Lorcan Dempsey and Rosemary Russell
UK Office for Library and Information Networking, University of
Bath, Bath, BA2 7AY, UK
{l.dempsey; r.russell}@ukoln.ac.uk
and
Robin Murray, Technical Director, Fretwell Downing
Informatics, Ecclesall Rd, Sheffield S11 7AE.
rmurray@fdgroup.co.uk
This is a preprint version of: Lorcan Dempsey, Rosemary Russell, and Robin Murray. A Utopian place of criticism: brokering access to network information. Journal of Documentation, 55(1), 1999. p 33-70. Please quote the printed version in any citation.
The management of autonomous, heterogeneous network resources and services provides new challenges which libraries are now addressing. This paper outlines an approach based on the construction of broker services which mediate access to resources. It outlines a framework - the MODELS Information Architecture - for thinking about the components of broker services and their logical arrangement. It describes several development projects and services which show how brokers are developing. It uses examples drawn from the serials environment to describe some of the issues.
Technologists understand that they must build more stable and unobtrusive media. They must establish more coherent contexts into which the technology may disappear.
Malcolm McCullough. Abstracting craft: the practiced digital hand.[1]
Alberto Manguel has a chapter on libraries and librarians in his recent A history of reading.[2] He calls them "Ordainers of the universe", an epithet used, he tells us, by the Sumerians. He dwells on the efforts of Callimachus to ordain the order of books at The Library of Alexandria, and notes that:
According to the French critic Christian Jacob, Callimachus's library was the first example of a "utopian place of criticism, in which the texts can be compared, opened side by side".[3] With Callimachus, the library became an organized reading-space.
For many years, libraries have refined the techniques developed by Callimachus. They have created physical places and intellectual reading-spaces which connect their users to resources in useful ways. They have evolved well-understood internal practices and procedures for management, and predictable ways of presenting services for their users. In this they have been assisted by the evolving technologies of print and publishing, as well as by internal library technologies. Books and journals come in accepted formats, which support some consistency of treatment and arrangement, which allow the advance construction of shelves and processing equipment, the assignment of space, and so on. They only exceptionally require separate introduction or special treatment: these particular technologies have become unobtrusive, experience of them submerged in the practice of reading. Libraries have also developed an intellectual apparatus for the organisation of their resources in various ways and with various goals (to collocate works by authors, for example). The physical and intellectual apparatuses are meshed together in different ways.
Libraries are now faced with the challenge of recreating this role in a new kind of space, the space of flows supported by the worldwide span of networks. Writing about access to networked information, Richard Heseltine remarked:
What I am more concerned about is the need to make the desktop working environment of the end-user simple and easy to operate. End-users are being confronted now by a multiplicity of systems and services: for obtaining information; for communicating; for taking delivery of documents, and for producing documents. We need to have much better models of how all these services should fit together from the point of view of the end-user. What are the key standards? What are the most effective means of presenting services? This is not just a matter of user interfaces but of the means of bringing everything together in a real working environment. [4]
Heseltine's concern is echoed in a recent UK Higher Education policy document[5] which lays out a view of how national information services should develop alongside local provision as part of a Distributed National Electronic Resource (DNER):
Integration is the key, allowing the user to move more easily between different information functions; more easily across all services (...); and to use from the desktop, the emerging tools for exploiting networked information, for more intelligent and standardised searching and retrieval, for locating material, requesting and receiving it, and for making appropriate use of all forms in further analysis and research.
What is being suggested in each case is an "organised space", in which resources may be used "side-by-side" in a "real working environment". However, this environment is not limited by the PC or the local library, it is an environment which may reach out in space and time: in space because the network spans the globe; in time, because users may be supported more persistently - by some combinations of personal profiles, agents, alerting services, or configurable, adaptive environments. It is also a space in which there are new divisions of labour in the learning and information domains (as for example in document supply, where publishers, libraries and aggregators are realigning the pattern of delivery), and new forms of user behaviour and expectation (as for example, where communication technologies are reaching into writing and learning environments).
How such `integration' will be constructed is a research and development challenge. Current digital environments are in early stages of development. What integration there is tends to be rather shallow, typically at the user access level where the Web has become the approach of choice. Pages of links, perhaps a database of resource descriptions[6], provide a level of integration at the discovery stage, but resources themselves are differently presented, accessed, structured. They remain individual, unconnected opportunities. A user may have to interact with quite different information systems to carry out a full search, for example. Furthermore, individual tasks rather than end-to-end processes are automated: the emphasis has been on getting individual systems to work - the ILL system, access to BIDS, the CD-ROM network -- rather than seeing them as part of a wider information environment which needs to be linked in various ways. These systems do not connect to each other. Information flows intermittently through supply chains, which are fragmented and incomplete.
Part of the challenge is that "standardization efforts are lagging behind the development of digital library services"[7]. The standards infrastructure is not yet achieved enough to make the management and use of electronic resources routinely predictable in the way that the management and use of print resources is. We do not yet have a "coherent context" into which the technology can disappear: difference and distraction are very much on the surface, data does not cross system boundaries. Libraries have evolved ways of combining components to provide services. In the digital environment, components do not work well together.
This is a serious issue, and we suggest, the most significant barrier to pervasive deployment of networked information systems as part of users' normal working practice. It is this development deficit that is driving the current interest in digital library research.
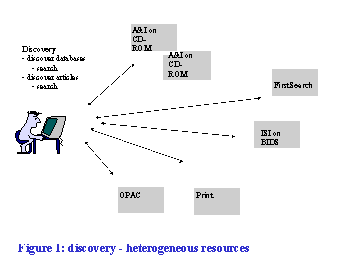
It would be useful to make some of `integration' issues more concrete with specific examples. The serials literature presents some particular challenges[8], which highlight more general issues, and we use it throughout this article to illustrate issues and trends. Take a simple example, which we have introduced elsewhere.[9] A project group wishes to discover journal articles and books about Roman Bath. In a well-stocked library, they can scan the shelves. Say they want to do a more thorough `discovery' of material. They can look in the catalogue. They can look in databases on CD-ROM. They might have access to some remote databases over the Internet. But each of these is delivered through a separate interface, they may have to move between machines, they may have to print out or write down results. They also have to know which databases to look in: in fact there may be very relevant resources which they will fail to use if they are not directed to them by staff. Figure 1 shows some of the resources which may typically be available to users.
Once they have discovered a selection of materials, they may have to find out where they are. Typically, they will have to return to the catalogue and redo searches for the desired titles. Say they are in a library which has an arrangement for reciprocal borrowing with several neighbouring institutions: they will have to redo searches for unfound titles in those libraries' catalogues. They might bring other items to the Interlibrary Loan department, where they may have to write down the details again. Then the ILL staff may repeat some of the operations already carried out by the users. Requests may then be sent for materials. Bibliographic details may be rekeyed for transmission.
Within the MODELS project (described further below), it has been found that the type of behaviour that we have just described can be represented in terms of a limited number of logical functions: `discover', `locate', `request', and `deliver'. These map well onto user behaviour and the services required to support it. Clearly, this list could be extended, to include `use' for example, but we have focused our attention on these four, which cover a large number of cross sectoral service scenarios and business requirements. They represent services provided in current library environments. (One of the issues which libraries need to address in this new environment, and it is part of the rationale for the development of `learning resource centres', is support for use, analysis and reuse of digital resources, but this is not treated further here.)
