UKOLN RDFHarvester: a PRIDE tool

Background: The RDFHarvester is one small part of the PRIDE Directory Toolkit. It is an automated agent (or a robot)
that is designed to work in the background (set up as a 'cron job' on Unix, for instance). These html pages
and the scripts that they link to are not required to run the agent: they exist to provide a visual aspect
to the working of the RDFHarvester, however, if they are of interest, the scripts are available.
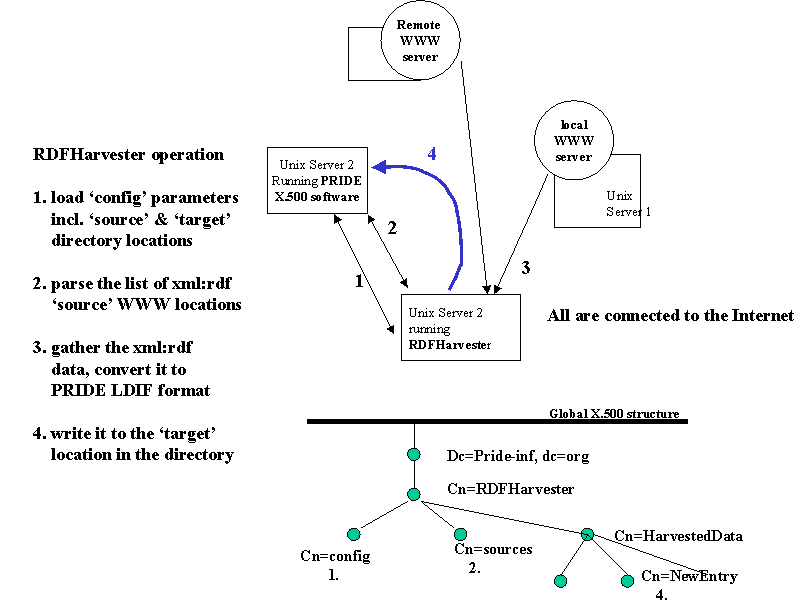
Contextual overview: a look at the context for a xml:rdf harvest
The RDFHarvester uses the PRIDE directory to read its configuration information.
From the 'config' directory entry, it learns the what to do: it reads information
about location in the PRIDE directory where it will find and in turn read a list
of WWW locations where data to be harvested exists and it reads where (in the PRIDE directory tree)
to write a given entry. In other words, it makes a basic configuration read followed by
a read of things to do. Once it 'knows what to do' (i.e. where, on the web to find directory
content information in RDF fromat) it systematically visits each WWW location, gathers the
specified data, and converts it to LDIF format for the PRIDE directory.
A Sample Run: using the above configuration values
view a subtree to delete specific items
In changing the values in the RDFHarvester config and sources entries the robot will perform
as the new values dictate. In the event that errors are made in the config/source entries, the original values
can easily be reloaded (feel free to experiment).
view a subtree