Andy Powell
UK Office for Library and Information Networking
University of Bath
Resource discovery, site-maps, Web collections, content rating, e-commerce and rights management, collaboration, privacy and Web-site management are all examples of Web applications that are based to a greater or lesser extent on metadata. Several of these areas have developed their own metadata systems to satisfy their requirements. Of these the most widely known is probably the simple ‘keywords’ and ‘descriptions’ embedded into HTML META tags that are collected and indexed by the large Web search engines like Alta Vista. In addition, there are the PICS labels that have been developed for content rating on the Web and several semi-proprietary formats for Web collections, mechanisms for grouping together collections of Web resources.
The World Wide Web Consortium (W3C) recognised the need for a common metadata architecture that can be used by all application areas. To this end, they have developed the Resource Description Framework (RDF) [1]. This paper provides a brief introduction to RDF, looking at the RDF model and its associated syntax based on the Extensible Markup Language (XML) [2]. It describes RDF schemas, the mechanism by which the generic RDF architecture can be used to hold application specific metadata. Finally, it gives an introduction to the Dublin Core, a simple set of metadata elements aimed at improving resource discovery on the Web, which looks likely to become one of the early adopters of RDF as its preferred syntax.
RDF has been developed over the last year or so as part of the W3C’s Metadata Activity [3] within the Technology and Society Domain [4]. The development has received input from several communities including those working on content rating using the Platform for Internet Content Selection (PICS) [5], Web collections, digital libraries (particularly the Dublin Core initiative), digital signatures (DSig) [6] and Web privacy (P3P). RDF provides a generic metadata architecture that can be expressed in XML. The ultimate aim is that a machine understandable Web of metadata will be developed across a broad range of application and subject areas. Whether this aim ever becomes fully realised remains to be seen. What can be said is that RDF is likely to become the pervasive metadata architecture, implemented in servers, caches, browsers and other components that make up the Web infrastructure.
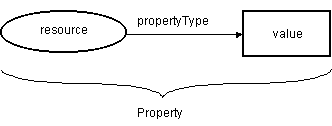
RDF is based on a mathematical model that provides a mechanism for grouping together sets of very simple metadata statements known as ‘triples’. Each triple is made up of a ‘resource’ (or node), a ‘propertyType’ and a ‘value’. RDF propertyTypes can be thought of as attributes in traditional attribute-value pairs. The model can be represented graphically using ‘node and arc diagrams’.
In the diagrams, an oval is used to show each node, a labelled arrow is used for each propertyType and a rectangle is used for simple values. Some nodes in the RDF model represent real world resources (Web pages, physical objects, etc.) whilst others do not. In RDF, all nodes that represent real-world resources must have an associated Uniform Resource Identifier (URI) [7]. Each triple in RDF is known as a ‘property’. Nodes may have more than one arc originating from them, indicating that multiple propertyTypes are associated with the same resource. Groups of multiple properties are known as ‘descriptions’. PropertyTypes may point to simple atomic values (strings and numbers) or to more complex values that are themselves made up of collections of properties.
Consider a simple example:

We can read this node and arc diagram as follows:
The resource identified by http://www.ukoln.ac.uk/metadata/ has a propertyType "Author" with the string value "Andy Powell".
Or, in plain English:
Andy Powell is the author of the Web page at http://www.ukoln.ac.uk/metadata/.
Suppose that we wanted to list the author’s email address as well as their name. We could replace the string value, "Andy Powell", with a node that has two propertyTypes originating from it, one for the name, one for the email address:
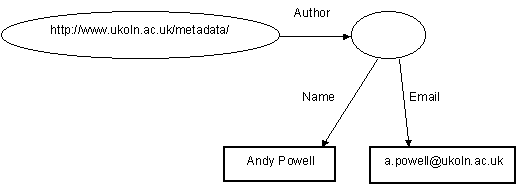
Notice that, in this example, the second node does not have a URI associated with it. Such nodes are called anonymous.
One powerful feature of the RDF model is that it is possible to make statements about properties. This is done using ‘reification’, a process by which properties are turned into nodes, allowing propertyTypes to be associated with them. The node and arc diagrams for reified properties are complex and are not shown here. However, the example below shows in a simplified way what can be achieved. It shows two simple properties. The first associating a "Cost" with a Web page and the second associating the propertyType of "ValidUntil" and a value of "1998-09" with the first property.
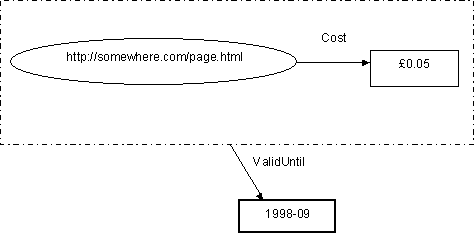
It is expected that reification will primarily be used so that statements can be made about who is making assertions about resources, i.e. who has created the metadata. It is anticipated that digital signatures will be used to provide a level of trust in such statements.
Although useful for visualising the RDF model, node and arc diagrams clearly cannot be used to share metadata between software applications on the Web. Therefore, the W3C RDF Model and Syntax Working Group have developed a ‘serialisation syntax’ based on XML that allows the RDF model to be written down in a way that can be processed by computer software.
