Work Package 2 of Telematics for Libraries project PRIDE (LB 5624)

Title page
Table of Contents
|
PRIDE Requirements and Success Factors
Work Package 2 of Telematics for Libraries project PRIDE (LB 5624) |
Title page Table of Contents |
The X.500 suite of standards was jointly developed by ISO and CCITT to provide directory services in the OSI environment. The need for such a service was highlighted by the development of the X.400 Message Handling System. To use a global electronic mail system, it became clear that a user would need a directory of people accessible through that system, to allow them to discover a colleague's electronic address. X.500 is intended to fulfil this role, and to support a wider range of other applications through the provision of a global directory. Information held in the directory is typically organisational in nature (for example information about people, departments and companies).
The Directory consists of a set of typed entries known as the Directory Information Base (DIB). Each entry represents an object consisting of a set of attributes. Each attribute has an attribute type which indicates the type of information represented by the attribute, and a value for that attribute.
For example the entry for a person may appear as:
objectClass=Person commonName=Paul Harvey telephoneNumber=1234 5678
The type of the object defines its schema and is given by its objectClass attribute, in this case Person.
The DIB forms a hierarchical structure known as the Directory Information Tree (DIT). The following figure shows a section of the DIT. Each object is named uniquely by traversing the tree from its root to the entry, concatenating the naming attributes of each node along the way. The result is termed the Distinguished Name (DN) of the entry. For example, in the figure, the DN of the entry for "Paul Harvey" is
cn=Paul Harvey, ou=Staff, o=Fretwell Downing, c=GB
The tags of the attributes used to name the entry in the above are commonly used abreviations (e.g. cn => commonName, ou=>organisationalUnit, o=>organisation, c=>country)
This section describes the most important operations made available to clients to access and to modify the directory. The predicable set of functionality is provided:
The DIB is decomposed into discrete data sets shared between a number of Directory System Agents (DSAs). How each DSA stores its share of the information isn't specified by the X.500 standard - X.500 only specifies the interface through which the information can be accessed.
DSAs communicate with each other through the Directory System Protocol (DSP). Directory User Agents (DUAs) access the information held by the DSAs through the Directory Access Protocol (DAP). Security is provided at the DUA to DSA level and DSA to DSA level using Simple Authentication (clear text passwords), Protected Simple Authentication (encrypted passwords) and Strong Authentication (digital signatures). The following diagram shows the entities and protocols of the X.500 system.
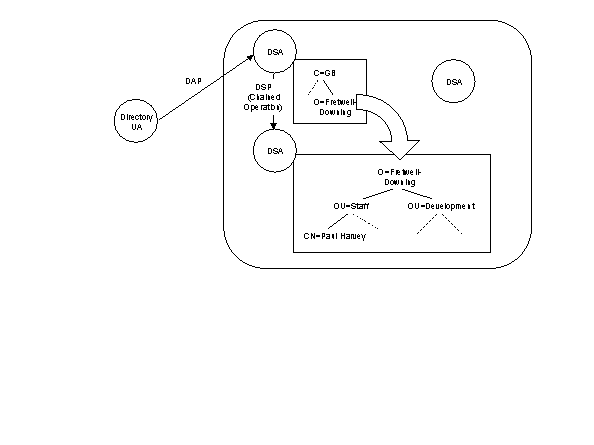
Figure 1 The X.500 Directory Service
Although the information set is decomposed into many data sets stored on many DSAs, X.500 provides a logical view of the information. A global naming scheme is used to present a single unified directory to the user.
Access to the information held in the Directory is the same regardless of which DSA the Directory is accessed through. A user formulates a query and submits it to their DUA. The DUA the submits the query to the local DSA. If the information is held by the local DSA, the information is returned to the DUA, and so to the user. If the information is held at another DSA, the local DSA makes use of a knowledge model to decide how to deal with the query. The DSA will either forward the request to another which will be able to better resolve the query - this is known as chaining - or will return information to the client indicating a DSA which may better resolve the query - this is known as referral.
The original X.500 standard was released in 1988, implementations of which highlighted several fundamental failings of the standard, in particular in the area of access control and data management. A second version of the X.500 standard, intended to address these problems, was released in 1993. This standard provides improved data administration, flexible access controls and facilities for data replication.
