Andy Powell, UKOLN, University of Bath
18 Sept 2004
DCMI has two documents concerning the use of Dublin Core metadata in RDF. The first, Expressing Simple Dublin Core in RDF/XML is a 'recommendation' and describes how to encode simple DC in RDF/XML. The second, Expressing Qualified Dublin Core in RDF / XML is a 'proposed recommendation' and describes how to encode qualified DC in RDF/XML.
More recently, the DC Architecture WG has been developing a DCMI Abstract Model which provides a reference model against which particular DC encoding guidelines can be compared.
The Abstract Model defines a terminology that includes the following terms (the definitions are repeated here for clarity):
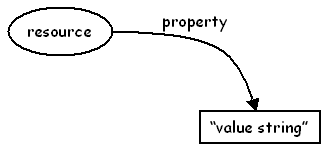
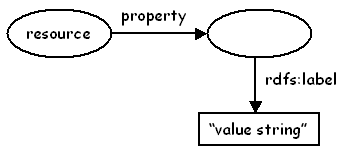
One issue with the two DCMI documents for encoding DC in RDF/XML is that they each recommend a different mechanism for encoding the value string that represents the value of a property. In the simple DC recommendation, a construct represented by the RDF graph in figure 1 is used. This construct uses a literal string as the value of the property. In the qualified DC proposed recommendation, a construct represented by the RDF graph in figure 2 is used. This construct represents the value of the property as an intermediate (often blank) node, allowing further properties to be used to describe the value resource, including a simple value string (using rdfs:label).
|
|
|
| Figure 1 | Figure 2 |
|---|
In terms of the Abstract Model both these constructs represent the same semantics - they both represent a resource URI, a property URI and a value string. However, in terms of the RDF model, the two constructs are different - non-DCMI applications would not recognise the two graphs as being synonimous. Perhaps more importantly, the use of these different constructs in a DCMI recommendation and a DCMI proposed recommendation has led to some confusion in the RDF implementor community, with some people following one recommendation and others following the other. The confusion is particularly accute where the resource represented by the intermediate node is relatively obvious, for example a person or organisation, as is the case with the dc:creator, dc:contributor and dc:publisher properties. This potentially leads to less interoperability between DC metadata applications than might otherwise be achieved.
Note that DCMI currently makes no recommendations about the class of the intermediate node, nor about whether it should be assigned a URI or be generated as a blank node.
The remainder of this document reviews some possible options for dealing with this situation.
Do nothing. Live with the current levels of confusion, such as they are. We've survived so far! Continue to recommend the two forms of encoding and leave implementors to decide which form best serves their need.
This option is the easiest for DCMI, since it requires no action. However, it does nothing to reduce the current levels of confusion in the implementor community and it doesn't bode well for future interoperability between DC-based implementations of RDF/XML.
Since writing this document it has been pointed out to me that there is a stricter interpretation of 'status quo' which is to only support the current 'simple DC in RDF' recommendation and ignore the 'qualified DC in RDF' proposed recommendation - on the basis that the 'qualified DC in RDF' document has never become a recommendation and therefore shouldn't be being used as the basis for deployment. While I have some sympathy for this, I'm not clear that it helps solve our problems.
This option would make recommendations to the developers of DC-aware software applications about how to handle the metadata records that they consume. For example, we could make a single recommendation along the following lines:
This option providers greater clarity for the DCMI community but doesn't to much to facilitate better interoperability between applications that are not aware of DC conventions.
This option would make recommendations to the developers of DC-aware software applications about both how to handle the metadata records that they consume and how to generate metadata records. For example, we could make two recommendations along the following lines:
Note that it might be argued that recommendation 2 is unnecessary given recommendation 1, since if DC-aware software applications that consume metadata records are allowed to treat the two constructs as synonimous then it does not matter which form other software applications generate. However, the intention of recommendation 2 is to provide a greater level of interoperability between DC RDF/XML records from different sources when they are consumed by software applications that are not DC-aware - i.e. that have no knowledge of recommendation 1.
This option effectively deprecates DCMI's simple DC in RDF recommendation in its current form, since it essentially recommends against following the guidelines in that document. The current simple DC in RDF recommendation would need to be revised or merged with the qualified DC proposed recommendation in some way.
This option would attempt to convince the wider Semantic Web community that the two graphs above are semantically equivalent. This could be done via the appropriate W3C specifications or by some lighter-weight implementor agreements.
This option has the advantage of leaving current practice on the part of implementors unchanged, but still achieves a high degree of interoperability between RDF applications, whether they are DC-aware or not. Clearly, DCMI would have to work with the W3C and the Semantic Web community to achieve this end.
Note that since writing this document it has been pointed out to me by PeteJ that this option is not sensible, because the two forms are not synonymous in terms of RDF, and never will be. Furthermore, there are good examples where one wouldn't want them to be treated as meaning the same. So I think we can forget this option!
This option would replicate the existing DC properties as new properties with essentially the same semantics as they have now but defined in such a way (using RDFS) that it is explicit that the value of the property is another resource.
For example, DCMI could declare a new term, dcterms:Creator, with essentially the same semantics as dc:creator but with the RDFS declaration of the new term making use of the rdfs:range construct to explicitly indicate that the value is a resource of class dcterms:Agent.
This option would have far reaching consequences for the exitsing usage of DC metadata and for the existing encoding guidelines.
Of the options presented here, my view is that option 1 is no longer tenable if we want DC to remain a credible standard in the development of the Semantic Web. I also think that option 5 is too drastic for DCMI to consider at this stage in the lifecycle of the standard.
Of the remaining options, option 4 looks interesting but my suspicion is that the Semantic Web community will not be willing to move in this direction. Option 2 doesn't go far enough in terms of ensuring interoperability.
Therefore, my personal view is to move forward with option 3 at this stage. This option will require some reworking of existing DCMI recommendations but it doesn't rule out option 4 happening at some future time if this is deemed to be appropriate by the wider community.