![]()
![]()
• The architecture should use current technology and international standards wherever possible.
• The architecture should be fundamentally accessible to users of current Z39.50 and http client software.
• The architecture should be scalable, allowing for implementations ranging from basic "low-tech" pilot studies through to complex national structures.
• The architecture, should be suitable for library catalogue clumping, but also be applicable to the larger cross-domain search problem.
• The architecture should be open enough to allow for a variety of interoperable implementations.
• The architecture should allow for the definition of persistent clumps as well as allowing clients/users to define adhoc virtual clumps based on the results of searching metadata records describing individual databases. This latter requirement allows users to discover databases that they did not previously know existed.
In order to define a Clump and its constituent databases in way that will make sense to both human and mechanical readers, we are going to need network accessible metadata records that describe the clump and its components.
There are at least three levels of description required:
• The constituent databases within a Clump
• The hosts or servers that provide access to the individual databases via well known protocols.
Clump Metadata needs to perform several functions. Firstly it needs to describe the content and purpose of the clump in such a way that the end user can decide whether the Clump is useful to them or not, and secondly it needs to provide enough technical information to the end-users client software to enable it to make the necessary connections to the remote service. The human-readable descriptive information needs to be indexible and searchable, so that end-users may search a database of Clump information in order to be returned a list of services that will best be able to satisfy the requirements of the search.
Such metadata systems are currently one of the hot topics on the Internet, and this means that there is much research into this area of information management, which also means that there are many possibly competing metadata systems under development and as yet no clearly winning solution. So rather than mandate a Clumps metadata system, it would be much more pragmatic to look at some of the more promising systems under development. The Clumps developers may then consider choosing one or more of these systems as the basis for storing and transferring Clump metadata.
The metadata formats examined in this paper are:
• Z39.50 Digital Collections Profile
Very simple listings of the data elements for each of these systems are included as Appendices at the end of this document. Anyone interested in any of these systems should go to the source documents themselves, since the brief listings given here have been provided solely to provide some form of comparison between the systems under discussion.
<URL: http://lcweb.loc.gov/z3950/agency/1995doc.html>
Within the latest version of the Z39.50 Information Search and Retrieval protocol there is the facility for Z39.50 servers to mount a database of metadata describing the services and databases available from that server. This metadata includes records that can be used to describe both actual databases and logical databases that consist of one or more physical databases. Since this accords quite strongly with our concept of Clumps representing one or more physical databases these Explain database description records merit further examination. This paper is not advocating the exclusive use of the Z39.50 Explain facility itself, but is suggesting that we might borrow Explain's database description record schema as a means of describing Clumps and their constituent databases, using whatever access protocol we think is most suitable. A list of of the elements used in Explain databaseInfo records is given in Appendix 1 of this document.
Z39.50 Digital Collections Profile
<URL: http://lcweb.loc.gov/z3950/agency/profiles/collections.ps>
The Digital Collections Profile has been developed to provide a mechanism whereby hierarchical descriptions of museum or library collections can be navigated by a Z39.50 client in order to locate items or collections of interest to a particular search. This profile is specifically aimed at the problem of cross-domain information retrieval, and at solving the problem of discovering which databases may be relevant to a given search. This profile is assumed to provide the top-level cross-domain search capabilities, and assumes that other more detailed profiles will be brought into play as the searcher "drills down" into a particular information domain.
As with the Z39.50 Explain system, this paper is not advocating the adoption of Z39.50 for implementing clumps metadata systems. However, this profile does appear to have been developed to solve a problem that is very similar to our own,
and it is therefore worthy of investigation by Clump implementors. Appendix 3 has an outline listing of the Collection Description record elements used by this profile.
<URL: http://purl.org/metadata/dublin_core_elements.html>
The Dublin Core is the core set of descriptive elements that can describe a "document-like object". The Dublin Core is still a topic of considerable debate, and although it might appear difficult to think of a Clump or a database as being a "document-like object", using Dublin Core for decribing Clumps has some distinct advantages:
The data elements are well known, and there are already proposals for encoding Dublin Core in HTML, SGML, as well as mappings between Dublin Core and MARC, GRS-1, SUTRS, and other common records syntaxes. This means that Dublin Core records can be accessed by a variety of network protocols, and the records themselves can be transferred between systems in a variety of encodings. All of which bodes well for interoperability between implementations that use Dublin Core as the basis of their metadata records.
The Dublin Core elements along with Ashley Sanders's proposal for describing Clumps and Databases using these elements are listed in Appendix 2 of this document.
<URL: http://cs-tr.cs.cornell.edu/Dienst/U1/2.0/Describe/ncstrl.cornell/TR96-1593>
The Warwick Framework is not really a metadata system in its own right, but is a system whereby different types of metadata may be packaged for transfer between systems. Since we have at least three different levels of metadata, and a variety of metadata systems to choose from, it is quite possible that each descriptive level could be implemented using a different metadata system, in which case, an implementation of the Warwick Framework would be one way of packaging this information for transfer between systems (and between Clump implementations).
