv="Expires" content="Sat, 31 Oct 1998 13:00:00 GMT">
will produce the following HTTP response header:
Expires: Sat, 31 Oct 1998 13:00:00 GMT
Some user-agents support the use of the refresh value for the http-equiv attribute to implement a simple form of client-pull.
The lang attribute can be used within the META element (as it can in many other HTML 4.0 defined elements) to specify the (human) language of the content attribute (this could be used, for example, for speaking browsers to pronounce words in various languages correctly).
The scheme attribute provides user agents with a context in which to interpret metadata. For example, to differentiate between different formats or to specify types of identifier. For example:
<META scheme="Month-Day-Year" name="date" content="08-24-98">
The META element may also be used to specify the defaults for scripting language, style sheet language and document character encoding.
The HEAD element may contain the profile attribute to specify the location of a metadata profile. Its value is a URI that is used by a user agent. Actions may then be taken by the user agent based upon definitions within the (dereferenced) profile.
Image maps are inline images that include "hotspots" that operate like hyperlinks. An image map has three components: an image, appropriate HTML to specify an image map and map data.
Server-side maps appeared first, where maps are interpreted by the web server (i.e. the browser sends the server a set of coordinates corresponding to the clicked image region). Client-side maps have largely replaced these, where the map data is stored within HTML and the browser interprets the map. With the introduction of Java support within browsers, there is also the possibility of Java-based image maps.
HTML 3.2 implemented a widely deployed subset of the specification given in RFC 1942 - "HTML Tables" and can for the mark-up of tabular material or for layout purposes (although with the recent advent of style sheets and various accessibility issues this type of use is discouraged).
Frames were not an official HTML standard until the W3C HTML 4.0 specification but were deployed as browser extensions to the Netscape browser (and also later implemented by Microsoft Internet Explorer). Frames enable browser windows to be split into multiple independently scrollable windows with separate objects in each window.
Support was introduced in the Netscape browser for the JavaScript scripting language developed by Netscape and Sun Microsystems. Javascript offered client-side scripting embedded within HTML and could be used to develop simple applications and to enhance user interfaces. Later Microsoft developed a version of JavaScript known as Jscript and provided support for Jscript and VBScript within their browser. Interoperability concerns prompted the standardisation of a scripting language by ECMA and the ECMAScript Language Specification was released in June 1997.
Initially, the scope of such object-oriented scripting languages within the HTML framework was limited due to the lack of an object model for the HTML language. The Document Object Model (DOM), developed by the W3C, addresses this issue by providing a non-proprietary API to a standard set of objects representing HTML and XML documents.
Dynamic HTML (DHTML) refers to the use of a scripting language within the DOM to remove previous restraints on functionality. DOM also addresses the inclusion of objects such as Java applets and ActiveX controls.
Style sheets were introduced to address the problem of layout within a document (since custom layout was not originally a concern of HTML). Cascading Style Sheets 1 (CSS1) was an initial W3C recommendation, but was only partly supported by Microsoft Internet Explorer. CSS2, released as a W3C recommendation in May 1998, provides a great deal of control over document appearance.
Flat HTML files were traditionally entirely written by hand. This results in problems such as invalid HTML (i.e. non-conformance to a DTD) and so the use of an HTML is generally recommended, a number of which a number now exist (including WYSIWYG systems). An editor can also better deal with large or complicated documents, provide versioning control and generate complex scripts. Packages such as Microsoft FrontPage integrate with a Microsoft server to provide many useful administrative and functional features.
HTML documents are traditionally stored as files accessible to server software that can serve resources via HTTP. There is however increasing use of storing (perhaps fragmented) HTML in a "back-end" database and serving the results of some database query to the client.
Prior to transfer of a document, scripting may be undertaken by the server to generate HTML (or other resources) which may entirely comprise what is served or add to other resources. Different servers (and platforms) may implement different kinds of server-side scripting, for example PHP, SSI and mod Perl under the UNIX apache server and ASP for Microsoft servers.
The CGI standard is also implemented server-side. On receiving a data set from a client, the server may operate on this and return a document, usually dynamically generated from the results of processing the data set. Java-based technologies may be used to provide richer functionality than CGI but at the cost of being more complicated to implement.
A web browser usually requests an HTML document from a server using the HTTP protocol. After receiving the contents (which may have been dynamically generated server-side), the browser can then process any objects such as scripts or style sheets (which may result in a client-side dynamic document).
A cache or proxy may bridge the route between client and server. It is possible that resources may be altered or generated at this stage.
Push technologies have recently become popular, where the traditional request-response paradigm is replaced by automatic delivery of resources to a suitable client (for example, news reports may be delivered to an "active desktop"). This may include HTML documents.
As the users of the Web continue to grow and become more diverse, various communities will have different abilities and skills. It is important to recognise that HTML needs to reflect this, for example being more accessible to those with disabilities. HTML 4.0 addresses a number of such issues, however much is down to the author of documents and guidelines exist covering the creation of accessible HTML.
Internationalisation issues are important for creating a functional international Web. Issues broadly split into:
How characters within the text (not mark-up) should be able to represent non-western alphabets
Explicitly defining the language for a segment of text.
HTML 4.0 includes a number of internationalisation features and incorporates RFC2070. Features include support for rendering text written right to left and the LANG attribute for many HTML elements used to specify language. There are also features for specifying the character encoding of a document. Importantly, the ISO/IEC:10646 has been adopted as the document character set for HTML. This standard deals most inclusively with issues of representing international characters, text direction, punctuation and other world language issues.