We have described an environment in which there is a variety of boundaries - between functions, between users and library - which are not interconnected by systems, and across which data does not flow. The `connections' are made by human effort: users repeat operations on different systems, consult staff, transcribe details. This wastes time and imposes barriers to full use. Some of the services which may have to be interacted with are shown in Figure 2. The current situation has some important characterstics:
There are clear integration challenges: service autonomy, heterogeneity, and geographic distribution will remain the rule. This is the case with the serials literature. It is very much more so when we consider the wider range of resources that are of potential interest to a user.
The current situation, as sketched above, is unsustainable for two broad reasons: it is wasteful of users' time and energies, and it poses growing management problems for libraries which need to move to routine ways of managing hybrid collections. Current electronic information services are underdeveloped: they do not allow easy integration with users' working environments, and they present case-by-case problems to libraries. This leads us to argue that a growing factor in the assessment of individual services and resources will be the ease with which they can become part of a wider environment of use. This will be a managed environment, which delivers added value to users and which develops procedures and practices which support economies of operation.
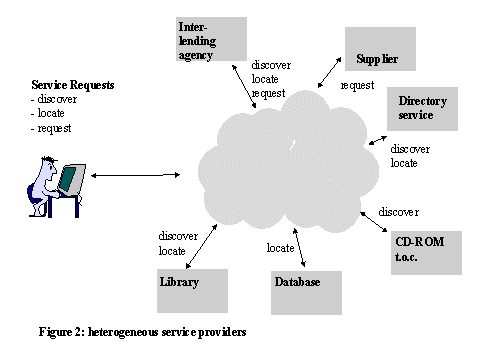
In terms of Figure 2, the challenge is to construct the cloud in the middle. This is `middleware', an additional service layer, which shields the user from complexity, heterogeneity and multiple mechanical actions. It provides a higher level interface, creating a federated resource from underlying heterogeneity and mediating access to it. In this article, we use the term `broker' for this box. To create this service requires high levels of inter-operability, both between servers providing the same service (eg. two search services) and between different services (eg. between locate and request).
We refer to these two types of interoperability as `intra-function' and `inter-function' respectively. Intra-function interoperability suggests the ability, for example, to search across several resources, or to have a request relayed to several different request systems.
Inter-function interoperability is where these functions communicate with each other by passing data between them. There is a high level of inter-function integration in a simple web environment, which is what makes it such an attractive tool to users, who can discover, locate, request, and have delivered materials with a few clicks. The environment we have discussed is a more heterogeneous one, in technical and service terms. There is currently much greater 'friction' in the system, as intra- and inter-function integration are lacking.
Interoperation benefits from standard, predictable application interfaces (for search and retrieve, for requesting, and so on, which will allow data to flow between applications and between applications and user systems), and on metadata (data which supports operations on resources, and which helps users and applications behave sensibly). More recently there has been significant renewed interest in identifiers[10],[11] and in issues of authentication and authorisation.[12],[13] However, we are always likely to be some way from a completely standards-based environment, and customised links also have to be created. Together, these form the infrastructure or `glue' that will allow the construction of broker services. The focus has been on individual technologies; attention is now turning to how they work together to support useful services. This is turn has created significant interest and development work to provide support for communicating software components. CORBA (Common Object Request Broker Architecture) and DCOM (Distributed Component Object Model) have emerged as principal specifications for such environments.
Our approach has been somewhat influenced by such developments, but is more concerned with modeling aspects of the information environment in which applications will be built. Some advantages of such an approach are that:
The MODELS Information Architecture (MIA) aims to provide a framework within which such issues can be addressed. The MIA is aligned with wider work which sees the development of `middleware' or `broker' services as a central part of how the information environment will develop. It is concerned with the types of function such `broker' services need to provide as they help project a unified service over a distributed, heterogeneous set of network services. It has a dual focus: as a conceptual heuristic tool for the library community which helps clarify thinking and acts as a lever for development, and as a tool to assist developers as they think about future systems work. The main emphasis has been on the former aspect. The MIA investigates the functional components of viable digital information environments and arranges them in a logical architecture: it does not yet specify how components will be implemented, or concrete interfaces.
MODELS (Moving to Distributed Environments for Library Services)[14] is a UKOLN initiative with additional support from the Electronic Libraries Programme, with some support also from the British Library. It has progressed through a series of workshops, background research and technical consultancy to work towards consensus on these issues. It has initiated several studies and has influenced policy and emerging services in the UK.
This paper further develops a discussion of the current information environments, introduces the MIA, and describes several current development initiatives which show how MIA-like service environments are emerging. Throughout the MODELS project, it has become clear that many of the issues addressed are generic across several information domains: they are not library-specific[15]. While the focus of this article is on library issues, discussion of current development work points to a wider context.
MODELS has focused on the `hybrid' library environment, characterised by the aim of constructing unified information spaces across existing, place-based library services, and emerging digital information spaces. These issues have had to be addressed in the various applied research and technical development programmes: the EU Libraries Programme (a colloquial term for activities managed by the Libraries Unit of DGXIII through Framework Programmes III and IV)[16], the Electronic Libraries Programme of the Joint Information Systems Committee of the Higher Education Funding Councils in the UK (eLib)[17], and the US Digital Libraries Initiative.[18] We trace the emergence of distributed library services in Europe elsewhere, with some focus on developments within the European Libraries Programme.[19] Work here has tended to be implementation- and demonstrator-oriented, and to have proceeded with a project-based focus, although there has been some investigation of library application models in the light of changing network environments.[20] There has been collaboration on a programme-wide basis, and further, on particular technologies, but rather less on broader architectural issues. The approach developed in this paper provides a good framework for understanding and relating many of these developments. This is especially so as the initial emphasis on the construction of component building blocks has now switched to the construction of production services based on integrated systems and products.
A similar situation exists within eLib. In this case, participants are working with MODELS as a tool in developing service scenarios, and the `clumps' initiative flows from it. A `clump' is a term used for services based on unified access to physically distributed catalogues, several of which are being funded under eLib.[21] The integration ideas underlying the DNER have been influenced by MODELS and we will continue to work with policy and service actors in this area.
The Digital Libraries Initiative in the US has had a different remit to either of the above programmes. It has been rather more research-led, with a computer science focus. It has also been rather more `digital' than `hybrid'. This has meant that there has been a more explicit architectural focus. In particular, the Stanford Digital Library Initiative has a specific emphasis on interoperability, and is pursuing a suite of related investigations within a distributed object environment, based on CORBA (Common Object Request Broker Architecture). Project collaborators note[22]:
In the Stanford Digital Library project, we view long-term digital library systems as collections of widely distributed autonomously maintained services. While searching services are valuable, they are not the only kind of service in the digital library of the future. Remotely usable information processing facilities are also important digital library services. These services provide support for activities such as document summarization, indexing, collaborative annotation, format conversion, bibliography maintenance, and copyright clearance.
Our project has focused on developing an infrastructure in which these disparate service can communicate and interoperate with one another. Our digital library testbed is providing an infrastructure that affords interoperability among there heterogeneous, autonomous components, much like a hardware bus enables interaction between disparate hardware elements. We call this infrastructure the InfoBus.