Links to X.500 Information. <URL:http://www.nexor.com/public/directory.html>
X.500 : Overview of Concepts, Models, and Services. (ISO/IEC 9594-1:1993). <URL:http://www.dante.net/np/ds/osi/9594-1-X.500.A4.ps>
X.501 : Models</a> (ISO/IEC 9594-2:1993) <URL:http://www.dante.net/np/ds/osi/9594-2-X.501.A4.ps>
X.511 : Abstract Service Definition (ISO/IEC 9594-3:1993) <URL:http://www.dante.net/np/ds/osi/9594-3-X.511.A4.ps>
X.518 : Procedures for Distributed Operation (ISO/IEC 9594-4:1993) <URL:http://www.dante.net/np/ds/osi/9594-4-X.518.A4.ps>
X.519 : Protocol Specifications (ISO/IEC 9594-5:1993). <URL:http://www.dante.net/np/ds/osi/9594-5-X.519.A4.ps>
X.520 : Selected Attribute Types (ISO/IEC 9594-6:1993). <URL:http://www.dante.net/np/ds/osi/9594-6-X.520.A4.ps>
X.521 : Selected Object Classes (ISO/IEC 9594-7:1993). <URL:http://www.dante.net/np/ds/osi/9594-7-X.521.A4.ps>
X.509 : Authentication Framework (ISO/IEC 9594-8:1993). <URL:http://www.dante.net/np/ds/osi/9594-8-X.509.A4.ps>
X.525 : Replication</a> (ISO/IEC 9594-9:1993). <URL:http://www.dante.net/np/ds/osi/9594-9-X.525.A4.ps>
The Lightweight Directory Access Protocol (LDAP) was originally intended to provide a less resource hungry alternative to the X.500 DAP protocol. Contemporary PC's were not sufficiently powerful to support the demands of a full OSI stack.
The facilities provided by LDAP are matched very closely to those of X.500 DAP. However LDAP uses a simpler encoding and runs directly on top of TCP/IP.
As the power of the typical PC has increased the original motivation for LDAP has disappeared. However, in the interim period, LDAP has gained significant acceptance and the use of OSI protocols has decreased when compared to the now dominant position of the TCP/IP (Internet) stack.
The following sections discuss the LDAP protocol, typical architecture/deployment scenarios, and existing versions and implementations. The data model and general facilities are not described as these match those of X.500.
Systems based on LDAP typically take one of the forms shown in the following figure.
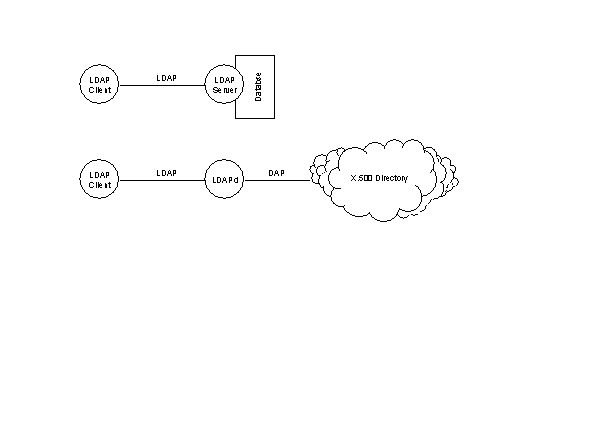
Figure 2 LDAP Deployment
The first is a pure LDAP scenario. We can see an LDAP client (or User Agent (UA)) using the LDAP protocol to communicate with an LDAP server. The LDAP server has a local database which contains its directory objects.
Should a query be addressed to the server which it cannot resolve, for example when it does not store the relevant directory objects, the server may return a set of referrals to the client. Each referral contains the addresses of an other LDAP server which may be able to better resolve the query. It is then the client's responsibility resubmit the original query to one of the referenced servers.
The second scenario involves a mixture of LDAP and X.500 DAP. The LDAP UA communicates with the LDAPd (LDAP daemon) using the standard LDAP protocol. The LDAPd appears to be a standalone LDAP server to the client, however it is actually a gateway between the LDAP protocol and the X.500 DAP protocol. Any request presented to the LDAPd is converted to the appropriate DAP and forwarded to the X.500 directory.