Standards were initially deployed via Internet drafts and RFCs. Later the standardisation procedure became W3C recommendation based. Standards are not necessarily fully adhered to by browser manufacturers.
PRIDE will obviously be using HTML. Issues that may arise with this use include:
The W3C is now looking at the next generation of HTML. There is demand for HTML to provide support for television and mobile devices and to integrate more closely with database applications. It is considered that XML will provide the foundation for further HTML development.
There is work on defining HTML as a modular application of XML. Modularity will allow the integration of HTML with specialised tag sets for various applications (e.g. Maths) and to define profiles tailored to different device capabilities. There would also be back compatibility with previous HTML versions. Interoperability is also a key concern and this may be achieved with tools to transform documents into a form suitable for different browsers (e.g. transformed at an intermediate proxy). Core HTML elements would be complemented by modular specialised domain element sets. Accessibility, Internationalisation and standards issues would continue to be reflected in HTML development.
World Wide Web Consortium, <URL:http://www.w3.org>
Internet Engineering Task Force, <URL:http://www.ietf.org>
XML, <URL:http://www.w3.org/XML/>
HTML specifications and history, <URL:http://www.w3.org/MarkUp/>
RFC 1942: HTML Tables
JavaScript, <URL:http://developer.netscape.com/docs/manuals/index.html?content=javascript.html>
JScript
VBScript
ECMAScript
DOM, <URL:http://www.w3.org/Press/1998/DOM-REC/>
Java, <URL:http://java.sun.com/>
ActiveX
Style sheets, <URL:http://www.w3.org/Style/>
HTTP, <URL:http://www.w3.org/Protocols/>
HTTP-NG, <URL:http://www.w3.org/Protocols/HTTP-NG/>
PHP, <URL:http://www.php.net/>
Apache, <URL:http://www.apache.org/>
Microsoft IIS, <URL:http://www.microsoft.com/>
The Resource Description Framework (RDF) is being developed by the W3C as a metadata framework that can be used by a variety of application areas such as: resource discovery, site-maps, Web collections, content rating, e-commerce and rights management, collaboration, privacy and Web-site management. RDF has been developed over the last year or so as part of the W3C's Metadata Activity and has received input from several communities including those working on content rating using PICS, Web collections, digital libraries (particularly the Dublin Core initiative), digital signatures (DSig) and Web privacy (P3P). RDF provides a generic metadata architecture that can be expressed in XML. The ultimate aim is that a machine understandable Web of metadata will be developed across a broad range of application and subject areas.
RDF is based on a mathematical model that provides a mechanism for grouping together sets of very simple metadata statements known as `triples'. These triples formally consist of a subject, a predicate and an object. The subject is the resource being described. The resource may be a Web page, a part of a Web page or a collection of pages (e.g. a whole Web-site). A resource may also be an object that is not directly accessible using the Web, for example a book. All resources described using RDF must be assigned a URI. The predicate is a property of the resource. The property is some aspect, attribute or characteristic used to describe a resource. The object is the value of the property. The value may be a literal (a string or number) or it may be some complex structure represented by other RDF triples.
The RDF model is often represented using node and arc diagrams. However, in order that RDF can be processed by computers, a serialisation syntax has been developed using the Extensible Markup Language (XML-RDF). A very simple example follows:
<rdf:RDF>
<rdf:Description about="http://www.ukoln.ac.uk/">
<Title>The UKOLN Home Page</Title>
</rdf:Description>
</rdf:RDF>
This XML-RDF represents the sentence, `The UKOLN Home Page is the title of the
resource
http://www.ukoln.ac.uk/.
The RDF model requires the semantics of metadata to be defined in an RDF schema. The schema allows software to take actions on RDF such as validation, mapping and value prompts. The RDF Model and Syntax Working group of the W3C are developing the RDF data model. The RDF Schema Working Group are developing an RDF Schema Definition Language.
Several tools and software toolkits are beginning to be developed that support the creation and manipulation of RDF. These include:
Reggie is a metadata editor that can output metadata in various formats, including XML-RDF. Reggie is implemented as a Web application using Java. Reggie allows the use of a schema to specify that structure of the metadata to be created. New schemas can be developed and referred to by URL within the editor. Reggie is being developed by DSTC.
DC-dot is a Web-based Dublin Core generator that automatically extracts metadata from a resource and then presents it for editing. DC-dot outputs Dublin Core in various formats including XML-RDF. DC-dot is being developed by UKOLN.
SiRPAC is an RDF parser and compiler by Janne Saarela (W3C). It is written in Java. The SiRPAC compiler takes XML-RDF and generates the RDF triples of the underlying data model.
RDF for XML is "a Java implementation of the RDF specification for creating technologies that search for, describe, categorize, rate, and manipulate data". RDF for XML is being developed by IBM Alphaworks.
The Resource Description Framework (RDF) Model and Syntax Specification and the Resources Description Framework (RDF) Schema Specification are both in the "last call" phase of W3C working draft documents.
The Dublin Core Data Model Working Group has been developing a data model for Dublin Core based on RDF. An example of the anticipated syntax for representing Dublin Core within RDF is given in the Dublin Core section of this document.
All metadata related activity within the W3C will be based on RDF from now on. It is expected that many other activities (for example the DOI developments related to metadata) will also use RDF as the basis for their work.