In building the InfoBus, we needed to provide services for finding resources likely to satisfy a given query, for formulating queries that are appropriate for multiple sources, for translating queries, and for making sense of query results.
The Stanford project has a research and implementation focus. In developing a distributed object model, it is consciously in advance of current implementation and experience.
Paepcke and colleagues from Stanford have recently presented an interesting discussion of digital library interoperability issues.[23] They identify a variety of modes of interoperability. We briefly consider three here to locate our discussion in a wider context. The first is `external mediation', where what they call the "interoperability machinery" is located outside the participating local systems to mediate between components. This machinery translates formats and modes of interaction, and where systems are standards based such mediation is facilitated: "For example, in an external mediation system providing interoperation for highly autonomous search components a single mediation facility covers all Z39.50 resources at once". A second is "specification-based interaction", where the goal is to "describe each component's requirements, assumptions and services so the components can interact with other after inspecting and reasoning about each others' specifications." A third they call "mobile functionality", which accomplishes interoperability by "exchanging code that `does the right thing' to communicate successfully among components". The latter two approaches will become more common in a distributed object environment. Discussion in this article leans towards the "external mediation" mode, not because the MIA assumes it, but because most of the development work we consider follows that mode. The discussion shows the growing importance of metadata, to describe services, applications and other components in a distributed environment.
MODELS has been developed within a library context, but it is clear that many issues are generic across other domains which involve managed access to, and use of, network resources. There are points of contact or comparison with ongoing work in other domains: other curatorial traditions (e.g. archives, museums[24]), geospatial data[25], humanities computing[26], distributed indexing of Internet resources[27], electronic product catalogues[28], and other areas.
In this section we put the above discussion in a wider context, by linking it to a more general account of the emerging technical environment, by considering in more detail the issues of providing distributed article discovery and supply, by briefly considering the wider information environment, and by introducing some of the services a broker might provide. We continue to consider the emergence of broker-based services alongside an examination of access to the serials literature.
Consider the progressive development of network information systems as presented in Figure 3 and Table 1. We suggest three layers: user layer (U), organisation layer (O), and a layer of resources and services (R/S). In a first phase, monolithic applications are accessed by separate interfaces, often indeed, by separate terminals. By monolithic, we mean that data and software are integrated and that the user communicates via terminal access; there is no flow of data between applications: there is no integration at that level. In this phase, there is little support at user or organisation layer. In a second phase, which is the current dominant phase, the Web provides a unifying user layer. Increasingly, the web is the de facto desktop user route into resources. The web also provides a very shallow framework for organisation of the underlying resources and services. In phase 2, we see unified web-based presentation to the user over largely monolithic, heterogeneous applications.
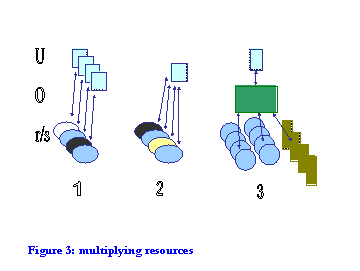
In phase 3, the emergent phase, we see the introduction of broker services, which support flexible presentation of a range of underlying services. This layer adds value to the lower layer of resources and services by supporting their presentation as a unified service according to a particular business logic, rather than as a set of separate opportunities. We have discussed the motivation for this development above.
|
User presentation |
Organisation |
Resources and services |
|
|
Phase 1 |
Independent |
- |
Monolithic applications |
|
Phase 2 |
Unified |
Shallow - presentation only |
Monolithic applications - data and application |
|
Phase 3 |
Flexible |
Unified |
Server based services, maybe accessible in several ways. |
It is now a familiar way of organising network applications, and is supported in a variety of business and application domains.
In the current network environment, services are typically made network accessible in one of several ways, which are successively characteristic of behaviour in each of these phases:
These modes of access correspond approximately to the three phases identified above. In the WWW and terminal examples the client software just responds to user interface directives such as `display this text in bold italics' etc. These services are largely oriented around providing services to human users, who then have to process the results.
When the client software understands the data it is handling, it can be reused in various ways, the results can be processed. The client software is responsible for the representation of that data to the user, and is capable of shielding the user from differences between servers. It can be reformatted for display alongside records from other resources. It is also capable of providing increased levels of inter-operability between multiple servers that perform discreet activities within, for example, the discovery and request operations we discussed above. For example a document identifier or citation found from a discovery session on one server can be passed to a `locate application' which may use it to query against a holdings file.
It is unlikely that users will have application clients on their desktops; typically they will have web browsers. Client functionality will be built into intermediate systems or brokers (i) which access end systems (e) on users' behalf (Figure 4).
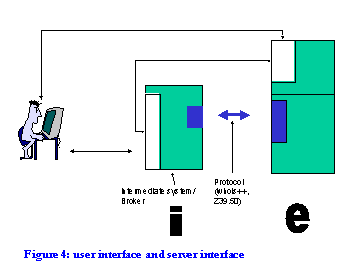
This suggests that increasingly services will be provided which may be accessible to human users through the web, or to intermediate systems through some protocol. In the latter case, machine-readable structured data will be returned for reuse in some context; in the former human-readable results will be returned for reading. So for example an OPAC may have a web interface for human access, and a Z39.50 interface for `clump' access. Brokers talk to machine interfaces.
It should be noted that this outline represents the current web environment. In this, the web is primarily a medium for passive information transfer, with some support for interactivity through CGI scripts and other techniques. We are seeing significant development in the web community which will provide support for the exchange of structured data, for distributed objects, and for a range of security and other services which will significantly enhance the development of web-based information processing applications. The development of XML - extensible markup language - is providing the basis for a variety of applications based on structured data, and together with support for communicating software objects (for example, the Internet Inter-ORB Protocol), will transform the web into a platform which supports distributed transaction-oriented applications.[29]
In passing, it should be noted that the emergence of the `structured web' raises issues for the further development of distributed library and information services and the approaches which have evolved in their support. It will be interesting, for example, to see whether a search protocol is developed in the web environment, and what impact this has on Z39.50 or other specialist approaches which predate current developments. Given the strategic importance of the web, it is likely that many communities will reengineer existing approaches to take advantage of developments there. [30]
We have identified some broad-based service goals for brokers:
Some examples of such services can be provided from current developments. In each case, an application, or `external mediator', mediates access to diverse resources and supports data flow. The broker will be designed to support a particular business need. For example, the eLib EDDIS project has developed an application that will provide some of the integration in the serials are that we have suggested is lacking above[31]. It brokers access to discovery, locate, request and delivery services in a distributed document supply context. Agora, to which we return in more detail, is an eLib hybrid libraries project which will extend EDDIS to look at other media and resource types. It will be designed to support access and use of print and electronic content of the `hybrid library'. The Arts and Humanities Data Service (AHDS) Gateway, also described in more detail below, projects a unified picture of the AHDS based on a federation of five underlying, autonomously managed service providers. The Gateway provides a service which hides the different access mechanisms and data formats of the heterogeneous systems in use at service provider sites, and provides authenticated document requesting services. Another example can be provided by the `clump' projects, already mentioned; these are funded by eLib to provide virtual union catalogue services across different underlying OPACs. Yet another example is provided by the ROADS cross-searching service. ROADS (Resource Organisation And Discovery in Subject-based services) is an eLib funded project which is providing a set of tools for the UK subject gateways, databases of descriptions of Internet resources. The cross-searching service provides a query routing and referral service between the autonomously managed subject gateways.[32] Gazebo, developed by the National Centre for Supercomputing Applications, is Internet server software which allows clients to query and browse results from multiple data sources simultaneously.[33] These provide early examples of the type of facility that is likely to become more common across a wider range of resources.