In this case, the LDAPd should be able to resolve all queries via its connection to X.500 and referrals should never take place.
There are two currently active versions of the LDAP protocol - version 2 (v2) and version 3 (v3). Both are standardised by the IETF. V2 is of interest because of its wide availability and the existence of a public domain implementation. V3 is of interest because of the enhancements it provides over v2.
V2 is defined in RFC1777 and standard C language client API is defined in RFC1823. A public domain implementation of both the LDAP API and an LDAP server (SLAPd) is available from the University of Michigan.
V3 is defined in RFC2251. It provides enhancements v2, including:
Access, Searching and Indexing of Directories (asid) IETF working group. <URL:http://www.ietf.cnri.reston.va.us/html.charters/asid-charter.html>
University of Michigan LDAP resources. <URL:http://www.umich.edu/~dirsvcs/ldap/>
Lightweight Directory Access Protocol (v3) (RFC 2251) By Mark Wahl (Critical Angle), Tim Howes (Netscape) and Steve Kille (ISODE Ltd). <URL:http://www.critical-angle.com/ldapworld/rfc2251.txt>
LDAPv3 Attribute Syntax Definitions (RFC 2252) By Mark Wahl, Andy Coulbeck (ISODE Ltd), Tim Howes and Steve Kille. <URL:http://www.critical-angle.com/ldapworld/rfc2252.txt>
UTF-8 String Representation of Distinguished Names (RFC 2253) By Mark Wahl, Steve Kille and Tim Howes. <URL:http://www.critical-angle.com/ldapworld/rfc2253.txt>
The String Representation of LDAP Search Filters (RFC 2254) By Tim Howes. <URL:http://www.critical-angle.com/ldapworld/rfc2254.txt>
The LDAP URL Format (RFC 2255) By Tim Howes and Mark Smith (Netscape). <URL:http://www.critical-angle.com/ldapworld/rfc2255.txt>
A Summary of the X.500(96) User Schema for use with LDAPv3 (RFC 2256). <URL:http://www.critical-angle.com/ldapworld/rfc2256.txt>
The C LDAP Application Program Interface. M. Smith, Editor 7 August 1998. <URL:http://search.ietf.org/internet-drafts/draft-ietf-ldapext-ldap-c-api-01.txt>
The Java LDAP Application Program Interface. <URL:http://draft-ietf-ldapext-ldap-java-api-02.txt>
The LDAP Application Program Interface. (rfc1823) T. Howes & M. Smith. August 1995. <URL:http://info.internet.isi.edu:80/in-notes/rfc/files/rfc1823.txt>
Lightweight Directory Access Protocol (rfc1777.txt) W. Yeong, T. Howes & S. Kille. March 1995. <URL:http://info.internet.isi.edu:80/in-notes/rfc/files/rfc1777.txt>
The Microsoft Active Directory (MAD) is included as part of Microsoft NT 5.0. It is essentially a marriage of existing technologies with some added value. The basic idea is to hang a set of LDAP servers from the existing DNS hierarchy. The DNS is used to locate a target LDAP server which is then queried directly using the LDAP protocol. This mechanism, although not without its drawbacks, avoids the greatest problem in deploying pure LDAP or X.500 - that of constructing the global hierarchy.
In addition, the Active Directory introduces a global catalogue. This maintains a copy of the most frequently searched attributes from a set of DSAs and so allows many searches to be efficiently resolved at a single point. The global catalogue is maintained using Microsoft's proprietary directory replication protocol.
This section describes implementation details of the Microsoft Active Directory. As noted above the Active Directory, rather than being an invention of new technology, is actually a merging of existing ideas and protocols.