RDF Model and Syntax Specification, <URL:http://www.w3.org/TR/WD-rdf-syntax/>
RDF Schema Specification, <URL:http://www.w3.org/TR/WD-rdf-schema/>
Reggie, <URL:http://metadata.net/dstc/>
DC-dot, <URL:http://www.ukoln.ac.uk/metadata/dcdot/>
SiRPAC, <URL:http://www.w3.org/RDF/Implementations/SiRPAC/>
RDF for XML, <URL:http://www.alphaworks.ibm.com/formula/rdfxml/>
Dublin Core Data Model Working Group, <URL:http://purl.org/dc/groups/datamodel.htm>
A Uniform Resource Identifier (URI) is a short string of characters that identifies a resource (in the abstract or physical sense). A URI provides a simple and extensible means for identifying a resource that can then be used within applications. The specification is derived from concepts introduced by the World Wide Web [RFC1630 - "Universal Resource Identifiers in WWW"] and builds upon previous notions such as URLs. URIs are a superset of Uniform Resource Locators (URLs), Uniform Resource Names (URNs) and Uniform Resource Citations or Uniform Resource Characteristics (URCs).
The URI specification implements the recommendations of RFC1736 - "Functional Recommendations for Internet Resource Locators" and RFC1737 - "Functional Requirements for Uniform Resource Names".
The following definitions from RFC2396 characterise the URI:
Uniform
The uniformity of URIs provides several benefits:
It allows different types of resource identifiers to be used in the same context (even though the mechanisms used to access the resources may differ).
It allows uniform semantic interpretation of common syntactic conventions across different types of resource identifiers (e.g. URLs start with a scheme representing the method of network access).
It allows the introduction of new types of resource identifiers without interfering with the way that existing identifiers are used.
It allows the use of identifiers to be reused in different contexts (this permitting new applications or protocols to leverage a pre-existing set of resource identifiers).
Resource
A resource is anything with identity, not necessarily network accessible. The term `resource' refers to the concept of the identified entity, so that a resource can remain fixed even when its content changes (for example, a noticeboard). An identified resource may not be instantiated at a given time.
Identifier
An identifier is an object that acts as a reference to something that has identity. For URIs, the object is a set of characters conforming to the URI syntax.
A Uniform Resource Identifier may be a locator, a name or a metadata resource.
URLs identify resources via a representation of their access mechanism (usually network location) rather than by any other attribute of the resource. URLs have the most varied use of the URI syntax and often have a hierarchical namespace. A major disadvantage of URLs is that they confuse the name of a resource with its location. In the larger Internet information architecture URLs will act only as locators.
Whereas a URL identifies the location or container for an instance of a resource, a URN identifies the resource. The resource identified by a URN may reside in one or more locations, may move, or may not actually be available at a given time.
The URN has two interpretations, the first is as a globally unique and persistent identifier for a resource (achieved though an institutional commitment) that is accessible over a network; the second is as the specific `urn' scheme which will embody the requirements for a standardised URN namespace [RFC2141 - "URN Syntax"]. Such a scheme will resolve names that have a greater persistence that that currently associated with URLs.
RFC1737 - "Functional Requirements for Uniform Resource Names" identifies the following requirements for a URN:
The internet draft "URC Scenarios and Requirements" defines the URC:
"The purpose or function of a URC is to provide a vehicle or structure for the representation of URIs and their associated meta-information".
Initially, URCs where the intermediate that associated a URN with a set of URLs that could then be used to obtain a resource. Later it was decided that metadata should also be included so that resources could be obtained conforming to a set of requirements. Although work has been carried out by the URC-WG, URCs are still not in existence.
URCs are descriptions of resources available via a network. Such a resource may have any number of locations. URCs provide a standard scheme for sites to provide descriptions, rather than relying on a central URC service. Because URCs are likely to describe a wide range of resources, there is no core set of descriptive attributes (such as author, title etc.). URC standards encourage the development of URC subtypes which are description schemes suited to particular domains.
Persistent URLs, or PURLs, were developed by OCLC as an interim naming and resolution system for the Web. PURLs increase the probability of correct resolution and thereby reduce the burden and expense of catalog maintenance.
A PURL is a URL. However, a PURL refers to a resolution service, which maps the PURL to a URL and returns this to the client. On the Web, this is a standard HTTP redirect.
Internet addressing standards are IETF based. A number of other standards may form part of private conventions.
PRIDE may want to look at how URNs could be used within its architecture.
RFC1630: Universal Resource Identifiers in WWW
RFC1736: Functional Recommendations for Internet Resource Locators
RFC1737: Functional Requirements for Uniform Resource Names
RFC2141: URN Syntax
RFC2396: Uniform Resource Identifiers (URI): Generic Syntax
W3C addressing page, <URL:http://www.w3.org/Addressing/>
TURNIP, the URN Interoperability Project, <URL:http://www.dstc.edu.au/RDU/TURNIP/>
DOI Foundation, <URL:http://www.doi.org>
PURL homepage, <URL:http://purl.oclc.org>
The Digital Object Identifier (DOI) has been developed by the International DOI Foundation (IDF) on behalf of the publishing community to provide an identifier for intellectual content in the digital environment. Its goals are to provide a framework for managing intellectual content, link customers with publishers, facilitate electronic commerce, and enable automated copyright management.
The DOI system has two main parts (the identifier and a directory system) and a third logical component, a database.
The identifier has two parts, a globally unique part called the prefix and a publisher assigned part called the suffix. For example, the DOI
10.153/34571has a prefix of `10.153' and a suffix of `34571'. The prefix is assigned by a DOI agency. Separate publisher imprints will be identified by extending the prefix -- prefix `10.153' might have imprints `10.153.2' and `10.153.11.4' for example. Prefixes begin with a code - `10' in the above example - to indicate the agency that allocated them. Currently there is only one agency. The suffix is assigned by the publisher and will be unique to them. It can be any string of printable characters and can be composed of another identifier, such as a SICI, if necessary.