The focus of some of these developments is discovery: to varying degrees, they hide differences and collate the results from several different underlying discovery systems. Some go beyond this to address several functional areas and allow data to flow between them. For example, EDDIS passes data about selected articles from a discovery to a `locate' function where it may be matched against some holdings data; data may then be passed to a request function, where it forms the basis of a request message. It hides the difference between different discovery systems and different request systems. There have been `gateways' and other intermediary services in the past. What characterises these initiatives is that they are based on standard machine interfaces which allows them to interact with arbitrary resources which support the same interfaces. They are a move towards a `plug and play' environment, which is seen to be essential in the type of distributed, indefinitely large resource space we have discussed. They currently largely operate with data that is well structured, or is amenable to being so structured. While they are largely `bespoke' applications with standard interfaces to the outside world, we will gradually see more fully distributed applications emerge based on distributed components specialised by function and assembled as required.
MODELS has generalised the services provided by such `brokers' in the following way:
These are logical functional groups which have worked well when measured against a range of emerging developments, and are further explicated in discussion of the MIA. The advantage of such an approach is that it separates different aspects. So if a service is offered through a different protocol, or if a new service is added, it should not be necessary to change the user access level. The appropriate transformations will be effected in the middle layer. Similarly, users may see available resources through different landscapes without having to alter the way in which those resources are organised. We begin to see how new resources might be routinely `shelved' by being added to the lower layer. We also begin to see how the flexibility introduced in the user access layer makes it plausible to consider a variety of customised approaches into the available resources.
We have explored how the current library electronic information environment is fragmented in much the way we describe in phase 2 above, with special reference to the journal literature. Some of the issues can be made clearer if we look at the actual technical environment of article discovery and supply in some more detail, and relate these issues to our description of the broker services. To do so is to be reminded of remarks quoted earlier of how standardisation is lagging behind actual digital library development requirements. (We explore some of the standardisation issues for serials elsewhere.[34])
In current automated systems, the `discovery' system is very underdeveloped. It tends to be limited to a series of once-off searches in discrete databases. Future services will need to be richer in various ways:
The discovery function may depend on a single search in a bibliographic database, or it may depend on processing of several potential searches and their results:
This data could be served up in different ways. Bibliographic data might be available through Z39.50 servers, data about bibliographic data sources might be available through the explain service of Z39.50, it might be made available through a directory service (e.g. LDAP - Lightweight Directory Access Protocol). User profiles might be made available in a number of ways including a directory service.
We can identify several current impediments. Currently, there is no widely deployed directory-type service in the UK; this means that local systems have to be configured with environment information. There is no agreed way of representing user profiles or database content. Experience with Z39.50 is still limited. Although there has been a steady growth in number of Z39.50-based services and of Z39.50 client capability, there is little production use as yet in the UK. This may change in the light of the eLib phase three development discussed above. The Z39.50 `explain service' is not yet widely deployed. Other search and retrieve protocols, WHOIS++ for example, do not have widespread use in this environment.
Within libraries, the locate function presents a challenge which arises from a historical accident in the way libraries provide access to the print literature.[35] Typically, the library catalogue provides access to journals at the journal title and issue levels, rather than at the article level. It says what titles are in the library, and sometimes which issues. Abstracting and indexing services say what articles are in the world, they do not typically say where they are or who might provide them. There are no tools which `locate' articles in the library, and, in the absence of widely deployed concise identifiers for journal articles, location is largely a manual process. Automation of this operation would confer many benefits, and will be increasingly necessary in emerging service environments where documents may be sourced from multiple locations (for example, from a resource sharing consortium, from publisher databases, from document suppliers).
Depending on the level of indexing employed at a specific database, users wishing to ascertain the potential availability of a required article may need to interact with bibliographic information at three distinct levels :
Depending on the level of indexing and the level of standardisation employed, inter-operability between the discovery and locate functions may be performed in a number of ways:
Having ascertained that a particular supplier potentially has the required article, holdings level information may provide the current availability status - this may either be the `circulation status' for physical items or format information for electronically available items. At this point the user may wish to know the choices in terms of availability for the item, this is especially important where multiple potential suppliers are being consulted simultaneously.
Again we can identify some impediments in the current environment. The locate function depends on search services, and a name resolution service (which returns bibliographic details for a SICI) or special procedures to match records. The SICI is not now widely deployed. Holdings data for serial articles are not widely standardised[38 ]; in fact, in a UK environment, there is considerable diversity of technical and service approaches. Nor are there agreed ways of representing terms and conditions data[39].
The identification of the required item, along with the preferred terms of availability and delivery mechanisms must be passed from the locate to the request process. The request itself must also carry order information (delivery address, billing address etc.) to the supplier. A request transaction may involve many messages passing between requester and supplier since it must cover the entire lifecycle from a request being placed to successful/unsuccessful completion. For inter-operability at the business as well as system level there must be a common understanding of the meaning of these messages and the effect they have on the status of the request. Interesting issues are raised in a heterogeneous physical and electronic document delivery environment where the life span of a request may be anything between milli-seconds and years. A user should be able to query the status of a request at any stage. Furthermore the request may mesh with with the exchange of business messages surrounding the transaction.
Similar impediments exist here. Request requires an agreed way of transmitting request information. There are a number of ways of doing this, none of which is widely deployed. The ILL protocol and Z39.50 item order extended service are being looked at in several contexts. EDI also has a potential role here but does not seem to have been widely deployed in this context. Several proprietary systems are in use by document suppliers, including the British Library Document Supply Centre.
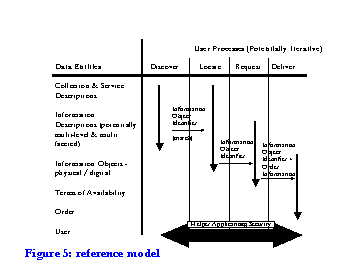
The discussion of serials literature is summarised in Figure 5, which outlines user processes or functions and the data entitities that support them.
We can relate this back to the broker discussion by outlining the concrete service scenario to be realised in the Agora prototype (see Figure 6). This will provide a service in Autumn 1998 and will provide a view over a social science subset of resources. Several databases will be available for searching for discovery purposes: general purpose union catalogues, specific social science resources, and a library catalogue specialising in social sciences (British Library of Political, Economic and Social Scences). Several databases will also be available for location purposes, including a union catalogue, a BLDSC resource, and a library catalogue (University of East Anglia). Requests will be sent to the BL, to a group of libraries, and to an individual library.
Figure 6: AGORA prototype
As the project develops, the aim is to begin to explore managing a wider range of services in real library service environments.