Although it is assumed that Clump database access will be via Z39.50, it is not so clear which protocol(s) will be used for accessing the metadata about Clumps. There are a variety of information retrieval protocols that would suitable, the most obvious ones being:
It is anticipated that a selection of these will be used in the pilot Clumps implementations.
Here are some possible architectures for connecting end users and their search clients to a variety of databases and Clumps.
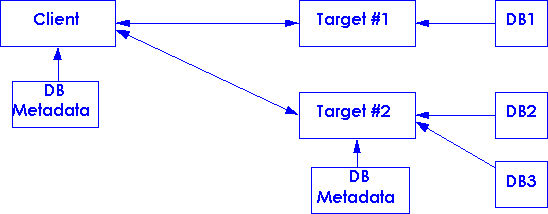
1. The Client searches a single target with a single database. The end user has prior knowledge about the location and contents of the target and its database..
2. The Client searches several targets, each mounting one or more databases. The Client keeps a local list of targets and databases internally or in a local server. This info may be gleaned by Explain or by external contact with database providers. The Client may also be cacheing metadata provided to it by the remote targets.
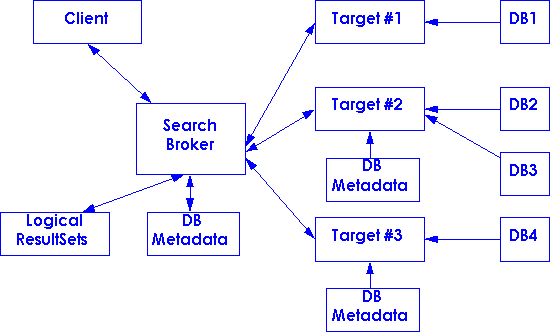
3. The Client communicates with a local or remote Search Broker that mediates between the client and the external servers and databases being accessed. The Search Brokers may provide additional services such as: locally cached clump/target/database information; the sorting and merging of retrieved metadata records into a single logical result set; user authentication and payment services and so on.
Search Brokers may be mounted by the local users' site, or by third-party agencies, or in the cases where a clump is associated with an administrative organisation, then that organisation may mount its own broker. In the above diagram, one of the Targets being accessed by the Search Broker may itself be another Search Broker.
Search Brokers may be used to provide the distributed metadata storage and access mechanisms. However navigational information concerning Clumps need not be confined to the Client or the Search Brokers, it may be held in yet another set of directory servers or information systems. Clumps metadata should therefore remain independent of any given protocol implementation in order to maximise interoperabilty.
This is question is really two related questions:
1. How does one name or reference a link to an actual database in a way that will not force the updating of all clump records if the access details of the database change.
2. How does one name or reference a link to other clump or database description records.
Here are some existing and emerging networked resource naming systems
URL: Universal Resource Location
This scheme identifies resources by providing details of their physical location on the network. URLs are by far the most common form of resource naming, but they are unreliable, since the resource's name changes as its physical location changes, and this is likely to cause major problems over time.
URL format is <protocol>://<machine address>/<filepath>/<filename>
URL example: http://lcweb.loc.gov/z3950/agency/
More experimental than URLs URNs try to provide a universal name space that allows a variety of existing naming systems to be incorporated into a single format. URNs rely on some third-party servers to resolve the permanent name into a temporary location, if the URL changes, then only the name resolvers need to be aware of this change, since the outside world will know the resource by its URN not its URL.
URN format is URN:<namespace>:<name>
URN example: urn:isbn:0124636379
PURL: Persisent Universal Resource Location
OCLC invented PURLs as a kind of halfway house between a URL and a URN. Like URNs a PURL is a permenent name that gets resolved locally into the URL that actually points to the resource. If the URL changes, only the PURL servers need to worry about this, the outside world only knows the resources by their PURLs.
PURL format is <protocol-to-access-resolver>://<resolver address>/<name>
PURL example: http://purl.oclc.org/home/fred/catalog
This is potentially the most difficult aspect of the Clumps initiative. Authentication and authorisation services may be provided by:
• End-User organisations (ie the Campus)
• Service provider organisation (Clump administrators)
They may use any one of several existing authentication systems such as Athens or Kerberos.
For the initial batch of pilot Clumps, it is assumed that access to resources will be free, but usage of resource (ie for ILL purposes etc) may be paid for. While the JISC and others are trying to produce a national solution to authentication and authorisation, it may be that these issues need not be tackled in the initial development of Clumps.
Related to authentication and authorisation is the issue of invoicing and payments. This may be handled entirely electronically, or it may be conducted more conventionaly using paper invoices and normal offline financial transactions. These issues are left entirely to the discretion of the individual Clump implementors.
![]()
![]()