The DOI system is based on a distributed central directory. Currently DOIs are usually embedded into URLs. When a user clicks on such a URL, a message is sent to the DOI directory where the URL associated with that DOI is stored. This location is sent back to the user's Internet browser as an HTTP redirect -- a special message telling the browser to "go to this particular URL".
The underlying technology for the DOI directory is the Handle resolution system developed by the Corporation for National Research Initiatives (CNRI). The Handle System is a distributed system that stores names (handles) of digital objects and which can resolve those names into locators (URLs) to access the objects. The system is global and general purpose and is used over networks such as the Internet. The Handle system is currently in use in a number of other prototype projects.
Information about an object that is identified by a DOI is maintained by the publisher. However, it is planned that the DOI system will also collect some minimum level of associated metadata to enable provision of automated, efficient services such as look-up of DOIs from bibliographic data, citation linking, and so forth.
It is currently difficult to determine how widespread the implementation of the DOI is. However, IDF members include major industry players in a range of technology and content industries. The Board of the Foundation, elected by and from the membership, currently consists of the Association of American Publishers, International Publishers Association, International Association of STM Publishers, Authors Licensing and Collecting Society, Elsevier Science, European Music Rights Alliance, Microsoft, New England Journal of Medicine, and Wiley.
DOIs are currently embedded into Web pages as URLs. In this way they can be resolved using any Web browser. A Handle browser plug-in is also available which can resolve DOIs directly. Some experimental work has also been done, encoding DOIs as URNs and resolving them using HTTP proxy servers.
The DOI syntax is being standardised within NISO. The IDF is also working closely with ISO (the ISWC working group) and with the URN working group of the IETF. In its discussions about metadata, the IDF is working with the Dublin Core initiative and the W3C RDF working group.
The DOI is closely related to other bibliographic identifiers such as the ISBN, ISSN and SICI. It is currently used in the form of a URL and is resolved in a very similar way to the Persistent URL (PURL).
One aspect of the DOI that is currently under discussion within the IDF is the issue of what metadata about the objects identified by a DOI should be held within the DOI directory. This discussion is bringing together several interested parties, including representatives of the Dublin Core initiative, the W3C RDF working group, publishers and copyright licensing agencies. Some of this discussion is likely to take place within the framework of the European funded Interoperability of Data in E-Commerce Systems (INDECS) project.
* International DOI Foundation, <URL:http://www.doi.org/>
MPEG-7, which is a work in progress at the moment, will be a standardised description of various types of multimedia information. This description will be associated with the content itself, to allow fast and efficient searching for material that is of interest to the user. MPEG-7 is formally called `Multimedia Content Description Interface'.
MPEG-7 is intended to extend the limited capabilities of proprietary solutions in identifying multimedia content that exist today, notably by including more data types. MPEG-7 will specify a standard set of descriptors that can be used to describe various types of multimedia information. MPEG-7 will also standardise ways to define other descriptors as well as structures (Description Schemes) for the descriptors and their relationships.
"This description (i.e. the combination of descriptors and description schemes) shall be associated with the content itself, to allow fast and efficient searching for material of a user's interest. MPEG-7 will also standardise a language to specify description schemes, i.e. a Description Definition Language (DDL). AV material that has MPEG-7 data associated with it, can be indexed and searched for. This `material' may include: still pictures, graphics, 3D models, audio, speech, video, and information about how these elements are combined in a multimedia presentation (`scenarios', composition information). Special cases of these general data types may include facial expressions and personal characteristics." [0]
The MPEG-7 standard builds on other representations such as analogue, PCM, MPEG-1, -2 and -4. One functionality of the standard is to provide references to suitable portions of them. For example, perhaps a shape descriptor used in MPEG-4 is useful in an MPEG-7 context as well, and the same may apply to motion vector fields used in MPEG-1 and MPEG-2.
MPEG-7 descriptors do not depend on the ways the described content is coded or stored. It is possible to attach an MPEG-7 description to an analogue movie or to a picture that is printed on paper. Even though the MPEG-7 description does not depend on the (coded) representation of the material, the standard in a way builds on MPEG-4, which provides the means to encode audio-visual material as objects having certain relations in time (synchronisation) and space (on the screen for video, or in the room for audio). Using MPEG-4 encoding, it will be possible to attach descriptions to elements (objects) within the scene, such as audio and visual objects. MPEG-7 will allow different granularity in its descriptions, offering the possibility to have different levels of discrimination.
The same material can be described using different types of features, tuned to the area of application. To take the example of visual material: a lower abstraction level would be a description of e.g. shape, size, texture, colour, movement (trajectory) and position (`where in the scene can the object be found?). And for audio: key, mood, tempo, tempo changes, position in sound space. The highest level would give semantic information: `This is a scene with a barking brown dog on the left and a blue ball that falls down on the right, with the sound of passing cars in the background.'
MPEG-7 will address applications that can be stored (on-line or off-line) or streamed (e.g. broadcast, push models on the Internet), and can operate in both real-time and non real-time environments.
The standardisation of audio-visual content recognition tools is beyond the scope of MPEG-7. In developing the standard, however, MPEG might build some coding tools for research purposes, but they would not become part of the standard itself.
The MPEG-7 standard is being developed by Moving Picture Experts Group (MPEG). At this stage, the requirements have been defined and an open Call for Proposals <URL:http://drogo.cselt.stet.it/mpeg/> . technologies and systems tools are due on 1 February 1999 in accordance with the instructions in the MPEG-7 Proposal Package Description (PPD) <URL:http://drogo.cselt.stet.it/mpeg/public/w2464.html>.