Here is another simple example showing a single property of the UKOLN metadata home page. Firstly, here is the node and arc diagram:

This can be written (or serialised) in XML as:
<RDF:RDF>
<RDF:Description RDF:HREF="http://www.ukoln.ac.uk/metadata/">
<Title>The UKOLN Metadata Home Page</Title>
</RDF:Description>
</RDF:RDF>
The <RDF:RDF> and </RDF:RDF> tag pair indicate to an XML processor that what is contained between these two tags is some RDF. More will be said about the RDF:RDF string later. The <RDF:Description> tag encloses an RDF description, in this case containing a single property. The <RDF:Description> tag has a single argument, RDF:HREF, giving the URI of the resource being described. Finally, the propertyType, Title, forms a tag pair enclosing the string value.
Here is a more complex example that shows three properties of the same page.
<RDF:RDF>
<RDF:Description
RDF:HREF="http://www.ukoln.ac.uk/metadata/">
<Title>The UKOLN Metadata Home Page</Title>
<Keywords>Dublin Core, MARC, TEI, IAFA, … </Keywords>
<Description>
Start of several Web pages about metadata
</Description>
</RDF:Description>
</RDF:RDF>
We have seen how the RDF model may be used to associate propertyTypes (attributes) and their values with resources (or nodes). We have also seen, at a very simple level, how the model may be written down in such a way that metadata can be shared between different Web applications. However, we have not yet mentioned anything about the semantics of propertyTypes. Crucially, we don’t know whether two metadata authors are using the same propertyType, for example "Title", in the same way.
XML namespaces are used to uniquely identify each propertyType. Namespaces provide a prefix for each propertyType name, using a colon to separate the namespace prefix from the name. For example, let’s suppose that UKOLN developed a new metadata system and within that system we chose to use the ‘Title’ propertyType in a very specific way. We might use a "UKOLN" namespace to indicate a UKOLN Title as follows:
<UKOLN:Title>The UKOLN Metadata Home Page</UKOLN:Title>
All namespaces have an associated URI. Two namespaces that have the same URI are the same even if the text string used as the prefix is different. Some examples of the use of the Dublin Core namespace and the way in which a URI is associated with a namespace are shown later.
The definition of the propertyTypes that may be used within a particular metadata application, the values those propertyTypes may take and the semantics of the propertyTypes within that system is collectively known as a ‘schema’. The W3C RDF Schema Working Group is currently developing a Schema Definition Language to define metadata systems based on RDF [8]. RDF schemas will employ a class mechanism allowing them to be organised hierarchically. In defining new RDF schemas it will be possible to inherit metadata definitions from one or more existing schemas as appropriate, thus leveraging work done by others.
The Dublin Core (DC) [9] is a fifteen element metadata set that was originally developed to improve resource discovery on the Web. To this end, the DC elements were primarily intended to describe Web-based ‘document-like objects’. More recently the scope of DC has expanded to include off-line electronic resources and other objects, museum artefacts for example. The Dublin Core effort is developing mechanisms for describing the relationships between such resources.
The Dublin Core originated at a meeting organised by OCLC in Dublin, Ohio attended by representatives of the library, museum and research communities and commercial Web software developers. Since then there have been 4 follow-up meetings in the Dublin Core workshop series, the most recent being in Helsinki, Finland late in 1997. A sixth workshop is planned for Washington DC, known as DC-DC, in November 1998. Between workshops, Dublin Core discussion continues via email. The main DC related mailing list currently has more than 400 subscribers [10].
Much of the DC effort has gone into defining the semantics of the 15 elements and considerable cross-domain consensus has been achieved on this over the last few years. There has also been some work on syntax, particularly on the use of DC within HTML Web pages. Many DC-based projects are embedding DC metadata directly into Web pages using the HTML META tag. In this way, the metadata is directly available for collection and indexing by Web robots.
Recently a formal structure, comprising a Policy Advisory Committee and a Technical Advisory Committee, has been put in place to oversee the future development of the Dublin Core. A series of five Internet Engineering Task Force Requests For Comments (IETF RFCs) are in preparation, the first two defining the semantics of the 15 elements and the way in which those elements may be embedded within HTML documents. Work is also underway to submit the Dublin Core to NISO as a national standard, the intention being to use this as the basis for a submission to ISO.
The fifteen DC elements and a very brief description of their semantics follow:
Note that complete descriptions of the element semantics are available from the reference description of the element set [11].
All of the elements are both optional and repeatable. A minimal DC record may therefore contain only one or two of the above elements. If necessary an element may be repeated, to indicate multiple authors for example. The values of several elements may be taken from enumerated lists. In some cases, these lists already exist, in others lists are being developed as part of the Dublin Core effort.