The above discussion focuses on journal articles. Libraries, and other intermediaries, are exploring how to provide managed access to other types of resource: internet resources, geospatial data, archives and museums resources, data and text archives, and so on. We are seeing the emergence of a network environment in which there will be an indefinitely large number of repositories. These will be embedded in various technical, service and business environments.
The extent to which the library seeks to offer access to the intellectual record in all its manifestations is one of the issues facing it over the next several years. Whatever the ambition, it will involve partnership with a range of professional and service sectors.
A characteristic of the network environment is that it brings within the same `organised space' materials which previously were compartmentalised within particular professional or sectoral services. For example, the recently published New Library: the People's Network looks forward to a renovated public library service. It discusses community information, cultural heritage materials, business information, Internet resources, and other information types.[40] Users have cross domain information needs. That is:
... they require access to information about relevant materials irrespective of where, how (e.g. as books, audio tapes, digital objects), or by whom (e.g. librarians, data archivists, museum curators) they are stored, and regardless of the manner in which they are described or catalogued. ... A university, for example, may wish to enable students and teachers to discover scholarly materials irrespective of whether information about those materials is described and organised differently in separate library, archive, and museum information systems. It may further seek to integrate information to a particular range of externally managed Web-based information resources.[41]
A reader interested in the history of Leeds may wish to look through local printed materials, but also search local history image databases, archival resources, as well as Internet search services and a range of other resources, which may be within or without library control. Information about Roman Bath will not be confined to the journal literature. Books and serial articles, demographic and other social data sets, and images are equally relevant to the cultural historian interested in the image of the city in modernist literature. The child doing a school project on butterflies and evolution may wish to look at images in the Natural History Museum, an encyclopedia article, and several journal articles. A teacher may wish to look for instructional materials and articles on a topic. And so on ...
This at once makes the issue of providing broker services more pressing and more complicated. The addition of new resource types means that additional formats and interfaces may need to be understood, but the approach we have discussed is extensible in that way and the development work we discuss below is drawn from several domains. Without such an approach, the twin problems of user frustration and management overhead will be further exacerbated.
We have already introduced aspects of MIA in considering the construction of broker services. Here we present it more formally.
MIA is based around the broker model. The broker or `trading place' is a venue where service requests and service providers come together. Services are `advertised' in the broker.
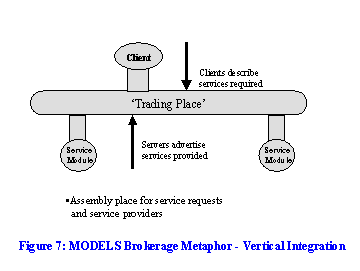
These terms may be familiar from a distributed object environment, but we intend no specialised meaning here. A broker may be a set of annotated web links; it may deploy a more sophisticated apparatus which supports a richer business model or quality of service.
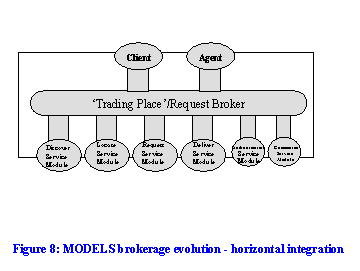
The broker provides infrastructure for managed access to physically distributed resources. In the examples we discuss below, the broker is provided by a bespoke piece of software which integrates particular capabilities. They follow the `external mediation' mode discussed above. Other modes may also be supported, where CORBA and DCOM have emerged as means of supporting communication between objects.
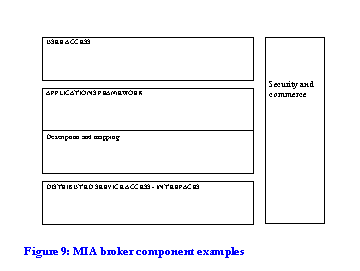
There are four broad functional blocks, which we have already introduced:
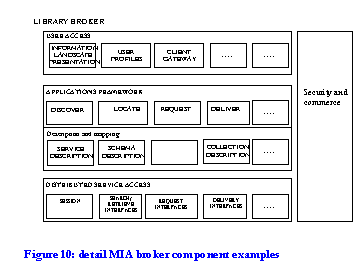
The functions we have been working with are:
Again, it should be noted that there is nothing definitive or exclusive about this enumeration of functions: it has been found to be useful in discussions and when measured against a range of services and applications. However, different business environments will require different functional support. They may also be refined or extended in various ways: for example, a `verification' function is introduced in the discussion of Edina below.
The broker needs to have access to various types of metadata to support its operation. This is data about its environment and the resources in it.
It is clear that metadata will be pervasive of distributed information environments. [42] Metadata will be associated with information objects, with applications, with people, with organisations. It will support operations by people and by programs, providing them with advance knowledge of the characteristics of objects of interest and supporting sensible behaviour. We have identified several critical areas:
In the current environment it is likely that brokers may be configured with this type of data. In due course it will be stored in directory services which the broker queries.
There are various ways to create machine- and human-readable descriptions of collections, applications and user profiles at the moment. None commands universal assent. Approaches may be embedded in particular application and/or professional domains. A review of some current approaches to collection and service descriptions has been prepared as part of the MODELS project.[44]
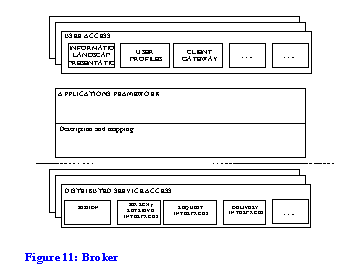
The user access layer may be realised in different environments: in a web environment, as a push based application, as VRML, and so on. Similarly, there may be several `bundles' of functionality in a service access layer.
As noted above, MIA has had a dual function: as a heuristic conceptual tool, and as a framework for development activity. In this section, several development activities are briefly described in relation to MIA. Some of this work is based on MIA, and some directly influenced by it. We also include descriptions of work on the Aquarelle and NESSTARR projects, which have developed in parallel to MODELS but whose insights are now being made available within the project. Other examples could be introduced.
Agora is a `hybrid library' project within eLib[45], which is directly based on the MODELS project. It is led by the University of East Anglia, with UKOLN, Fretwell Downing Informatics and the Centre for Research in Library and Information Management (CERLIM) as partners. It works with associate groups of libraries (who will deploy the solution in the context of their electronic collection management procedures), of service providers (who will interwork with the broker), and of system developers (who will pool technical knowledge). Some of these are listed in Figure 12.
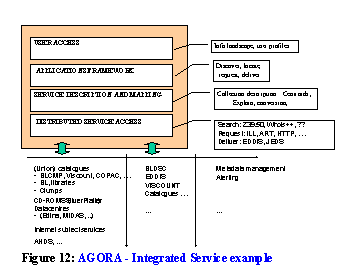
Agora will build on the existing eLib projects EDDIS and NewsAgent and will benefit from the metadata work of UKOLN. It will initially support a limited range of interfaces to remote resources. These will include Z39.50, the ILL Protocol, the British Library's ART interface to the Document Supply Centre, as well as the Web protocols. At the centre of the system will be a Hybrid Library Management System (HLMS) which will be a MIA-type broker. Within this context, the project will experiment with creating `landscapes' which provide integrated access to the types of services listed below. This is given here to outline some of the issues faced.