The preliminary work plan for MPEG-7 foresees:
The Dublin Core (DC) is a fifteen element metadata set that was originally developed to improve resource discovery on the Web. To this end, the DC elements were primarily intended to describe Web-based `document-like objects'. More recently the scope of DC has expanded to include off-line electronic resources and other objects, museum artefacts for example. The Dublin Core effort is developing mechanisms for describing the relationships between such resources.
The Dublin Core originated at a meeting organised by OCLC in Dublin, Ohio attended by representatives of the library, museum and research communities and commercial Web software developers. Since then there have been 4 follow-up meetings in the Dublin Core workshop series, the most recent being in Helsinki, Finland late in 1997. A sixth workshop is planned for Washington DC, known as DC-DC, in November 1998. Between workshops, Dublin Core discussion continues via email. The main DC related mailing list currently has more than 400 subscribers.
The fifteen DC elements and a very brief description of their semantics follow:
Title
|
the
title of the resource
|
Subject
|
simple
keywords or terms taken from a list of subject headings
|
Description
|
a
description or abstract
|
Creator
|
the
person or organisation primarily responsible for the intellectual content of
the resource
|
Publisher
|
the
publisher
|
Contributor
|
a
secondary contributor to the intellectual content of the resource
|
Date
|
a
date associated with the creation or availability of the resource
|
Type
|
the
genre of the resource (home page, thesis, article, journal, data-set, etc.)
|
Format
|
typically
a MIME type (e.g. text/html)
|
Identifier
|
a
URL, DOI, ISBN, ISSN, URN or other identifier
|
Source
|
the
resource from which the current resource was derived
|
Language
|
the
language of the resource
|
Relation
|
an
identifier of a second resource and its relationship to the current resource
|
Coverage
|
the
temporal or spatial characteristics of the resource (e.g. 18 century UK)
|
Rights
|
a
simple rights statement about the resource
|
All of the elements are both optional and repeatable. A minimal DC record may therefore contain only one or two of the above elements. If necessary an element may be repeated, to indicate multiple authors for example. The values of several elements may be taken from enumerated lists. In some cases, these lists already exist, in others lists are being developed as part of the Dublin Core effort.
The semantics of some of the elements are defined very broadly. For example, the date element is simply defined as "a date associated with the creation or availability of the resource" and the relation element as "an identifier of a second resource and its relationship to the present resource". It is possible to refine the meaning of the elements using an 'element' qualifier:
Date DateType=Valid
Relation RelationType=IsPartOf
It is also possible to qualify the value of an element using a 'value' qualifier. For example, to associate an externally defined `scheme' (for example a controlled vocabulary or specific syntax) with element values:
Subject SubjectScheme=LCSH
Date DateScheme=ISO 8601
Dublin Core that makes use of `element' and `value' qualifiers is known as `Qualified DC'. Dublin Core that does not is often referred to as `Simple DC'.
Much of the DC effort has gone into defining the semantics of the 15 elements and considerable cross-domain consensus has been achieved on this over the last few years. There has also been some work on syntax, particularly on the use of DC within HTML Web pages. Many DC-based projects are embedding DC metadata directly into Web pages using the HTML META tag. In this way, the metadata is directly available for collection and indexing by Web robots. For example, the DC metadata embedded into the UKOLN homepage is:
<HTML>
<HEAD>
<TITLE>UKOLN Home
Page</TITLE>
<META NAME="DC.Title" CONTENT="UKOLN: UK Office for
Library and Information Networking">
<META NAME="DC.Subject"
CONTENT="national centre, network information support, library community,
awareness, research, information services, public library networking,
bibliographic management, distributed library systems, metadata, resource
discovery, conferences, lectures, workshops">
<META
NAME="DC.Description" CONTENT="UKOLN is a national centre for support in
network information management in the library and information communities. It
provides awareness, research and information services">
<META
NAME="DC.Creator" CONTENT="UKOLN Information Services
Group">
</HEAD>
<BODY>
...
</BODY>
</HTML>
Notice that the element names, `Creator' for example, are prefixed by `DC.' to indicate that each one is a part of the Dublin Core. Many projects using Dublin Core have added extra metadata elements appropriate to their needs, using a different prefix to indicate that these elements are not part of DC.
However, there are limitations in what can be achieved using HTML META tags. It is not possible to group sets of META tags in HTML, nor is it possible to represent any hierarchical structure that may be present in the metadata. Qualified DC can be embedded, indeed many projects using Dublin Core rely on qualified DC for their resource descriptions, but there is some inconsistency in the way projects are doing this. In particular, the way in which qualified DC is embedded into HTML depends on the HTML version in use. HTML 4.0 incorporated some of the ideas from the Dublin Core and added a SCHEME attribute on the META tag, which was not present in earlier versions.