The semantics of some of the elements are defined very broadly. For example, the date element is simply defined as "a date associated with the creation or availability of the resource" and the relation element as "an identifier of a second resource and its relationship to the present resource". It is possible to refine the meaning of the elements using a ‘TYPE’:
Date TYPE=Valid
Relation TYPE=IsPartOf
It is also possible to associate an externally defined ‘SCHEME’ (for example a controlled vocabulary or specific syntax) with element values:
Subject SCHEME=LCSH
Date SCHEME=ISO 8601
Finally, the LANGUAGE of the element value can also be specified:
Title LANGUAGE=fr
TYPE, SCHEME and LANGUAGE are known as qualifiers. Dublin Core that makes use of qualifiers is known as ‘qualified DC’. Dublin Core that does not is often referred to as ‘simple DC’.
As mentioned previously, DC elements are typically embedded into the HTML resources that they describe using the META tag. The syntax for embedding simple DC into HTML is well defined. Here, for example, is the Dublin Core metadata embedded into the UKOLN home page:
<HTML>
<HEAD>
<TITLE>UKOLN Home Page</TITLE>
<META NAME="DC.Title" CONTENT="UKOLN: UK Office for
Library and Information Networking">
<META NAME="DC.Subject" CONTENT="national centre,
network information support, library community, awareness, research,
information services, public library networking, bibliographic management,
distributed library systems, metadata, resource discovery, conferences,
lectures, workshops">
<META NAME="DC.Description" CONTENT="UKOLN is a
national centre for support in network information management in the
library and information communities. It provides awareness, research and
information services">
<META NAME="DC.Creator" CONTENT="UKOLN Information
Services Group">
</HEAD>
<BODY>
...
</BODY>
</HTML>
Notice that the element names, ‘Creator’ for example, are prefixed by ‘DC.’ to indicate that each one is a part of the Dublin Core. Many projects using Dublin Core have added extra metadata elements appropriate to their needs, using a different prefix to indicate that these elements are not part of DC.
However, there are limitations in what can be achieved using HTML META tags. It is not possible to group sets of META tags in HTML, nor is it possible to represent any hierarchical structure that may be present in the metadata. Qualified DC can be embedded, indeed many projects using Dublin Core rely on qualified DC for their resource descriptions, but there is some inconsistency in the way projects are doing this. In particular, the way in which qualified DC is embedded into HTML depends on the HTML version in use. HTML 4.0 incorporated some of the ideas from the Dublin Core and added a "SCHEME" attribute on the META tag, which was not present in earlier versions.
Partly because of these difficulties, DC looks likely to make use of RDF as its preferred syntax in the future and to become one of the early RDF schemas. Work is currently underway to develop the mechanisms for representing Dublin Core resource descriptions in RDF.
Let us return to our simple RDF example showing a single property of the UKOLN metadata home page to see how it might be represented using Dublin Core in RDF.

<RDF:RDF>
<RDF:Description
RDF:HREF="http://www.ukoln.ac.uk/metadata/">
<DC:Title>The UKOLN Metadata Home Page</DC:Title>
</RDF:Description>
</RDF:RDF>
Rather than the simple "Title" propertyType we are now explicitly using "DC:Title", i.e. we are using the Title propertyType from the Dublin Core namespace.
For this to be valid XML we must explicitly declare the "DC" namespace using the following syntax:
<?xml:namespace ns="http://purl.org/dublin_core/schema/" prefix="DC"?>
Notice that this declaration shows the string prefix that will be used in the XML that follows. It also gives the URI that is associated with the namespace. Currently the URI in this example does not resolve to anything, it simply uniquely identifies the namespace. In the future it is likely that namespace URIs will resolve to a schema definition for the namespace.
There is also a second namespace in our example, the "RDF" namespace. This is the namespace within which the various RDF specific tags are defined. Therefore, we must also include a declaration for this namespace. So our completed, though minimal example of Dublin Core in RDF becomes:
<?xml:namespace ns="http://www.w3.org/TR/WD-rdf/" prefix="RDF"?>
<?xml:namespace ns="http://purl.org/dublin_core/schema/" prefix="DC"?>
<RDF:RDF>
<RDF:Description
RDF:HREF="http://www.ukoln.ac.uk/metadata/">
<DC:Title>The UKOLN Metadata Home Page</DC:Title>
</RDF:Description>
</RDF:RDF>
RDF is still under development and the XML syntax is subject to change. The examples in this paper are based on the February 1998 version of the RDF Model and Syntax draft. Despite this lack of stability there has been some experimental development of RDF compliant software. Mozilla [12], Netscape’s source code release of their Web browser, uses RDF as the basis for its bookmarks and history lists. Several RDF toolkits and editors are also beginning to be made available including DC-dot [13], a Dublin Core generator developed by UKOLN, and Reggie [14], a generic metadata editor developed by DSTC in Australia.
This paper has given brief introductions to both RDF and the Dublin Core. It has attempted to show that RDF is a general-purpose architecture providing structured, machine-understandable metadata for the Web. RDF schemas give us a mechanism for developing metadata applications without central co-ordination- in a way that allows us to make use of existing schemas where they exist. Finally, Dublin Core looks likely to become one of the key RDF schemas.
UKOLN is funded by the British Library Research and Innovation Centre, the Joint Information Systems Committee of the Higher Education Funding Councils, as well as by project funding from the JISC’s Electronic Libraries Programme and the European Union. UKOLN also receives support from the University of Bath where it is based.