In this way, the project will bring together in a controlled environment access to discovery, location, request and delivery applications and services, and provide the library associate group with the tools to project a unified service to their users. [47]
Fretwell-Downing Informatics (FDI)[48] is currently implementing solutions based on the MIA architecture in a range of domains and service settings, from public library resource sharing (with LASER) to cross domain searching for research (with the Arts and Humanities Data Service).
FDI have been involved in the development of the MIA as consultants to the MODELS project. FDI view MIA as a framework for the design and actualisation of systems which are critical for the potential of networked information to be translated into real services. From the FDI development point of view, MIA has several important features. Firstly, it is designed to accommodate the interoperation of a range of services to meet a business requirement (for example search, locate, authenticate and request for interlending). Secondly MIA services can be applied to heterogeneous information resources, independent of domain (eg libraries and museums) and of format (eg MARC and EAD - Encoding Archival Description). These capabilities will be very important in providing implementations that are geared to end user needs - such as those of the researcher or distance learner who needs to access information, resources and services on the basis of research topics rather than by choosing services or by investigating repositories individually by domain or locale. In this context a third key feature of MIA might be emphasised: its provision for `forward knowledge' of resources and services through the mediation of a gateway based information landscape. This will map out who has what where, and on what terms.
The following projects illustrate FDI implementations in a range of environments:
The same framework has already been adopted for key sectoral and national resource sharing initiatives in Australia and New Zealand. [49]
The Arts and Humanities Data Service (AHDS)[50] is a national service funded by JISC to collect, describe, and preserve the electronic resources which result from research and teaching in the humanities. It has five geographically distributed disciplinary service providers: Oxford Text Archive (OTA), Performing Arts Data Service (PADS), Archaeology Data Service (ADS), Visual Arts Data Service (VADS), History Data Service (HDS).
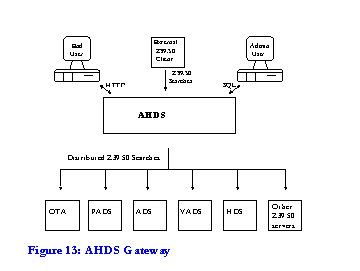
One of AHDS's key aims is to encourage scholarly use of its collections and make information about them available through an online catalogue. Each of the five AHDS Service Providers is developing their own catalogue with record structures which are most appropriate for their community's resources; e.g. the Archaeology Data Service will adopt an SQL-based database implementation while the History Data Service's catalogue will be SGML-based. However owing to the intrinsic interdisciplinarity of humanities research, the AHDS also needs to allow users to search simultaneously across its distributed, interdisciplinary, and differently catalogued holdings. Issues surrounding cross-domain discovery were explored at the fourth MODELS workshop in December 1996, which prepared the groundwork for the subsequent series of six specialist AHDS workshops[51]. These developed recommendations on metadata to support cross-domain resource discovery. Parallel to this, Fretwell-Downing was commissioned to develop a suite of resource discovery tools. This will provide a `gateway' based on Z39.50; it will exploit the unifying metadata format identified by the workshops. The development of the AHDS Gateway concept was influenced by the MODELS process and emerged in parallel with MIA.
The Gateway will enable users to query the AHDS's distributed holdings in an integrated way. Standard user access will be through a Web interface (although Z39.50 client access will also be possible) and will provide a single point of entry to the online catalogues developed by the five Service Providers. An `information landscape definition' will provide users with a contextualised map of the information and services available from the gateway. `Dynamic interface definition' ensures that the user interface changes to reflect the services available to users as they move through the landscape. In time the gateway will also enable users to search other network resources of interest to humanities scholars, which are not maintained by AHDS.
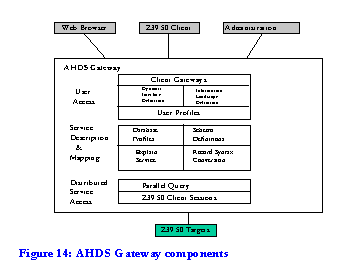
The `Service description layer' will enable the Gateway to smooth out anomalies between underlying databases. It comprises two principal components: a Z39.50 Explain proxy service and a record syntax conversion facility. The Explain proxy service will store profiles of databases that are known to and thus searchable by the Gateway. A profile will include information about the database's contents and record structure, the kinds of queries it supports, and the format in which results are returned. The Z39.50 Explain function is designed to generate such information about a database whenever it is queried by a Z39.50 client. However there are currently very few Explain implementations so the Explain proxy service is an interim measure until Explain is more widely available.
A record syntax conversion facility will hide the heterogeneity of different databases from the user by converting incoming record structures into a standard internal format which will display single uniform result sets to users.
The system will initially provide access to a small number of scholarly humanities collections, but since its design is aligned with the MIA framework, it is extensible, enabling scholarly communities to take full advantage of network technologies and the proliferation of online information resources.[52]
EDINA[53] was launched as a UK national datacentre early in 1996. In addition to establishing itself as a host for national services, a further task was to find its role in the emerging virtual library for UK higher education, the design for which was being laid out through the MODELS workshops and the eLib Programme.
The MODELS `user' verbs have been used in EDINA's strategic thinking: discover, locate, request and access. By hosting bibliographic discovery services (such as Art Abstracts, BIOSIS Previews and Periodical Contents Index (PCI)), EDINA already helps to provide part of the response to the first verb (discover). By running and developing SALSER (Scottish Academic Library Serials)[54], the virtual union catalogue of serials holdings in Scotland, the second verb (locate) is also addressed, with specialist emphasis on serials. EDINA is also working with colleagues in Europe, through the CASA project in the EU Telematics Programme, to contribute an extra verb, that of `verify'. ISSN-based identifiers (such as SICI and DOI) and network access to the ISSN world serials register act as lynchpins to make cost-effective the automatic progression along this chain from discovery of an information object (eg an article), to access and use of that object. (The project also involves the development of an international infrastructure for serials services directories.)
EDINA is using OCLC SiteSearch as the software platform to achieve this interoperability. Two bibliographic databases are already in service with version 3.1 of SiteSearch. As the European field tester for version 4.0 (written in Java on the server-side with database object classes to maximise connectivity to heterogeneous databases), EDINA is taking forward several projects which will play an important part in the implementation of the MODELS Information Architecture. The first is to port SALSER from Web/WAIS into SiteSearch, in order to search information on serials holdings across databases using Z39.50. A redesign will also take advantage of the ISSN world serials register, providing a serials authority file for the virtual union catalogue. The second is to set up facilities to allow users of PCI and Art Abstracts who discover a journal article of interest to have a `hot link' which will locate the libraries which hold that journal. This redesign of SALSER will be used as an opportunity to demonstrate interoperability, such as cross-database searching, with other discovery facilities as well as the use of SALSER to provide links to other network-accessible information on serials holdings.
EDINA is also interested in helping enact the final verbs for the digital information object of interest: request and access. This might include, for example, the delivery of electronic access to the full text of a journal article, to a research dataset, or to a (digital) map for printing. As a JISC national datacentre, EDINA may be directed to host such information objects, but it is realised that plans must be made to support connectivity to the vast range of specialist objects hosted elsewhere, either in the JISC distributed national electronic resource or in the online services of commercial vendors. EDINA is therefore supportive of the adoption of MODELS thinking, to facilitate interworking between sectors and domains.[55]
Aquarelle is an EC Telematics Applications Programme-funded project developing the Information Network on Cultural Heritage. It is a distributed information system, offering access to interrelated multimedia reference documents and primary data that describe the cultural heritage of Europe. It aims to provide a facility affording uniform access to the varied collection of data held by museums, art galleries, and other cultural organisations throughout Europe.