Partly because of these difficulties, DC looks likely to make use of RDF as its preferred syntax in the future and to become one of the early RDF schemas. Although the syntax for representing DC in RDF is still being developed, it is likely to be something like the following:
<rdf:RDF
xmlns:rdf=http://www.w3.org/TR/WD-rdf-syntax#
xmlns:dc="http://purl.org/dc/elements/1.0/">
<rdf:Description about="http://www.ukoln.ac.uk/">
<dc:Title>
UKOLN: UK Office for Library and Information Networking
</dc:Title>
<dc:Creator>
UKOLN Information Services Group
</dc:Creator>
<dc:Subject>
national centre, network information support, library community,
awareness, research, information services, public library networking,
bibliographic management, distributed library systems, metadata,
resource discovery, conferences, lectures, workshops
</dc:Subject>
<dc:Description>
UKOLN is a national centre for support in network information
management in the library and information communities. It provides
awareness, research and information services
</dc:Description>
<dc:Publisher>
Bath University
</dc:Publisher>
<dc:Type>
Text
</dc:Type>
<dc:Format>
text/html - 10907 bytes
</dc:Format>
</rdf:Description>
</rdf:RDF>
Early development of the Dublin Core was done informally, using a combination of face to face meetings (usually one or two per year) and mailing list discussion by a group of invited experts from around the world. Recently a formal structure, comprising a Policy Advisory Committee and a Technical Advisory Committee, has been put in place to oversee the future development of the Dublin Core. The first of five Internet Engineering Task Force Requests For Comments (IETF RFCs) has been published - RFC 2413, "Dublin Core Metadata for Resource Discovery". Work is also underway to submit the Dublin Core to NISO as a national standard, the intention being to use this as the basis for a submission to ISO.
Dublin Core Metadata Homepage, <URL:http://purl.org/metadata/dublin_core/>
RFC 2143: Dublin Core Metadata for Resource Discovery
The ISBN system was developed in 1967 (ISO standard in 1970) as an international standard numbering system for books and other monographic publications.
An ISBN always has ten decimal digits following the letters `ISBN'. The digits are divided into four parts separated by a hyphen or a space. For example:
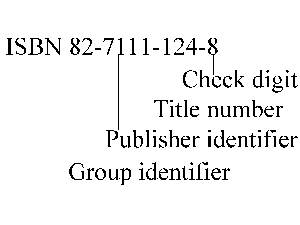
Group
identifier
|
Identifies
a country (82=Norway) or a language area (3=German, Switzerland (German part)
and Austria). May be 1-5 digits in length, depending on the number of documents
issued in the country/area.
|
Publisher
identifier
|
The
number is assigned by the national ISBN agencies and may be 2-6 digits
in length. Publishers issuing many items have short identifiers and publishers
issuing few documents have longer identifiers.
|
Title
number
|
A
unique title number assigned by the publisher.
|
Check
digit
|
A
check digit, calculated using the Modulus 11 algorithm.
|
Each ISBN is unique and should never be used for another title. If a publisher uses up all their available title numbers, a new publisher identifier will be assigned by the national ISBN agency. Each form of a publication, for example paper and CD-ROM, will be assigned a different ISBN. ISBNs can be assigned to any printed publication of 16 pages or more. They can also be assigned to spoken word audiocassettes, microform publications, Braille publications, calendars, floppy disks, CD-ROMs and videocassettes. Recent guidelines from the International ISBN agency also include on-line publications. ISBNs should not be used for printed music, newspapers, magazines, art prints and art folders without title page of text, private firms catalogues, price-lists, directions, loose-leaf systems, theatre and exhibition programmes, colouring-books, games or sound recordings. Serial titles are assigned an ISSN.
At the international level, Internationale ISBN-Agentur, Staatsbibliothek, Berlin is responsible for the ISBN and for assigning new group identifiers. Each country has a national ISBN agency that is responsible for assigning new publisher identifiers and for updating the Publisher's International ISBN Directory, published by Internationale ISBN-Agentur. The national ISBN agencies also produce lists of title numbers for publishers.
The ISBN is used by publishers, booksellers, intermediaries and libraries in order to purchase, retrieve and manage items. Libraries also use the ISBN for citation purposes. The ISBN is widely used in most countries (129 countries in 1993).
The ISBN is used on nearly all printed books and to some extent on electronic off-line documents, such as CD-ROMs. Traditional publishers who normally assign an ISBN to books also tend to use them when they issue electronic publications.
The ISBN is defined by ISO 2108: International Standard Book Numbering.
International Standard ISO 2108:1992: Information and Documentation - International Standard Book Numbering (ISBN)
Identification - Deliverable D2.1 of Telematics for Libraries project BIBLINK (LB 4034), <URL:http://hosted.ukoln.ac.uk/biblink/wp2/d2.1/>
Parts of this section are based on 'BIBLINK - LB 4034 D2.1 Identification'.
The ISSN is a standardised international numeric code that allows the identification of any serial publication independent of its medium. This includes periodicals, newspapers, newsletters, yearbooks, annuals and series published on paper or other medium (floppy disk, CD-ROM, CD-I) or accessible online. The ISSN is linked to a standardised form of the title of the identified serial, known as the `key title'. The ISSN has (as explicit representation, as appearance in print) the form of the acronym ISSN followed by two groups of four digits, separated by a hyphen. The eighth character is a control digit (on the basis of the preceding 7 digits); the control digit can be an `X'. Examples:
ISSN 0374-0536
ISSN 0244-433X
The ISSN has a fixed number of digits and a built-in check-digit and can be validated locally by library systems. Every assigned ISSN is basically unique (globally). In general an assigned original ISSN will never be used again for another title. Only one ISSN is assigned to a serial title. The ISSN is unique for every specific form of the publication. Documents issued in different versions, i.e. both on paper and on the Internet, will be assigned different ISSNs.
There is a central ISSN database (ISSN Register) in which every ISSN input is checked for consistency and uniqueness by the International ISSN Centre. New blocks of unique ISSN are only distributed by the International Centre to national centres. The participants in the network, the national ISSN centres, are responsible for the correct assignment of ISSN in their own countries. The International Centre takes care of the ISSN assignment for countries without a national ISSN centre.