The naming and data model used in the Active Directory is adopted directly from LDAP and X.500, and the fundamental access protocol for the Active Directory is LDAP (v2 or v3). Refer to the relevant section of this document for further information
The use of the Distinguished Name (DN) in the Active Directory has been adapted slightly from that in pure X.500. With reference to the following figure, the upper sections of an Active Directory DN consist solely of DC elements. For example in:
cn=Paul Harvey, ou=Staff, DC=fdgroup, DC=co, DC=ukWe have:
DC=fdgroup, DC=co, DC=ukIn the name resolution process the DC elements are actually concatenated to form a Domain Name (DN), in this case:
fdgroup.co.ukIn order to locate an entry from its DN, its domain name is first constructed. This is looked up in the DNS and is expected to refer to a SRV Resource Record. This type of DNS entry contains basic information about other computerised services in the following form:
service.protocol.hostnameSo, if in our case the target LDAP service was available via TCP and was hosted on ldaphost.fdgroup.co.uk then the DNS entry for fdgroup.co.uk would contain:
ldap.tcp.ldaphost.fdgroup.co.ukOnce the service has been located in this way, its host name may be resolved (again via the DNS) and the relevant Active Directory System Agent queried via LDAP, supplying the complete DN.
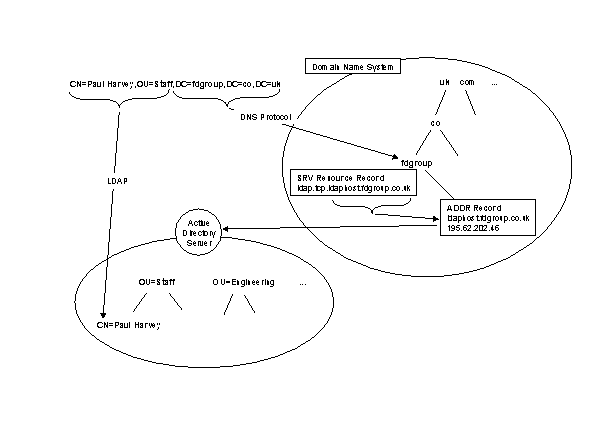
Figure 3 The Microsoft Active Directory
As we have seen the Active Directory is essentially a deployment of LDAP DSAs linked together via the DNS. This section describes some additional features, once more these are largely inspired by the LDAP/X.500 community, either by standards efforts or from research work:
The primary mechanism for the development of Active Directory applications is using the proprietary Active Directory Services Interfaces (ADSI) API. ADSI exposes the Active Directory and the data it contains as COM objects.
ASDI provides a consistent API, while allowing access to different directory systems via appropriate providers. Currently the following directory systems are supported:
Lightweight Directory Access Protocol (rfc1777.txt) W. Yeong, T. Howes & S. Kille. March 1995. <URL:http://info.internet.isi.edu:80/in-notes/rfc/files/rfc1777.txt>
Lightweight Directory Access Protocol (v3) (RFC 2251) By Mark Wahl (Critical Angle), Tim Howes (Netscape) and Steve Kille (ISODE Ltd). <URL:http://www.critical-angle.com/ldapworld/rfc2251.txt>
Active Directory Programmers Guide. <URL:http://msdn.microsoft.com/developer/windowsnt5/adsi/actdirguide.htm>
Active Directory Service Inteface Prorammers Guide. <URL:http://premium.microsoft.com/msdn/library/sdkdoc/adsi/ds2prggd_72hx.htm>
WHOIS++, is an extension to the trivial WHOIS service described in RFC954 to permit WHOIS-like servers to make available more structured information to the Internet. The basic WHOIS information model represents each individual record as a Rolodex-like collection of text. Each record has a unique identifier (or handle), but otherwise is assumed to have little structure. The current service allows users to issue searches for individual strings within individual records, as well as searches for individual record handles using a very simple query-response protocol.
WHOIS++, is a simple, distributed and extensible information lookup service based upon a small set of extensions to the original WHOIS information model. These extensions allow the new service to address the community's need for a simple directory service, yet the extensible architecture is expected to also allow it to find application in a number of other information service areas.
Added features include an extension to the trivial WHOIS data model and query protocol and a companion extensible, distributed indexing service. A number of other options have also been added, like Boolean operators, more powerful search constraints and search methods, and most specifically structured data to make both the client and the server part of the dialogue more stringent and parsable. An optional authentication mechanism for protecting all or parts of the associated WHOIS++ information database from unauthorised access is also briefly described.