An Aquarelle user formulates a query at the user interface. This query is passed to the Aquarelle central services module, the Access Server. It is further processed by the Access Server and submitted to the data servers. The responses from the data servers are collated by the Access Server and passed back to the user. As the query passes from the user to the data servers and the results are passed back they undergo a series of transformations as they are encoded in various protocols. The principal protocols are HTTP, AQL, Z39.50 and SGML together with the local protocol used at the data servers.
Aquarelle supports two types of data servers, Archive Servers and Data Servers. Archive Servers provide information about individual objects or sites, typically returning a record about each object or site. They follow the conventional information retrieval for database access. The Archive Server model is designed so that an existing museum collection management system or data service system could act as an Aquarelle Archive Server using the appropriate interface. Data servers provide access to objects themselves.
The Aquarelle system can be mapped readily to the MIA model. The Aquarelle Access Server is a broker supporting most of the MIA functions. It maintains a database of registered users for authentication and user profiles. The Aquarelle Directory services maintain a database of collection and service descriptions which support the MIA discover and locate functions. The user interface components present the information landscape in terms of subject domains as well as specific databases; they also provide multilingual thesauri to assist in query formulation. Aquarelle supports the MIA request and delivery functions for Aquarelle folders. In addition Aquarelle offers facilities which are not explicit MIA components: folder publishing, persistent link management and multilingual thesauri for query formulation.[56]
The NESSTAR[57] project has brought together several European data archives (The Data Archive, UK (University of Essex), Danish Data Archives and Norwegian Social Science Data Services), as well as data producers and users, to develop distributed yet seamless resource discovery and use systems. It has been funded by Information Engineering, part of the EC Telematics Applications Programme.
The archives typically hold data about society, whether economic or social, which has been collected by many government departments, research institutes and companies. The project will increase the use of these data by developing a set of generic tools that will make it easier to:
Producers of data will have improved means of structuring and disseminating data in controlled ways. Users of data will have access to improved tools to identify the most appropriate data sources and will be able to analyse the data effectively, either via the Web browser or via downloading to the local site. The effect of these developments will be not only to increase productivity among traditional researchers, but also to lead to greater data use among new, more statistically naïve, groups of users.
In order to achieve these goals the project will take advantage of three key technologies. These are:
The project has a strong focus on the ease of use of social and economic data, but with a specific aim of making these resources more available by participating in complementary developments in the electronic library world, such as the MODELS Information Architecture (MIA) model.[58]
The ROADS cross-searching facility was introduced above. This could be discussed in the following terms:
We have described aspects of the current network information environment, and argued that current management approaches are unsustainable: they will not support users adequately, and they will impose an increased management overhead on the library. We have outlined a broker-based approach and have introduced the MODELS Information Architecture, a device for thinking about desirable components of such approaches and their logical arrangement. We have described some development activity which is aligned with the approach suggested.
MIA separates the presentation of an integrated service to users from interaction with the components which provide that service. In this way, it becomes possible to develop an `information landscape' which responds to user interests and preferences rather than to particular system constraints. It becomes possible to manage the acquisition or substitution of components while minimising the impact on the user. A framework is suggested which supports intra-function integration so as to protect the user and manager from difference, and inter-function integration so as to support automation of end-to-end processes.
This is not to suggest that there are not many difficulties in a heterogeneous environment, and some of the issues in relation to the serials literature have been explored.
The library will increasingly broker direct user access to resources and services, organising information flows in a managed environment. This will be necessary to support the changing educational and social environments in which they operate. When technologies of control improve (authentication, rights management, commerce), this trend will become more pronounced. The consequence of a lack of integration is that investment in networked information is less efficient than it could be:
The approach developed here suggests how libraries can begin to develop a `coherent context' into which the technology can disappear. We expect the library will continue to organise the assembly places where information users and information products are brought into fruitful contact. The challenge is to help create a new `utopian place of criticism' where the organised reading space of the world's resources can be opened `side by side' in the user's workspace.
This work has been supported by the MODELS project. UKOLN is funded by the British Library and the Joint Information Systems Committee. It also receives support from the University of Bath where it is based.
[1] McCullough, Malcolm. Abstracting craft: the practiced digital hand. Cambridge, MA.: The MIT Press, 1996. P.251
[2] Manguel, Alberto. A history of reading. London: HarperCollins, 1996.
[3] Jacob, Christian. La Lecon d'Alexandrie. Autrement, Number 121, Paris, 1993. (as cited in Manguel, op cit)
[4] Heseltine, Richard. Resource discovery and systemic change: a UK perspective. In: Dempsey, Lorcan; Law, Derek; Mowat; Ian. (eds). Networking and the fuuture of libraries 2: managing the intellectual record. London: Library Association Publishing, 1995, 119-124.
[5] JISC. JISC Collections Policy: an integrated environment for higher education: developing the distributed national electronic resource (DNER). [Bristol]: JISC, 1998. Also available at <URL:http://www.jisc.ac.uk/cei/dner_col_pol.html> (visited 23 May 1998)
[6] Hanson, Terry. The access catalogue gateway to resources. Ariadne, 15, 1998. <URL:http://www.ukoln.ac.uk/ariadne/issue15/main>. (visited 2 June 1998)
[7] Paepcke, Andreas, et al. Using distributed objects for digital library interoperability. Computer, 29(5), 1996, 61-68.
[8] Russell, Rosemary. Towards new models for managing and accessing serials resources. Managing Information, 4 (8), October 1997, 37-39.
[9] Dempsey, Lorcan; Russell, Rosemary; Murray, Robin; and Heseltine, Richard. Managing access to a distributed library resource. Program,32(3),1998, 265-281.
[10] Lynch, Clifford A. Identifiers and their role in networked information applications. ARL Newsletter, 194, 1997. Available at <URL:http://www.arl.org/newsltr/194/identifier.html> (visited 7 April 1998)
[11] Powell, Andy. Unique identifiers in a digital world. Ariadne, 8, March 1997. <URL:http://www.ariadne.ac.uk/issue8/unique-identifiers/> (visited 20 May 1998)
[12] Young, Andrew. Implementation of JANET authentication and encryption services. A report published by the JTAP programme of JISC. 1997. Available from the JTAP web site <URL:http://www.jtap.ac.uk/> (visited 20 May 1998) (visited 19 May 1998)
[13] Lynch, Clifford A. (ed). A White Paper on authentication and access management issues in cross-organizational use of networked information resources. Revised discussion draft of April 14, 1998. Available from the Coalition for Networked Information web site <URL:http://www.cni.org/projects/authentication/authentication-wp.html>. (visited 19 May 1998)
[14] Further information about MODELS and its results can be found at <URL:http://www.ukoln.ac.uk/dlis/models> (visited 20 May 1998)
[15] Russell, Rosemary. UKOLN MODELS 4: evaluation of cross-domain resource discovery. In: Daniel Greenstein and Paul Miller (eds) Discovering online resources across the humanities. Bath: UKOLN (on behalf of the Arts and Humanities Data Service and the UK Office for Library and information Networking), 1997, 18-21.