According to the standard and syntax of ISSN there is no possibility of extension to the scheme at the current time. The ISSN has a fixed number of digits and consequently the number of available numbers is limited, but for the foreseeable future there will be enough numbers available. However, the guidelines of the scheme have been extended to permit inclusion of new media, for example electronic documents. (Note: if serials appear in different physical formats or manifestations, different editions or, for example, in different versions a separate ISSN can be assigned without any need for extension of the syntax).
The authority responsible for uniqueness is the ISSN International Centre (located in Paris). It is the registration institution officially designated by ISO for the ISSN. It works in collaboration with the national ISSN centres. The ISSN International Centre compiles and maintains the central ISSN database, ensuring that it is accurate, consistent and continually updated. On the national (and regional) level the national (and regional) ISSN centres are responsible. In cases where there is no existing ISSN centre in a particular country, the ISSN International Centre will take responsibility. The ISSN International Centre also takes responsibility for all ISSN assignments concerning serials of international organisations world-wide. An ISSN can be assigned at any point in the publishing process.
The ISSN identification scheme is used, among others, by: publishers, distributors, subscription agencies, libraries, national bibliographic agencies, documentation centres and databases, union catalogues, reproduction rights organisations (RROs), postal services, (scientific) researchers, authors and library users. The original purpose of the ISSN is to identify the title of a specific serial publication by the application of an international standard code, enabling the exchange of information about serials between computers.
Actual use is still related to the unique identification code for serial publications. This is done, for example, by finding a specific serial title in a database through a search with the 8 digits. The ISSN can also be used in citations. The use of ISSN is especially effective if titles of serials (world-wide) resemble each other very closely. In such cases it can be difficult to identify a title unless the ISSN is known. Without the ISSN, far more bibliographic detail of the specific serial publication is required. In general the records within the ISSN Register can also be used to control, complete or create specific databases. Cost of usage is in principle zero. In practice only a couple of national ISSN centres are planning to charge for (part of the) administration costs. The scale of usage is world-wide.
The ISSN is defined by a standard, i.e. it is the object of a definition and of standardised application rules internationally adopted in the framework of ISO (International Standards Organisation) which groups the official standardisation institutions throughout the world. ISSN is defined by the ISO 3297 standard, which concerns the definition of a serial.
International Standard ISO 3297:1986: Documentation - International Standard Serial Numbering (ISSN)
ISSN International Centre, <URL:http://www.issn.org/>
Identification - Deliverable D2.1 of Telematics for Libraries project BIBLINK (LB 4034), <URL:http://hosted.ukoln.ac.uk/biblink/wp2/d2.1/>
Parts of this section are based on 'BIBLINK - LB 4034 D2.1 Identification'.
The SICI is a variable length code that uniquely identifies serial items (issues) and each contribution (article) contained in a serial. The work on the standard began in the US Serials Industry Systems Advisory Committee (SISAC) in 1983 and was taken over by the National Information Standards Organisation (NISO) as the standard was published in 1991. The standard has recently been revised (1996).
A SICI is divided in three segments with the following syntax:
Item segment<Contribution segment>Control segmentThe Contribution segment is optional. The different parts within the segments are separated by punctuation. There is no restriction on the length of a SICI. For example,
Needleman, Mark. "Computing Resources for an Online Catalog - 10 Years
Later".
Information Technology and Libraries, 1992 Jun, v11n2:168-172
would be assigned the following SICI:
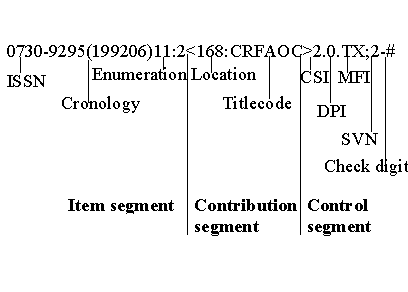
Item
segment
|
ISSN
|
All
SICIs must have an ISSN. For serials that do not have an ISSN, there are
mechanisms to request for one.
|
Chronology
|
The
cover date for a serial title.
| |
Enumeration
|
The
enumeration of a specific issue of a serial title. As many levels as
needed are recorded, e.g. series, volume, number. The levels are separated
using a colon.
|
Contribution
Segment
|
Location
|
The
location of the contribution, normally a page number. This is set to zero for
electronic documents.
|
Locally assigned numbers
[Not in the example]
|
The
contribution segment also allows for alternative local numbers, e.g. numbers
used by publishers during the production process. Locally assigned numbers are
separated from the title code with a colon. (CSI=3)
| |
Titlecode
|
The
first characters in the first six words of the title and subtitle.
|
Control
Segment
|
CSI
(Code Structure Identifier)
|
Determines the coding level. CSI = 1: Assigned to an issue of a serial (SII- Serial Item Identifier) CSI = 2: Assigned to a contribution within a serial (SCI- Serial Contribution Identifier)
CSI = 3: An alternative numbering scheme is included. Only used during the
production process. A published document will have a CSI 1 or a CSI 2.
|
DPI
(Derivative Part Identifier)
|
Identifies parts of the serial other than articles. DPI = 0: A serial item or a contribution DPI = 1: A table of contents DPI = 2: An index
DPI = 3: An abstract
| |
MFI
(Medium/ Format Identifier)
|
A
two letter alphabetic code used to indicate the physical format
| |
SVN
|
Standard
version number of the SICI standard used.
| |
Check
character
|
Calculated
by applying the Modulus 37 algorithm.
|
A SICI is essentially a unique identifier. (Theoretically, two contributions can have identical SICI values if, for instance, two articles in different serials start on the same page number and have the same first six characters in the titles. Tests indicate that duplicate values occur once per million contributions). It should be noted that a SICI can be constructed on the basis of different sources, both from the serial in hand and from various forms of citations. Therefore, depending on the information available in the different sources, a contribution (article) might be given more than one SICI. Different forms of a publication, e.g. documents issued both on paper and CD-ROM, will be assigned different SICIs.