The basic architecture of WHOIS++ allows distributed maintenance of the directory contents and the use of the WHOIS++ indexing service for locating additional WHOIS++ servers
The WHOIS++ service is based on the concept of structuring user information around a series of standardised information templates. Such templates consist of ordered sets of data elements (or attribute-value pairs).
It is intended that adding such structured templates to a server and subsequently identifying and searching them should be simple tasks. The creation and use of customised templates should also be possible with little effort, although their use is discouraged where appropriate standardised templates exist.
The WHOIS++ server simply functions as a known front end, offering a simple data model and communicating through a well known port and query protocol. The format of both queries and replies has been structured to allow the use of client software for generating searches and displaying the results. At the same time, some effort has been made to keep responses at least to some degree readable by humans, to ensure low entry cost and to ease debugging.
The WHOIS service is based upon a simple data model. The NIC WHOIS database consists of a series of individual records, each of which is identified by a single unique identifier (the "handle"). Each record contains one or more lines of information. Currently, there is no structure or implicit ordering of this information, although by implication each record is concerned with information about a single user or service.
Two basic changes to this model are implemented by the WHOIS++ service. First, the information within the database has been structured as collections of data elements, or simple attribute/value pairs. Each individual record contains a specified ordered set of these data elements.
Secondly, WHOIS++ has introduced typing of the database records. In effect, each record is based upon one of a specified set of templates, each containing a finite and specified number of data elements. This allow users to easily limit searches to specific collections of information, such as information about users, services, abstracts of papers, descriptions of software, and so on.
The WHOIS++ search mechanism is intended to be extremely simple. A search command consists of one or more search terms, with an optional set of global constraints (specifiers that modify or control a search). Search terms allow the user to specify template type, attribute, value or handle that any record returns must satisfy. Each search term can have an optional set of local constraints that apply to only that term. Each term specifies a further constraint that the selected set of output records must satisfy. Each term may thus be thought of as performing a subtractive selection, in the sense that any record that does not fulfil the term is discarded from the result set. Boolean searches are possible by the use of AND, OR, not and parenthesis.
The WHOIS++ directory service has an architecture which is separated into two components; the base level server, and a indexing server. A single physical server can act as both a base level server and an indexing server. A base level server is one which contains only filled templates. An indexing server is one which contains forward knowledge and pointers to other indexing servers or base level servers.
Indexing in WHOIS++ is used to tie together many base level servers and index servers into a unified directory service. Each base level server and index server which wishes to participate in the unified directory service must generate "forward knowledge" for the entries it contains. One type of forward knowledge is the "centroid". Index servers can collect forward knowledge for any servers it wishes. In effect, all of the servers that the index server knows about can be searched with a single query to the index server; the index server holds the forward knowledge along with pointers to the servers it indexes, and can refer the query to servers which might hold information which satisfies the query. Implementers of this protocol are strongly encouraged to incorporate centroid generation abilities into their servers.
A WHOIS++ server will normally listen for a TCP connections on the allocated WHOIS++ port (although a WHOIS++ server can be accessed over any TCP connection). Once a connection is established, the server issues a banner message, and listens for input. The command specified in this input is processed and the results returned including an ending system message. If the server supports the optional HOLD constraint, and this constraint is specified as part of any command, the server continues to listen on the connection for another line of input.
This cycle continues as long as the sender continues to append the required HOLD constraint to each subsequent command. At the same time, each server is permitted to set an optional timeout value. If set, the server is free to terminate an idle connection at any time after this delay has passed with no input from the client. If the server terminates the connection due to timeout, it will be indicated by the system message. The timeout value is not changeable by the client.