[16] Further information can be found on the Telematics for Libraries web site <URL:http://www2.echo.lu/libraries/en/libraries.html>. (visited 19 May 1998)
[17] Further information about eLib can be found on the eLib web site <URL:http://www.ukoln.ac.uk/services/elib/>. (visited 19 May 1998)
[18] Further information about the Digital Libraries Initiative can be found at <URL:http://dli.grainger.uiuc.edu/national.htm> (visited 20 May 1998)
[19] Dempsey, Lorcan; Russell, Rosemary; and Murray, Robin. The emergence of distributed library systems: a European perspective. Journal of the American Society of Information Scientists, 49 (10), 1998, 942-951.
[20] Mackenzie Owen, J.S. and Wierck, A. EUR 16905 - Knowledge models for networked library services. Luxembourg: Office for Official Publications of the European Communities, 1996.
[21] Dempsey, Lorcan and Russell, Rosemary. `Clumps' - or distributed access to scholarly material. Program, 31(3), July 1997, 239-249.
[22] Baldonado, Michelle et al. The Stanford Digital Library metadata architecture. [1998] <URL:http://www-diglib.stanford.edu/diglib/pub/delos.html> (visited 6 April 1998)
[23] Paepcke, Andreas et al. Interoperability for digital libraries worldwide. Communications of the ACM, April 1998, 41(4), 33-43.
[24] Moen, William E. Accessing distributed cultural heritage information. Communications of the ACM, April 1998, 41(4), 45-48.
[25] Committee on Earth Observation Satellites. Interoperable catalogue system: system design document. Version 1.2. March 1997.
[26] Greenstein, Daniel and Murray, Robin. Metadata and middleware: a systems architecture for cross domain discovery. In: Greenstein, Daniel and Miller, Paul (eds) Discovering online resources across the humanities. Bath: UKOLN (on behalf of the Arts and Humanities Data Service and the UK Office for Library and information Networking), 1997, 56-62.
[27] Valkenburg, Peter (ed). Standards in a distributed indexing architecture, draft version 1. 24 February 1998. <URL:http://www.terena.nl/projects/chic-pilot/standards_v1.html> (visited 27 May 1998)
[28] Lincke, David-Michael and Schmid, B. Mediating electronic product catalogs. Communications of the ACM, 41(7), 1998, 86-88.
[29] Kochikar, Vivekanand P. The object-powered web. IEEE Software, May/June 1998, 57-62.
[30] Web standards can be tracked at the World Wide Web Consortium's website <URL:http://www.w3.org/> (visited 25 May 1998)
[31] Larbey, David. Project EDDIS: an approach to integrating document discovery, locate, request and supply. Interlending and Document Supply, 25(3), 1997, 96-102.
[32] The ROADS cross searching service is available at <URL:http://www.ukoln.ac.uk/metadata/roads/crossroads/>. (visited 20 May 1998)
[33] An overview of the Gazebo software is available at <URL:http://emerge.ncsa.uiuc.edu/gazebo.html>. (visited 20 May 1998)
[34] Russell, Rosemary. Standards for serials: building the basis for distributed access. Serials, 10(3), November 1997, 357-364.
[35] Dempsey, Lorcan. Readbites: the scandal of serials holding data. Catalogue & Index, number 118, Winter 1995. p. 9.
[36] Information about the DOI Foundation and DOIs can be found at <URL:http://www.doi.org/>. (visited 19 April 1998.)
[37] Lynch, Clifford A. Identifiers and their role in networked information applications. Op cit.
[38] Hopkinson, Alan. Standards for Serial Holdings and for Serials Data in the Serials Analytic Record. [1997] An eLib supporting study coordinated by UKOLN and prepared as a result of MODELS 1. Available from the eLib supporting studies web page<URL:<URL:http://www.ukoln.ac.uk/dlis/models/studies/>. (visited 12 May 1998)
[39] Martin, David and Bide, Mark. Standards for serials metadata and Terms of availability - combined report. 1997. An eLib supporting study coordinated by UKOLN and prepared as a result of MODELS 1. Available from the eLib supporting studies web page<URL:<URL:http://www.ukoln.ac.uk/dlis/models/studies/>. (visited 12 May 1998)
[40] Library and Information Commission. New library: the people's network. London: Library and Information Commission, 1997. Text available at <URL: <URL:http://www.ukoln.ac.uk/services/lic/newlibrary/> (last visited 14 May 1998). (visited 20 May 1998)
[41] Greenstein, Daniel and Dempsey, Lorcan. Crossing the great divide: integrating access to the scholarly record. In: Greenstein, Daniel and Miller, Paul (eds) Discovering online resources across the humanities. Bath: UKOLN (on behalf of the Arts and Humanities Data Service and the UK Office for Library and information Networking), 1997, 7-10.
[42] Dempsey, Lorcan and Heery, Rachel. Metadata: a current view of practice and issues. Journal of Documentation, 54(2), 1998, 145-172.
[43] Allen, J. and Mealling, M. The architecture of the Common Indexing Protocol (CIP). Request for Comments draft version 1. 1997. Available at <URL:ftp://ftp.ietf.org/internet-drafts/draft-ietf-find-cip-arch-01.txt> (visited 25 May 1998)
[44] The MODELS collection description study is available at: <URL:http://www.ukoln.ac.uk/dlis/models/studies/> (visited 8 June 1998)
[45] The Agora web-site is at <URL:http://hosted.ukoln.ac.uk/agora/> (visited 3 May 1998)
[46] Experimental Z39.50 servers including ROADS databases can be trialled at: <URL:http://roads.ukoln.ac.uk/cgi-bin/egwcgi/egwirtcl/targets.egw>. (visited 5 August 1998)
[47] This section is adapted from text supplied by David Kay, Fretwell Downing Informatics
[48] Information about Fretwell-Downing is at: <URL:http://www.fdgroup.co.uk/FDI/> (visited 3 May 1998)
[49] This section is based on Greenstein and Murray, op cit, updated by personal communication from Daniel Greenstein.
[50] Information about AHDS is at: <URL:http://www.ahds.ac.uk/> (visited 3 May 1998)
[51] Miller, Paul. and Greenstein, Daniel. (eds.) Discovering online resources across the humanities: a practical implementation of the Dublin Core. Bath: UKOLN, 1997.
[52] This section is adapted from text provided by Peter Burnhill, Director EDINA.
[53] Information about EDINA is at: <URL:http://edina.ed.ac.uk> (visited 3 May 1998)
[54] Information about SALSER is at: <URL:http://edina.ed.ac.uk/salser/> (visited 3 May 1998)
[55] This section has been adapted from text supplied by Mike Stapleton, System Simulation Ltd.
[56] This section has been adapted from text supplied by Simon Musgrave, Director, The Data Archive, University of Essex.
[57] Information about NESSTAR is at: <URL:http://dawww.essex.ac.uk/projects/nesstar/> (visited 3 May 1998)
[58] Based on some text supplied by Ian Peacock, UKOLN.
[59] Allen and Mealling. Op cit.
[60] Bell, Anne. The impact of electronic information on the academic research community. The New Review of Academic Librarianship, 3, 1997, 1-24.