The SICI code has no length restriction. The latest version (Z39.56-199X) is extended to include contributions other than articles, e.g. table of content, indexes etc. In principle the SICI code could be further extended if necessary.
The SICI covers all serial items, including periodicals, newspapers, annual works, reports, journals, proceedings, transactions and numbered monographic series and articles in a serial. Book Industry Communication (BIC) has drafted a non-serial equivalent of the SICI, a "Book Item and Component Identifier (BICI)". The draft is being offered to NISO for adoption and submission to ISO alongside the SICI. The numbering scheme does not cover electronic documents that do not contain location numbers or enumeration.
The SICI is intended for use by those members of the bibliographic community engaged in the functions associated with management of serials and the contributions they contain, such as ordering, accessioning, claiming, royalty collection, rights management, online retrieval, database linking, document delivery, etc.
The SICI is defined by ANSI/NISO standard Z39.56.
SICI: Serial Item and Contribution Identifier Standard, <URL:http://sunsite.Berkeley.EDU/SICI/>
Identification - Deliverable D2.1 of Telematics for Libraries project BIBLINK (LB 4034), <URL:http://hosted.ukoln.ac.uk/biblink/wp2/d2.1/>
Parts of this section are based on 'BIBLINK - LB 4034 D2.1 Identification'
The Warwick Framework provides a conceptual architecture for the interchange of distinct metadata packages. The architecture has two fundamental components, containers and packages. Containers are the unit for aggregating metadata packages. A container may be transient, existing only to transfer packages between systems, or persistent. In its persistent form a container is stored on one or more servers and is accessible using a global identifier (URI). It should be noted that a container can be wrapped within another object, i.e. one that is a wrapper for both data and metadata. Each package is a typed object of one of the following kinds:
metadata set, for example a Dublin Core or MARC record
indirect, i.e. a reference to an external object using a URI
container, these can be nested to any level of complexity
The following diagram shows a simple example of a Warwick Framework container with three packages, the first two contained within the container and the third referenced indirectly.
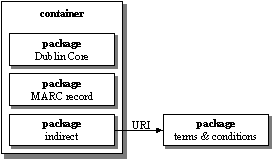
The key characteristics of the Warwick Framework are:
The Warwick Framework makes no constraints on the underlying means of communication. It has been implemented experimentally using MIME and SGML. Warwick Framework containers could be transmitted using email, file transfer, HTTP (the Web), etc. However, there are no known implementations of the Warwick Framework in a "service" environment.
The Resource Description Framework (RDF), currently under development by two working groups of the W3C, provides all of the functionality of the Warwick Framework.
C Lagoze, C A Lynch, R Daniel Jr. The Warwick Framework -- A container Architecture for Aggregating Sets of Metadata. 1996. <URL:http://mirrored.ukoln.ac.uk/lis-journals/dlib/dlib/dlib/july96/lagoze/07lagoze.html>
C Lagoze, R Daniel Jr. Extending the Warwick Framework -- From Metadata Containers to Active Digital Objects. 1997. <URL:http://mirrored.ukoln.ac.uk/lis-journals/dlib/dlib/dlib/november97/daniel/11daniel.html>
J Knight, M Hamilton. A MIME implementation for the Warwick Framework. 1996. <URL:http://weeble.lut.ac.uk/MIME-WF.html>
L Burnard, E Miller, L Quin, C M Sperberg-McQueen. A Syntax for Dublin Core Metadata - Recommendations from the Second Metadata Workshop. 1996. <URL:http://info.ox.ac.uk/~lou/wip/metadata.syntax.html>
Resource Description Framework (RDF) Model and Syntax Specification - working draft. <URL:http://www.w3.org/TR/WD-rdf-syntax/>
For the purposes of resource management, cataloguing, discovery, rights management and other functions, individual resources are often grouped together and treated collectively. These groups are commonly referred to as `collections' and may contain physical items (books, journals, museum artefacts), digital surrogates of physical items, other digital items and catalogues of such collections. Typical examples of collections include:
Collection descriptions are currently provided in a variety of different contexts including:
The PRIDE directory will contain descriptions of collections and the services that provide access to those collections. Therefore, the project will need to identify a suitable attribute set for describing those collections or will need to develop one.
ELib Phase 3 Collection Description Working Group - Report on work in progress <URL:http://www.ukoln.ac.uk/metadata/cld/wg-report/>
Collection Level Description - an eLib supporting study (in progress) <URL:http://www.ukoln.ac.uk/metadata/cld/study/toc/>
RFC-2413 Dublin Core Metadata for Resource Discovery <URL:http://sunsite.doc.ic.ac.uk/computing/internet/rfc/rfc2413.txt>
Application Profile for GILS <URL:http://www.gils.net/prof_v2.html>
ROADS SERVICE template <URL:http://www.ukoln.ac.uk/metadata/roads/templates/service.html>
ISAD(G): General International Standard Archival Description <URL:http://www.archives.ca/ica/cds/isad(g)e.html>
Z39.50 Profile for Access to Digital Collections <URL:http://www.ukoln.ac.uk/metadata/cld/study/collection/zpadc/zpadc.pdf>
WASRV <URL:http://www.bell-labs.com/mailing-lists/wasrv/>
| 1999-01-22 | PRIDE Requirements and Success Factors |