Architecture of the Whois++ Index Service. (rfc1913.txt) C. Weider, J. Fullton & S. Spero. February 1996. <URL:http://info.internet.isi.edu:80/in-notes/rfc/files/rfc1913.txt>
Architecture of the WHOIS++ service. (rfc1835.txt). P. Deutsch, R. Schoultz, P. Faltstrom & C. Weider. August 1995. <URL:http://info.internet.isi.edu:80/in-notes/rfc/files/rfc1835.txt>
Whois and Network Information Lookup Service, Whois++. (rfc1834.txt ). J. Gargano & K. Weiss. August 1995. <URL:http://info.internet.isi.edu:80/in-notes/rfc/files/rfc1834.txt>
The Common Object Request Broker Architecture (CORBA) from the Object Management Group (OMG) is a set of standards for network object interoperability. Fundamentally the CORBA standards specify the following:
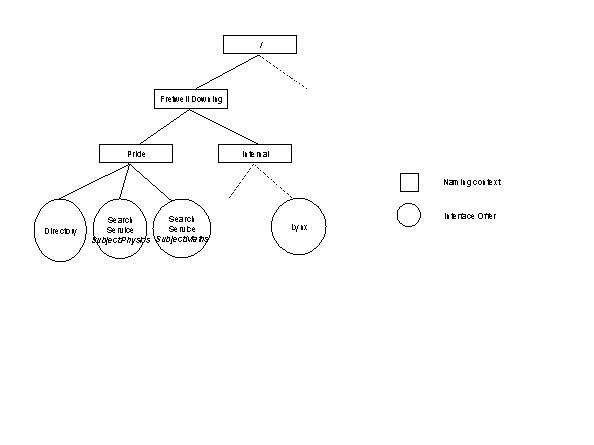
Figure 4 The Trader Context Name Space
A service creates instances of supported interface(s) and supplies or exports them to the Trader. Clients query the Trader to find offers of interfaces of the types they require and then import those to be made use of.
The Trader organises interface information using two name spaces; the type space structures interface type relationships and the context name space structures interface offers.
The context name space is a hierarchical structure, an example is shown in the figure above. The `/' symbol represents the root of the tree, and any node is described by the path traversed to reach it from the root. When a server exports a reference to an interface instance it names a position in the context name space to enter the offer. In the figure we can see a number of naming contexts, with the /Fretwell-Downing/Pride context populated with three interface offers, two of type Search Service and one of type Directory.
The naming context structure is analogous to that of a hierarchical file system, with names being directories and interface offers being files.
In order to access a particular service a client issues a request for the associated interface type to the Trader and names a position in the naming context structure. The Trader searches for a suitable interface offer below the named point in the tree, and returns any found.
In addition, an interface offer may have properties associated with it. A property is a 2-tuple consisting of a name and a data element. The name element identifies the property and the data element is its simply typed value. In the diagram we see the Subject property associated with the Search offers, with values of Physics and Maths. When a client tries to import an interface it can supply a set of constraints to the trader. These constraints are applied to property values and only those interfaces which conform are returned.
The example Search allows a client to bind to a service supporting a particular subject area by constraining the appropriate interface property.
The trader provides interfaces; for the import and export of offers; to manipulate the type space; and to manipulate the context name space.
The Object Management Group. <URL:http://www.omg.org/>
Trading Object Services Specification. <URL:http://www.omg.org/corba/sectrans.html#trader>
CORBA for Beginners. <URL:http://www.omg.org/corba/beginners.html>
The Domain Name System (DNS), is a distributed database that can be used by TCP/IP applications to map between hostnames and associated information (most commonly IP addresses). This database is characterised as a distributed one because no single site on the Internet knows all the information (in terms of IP addresses and hostnames) that exists in the network.
Each site maintains its own database of information that contains the mappings for all of the hosts that belong to the domain administered by this site. The distribution of this information is accomplished with the use of special software called name server. Clients that need information about a host can query the name server across the Internet.
The DNS name space is hierarchical. The following figure shows the organisation of the DNS name space.
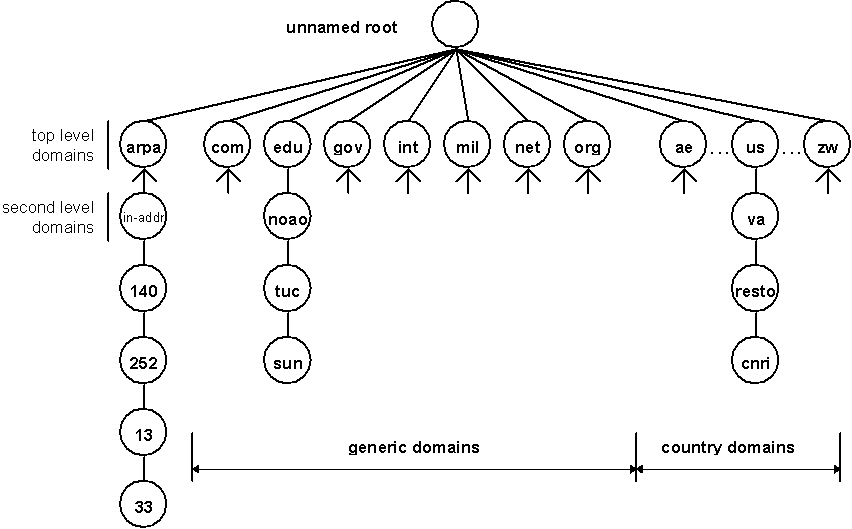
Figure 5 - DNS name space
Every node has a label of up to 63 characters (no distinction between uppercase and lowercase characters is made). The root of the tree is a special node with a null label. The domain name of any node in the tree is the list of labels starting at the node and working up to the root. The labels are separated with a period (dot). Every node in the tree must have a unique domain name but there is no restriction to use the same label at different points in the tree.
A domain name that ends with a period is called an absolute domain name or a fully qualified domain name (FQDN). The top level domains are divided into three areas:
The .arpa domain that is a special domain used for address-to-name mappings. This domain is used for answering the so called pointer queries. These queries contain the address of a particular host. Each organisation that joins the Internet and obtains authority for a portion of the DNS name space also obtains authority for a portion of the in-addr.arpa name space. This name space corresponds to their IP address space. Every pointer query is answered by searching the in-addr.arpa space.
The seven generic domains (also called organisational domains). Most people believe that these generic domains are only for the use of U.S organisations. This is DNS folklore, with the only generic domains that are restricted to United States are the .gov and .mil domains.
The two-letter country or geographical domains represent top level domains for the various countries all over the world. The labels of these domains are according to the country codes found in ISO 3166.
The access to the DNS name space is facilitated through the use of a resolver. Usually the resolver is implemented as functions that are linked with the TCP/IP application that needs to query the name server. An example of such functions are the two library functions gethostbyname() and gethostbyaddr() that are provided for such purposes by UNIX.
The resolver first queries the name server or servers that are designated authoritative (primary servers) for the domain that the resolver belongs to. If the name server cannot answer the query it contacts another name server. Since it is not possible for every name server to know the addresses of all the existing name servers, it contacts one of the root name servers. Each primary name server is required to know the address of every root name server.
The process that follows is an iterative one: the query of the primary name server is redirected, by the root name server, to the appropriate second level domain authoritative server. If this server does not contain or does not know the requested information, directs the query to the next authoritative server in its domain. This is repeated until one of the queried servers returns the needed address/hostname.
The queries are exchanged between clients and name server with the use of the DNS message. There is only one message defined for both queries and responses. It has a fixed 12-byte header which is followed by four variable-length fields. These fields contain the question, answers, authority and additional information portions of the message. The last three fields share a common format called a resource record (RR).
Each question portion contains the query name, which is a sequence of one or more labels, the query type and the query class. There are about 20 different values for the query type some of which are now obsolete. The most common type of query type is an A type which means that an IP address is desired for the query name. A PTR query requests the names corresponding to an IP address and is the pointer query that was mentioned above. The query class normally has the value 1 meaning an Internet address.
A resource record contains six fields; the domain name to which the resource record, that follows, corresponds; the type that corresponds to the query type values; the class which is normally 1 for Internet data; the time-to-live (TTL) which shows the number of seconds that the RR can be cached by the client; the resource data length that specifies the amount of resource data that follow.
Domain naming convention for Internet user applications. (rfc819) Z. Su, J. Postel. Aug-01-1982. <URL:http://info.internet.isi.edu/in-notes/rfc/files/rfc819.txt>
Domain names - concepts and facilities. (rfc1034). P.V. Mockapetris. Nov-01-1987. <URL:http://info.internet.isi.edu/in-notes/rfc/files/rfc1034.txt>
Domain names - implementation and specification. (rfc1035). P.V. Mockapetris. Nov-01-1987. <URL:http://info.internet.isi.edu/in-notes/rfc/files/rfc1035.txt>
| 1999-01-22 | PRIDE Requirements and Success Factors |